神仙打架看不懂?用人话解读NIPS神经网络攻防赛清华三连冠团队模型算法
本文用高中生能听懂的人话介绍了2017NIPS神经网络攻防竞赛清华大学三项冠军团队的算法模型,详细介绍了基本算法FGSM、对抗样本的生成、攻防模型训练、NIPS比赛规则、清华参赛队的模型可迁移性优化策略、降噪优化算法。
作者:张子豪(同济大学在读研究生)
发布于2018-10-29
在阅读下文之前,请先用三分钟阅读本文作者的另一篇科普文:【科普】人工智能秒变人工智障:误导神经网络指鹿为马。这篇文章用人话讲解了神经网络对抗样本、逃逸攻击、白盒黑盒攻击的基本概念,并展示了学术最前沿的几个攻击神经网络成功案例(全文无数学推导,请放心食用)。
文章目录
- 1、本文概览
- 2、FGSM算法:生成对抗样本
- 第一步:构造损失函数
- 第二步:多步迭代,找到损失函数最大值
- 第三步:带目标FGSM算法—指鹿为马
- 第四步:集合攻击—集百山之石,攻此山之玉
- 第五步:对抗训练—把真实战场作为训练场
- 3、NIPS2017神经网络攻防竞赛
- 比赛分组
- 清华参赛队模型
- 一味提高迭代次数反而适得其反?
- 带动量的FGSM算法—放心大胆迭代计算
- 对于指定要求指鹿为马的攻击
- 对抗样本对原图做了什么?噪音!
- 两种去除噪音的神经网络模型
- 清华参赛队去噪防守模型训练过程
- 两种去噪模型全都不靠谱
- 改进的降噪方案—PDG和HGD
- HGD模型的可迁移性:多种模型都适用
- 像素层面上的去噪并不能真正去掉噪音
- 4、参考文献与扩展阅读
1、本文概览
2017年,“生成对抗神经网络GAN之父”Ian Goodfellow 牵头组织了NIPS的 Adversarial Attacks and Defences(神经网络对抗攻防竞赛),清华大学博士生董胤蓬、廖方舟、庞天宇及指导老师朱军、胡晓林、李建民、苏航组成的团队在竞赛中的全部三个项目中得到冠军。以下是清华大学参赛师生赛后撰写的总结和相关报告。
清华大学团队包揽三项冠军,NIPS 2017对抗样本攻防竞赛总结
清华大学廖方舟:产生和防御对抗样本的新方法 | 分享总结
清华大学朱军教授:深度学习中的对抗攻击与防守—2018中国计算机大会人工智能与信息安全分会场
动量迭代攻击和高层引导去噪:对抗样本攻防的新方法
清华参赛队攻击组论文:Boosting Adversarial Attacks with Momentum
清华参赛队防御组论文:Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser
本文作者张子豪参加了2018中国计算机大会—人工智能与信息安全分论坛,了解到清华参赛团队的算法思路,详细阅读了2017NIPS神经网络攻防竞赛清华大学三项冠军团队的赛后总结报告和论文。神经网络对抗样本生成与攻防是一个非常有(zhuang)趣(bi)且有前景的研究方向,但常人难以轻易理解内在原理。所以作者决定用高中生能听懂的人话将这一前沿领域以及清华优秀团队的算法模型介绍给大家。
本文大部分图片来自于视频清华大学廖方舟:产生和防御对抗样本的新方法 | AI研习社。
参赛选手廖方舟同学Kaggle最高排名世界第10,是Data Science Bowl 2017冠军。
2、FGSM算法:生成对抗样本
早在2015年,“生成对抗神经网络GAN之父”Ian Goodfellow在ICLR会议上展示了攻击神经网络欺骗成功的案例,在原版大熊猫图片中加入肉眼难以发现的干扰,生成对抗样本。就可以让Google训练的神经网络误认为它99.3%是长臂猿。

下图展示了FGSM算法的基本原理,X*是要产生的对抗样本,x是真实样本,y是图片正确的预测值。
第一步:构造损失函数
第一行表示构造损失函数L(x*,y),同时保证新生成的对抗样本x*必须与原图x保持在一定距离的高维空间之内(约束条件)。 在数学上,argmax(f(x))是使得 f(x)取得最大值所对应的变量x。第一行就是说在满足约束条件前提下,找到让损失函数L(x*,y)最大(也就是让神经网络推测结果越失败)的对抗样本x*。
用人话说就是:在肉眼看上去依旧差不多是同一只大熊猫图片的基础上,把神经网络的推测结果能误导多远就误导多远。

