2020奇安信模拟笔试
1.有 ABCDEF 六个城市,每一个城市都和其他所有城市直接相连,问从 A — B 有多少种连接方式,路径不允许在两个城市之间往返。
A 78
B 65
C 43
D 其他选项都不对
思路:简单的排列组合
2.甲有若干本书,乙借走了一半加 3 本,剩下的书,丙借走了 1/3 加 2 本,再剩下的书,丁借走了 1/4 加 1 本,最后甲还有 2 本书。问甲原来有多少本书?
A 24
B 33
C 13
D 28
3.在如下8*6的矩阵中,请计算从A移动到B一共有多少种走法,要求每次只能向上或向右移动一格,并且不能通过P()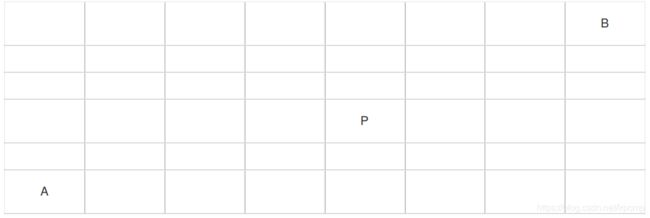
A 702
B 626
C 456
D 680
E 568
F 492
思路:由于只能向上或者向右移动,A→B需要向上走5步,向右走7步,共12步,即组合C(12,5),但是不能通过p,则需要减去经过p的走法,即A→P和P→B的走法,即组合C(6,2)*C(6,3),故不经过p的走法为C(12,5)-C(6,2)*C(6,3)=492。同时这道题可由动态规划进行求解,即当前位置(i,j)的走法等于(i-1,j)和(i,j-1)的走法之和。
4.对有序数组{2、11、15、19、30、32、61、72、88、90、96}进行二分查找,则成功找到15需比较()次
A 3
B 4
C 2
D 5
5.众里寻他千百度,蓦然回首,那人却在灯火阑珊处。——辛弃疾《青玉案》描述的是()
A 贪心
B 回溯
C 穷举
D 分治
E 递归
6.使用KMP算法在文本串S中找模式串P是一种常见的方法。假设S=P={xyxyyxxyx},亦即将S对自己进行匹配,匹配过程中正确的next数组是____。
A 0,1,1,2,2,1,2,2,3
B 0,1,2,2,3,1,2,2,3
C 0,1,1,2,3,1,2,2,3
D 0,1,1,2,3,1,1,2,3
E 0,1,2,2,3,1,1,2,3
F 0,1,2,2,2,1,1,2,3
思路:KMP算法为字符串匹配算法,相比于传统的暴力求解,将复杂度从O(n*m)降到O(n+m),KMP算法模式串p匹配失败后并不是相对于文本串向前移动1位,而是根据next数组(反应了模式串p的子串最长公共前缀后缀的长度)移动相应位数。
参考博文:
从头到尾彻底理解KMP
KMP算法最浅显理解——一看就明白
7.广度优先搜索算法需使用的辅助数据结构为()
A 三元组
B 队列
C 二叉树
D 栈
8.整数数组, N为A的数组长度,请问执行以下代码,最坏情况下的时间复杂度为____。

A O(N)
B O(N^2)
C O(Nlog(N))
D O(log(N))
E O(N^3)
F 无法确定
9.某段通信电文仅由 6 个字母 ABCDEF 组成,字母在电文中出现的频率分别为2,3,7,15,4,6。根据这些频率作为权值构造哈夫曼编码,最终构造出的哈夫 曼树带权路径长度与字母 B 的哈夫曼编码分别为______。(这里假定左节点的值小于右节点的值)
A 86,1011
B 70,1000
C 86,0001
D 70,0010
E 92,1000
F 92,0100
思路:霍夫曼编码是可变长编码的一种,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。构造方法:使用概率最小的两个字母作为左右子树,由下至上构造二叉树,编码时左路径编码为0,右路径编码为1,由上至下对字母进行编码,概率越高的字母编码长度越短。
参考博文:霍夫曼编码
10.下面()数据结构常用于函数调用。
A 队列
B 栈
C 链表
D 数组
11.关于cookie以下描述中不正确的是______。
A cookie附带于http请求中
B cookie有大小限制
C 用户可以主动禁止cookie
D https协议下cookie是明文传递的
12.程序的完整编译过程分为是:预处理,编译,汇编等,如下关于编译阶段的编译优化的说法中不正确的是()。
A 死代码删除指的是编译过程直接抛弃掉被注释的代码;
B 函数内联可以避免函数调用中压栈和退栈的开销
C for循环的循环控制变量通常很适合调度到寄存器访问
D 强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令
13.以下那一个不是进程的基本状态 ()
A 阻塞态
B 执行态
C 就绪态
D 完成态
14.在5个页框上使用LRU页面替换算法,当页框初始为空时,引用序列为0、1、7、8、6、2、3、7、2、9、8、1、0、2,系统将发生()次缺页
A 13
B 12
C 11
D 8
15.牛客网的数据库有一个paper表,现在要查询试卷名字包含"人人网"的所有数据,则sql语句应该为?
A SELECT * FROM paper WHERE paper_name LIKE ‘人人网’;
B SELECT * FROM paper WHERE paper_name LIKE ‘%人人网’
C SELECT * FROM paper WHERE paper_name LIKE ‘人人网%’;
D SELECT * FROM paper WHERE paper_name LIKE ‘%人人网%’;
16.一般,k-NN最近邻方法在( )的情况下效果较好
A 样本较多但典型性不好
B 样本较少但典型性好
C 样本呈团状分布
D 样本呈链状分布
17.关于 logit 回归和 SVM 不正确的是()
A Logit回归目标函数是最小化后验概率
B Logit回归可以用于预测事件发生概率的大小
C SVM目标是结构风险最小化
D SVM可以有效避免模型过拟合
18.Nave Bayes是一种特殊的Bayes分类器,特征变量是X,类别标签是C,它的一个假定是:()
A 各类别的先验概率P©是相等的
B 以0为均值,sqr(2)/2为标准差的正态分布
C 特征变量X的各个维度是类别条件独立随机变量
D P(X|C)是高斯分布
19.以下几种模型方法属于判别式模型(Discriminative Model)的有()
1)混合高斯模型
2)条件随机场模型
3)区分度训练
4)隐马尔科夫模型
A 2,3
B 3,4
C 1,4
D 1,2
20.有两个样本点,第一个点为正样本,它的特征向量是(0,-1);第二个点为负样本,它的特征向量是(2,3),从这两个样本点组成的训练集构建一个线性SVM分类器的分类面方程是()
A 2x+y=4
B x+2y=5
C x+2y=3
D 以上都不对
思路:该题貌似有问题