python 全栈开发,Day133(玩具与玩具之间的对话,基于jieba gensim pypinyin实现的自然语言处理,打包apk)
先下载github代码,下面的操作,都是基于这个版本来的!
https://github.com/987334176/Intelligent_toy/archive/v1.6.zip
注意:由于涉及到版权问题,此附件没有图片和音乐。请参考链接,手动采集一下!
请参考链接:
https://www.cnblogs.com/xiao987334176/p/9647993.html#autoid-3-4-0
一、玩具与玩具之间的对话
app消息提醒
之前实现了App发送语音消息给web端玩具,web端有消息提醒。现在app端,也需要消息提醒!
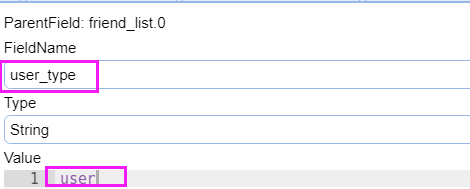
那么在后端,需要判断。这个消息是人还是玩具发送的消息。加一个user_type
玩具表增加user_type
修改玩具表toys。这里的小鱼,表示用户!

增加user_type
toys表的其他记录,也需要一并修改
务必保证 friend_list里面的每一条记录。都有user_type字段!
务必保证,每一个玩具都有2个好友。一个是主人,一个是除自己之外的玩具。
用户表增加user_type
修改用户表

修改第一个好友,增加user_type字段,toy表示玩具

修改另外一条记录

完整数据如下:


{ "_id" : ObjectId("5b9bb768e1253281608e96eb"), "username" : "xiao", "password" : "202cb962ac59075b964b07152d234b70", "age" : "20", "nickname" : "xiao", "gender" : "1", "phone" : "1234567", "avatar" : "boy.jpg", "bind_toy" : [ "5ba0f1f2e12532418089bf88", "5ba21c84e1253229c4acbd12" ], "friend_list" : [ { "friend_id" : "5ba0f1f2e12532418089bf88", "friend_name" : "小可爱", "friend_remark" : "小甜甜", "friend_avatar" : "girl.jpg", "friend_chat" : "5ba0f1f2e12532418089bf87", "user_type" : "toy" }, { "friend_id" : "5ba21c84e1253229c4acbd12", "friend_name" : "嘻嘻", "friend_remark" : "小豆芽", "friend_avatar" : "girl.jpg", "friend_chat" : "5ba21c84e1253229c4acbd11", "user_type" : "toy" } ] }
务必保证 friend_list里面的每一条记录。都有user_type字段!
后台逻辑修改
进入flask项目,修改 serv--> friend.py,增加user_type
from flask import Blueprint, request, jsonify from setting import MONGO_DB from setting import RET from bson import ObjectId fri = Blueprint("fri", __name__) @fri.route("/friend_list", methods=["POST"]) def friend_list(): # 好友列表 user_id = request.form.get("user_id") # 查询用户id信息 res = MONGO_DB.users.find_one({"_id": ObjectId(user_id)}) friend_list = res.get("friend_list") # 获取好友列表 RET["code"] = 0 RET["msg"] = "" RET["data"] = friend_list return jsonify(RET) @fri.route("/add_req", methods=["POST"]) def add_req(): # 添加好友请求 user_id = request.form.get("user_id") # 有可能是 toy_id or user_id friend_id = request.form.get("friend_id") # 100%是toy_id req_type = request.form.get("req_type") req_msg = request.form.get("req_msg") # 描述 remark = request.form.get("remark") # 备注 if req_type == "toy": user_info = MONGO_DB.toys.find_one({"_id": ObjectId(user_id)}) else: user_info = MONGO_DB.users.find_one({"_id": ObjectId(user_id)}) req_str = { "req_user": str(user_info.get("_id")), "req_type": req_type, "req_toy": friend_id, "req_msg": req_msg, "avatar": user_info.get("avatar"), "user_remark": remark, # 昵称,玩具是没有的 "user_nick": user_info.get("nickname") if user_info.get("nickname") else user_info.get("baby_name"), # 状态,1通过,2拒绝,0中间状态(可切换到1和2)。 "status": 0 } MONGO_DB.req.insert_one(req_str) RET["code"] = 0 RET["msg"] = "请求发送成功" RET["data"] = {} return jsonify(RET) @fri.route("/req_list", methods=["POST"]) def req_list(): # 添加请求列表 user_id = request.form.get("user_id") user_info = MONGO_DB.users.find_one({"_id": ObjectId(user_id)}) bind_toy = user_info.get("bind_toy") reqs = list(MONGO_DB.req.find({"req_toy": {"$in": bind_toy}, "status": 0})) for index, req in enumerate(reqs): reqs[index]["_id"] = str(req.get("_id")) RET["code"] = 0 RET["msg"] = "" RET["data"] = reqs return jsonify(RET) @fri.route("/get_req", methods=["POST"]) def get_req(): # 获取一个好友请求 req_id = request.form.get("req_id") req_info = MONGO_DB.req.find_one({"_id": ObjectId(req_id)}) req_info["_id"] = str(req_info.get("_id")) RET["code"] = 0 RET["msg"] = "" RET["data"] = req_info return jsonify(RET) @fri.route("/acc_req", methods=["POST"]) def acc_req(): # 允许一个好友请求 req_id = request.form.get("req_id") remark = request.form.get("remark") req_info = MONGO_DB.req.find_one({"_id": ObjectId(req_id)}) # 1. 