redis 哨兵
redis 哨兵
一、图解
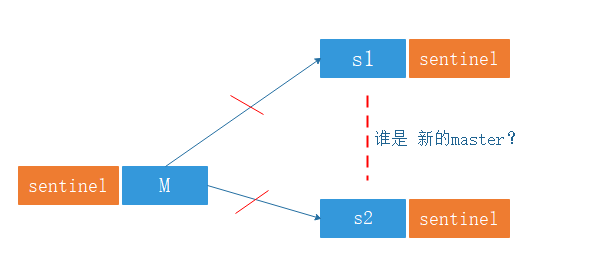
如图:
每个节点都有一个哨兵进程用于监控 redis 进程是否存活,当 master 宕机时候,哨兵们在剩余的slave 节点中 ,可以投票选举 新的master 节点,并且slave节点可以自动完成角色的切换。哨兵可以不和 Redis 服务器部署在一起,但是为节约服务器,只好放在一起。
当Sentinel将一个主服务器判断为主观下线之后(没有收到回复),为了确认这个主服务器是否真的下线了,它会向同样监视这一主服务器的其他Sentinel进行询问,看它们是否也认为主服务器已经进入了下线状态(可以是主观下线或者客观下线)。当Sentinel从其他Sentinel那里接收到足够数量的已下线判断之后,Sentinel就会将从服务器判定客观下线,并对主服务器执行故障转移操作。
注意:选举通常是至少一半的人(即下面的参数quorum,是偶数)同意才算选举成功,所以参加选举的人数必须是奇数,所以在设计式哨兵的配置一定是奇数。
sentinel monitor
二 、搭建哨兵架构
2.1 先搭建1主2从的架构
2.2 配置哨兵
1.使用二进制安装,apt 安装没有redis-sentinel的命令。二进制包有
2.哨兵的配置
bind 192.168.1.10X(x 代表当前机器地址)
daemonize yes
pidfile "/apps/redis/run/redis-sentinel.pid"
logfile "/apps/redis/log/sentinel_26379.log"
port 26379
dir "/apps/redis/data"
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 192.168.1.101 6379 2 (此处都一样,都是master的地址)
sentinel auth-pass mymaster 123456
3.启动
root@z3:~# /apps/redis/bin/redis-sentinel /apps/redis/etc/sentinel.conf
4.验证
root@z1:~# redis-cli -h 192.168.1.101 -p 26379
192.168.1.101:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.1.101:6379,slaves=2,sentinels=3
发现有1个master,2个slave,3个sentinel 即可
5.sentinel 自动添加的参数
在master 上:
sentinel.conf 自动生成的配置
- 每个哨兵的id
- 除去M的 redis客户端的地址和端口,
- 除去自己的哨兵地址和端口
sentinel myid edce8d64ee4790d380ab5a86dd074183a76e100e
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 192.168.1.102 6379
sentinel known-slave mymaster 192.168.1.103 6379
sentinel known-sentinel mymaster 192.168.1.102 26379 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5
sentinel known-sentinel mymaster 192.168.1.103 26379 09f0c95a1bac1882695e5b7dccdb5a6b6a6ec653
sentinel current-epoch 0
在salve1 上
sentinel.conf 自动生成的配置
sentinel myid 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 192.168.1.102 6379
sentinel known-slave mymaster 192.168.1.103 6379
sentinel known-sentinel mymaster 192.168.1.103 26379 09f0c95a1bac1882695e5b7dccdb5a6b6a6ec653
sentinel known-sentinel mymaster 192.168.1.101 26379 edce8d64ee4790d380ab5a86dd074183a76e100e
sentinel current-epoch 0
在slave2上自动生成的配置
sentinel myid 09f0c95a1bac1882695e5b7dccdb5a6b6a6ec653
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 192.168.1.102 6379
sentinel known-slave mymaster 192.168.1.103 6379
sentinel known-sentinel mymaster 192.168.1.102 26379 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5
sentinel known-sentinel mymaster 192.168.1.101 26379 edce8d64ee4790d380ab5a86dd074183a76e100e
sentinel current-epoch 0
6.故障转移时变化的参数
-
存活的redis端口
-
epoch 值
M:
sentinel leader-epoch mymaster 1
sentinel known-slave mymaster 192.168.1.101 6379
sentinel known-slave mymaster 192.168.1.103 6379
sentinel known-sentinel mymaster 192.168.1.102 26379 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5
sentinel known-sentinel mymaster 192.168.1.103 26379 09f0c95a1bac1882695e5b7dccdb5a6b6a6ec653
sentinel current-epoch 1
S1:
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
sentinel known-slave mymaster 192.168.1.101 6379
sentinel known-slave mymaster 192.168.1.103 6379
sentinel known-sentinel mymaster 192.168.1.103 26379 09f0c95a1bac1882695e5b7dccdb5a6b6a6ec653
sentinel known-sentinel mymaster 192.168.1.101 26379 edce8d64ee4790d380ab5a86dd074183a76e100e
sentinel current-epoch 1
S2:
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
sentinel known-slave mymaster 192.168.1.101 6379