第二行:运用线性假设,构造x*的迭代过程,相当于用反向传播的思想不断用新生成 把反传给图像上的梯度传给原图像
第三行:之所以不采用L2 norm,是因为会产生很大的畸变。
第二步:多步迭代,找到损失函数最大值
之后,采用多步FGSM攻击,找到损失函数最大值,每一步迭代的步长会相应减小,避免步子大了扯到蛋。


第三步:带目标FGSM算法—指鹿为马
通过上述步骤,你已经可以让神经网络不认识熊猫了,那如果我想指定让神经网络把熊猫认成长臂猿呢?就要用到Targeted FGSM攻击,只需用预测输出结果长臂猿y*取代传统FGSM算法中的正确预测结果y,同时最小化损失函数即可。

第四步:集合攻击—集百山之石,攻此山之玉
如何提高黑盒攻击的成功率和模型可迁移性?
- 攻击多个模型的集合,而不是逐个击破。比方说,把ResNet、VGG、Inception三个模型视作单个的大模型一起攻击,再用训练好的模型攻击AlexNet,成功率就会大大提高。可以在模型底层、预测值、损失函数三个层面进行多个模型的集合攻击。
第五步:对抗训练—把真实战场作为训练场
一个防守策略:在训练模型的时候就加上对抗样本(对抗训练)。
对抗样本随模型训练的过程在线生成。由下图可以看出,将对抗样本引入训练数据集,防守模型识别成功率比baseline基准模型大大提升。
top1和top5是什么?
每次识别图片,模型都会给出它认为最像的前五个结果。top1指的是模型认为最像的确实是真实答案的成功率。top5指的是模型认为最像的前五个里有真实答案的成功率。

但对抗训练要耗费数倍的时间,一方面是因为要在线生成对抗样本,一方面是因为要训练模型适应对抗样本。
增强版的对抗训练方法:集合攻击,相当于用五岳他山之石攻此山之玉。比如用ResNet、VGG、LeNet生成的对抗样本去训练Inception。这样训练出的网络非常稳定。但要耗费好几十倍的时间。
3、NIPS2017神经网络攻防竞赛
比赛分组

比赛为三组选手互相进行攻防
- Targeted Attack组:组委会给5000张原图和每张图对应的目标误导结果数据集,指定要求指鹿为马
- Non-targeted Attack组:只要认不出是鹿就行
- Defense组:正确识别被其它组对抗样本攻击的图片
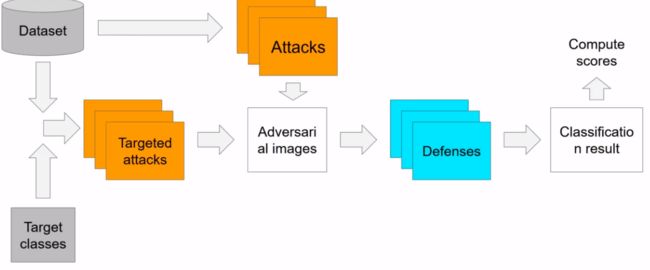
限制条件:
- 攻击步长ε不能超过16:也就是说生成的干扰图片需要非常接近原图,不能看出明显差别。
- 识别图片不能太耗时间:识别100张图片的时间不能超过500s
清华参赛队模型
下图展示了使用FGSM模型进行攻击的测试,横行为攻击模型名称,竖列为防守模型名称,表格中的数字表示对于每1000张攻击图片,防守模型成功防守的图片数目,数字越大,表示竖列模型防守越有效,数字越小,表示横行模型进攻越有效。
红色表示用同一个模型进行攻防(白盒攻击)。
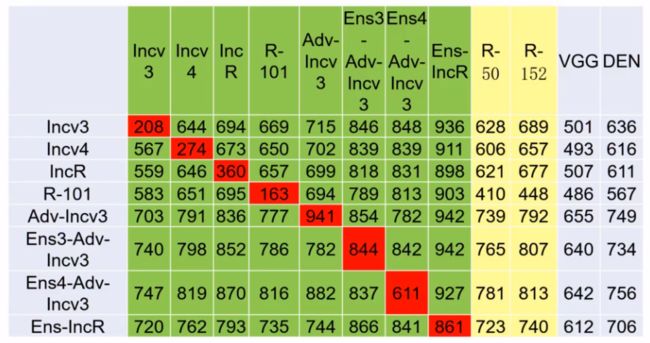
可以看出:
1、白盒攻击成功率远远大于黑盒成功率。提高黑盒攻击的可迁移性,解决跨模型的黑盒攻击是一个重要问题。
2、由Adv-Incv3竖列看出,经过对抗训练之后的防守模型非常强悍。甚至可以达到94.1%的防守成功率。因此,将对抗样本引入训练数据集进行对抗训练是有效的防守策略。
3、由Ens4-Adv-Incv3竖列看出,经过多个模型集合训练之后的防守模型非常强悍。正所谓“用五岳他山之石攻此山之玉”、“曾经沧海难为水”,使用多个深度模型训练出的防守模型必然是集众家之长。
一味提高迭代次数反而适得其反?
由下图可以看出,随着迭代次数的增加,绿色的防守模型很快被攻破,防守成功率大大下降。跟绿色模型有远房亲戚关系的黄色模型也受到了波及。但与绿色亲戚毫无关系的灰色防守模型却屹立不倒,而且随着迭代次数增加,防守成功率反而还提升了。这反映了黑盒攻击时随迭代次数增加的过拟合现象,就好比片面僵化照搬苏联经验到中国,革命事业就会遭遇挫折。
在比赛中,如果防守方选手偷懒,直接提交开源的灰色模型本身,那么攻击方千辛万苦增加迭代次数,消耗计算时间的工作就反而适得其反,为他人作嫁衣裳。
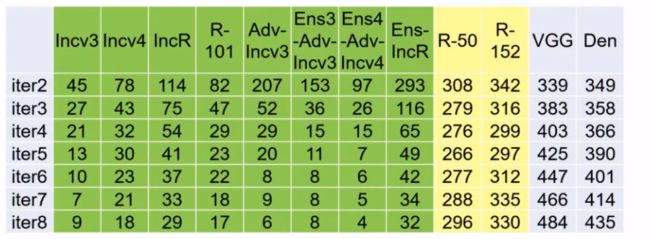
带动量的FGSM算法—放心大胆迭代计算
如何解决这个问题呢?引入Momentum动量的FGSM算法!