为 user 或 toy 添加 toy if req_info.get("req_type") == "toy": user_info = MONGO_DB.toys.find_one({"_id": ObjectId(req_info.get("req_user"))}) user_type = "toy" else: user_info = MONGO_DB.users.find_one({"_id": ObjectId(req_info.get("req_user"))}) user_type = "user" toy = MONGO_DB.toys.find_one({"_id": ObjectId(req_info.get("req_toy"))}) chat_window = MONGO_DB.chat.insert_one({"user_list": [str(toy.get("_id")), str(user_info.get("_id"))]}) friend_info = { "friend_id": str(toy.get("_id")), "friend_name": toy.get("baby_name"), "friend_remark": req_info.get("user_remark"), "friend_avatar": toy.get("avatar"), "friend_chat": str(chat_window.inserted_id), "user_type": "toy" } if req_info.get("req_type") == "toy": MONGO_DB.toys.update_one({"_id": ObjectId(req_info.get("req_user"))}, {"$push": {"friend_list": friend_info}}) else: MONGO_DB.users.update_one({"_id": ObjectId(req_info.get("req_user"))}, {"$push": {"friend_list": friend_info}}) # 2. 为 toy 添加 user 或 toy user_name = user_info.get("nickname") if user_info.get("nickname") else user_info.get("baby_name") friend_info2 = { "friend_id": str(user_info.get("_id")), "friend_name": user_name, # 同意方的备注 "friend_remark": remark if remark else user_name, "friend_avatar": user_info.get("avatar"), "friend_chat": str(chat_window.inserted_id), "user_type":user_type # 用户类型 } MONGO_DB.toys.update_one({"_id": ObjectId(req_info.get("req_toy"))}, {"$push": {"friend_list": friend_info2}}) RET["code"] = 0 RET["msg"] = f"添加好友{remark}成功" RET["data"] = {} MONGO_DB.req.update_one({"_id": ObjectId(req_id)}, {"$set": {"status": 1}}) return jsonify(RET) @fri.route("/ref_req", methods=["POST"]) def ref_req(): # 拒绝一个好友请求 req_id = request.form.get("req_id") MONGO_DB.req.update_one({"_id": ObjectId(req_id)}, {"$set": {"status": 2}}) RET["code"] = 0 RET["msg"] = "已拒绝好友请求" RET["data"] = {} return jsonify(RET)
修改 serv--> devices.py,增加user_type
from flask import Blueprint, request, jsonify from setting import MONGO_DB from setting import RET from bson import ObjectId devs = Blueprint("devs", __name__) @devs.route("/yanzheng_qr", methods=["POST"]) def yanzheng_qr(): # 验证二维码 device_id = request.form.get("device_id") # 获取设备id print(device_id) if MONGO_DB.devices.find_one({"device_id": device_id}): # 从数据库中查询设备id # 查询该玩具是不是已被用户绑定 toy_info = MONGO_DB.toys.find_one({"device_id": device_id}) # 未绑定开启绑定逻辑 if not toy_info: RET["code"] = 0 RET["msg"] = "感谢购买本公司产品" RET["data"] = {} # 如果被绑定加好友逻辑开启 if toy_info: RET["code"] = 1 RET["msg"] = "添加好友" RET["data"] = {"toy_id": str(toy_info.get("_id"))} else: RET["code"] = 2 RET["msg"] = "二货,这不是本公司设备,快去买正版!" RET["data"] = {} return jsonify(RET) @devs.route("/bind_toy", methods=["POST"]) def bind_toy(): # 绑定玩具 chat_window = MONGO_DB.chat.insert_one({}) # 插入一个空数据 chat_id = chat_window.inserted_id # 获取聊天id user_id = request.form.get("user_id") # 用户id res = MONGO_DB.users.find_one({"_id": ObjectId(user_id)}) # 查询用户id是否存在 device_id = request.form.get("device_id") # 设备id toy_name = request.form.get("toy_name") # 玩具的昵称 baby_name = request.form.get("baby_name") # 小主人的名字 remark = request.form.get("remark") # 玩具主人对您的称呼 gender = request.form.get("gender") # 性别 toy_info = { "device_id": device_id, "toy_name": toy_name, "baby_name": baby_name, "gender": gender, "avatar": "boy.jpg" if gender == 1 else "girl.jpg", # 绑定用户 "bind_user": str(res.get("_id")), # 第一个好友 "friend_list": [{ "friend_id": str(res.get("_id")), # 好友id "friend_name": res.get("nickname"), # 好友昵称 "friend_remark": remark, # 好友称呼 "friend_avatar": res.get("avatar"), # 好友头像 "friend_chat": str(chat_id), # 好友聊天id "user_type":"user" # 用户类型 }] } toy_res = MONGO_DB.toys.insert_one(toy_info) # 插入玩具表数据 if res.get("friend_list"): # 