sentinel known-slave mymaster 192.168.1.103 6379
sentinel known-sentinel mymaster 192.168.1.102 26379 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5
sentinel known-sentinel mymaster 192.168.1.101 26379 edce8d64ee4790d380ab5a86dd074183a76e100e
sentinel current-epoch 1
三、sentinel 参数简介
- sentinel parallel-syncs mymaster 1 #发生故障转移时候并行向新 master 同步数据的 slave 数量,数字越 小总同步时间越长
- sentinel failover-timeout mymaster 180000 #所有 slaves 指向新的 master 所需的超时时间
- sentinel deny-scripts-reconfig yes 是否允许lua脚本再配置。在你不使用lua脚本的时候,这项没有啥用
四、停止 Redis Master 测试故障转移:
故障转移后 redis.conf 中的 replicaof 行的 master IP 会被修改,sentinel.conf 中的 sentinel monitor IP 会 被修改
具体过程参考:https://www.cnblogs.com/Eugene-Jin/p/10819601.html
没有发生故障前slave 2的状态
# Replication
role:slave
master_host:192.168.1.101
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:826027
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:73d3e109fdb47536c7cc8984470899e5ccef02f1
master_replid2:0000000000000000000000000000000000000000
发生故障后slave 2的状态,已经切换为master,master_replid 发生的改变。id2 是上次的id
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.1.103,port=6379,state=online,offset=957605,lag=1
master_replid:79bc9490490ee6f825f4d29e8fa373624a161903
master_replid2:73d3e109fdb47536c7cc8984470899e5ccef02f1
而且会自动修改 和sentinel 、redis.conf 的内容
redis.conf
102 上 追加masterauth “123456” ,把之前的给注释了
103 上会追加 slaveof 192.168.1.102 6379 masterauth “123456” 把之前的给注释了
五、专有名词
转载自:https://blog.csdn.net/chen_kkw/article/details/82724330
-
纪元(epoch)
Redis Cluster 使用了类似于 Raft 算法 term(任期)的概念称为 epoch(纪元),用来给事件增加版本号。Redis 集群中的纪元主要是两种:currentEpoch 和 configEpoch。
-
currentEpoch
这是一个集群状态相关的概念,可以当做记录集群状态变更的递增版本号。每个集群节点,都会通过 server.cluster->currentEpoch 记录当前的 currentEpoch。
集群节点创建时,不管是 master 还是 slave,都置 currentEpoch 为 0。当前节点接收到来自其他节点的包时,如果发送者的 currentEpoch(消息头部会包含发送者的 currentEpoch)大于当前节点的currentEpoch,那么当前节点会更新 currentEpoch 为发送者的 currentEpoch。因此,集群中所有节点的 currentEpoch 最终会达成一致,相当于对集群状态的认知达成了一致。
currentEpoch 作用
currentEpoch 作用在于,当集群的状态发生改变,某个节点为了执行一些动作需要寻求其他节点的同意时,就会增加 currentEpoch 的值。目前 currentEpoch 只用于 slave 的故障转移流程,这就跟哨兵中的sentinel.current_epoch 作用是一模一样的。当 slave A 发现其所属的 master 下线时,就会试图发起故障转移流程。首先就是增加 currentEpoch 的值,这个增加后的 currentEpoch 是所有集群节点中最大的。然后slave A 向所有节点发起拉票请求,请求其他 master 投票给自己,使自己能成为新的 master。其他节点收到包后,发现发送者的 currentEpoch 比自己的 currentEpoch 大,就会更新自己的 currentEpoch,并在尚未投票的情况下,投票给 slave A,表示同意使其成为新的 master。
六、日志追踪
master 的日志记录
5522:X 16 Feb 23:00:56.984 # +new-epoch 1 (进入新的纪元,当前集群状态已经更新)
5522:X 16 Feb 23:00:56.987 # +vote-for-leader 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5 1(自己给102 投了一票)
5522:X 16 Feb 23:00:58.002 # +config-update-from sentinel 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5 192.168.1.102 26379 @ mymaster 192.168.1.101 6379 (更新当前哨兵的设置,把配置文件给更新了)
5522:X 16 Feb 23:00:58.003 # +switch-master mymaster 192.168.1.101 6379 192.168.1.102 6379 (集群中的master 由101 转变为102)
5522:X 16 Feb 23:00:58.004 * +slave slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.102 6379(检测到103,并且把103作为102的slave)
5522:X 16 Feb 23:00:58.004 * +slave slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.102 6379(检测到101,并且把101作为102的slave)
5522:X 16 Feb 23:01:28.028 # +sdown slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.102 6379 (检测到101 已经客观宕机了)
slave1 的日志记录
5223:X 16 Feb 23:00:56.914 # +sdown master mymaster 192.168.1.101 6379(matser主观下线)