随着迭代次数增多,黑盒攻击的成功率终于逐步提高,攻击方可以撸起袖子放心大胆提高迭代次数了。如果偷懒的防守方选择提交baseline基准模型,也能照打不误。
左图展示了传统方法的黑盒攻击,随迭代次数增加,攻击失败率上升。右图展示了引入动量的FGSM方法,随迭代次数增加,攻击失败率下降。


对于指定要求指鹿为马的攻击
模型迁移性一直很差,这很好理解,指鹿为马要求的特异性太高,很难找到一个适应百家深度学习模型的普适对抗样本生成模型。
对抗样本对原图做了什么?噪音!
对抗样本会在原图上增加肉眼很难发现的干扰,但依旧能看得出来和原图的区别:

一个很自然的想法就是,通过像素级别的去噪,把干扰样本图片还原回原来的图片,经过median filter、BM3D等传统去噪方法试验,发现用这些方法破解对抗样本的成功率很低。于是转向使用神经网络。
两种去除噪音的神经网络模型
使用两种不同架构的神经网络去噪:
- Denoising Autoencoder神经网络是常见的去噪卷积神经网络
- Denosing Additive U-Net神经网络在各层网络之间增加了横向连接,力图还原重建出对抗样本噪音本身然后反向叠加到原图上进行去噪。


清华参赛队去噪防守模型训练过程
训练集Image.Net的三万张图片
攻击方式:七种
得到二十一万张对抗样本图片,成为去噪的训练样本

两种去噪模型全都不靠谱
针对白盒攻击和黑盒攻击分别制作了测试集,测试结果如下图:
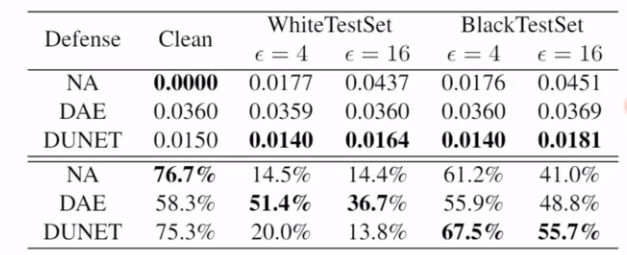
NA表示不进行去噪的空白对照组;DAE表示Denoising Autoencoder神经网络去噪;DUNET表示Denosing Additive U-Net神经网络去噪。Clean表示对未经过对抗样本干扰的干净图片进行攻击。前排数字表示去噪之后剩余的噪音。后排百分数表示去噪防守成功率。
试验发现:
1、相比NA空白对照组,Denoising Autoencoder神经网络反而增加了噪音。
2、相比NA空白对照组,DUNET虽然去除了大部分噪音,却一点儿也没能提高防守成功率。
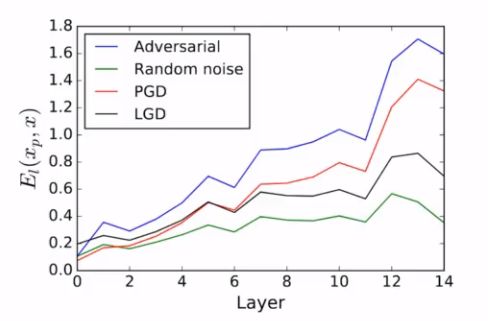
为什么会这样呢?由下图可以看出,随着计算的逐层推进,对抗样本的噪音在逐层放大(蓝线)。而去噪(红线)仅仅部分缩短了对抗样本与空白组(绿线)的距离,大部分噪音依旧存在。