判断用户好友列表是否为空 # 追加好友 res["bind_toy"].append(str(toy_res.inserted_id)) res["friend_list"].append({ "friend_id": str(toy_res.inserted_id), "friend_name": toy_name, "friend_remark": baby_name, "friend_avatar": toy_info.get("avatar"), "friend_chat": str(chat_id), "user_type": "toy" # 用户类型 }) else: # 更新好友 res["bind_toy"] = [str(toy_res.inserted_id)] res["friend_list"] = [{ "friend_id": str(toy_res.inserted_id), "friend_name": toy_name, "friend_remark": baby_name, "friend_avatar": toy_info.get("avatar"), "friend_chat": str(chat_id), "user_type": "toy" # 用户类型 }] MONGO_DB.users.update_one({"_id": ObjectId(user_id)}, {"$set": res}) # 更新用户记录 # 更新聊天表 # user_list有2个值。第一个是玩具id,第2个是用户id # 这样,用户和玩具就能通讯了 MONGO_DB.chat.update_one({"_id": chat_id}, {"$set": {"user_list": [str(toy_res.inserted_id), str(res.get("_id"))]}}) RET["code"] = 0 RET["msg"] = "绑定成功" RET["data"] = {} return jsonify(RET)
修改 utils-->baidu_ai.py,增加user_type
from aip import AipSpeech import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 项目根目录 import sys sys.path.append(BASE_DIR) # 加入到系统环境变量中 import setting # 导入setting from uuid import uuid4 # from setting import MONGO_DB # import setting import os from bson import ObjectId client = AipSpeech(setting.APP_ID,setting.API_KEY,setting.SECRET_KEY) def text2audio(text): res = client.synthesis(text, "zh", 1, setting.SPEECH) file_name = f"{uuid4()}.mp3" file_path = os.path.join(setting.CHAT_FILE, file_name) with open(file_path, "wb") as f: f.write(res) return file_name def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def audio2text(file_name): # 识别本地文件 liu = get_file_content(file_name) res = client.asr(liu, 'pcm', 16000, { 'dev_pid': 1536, }) if res.get("result"): return res.get("result")[0] else: return res # text2audio("你好") def my_nlp(q,toy_id): # 1. 假设玩具说:q = 我要给爸爸发消息 print(q,"百度q") if "发消息" in q: toy = setting.MONGO_DB.toys.find_one({"_id":ObjectId(toy_id)}) # print(toy.get("friend_list")) for i in toy.get("friend_list"): # print(i.get("friend_remark"),i.get("friend_name"),'iiiiiiiii') if i.get("friend_remark") in q or i.get("friend_name") in q : res = text2audio(f"可以按消息键,给{i.get('friend_remark')}发消息了") send_str = { "code": 0, "from_user": i.get("friend_id"), "msg_type": "chat", "data": res, "user_type":i.get("user_type") } return send_str if "我要听" in q or "我想听" in q or "唱一首" in q: sources = setting.MONGO_DB.sources.find({}) for i in sources: if i.get("title") in q: send_str = { "code": 0, "from_user": toy_id, "msg_type": "music", "data": i.get("audio") } return send_str res = text2audio("对不起,我没明白你的意思") send_str = { "code": 0, "from_user": toy_id, "msg_type": "chat", "data": res } return send_str
修改 im_serv.py,增加user_type
from flask import Flask, request from geventwebsocket.websocket import WebSocket from geventwebsocket.handler import WebSocketHandler from gevent.pywsgi import WSGIServer import json, os from uuid import uuid4 from setting import AUDIO_FILE,CHAT_FILE from serv import content from utils import baidu_ai from utils import chat_redis import setting from bson import ObjectId import time app = Flask(__name__) user_socket_dict = {} # 空字典,用来存放用户名和发送消息 @app.route("/toy/") def toy(tid): # 玩具连接 # 获取请求的WebSocket对象 user_socket = request.environ.get("wsgi.websocket") # type:WebSocket if user_socket: # 设置键值对 user_socket_dict[tid] = user_socket print(user_socket_dict) # {'123456': } file_name = "" to_user = "" # 循环,接收消息 while True: msg = user_socket.receive() if type(msg) == bytearray: file_name = f"{uuid4()}.wav" file_path = os.path.join(CHAT_FILE, file_name) with open(file_path, "wb") as f: f.write(msg) else: msg_dict = json.loads(msg) to_user = msg_dict.get("to_user") msg_type = msg_dict.get("msg_type") user_type = msg_dict.get("user_type") if to_user and file_name: other_user_socket = user_socket_dict.get(to_user) if msg_type == "ai": q = baidu_ai.audio2text(file_path) print(q) ret = baidu_ai.my_nlp(q, tid) other_user_socket.send(json.dumps(ret)) else: if user_type == "toy": res = setting.MONGO_DB.toys.find_one({"_id": ObjectId(to_user)}) fri = [i.get("friend_remark") for i in res.get("friend_list") if i.get("friend_id") == tid][0] msg_file_name = baidu_ai.text2audio(f"你有来自{fri}的消息") send_str = { "code": 0, "from_user": tid, "msg_type": "chat", "user_type": "toy", "data": msg_file_name } else: send_str = { "code": 0, "from_user": tid, "msg_type": "chat", "data": file_name, } if other_user_socket: # 当websocket连接存在时 chat_redis.save_msg(tid, to_user) # 保存消息到redis # 发送数据 other_user_socket.send(json.dumps(send_str)) else: # 离线消息 chat_redis.save_msg(tid, to_user) # 保存聊天记录到MongoDB _add_chat(tid, to_user, send_str.get("data")) to_user = "" file_name = "" @app.route("/app/") def user_app(uid): # 手机app连接 user_socket = request.environ.get("wsgi.websocket") # type:WebSocket if user_socket: user_socket_dict[uid] = user_socket # { uid : websocket} print(user_socket_dict) file_name = "" to_user = "" while True: # 手机听歌 把歌曲发送给 玩具 1.将文件直接发送给玩具 2.将当前听的歌曲名称或ID发送到玩具 msg = user_socket.receive() if type(msg) == bytearray: # 判断类型为bytearray file_name = f"{uuid4()}.amr" # 文件后缀为amr,安卓和ios通用 file_path = os.path.join(CHAT_FILE, file_name) # 存放在chat目录 print(msg) with open(file_path, "wb") as f: f.write(msg) # 写入文件 # 将amr转换为mp3,因为html中的audio不支持amr os.system(f"ffmpeg -i {file_path} {file_path}.mp3") else: msg_dict = json.loads(msg) to_user = msg_dict.get("to_user") # 获取目标用户 if msg_dict.get("msg_type") == "music": other_user_socket = user_socket_dict.get(to_user) send_str = { "code": 0, "from_user": uid, "msg_type": "music", "data": msg_dict.get("data") } other_user_socket.send(json.dumps(send_str)) # res = content._content_one(content_id) if file_name and to_user: # 如果文件名和发送用户同上存在时 # 查询玩具信息 res = setting.MONGO_DB.toys.find_one({"_id": ObjectId(to_user)}) # 获取friend_remark fri = [i.get("friend_remark") for i in res.get("friend_list") if i.get("friend_id") == uid][0] msg_file_name = baidu_ai.text2audio(f"你有来自{fri}的消息") # 获取websocket对象 other_user_socket = user_socket_dict.get(to_user) # 构造数据 send_str = { "code": 0, "from_user": uid, "msg_type": "chat", # 聊天类型 # 后缀必须是mp3的 "data": msg_file_name } if other_user_socket: chat_redis.save_msg(uid, to_user) # 发送数据给前端页面 other_user_socket.send(json.dumps(send_str)) else: # 保存redis chat_redis.save_msg(uid, to_user) # 添加聊天记录到数据库 _add_chat(uid, to_user, f"{file_name}.mp3") # 最后一定要清空这2个变量,否则造成混乱 file_name = "" to_user = "" def _add_chat(sender, to_user, msg): # 添加聊天记录到数据库 chat_window = setting.MONGO_DB.chat.find_one({"user_list": {"$all": [sender, to_user]}}) if not chat_window.get("chat_list"): chat_window["chat_list"] = [{ "sender": sender, "msg": msg, "updated_at": time.time(), }] res = setting.MONGO_DB.chat.update_one({"_id": ObjectId(chat_window.get("_id"))}, {"$set": chat_window}) else: chat = { "sender": sender, "msg": msg, "updated_at": time.time(), } res = setting.MONGO_DB.chat.update_one({"_id": ObjectId(chat_window.get("_id"))}, {"$push": {"chat_list": chat}}) return res if __name__ == '__main__': # 创建一个WebSocket服务器 http_serv = WSGIServer(("0.0.0.0", 9528), app, handler_class=WebSocketHandler) # 开始监听HTTP请求 http_serv.serve_forever() ''' { "code": 0, "from_user": uid, # APP用户id "data": music_name # 歌曲名 } '''
修改 templates-->index.html,增加user_type
"en"> "UTF-8">Title
"text" id="device_id"/>
"to_user"> "user_type">
重启manager.py和im_serv.py
重新访问网页,让2个玩具开机。左边是小甜甜,右边是小豆芽
为了保证给对方发消息的时候,不造成混乱!