5223:X 16 Feb 23:00:56.967 # +odown master mymaster 192.168.1.101 6379 #quorum 2/2(master客观下线2个人赞成)
5223:X 16 Feb 23:00:56.967 # +new-epoch 1 (进入新的纪元)
5223:X 16 Feb 23:00:56.967 # +try-failover master mymaster 192.168.1.101 6379(新的故障转移正在进行中,正在等待多数选出)
5223:X 16 Feb 23:00:56.969 # +vote-for-leader 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5 1(自己投了102一票)
5223:X 16 Feb 23:00:56.973 # edce8d64ee4790d380ab5a86dd074183a76e100e voted for 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5 1 (101 投了102 一票)
5223:X 16 Feb 23:00:56.973 # 09f0c95a1bac1882695e5b7dccdb5a6b6a6ec653 voted for 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5 1 (103 也投了102一票)
5223:X 16 Feb 23:00:57.036 # +elected-leader master mymaster 192.168.1.101 6379 (101被选举为去执行failover)
5223:X 16 Feb 23:00:57.036 # +failover-state-select-slave master mymaster 192.168.1.101 6379(准备要选择一个slave当选新master,尝试寻找合适的salve进行升级为master)
5223:X 16 Feb 23:00:57.113 # +selected-slave slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379 (找到了一个适合的slave 102来担当新master)
5223:X 16 Feb 23:00:57.113 * +failover-state-send-slaveof-noone slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379 (把选择为新master的slave 102 的身份进行切换)
5223:X 16 Feb 23:00:57.176 * +failover-state-wait-promotion slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379 (等待slave 102身份的切换)
5223:X 16 Feb 23:00:57.899 # +promoted-slave slave 192.168.1.102:6379 192.168.1.102 6379 @ mymaster 192.168.1.101 6379 (102 成功的提升为master)
5223:X 16 Feb 23:00:57.899 # +failover-state-reconf-slaves master mymaster 192.168.1.101 6379 ( 集群的状态由 Failover变为reconf-slaves状态)
5223:X 16 Feb 23:00:57.988 * +slave-reconf-sent slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379 (sentinel发送SLAVEOF命令把103重新配置时)
5223:X 16 Feb 23:00:58.903 * +slave-reconf-inprog slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379 (slave 103被重新配置为另外一个102的slave,但数据复制还未发生)
5223:X 16 Feb 23:00:58.903 * +slave-reconf-done slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.101 6379 (103 数据复制已经与master102同步)
5223:X 16 Feb 23:00:58.958 # +failover-end master mymaster 192.168.1.101 6379 (failover成功完成)
slave2的日志记录
5179:X 16 Feb 23:00:56.977 # +new-epoch 1 (进入新的纪元)
5179:X 16 Feb 23:00:56.979 # +vote-for-leader 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5 1 (自己投了102)
5179:X 16 Feb 23:00:56.996 # +sdown master mymaster 192.168.1.101 6379 (101 主观下线)
5179:X 16 Feb 23:00:57.067 # +odown master mymaster 192.168.1.101 6379 #quorum 3/2 (全体认为101 客观下线)
5179:X 16 Feb 23:00:57.068 # Next failover delay: I will not start a failover before Sun Feb 16 23:06:57 2020 (因为多个salve故障转移有并行限制)
5179:X 16 Feb 23:00:57.995 # +config-update-from sentinel 8c24a7cf01aa94c771b9c5fc6daae5c2e49b2ed5 192.168.1.102 26379 @ mymaster 192.168.1.101 6379 (自动更新配置文件)
5179:X 16 Feb 23:00:57.995 # +switch-master mymaster 192.168.1.101 6379 192.168.1.102 6379 (master的地址发生变化)
5179:X 16 Feb 23:00:57.996 * +slave slave 192.168.1.103:6379 192.168.1.103 6379 @ mymaster 192.168.1.102 6379 (检测到一个slave 103并添加进slave列表)
5179:X 16 Feb 23:00:57.996 * +slave slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.102 6379 (检测到一个slave 101并添加进slave列表)
5179:X 16 Feb 23:01:28.040 # +sdown slave 192.168.1.101:6379 192.168.1.101 6379 @ mymaster 192.168.1.102 6379 ( 101 进入SDOWN状态;)