很自然的想法就是将剩余噪音作为损失函数,然后找到它的最小值。
改进的降噪方案—PDG和HGD
下图展示了两种降噪方案:旨在像素级降噪的PGD、旨在识别结果的HGD

HGD的三个变种:
- FGD:每一层CNN提取的特征之间作比较
- LGD:都与最后结果作比较
- CGD:先让CNN预测一个结果,然后与真实值作比较

采用新的降噪方法,防守准确率大大提升,甚至超过了前人的ensV3模型。误差放大现象也得到了很好的修补。

HGD模型的可迁移性:多种模型都适用
新的HGD降噪方法具有良好的迁移性,仅使用了750张训练图片,就达到了很好的防守效果。
不同模型之间互换HGD降噪模型,也能发挥不错的降噪效果。这就好比:虽然自己的帽子戴着最舒坦,但借别人的帽子戴戴也是可以遮风挡雨的嘛。

研究人员进而尝试把不同模型的HGD降噪模型混合,发现效果不如大家统一采用同一个HGD降噪模型。
在最终的比赛中,清华团队提交了四个降噪模型。
HGD网络总结
优点:
- 效果显著比其他队伍的模型好。在比赛中碾压了其它队伍。
- 使用更少的训练图片和更少的训练时间。
- 可迁移好。
缺点:
- 还依赖于微小变化的可测量
- 只有在攻击方不知道防守方采用了HGD去噪方案时才有效
像素层面上的去噪并不能真正去掉噪音
为什么旨在像素级别的降噪方法PGD在真实防守时效果远远不如LGD呢?这张图说明了这个问题。横轴表示图像上的噪声幅值,纵轴表示降噪方法去掉的噪音幅值,在PGD去噪方法中,纵轴只有横轴的一半,也就是PGD方法只去掉一半噪声。而在LGD去噪方法中,噪声基本都被去掉了。

4、参考文献与扩展阅读
【科普】人工智能秒变人工智障:误导神经网络指鹿为马
2018中国计算机大会:人工智能与信息安全分论坛
清华大学团队包揽三项冠军,NIPS 2017对抗样本攻防竞赛总结
Goodfellow最新对抗样本,连人类都分不清是狗是猫
动量迭代攻击和高层引导去噪:对抗样本攻防的新方法
清华大学廖方舟:产生和防御对抗样本的新方法 | 分享总结
两分钟论文:对抗样本同时骗过人类和计算机视觉 @雷锋字幕组
谷歌新论文发现:对抗样本也会骗人
清华参赛队攻击组论文:Boosting Adversarial Attacks with Momentum
清华参赛队防御组论文:Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser
2018中国计算机大会:人工智能与信息安全分论坛
Adversarial Attacks and Defences Competition
Explaining and Harnessing Adversarial Examples
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
作者介绍:
张子豪,同济大学在读研究生。致力于用人类能听懂的语言向大众科普人工智能前沿科技。目前正在制作《说人话的深度学习视频教程》、《零基础入门树莓派趣味编程》等视频教程。西南地区人工智能爱好者高校联盟联合创始人,重庆大学人工智能协会联合创始人。充满好奇的终身学习者、崇尚自由的开源社区贡献者、乐于向零基础分享经验的引路人、口才还不错的程序员。
说人话的零基础深度学习、数据科学视频教程、树莓派趣味开发视频教程等你来看!
微信公众号:子豪兄的科研小屋 Github代码仓库:TommyZihao
同济大学开源软件协会
西南人工智能爱好者联盟
重庆大学人工智能协会