修改 玩具表toys,将toy_name和baby_name改成一样的。
完整数据如下:
/* 1 createdAt:2018/9/19 下午5:53:08*/ { "_id" : ObjectId("5ba21c84e1253229c4acbd12"), "device_id" : "02cc0fc7490b6ee08c31f38ac7a375eb", "toy_name" : "小豆芽", "baby_name" : "小豆芽", "gender" : "2", "avatar" : "girl.jpg", "bind_user" : "5b9bb768e1253281608e96eb", "friend_list" : [ { "friend_id" : "5b9bb768e1253281608e96eb", "friend_name" : "xiao", "friend_remark" : "小鱼", "friend_avatar" : "boy.jpg", "friend_chat" : "5ba21c84e1253229c4acbd11", "user_type" : "user" }, { "friend_id" : "5ba0f1f2e12532418089bf88", "friend_name" : "小甜甜", "friend_remark" : "小甜甜", "friend_avatar" : "girl.jpg", "friend_chat" : "5bab7c19e125327ffc804459", "user_type" : "toy" } ] }, /* 2 createdAt:2018/9/18 下午8:39:14*/ { "_id" : ObjectId("5ba0f1f2e12532418089bf88"), "device_id" : "01f9bf1bac93eddd8397d0455abbeddb", "toy_name" : "小甜甜", "baby_name" : "小甜甜", "gender" : "2", "avatar" : "girl.jpg", "bind_user" : "5b9bb768e1253281608e96eb", "friend_list" : [ { "friend_id" : "5b9bb768e1253281608e96eb", "friend_name" : "xiao", "friend_remark" : "小鱼", "friend_avatar" : "boy.jpg", "friend_chat" : "5ba21c84e1253229c4acbd11", "user_type" : "user" }, { "friend_id" : "5ba21c84e1253229c4acbd12", "friend_name" : "小豆芽", "friend_remark" : "小豆芽", "friend_avatar" : "girl.jpg", "friend_chat" : "5bab7c19e125327ffc804459", "user_type" : "toy" } ] }
修改 用户表users,也是将toy_name和baby_name改成一样的
{ "_id" : ObjectId("5b9bb768e1253281608e96eb"), "username" : "xiao", "password" : "202cb962ac59075b964b07152d234b70", "age" : "20", "nickname" : "xiao", "gender" : "1", "phone" : "1234567", "avatar" : "boy.jpg", "bind_toy" : [ "5ba0f1f2e12532418089bf88", "5ba21c84e1253229c4acbd12" ], "friend_list" : [ { "friend_id" : "5ba0f1f2e12532418089bf88", "friend_name" : "小甜甜", "friend_remark" : "小甜甜", "friend_avatar" : "girl.jpg", "friend_chat" : "5ba0f1f2e12532418089bf87", "user_type" : "toy" }, { "friend_id" : "5ba21c84e1253229c4acbd12", "friend_name" : "小豆芽", "friend_remark" : "小豆芽", "friend_avatar" : "girl.jpg", "friend_chat" : "5ba21c84e1253229c4acbd11", "user_type" : "toy" } ] }
修改 chat表,请确保 主人-->小甜甜-->小豆芽。这3者之间必须要有3条记录!
分别是:
主人--> 小甜甜
主人--> 小豆芽
小甜甜--> 小豆芽
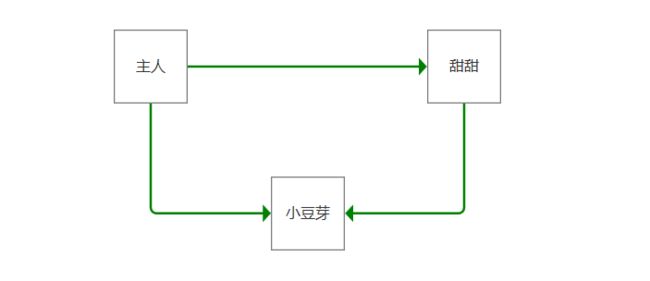
这样,就可以实现3者之间的聊天通信了!
chat完整记录如下:
/* 1 createdAt:2018/9/25 下午9:05:46*/ { "_id" : ObjectId("5baa32aae125320598c912f3"), "user_list" : [ "5ba0f1f2e12532418089bf88", "5ba21c84e1253229c4acbd12" ] }, /* 2 createdAt:2018/9/19 下午5:53:08*/ { "_id" : ObjectId("5ba21c84e1253229c4acbd11"), "user_list" : [ "5b9bb768e1253281608e96eb", "5ba21c84e1253229c4acbd12" ] }, /* 3 createdAt:2018/9/18 下午8:39:14*/ { "_id" : ObjectId("5ba0f1f2e12532418089bf87"), "user_list" : [ "5b9bb768e1253281608e96eb", "5ba0f1f2e12532418089bf88" ] }
进入左边网页,点击 开始废话,说: 发消息给 小豆芽 。再点击发送语音!
网页会说:可以按消息键,给 小豆芽 发消息了!
这里会出现 toy,表示给玩具发消息。左边的id,就是 小豆芽的id

点击 录制消息,说:你好, 我是小甜甜!
点击 发送语音消息

这个时候,网页会有提示: 你有来自 小甜甜 的消息
切换到第二个网页,会出现设备id,这个是 小甜甜的。
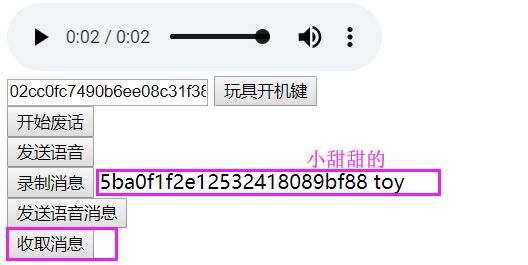
点击 收取消息
![]()
会播放: 你好, 我是小甜甜!
这样,就实现了,玩具之间的通信了!
二、基于jieba gensim pypinyin实现的自然语言处理
jieba
jieba分词,完全开源,有集成的python库,简单易用。
jieba分词是基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG),动态规划查找最大概率路径, 找出基于词频的最大切分组合
安装
pip install gensim
由于包很大,如果安装比较慢,可以使用国内更新源安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
使用
我们通常把这个库叫做 结巴分词 确实是结巴分词,而且这个词库是 made in china , 基本用一下这个结巴分词:
import jieba key_word = "我的妈妈真伟大" # 定义一句话,基于这句话进行分词 cut_word = jieba.cut(key_word) # 使用结巴分词中的cut方法对"我的妈妈真伟大" 进行分词 print(cut_word) #不懂生成器的话,就忽略这里 cut_word_list = list(cut_word) # 如果不明白生成器的话,这里要记得把生成器对象做成列表 print(cut_word_list) # ['我', '的', '妈妈', '真', '伟大']
测试代码就很明显了,它很清晰的把咱们的中文字符串转为列表存储起来了
如果需要将 "真伟大" 变成一个词,需要添加词库,使用add_word
import jieba key_word = "我的妈妈真伟大" # 定义一句话,基于这句话进行分词 jieba.add_word("真伟大") # 添加词库 cut_word = jieba.cut(key_word) # 使用结巴分词中的cut方法对"我的妈妈真伟大" 进行分词 cut_word_list = list(cut_word) # 如果不明白生成器的话,这里要记得把生成器对象做成列表 print(cut_word_list) # ['我', '的', '妈妈', '真伟大']
pypinyin
将汉字转为拼音。可以用于汉字注音、排序、检索(Russian translation) 。
特性
- 根据词组智能匹配最正确的拼音。
- 支持多音字。
- 简单的繁体支持, 注音支持。
- 支持多种不同拼音/注音风格。
安装
pip install pypinyin
使用
from pypinyin import lazy_pinyin,TONE2 key_word = "我的妈妈真伟大" # 定义一句话 res = lazy_pinyin(key_word,style=TONE2) # 设置拼音风格 print(res) # ['wo3', 'de', 'ma1', 'ma1', 'zhe1n', 'we3i', 'da4']
拼音声调是指普通话中的声调,通常叫四声,即阴平(第一声),用“ˉ”表示,如lā;阳平第二声,用“ˊ”表示,如lá;上声(第三声),用“ˇ”表示,如lǎ;去声(第四声),用“ˋ”表示,如;là。
wo3 最后面的3表示声调。它是第三声!
看下面的例子,这些字也是同音
from pypinyin import lazy_pinyin,TONE2 key_word = "贝贝蓓蓓背背" # 定义一句话 res = lazy_pinyin(key_word,style=TONE2) # 设置拼音风格 print(res) # ['be4i', 'be4i', 'be4i', 'be4i', 'be4i', 'be4i']
gensim
Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。
它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,
支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口
基本概念
-
语料(Corpus):一组原始文本的集合,用于无监督地训练文本主题的隐层结构。语料中不需要人工标注的附加信息。在Gensim中,Corpus通常是一个可迭代的对象(比如列表)。每一次迭代返回一个可用于表达文本对象的稀疏向量。
-
向量(Vector):由一组文本特征构成的列表。是一段文本在Gensim中的内部表达。
-
稀疏向量(SparseVector):通常,我们可以略去向量中多余的0元素。此时,向量中的每一个元素是一个(key, value)的元组
-
模型(Model):是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。
安装
pip install jieba
使用
这个训练库很厉害, 里面封装很多机器学习的算法, 是目前人工智能的主流应用库,这个不是很好理解, 需要一定的Python数据处理的功底
import jieba import gensim from gensim import corpora from gensim import models from gensim import similarities l1 = ["你的名字是什么", "你今年几岁了", "你有多高你心情怎么样", "你心情怎么样"] a = "你今年多大了" # 制作语料库 all_doc_list = [] for doc in l1: doc_list = [word for word in jieba.cut(doc)] all_doc_list.append(doc_list) print(all_doc_list) #[['你', '的', '名字', '是', '什么'], # 1 4 2 3 0 # ['你', '今年', '几岁', '了'], # 1 6 7 5 # 将问题分词 doc_test_list = [word for word in jieba.cut(a)] #['你', '今年', '多大', '了'] # 1 6 5 # 制作词袋 dictionary = corpora.Dictionary(all_doc_list) # 词袋的理解 # 词袋就是将很多很多的词,进行排列形成一个 词(key) 与一个 标志位(value) 的字典 # 例如: {'什么': 0, '你': 1, '名字': 2, '是': 3, '的': 4, '了': 5, '今年': 6, '几岁': 7, '多': 8, '心情': 9, '怎么样': 10, '有': 11, '高': 12} # 至于它是做什么用的,带着问题往下看 print("token2id", dictionary.token2id) print("dictionary", dictionary, type(dictionary)) corpus = [dictionary.doc2bow(doc) for doc in all_doc_list] # 语料库: # 这里是将all_doc_list 中的每一个列表中的词语 与 dictionary 中的Key进行匹配 # 得到一个匹配后的结果,例如['你', '今年', '几岁', '了'] # 就可以得到 [(1, 1), (6, 1), (7, 1), (5, 1)] # 1代表的的是 你 1代表出现一次, 5代表的是 了 1代表出现了一次, 以此类推 6 = 今年 , 7 = 几岁 print("corpus", corpus, type(corpus)) # 将需要寻找相似度的分词列表 做成 语料库 doc_test_vec doc_test_vec = dictionary.doc2bow(doc_test_list) print("doc_test_vec", doc_test_vec, type(doc_test_vec)) # 将corpus语料库(初识语料库) 使用Lsi模型进行训练 lsi = models.LsiModel(corpus) # 这里的只是需要学习Lsi模型来了解的,这里不做阐述 print("lsi", lsi, type(lsi)) # 语料库corpus的训练结果 print("lsi[corpus]", lsi[corpus]) # 获得语料库doc_test_vec 在 语料库corpus的训练结果 中的 向量表示 print("lsi[doc_test_vec]", lsi[doc_test_vec]) # 文本相似度 # 稀疏矩阵相似度 将 主 语料库corpus的训练结果 作为初始值 index = similarities.SparseMatrixSimilarity(lsi[corpus], num_features=len(dictionary.keys())) print("index", index, type(index)) # 将 语料库doc_test_vec 在 语料库corpus的训练结果 中的 向量表示 与 语料库corpus的 向量表示 做矩阵相似度计算 sim = index[lsi[doc_test_vec]] print("sim", sim, type(sim)) # 对下标和相似度结果进行一个排序,拿出相似度最高的结果 # cc = sorted(enumerate(sim), key=lambda item: item[1],reverse=True) cc = sorted(enumerate(sim), key=lambda item: -item[1]) print(cc) text = l1[cc[0][0]] print(a,text)
执行输出:
[['你', '的', '名字', '是', '什么'], ['你', '今年', '几岁', '了'], ['你', '有', '多', '高', '你', '心情', '怎么样'], ['你', '心情', '怎么样']] token2id {'什么': 0, '你': 1, '名字': 2, '是': 3, '的': 4, '了': 5, '今年': 6, '几岁': 7, '多': 8, '心情': 9, '怎么样': 10, '有': 11, '高': 12} dictionary Dictionary(13 unique tokens: ['什么', '你', '名字', '是', '的']...) <class 'gensim.corpora.dictionary.Dictionary'> corpus [[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1)], [(1, 1), (5, 1), (6, 1), (7, 1)], [(1, 2), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1)], [(1, 1), (9, 1), (10, 1)]] <class 'list'> doc_test_vec [(1, 1), (5, 1), (6, 1)] <class 'list'> lsi LsiModel(num_terms=13, num_topics=200, decay=1.0, chunksize=20000) <class 'gensim.models.lsimodel.LsiModel'> lsi[corpus]lsi[doc_test_vec] [(0, 0.900230201263672), (1, 0.3426436202483724), (2, -1.1659919622685817)] index <class 'gensim.similarities.docsim.SparseMatrixSimilarity'> sim [0.2956978 0.99180055 0.44080025 0.38174424] <class 'numpy.ndarray'> [(1, 0.99180055), (2, 0.44080025), (3, 0.38174424), (0, 0.2956978)] 你今年多大了 你今年几岁了
噼里啪啦写了这一堆代码,到底干了啥哟?看了一脸懵逼!
大概意思就是。我抛出了一个问题,就是变量a
你今年多大了
在问题库里面,有这些问题
["你的名字是什么", "你今年几岁了", "你有多高你心情怎么样", "你心情怎么样"]
经过 矩阵相似度计算之后,得到一个最优的结果
你今年几岁了
也就是说,我问:你今年多大了,机器认为我的问题是:你今天几岁了
这2句话,其实是一个意思!
集成到flask
进入flask项目,进入utils目录,新建文件lowB_plus.py
import jieba import setting from gensim import corpora from gensim import models from gensim import similarities l1 = [] for i in setting.MONGO_DB.sources.find({}): l1.append(i.get("title")) def my_nlp(text): # 制作语料库 all_doc_list = [] for doc in l1: doc_list = [word for word in jieba.cut(doc)] all_doc_list.append(doc_list) print(all_doc_list) # [['你', '的', '名字', '是', '什么'], # 1 4 2 3 0 # ['你', '今年', '几岁', '了'], # 1 6 7 5 # ['你', '有', '多', '高', '你', '胸多大'], # 1 9 8 11 1 10 # ['你', '胸多大']] # 1 10 # 将问题分词 doc_test_list = [word for word in jieba.cut(text)] print(doc_test_list) # ['你', '今年', '多大', '了'] # 1 6 5 # 制作词袋 dictionary = corpora.Dictionary(all_doc_list) # 词袋的理解 # 词袋就是将很多很多的词,进行排列形成一个 词(key) 与一个 标志位(value) 的字典 # 例如: {'什么': 0, '你': 1, '名字': 2, '是': 3, '的': 4, '了': 5, '今年': 6, '几岁': 7, '多': 8, '有': 9, '胸多大': 10, '高': 11} # 至于它是做什么用的,带着问题往下看 print("token2id", dictionary.token2id) print("dictionary", dictionary, type(dictionary)) corpus = [dictionary.doc2bow(doc) for doc in all_doc_list] # 语料库: # 这里是将all_doc_list 中的每一个列表中的词语 与 dictionary 中的Key进行匹配 # 得到一个匹配后的结果,例如['你', '今年', '几岁', '了'] # 就可以得到 [(1, 1), (5, 1), (6, 1), (7, 1)] # 1代表的的是 你 1代表出现一次, 5代表的是 了 1代表出现了一次, 以此类推 6 = 今年 , 7 = 几岁 print("corpus", corpus, type(corpus)) # 将需要寻找相似度的分词列表 做成 语料库 doc_test_vec doc_test_vec = dictionary.doc2bow(doc_test_list) print("doc_test_vec", doc_test_vec, type(doc_test_vec)) # [(1, 1), (5, 1), (6, 1)] # 将corpus语料库(初识语料库) 使用Lsi模型进行训练 lsi = models.LsiModel(corpus) # 这里的只是需要学习Lsi模型来了解的,这里不做阐述 print("lsi", lsi, type(lsi)) # 语料库corpus的训练结果 print("lsi[corpus]", lsi[corpus]) # 获得语料库doc_test_vec 在 语料库corpus的训练结果 中的 向量表示 print("lsi[doc_test_vec]", lsi[doc_test_vec]) # 文本相似度 # 稀疏矩阵相似度 将 主 语料库corpus的训练结果 作为初始值 index = similarities.SparseMatrixSimilarity(lsi[corpus], num_features=len(dictionary.keys())) print("index", index, type(index)) # 向量表示: # (0.387654321,0.84382974,0.4297589245,1.2439785,3.9867462154) # ((0.387654321,0.84382974,0.4297589245,1.2439786,3.9867462154),(0.387654321,0.84382974,0.4297589245,1.2439786,3.9867462154),(0.387654321,0.84382974,0.4297589245,1.2439786,3.9867462154),(0.387654321,0.84382974,0.4297589245,1.2439786,3.9867462154)) # 将 语料库doc_test_vec 在 语料库corpus的训练结果 中的 向量表示 与 语料库corpus的 向量表示 做矩阵相似度计算 sim = index[lsi[doc_test_vec]] print("sim", sim, type(sim)) # 对下标和相似度结果进行一个排序,拿出相似度最高的结果 # cc = sorted(enumerate(sim), key=lambda item: item[1],reverse=True) cc = sorted(enumerate(sim), key=lambda item: -item[1]) print(cc) text = l1[cc[0][0]] return text
由于还不够智能,所以叫 lowB_plus
修改 utils-->baidu_ai.py,使用 lowB_plus
from aip import AipSpeech import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 项目根目录 import sys sys.path.append(BASE_DIR) # 加入到系统环境变量中 import setting # 导入setting from uuid import uuid4 # from setting import MONGO_DB # import setting import os from bson import ObjectId from utils import lowB_plus from pypinyin import lazy_pinyin, TONE2 client = AipSpeech(setting.APP_ID,setting.API_KEY,setting.SECRET_KEY) def text2audio(text): res = client.synthesis(text, "zh", 1, setting.SPEECH) file_name = f"{uuid4()}.mp3" file_path = os.path.join(setting.CHAT_FILE, file_name) with open(file_path, "wb") as f: f.write(res) return file_name def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def audio2text(file_name): # 识别本地文件 liu = get_file_content(file_name) res = client.asr(liu, 'pcm', 16000, { 'dev_pid': 1536, }) if res.get("result"): return res.get("result")[0] else: return res # text2audio("你好") def my_nlp(q,toy_id): # 1. 假设玩具说:q = 我要给爸爸发消息 if "发消息" in q: q = "".join(lazy_pinyin(q, style=TONE2)) print(q) toy = setting.MONGO_DB.toys.find_one({"_id": ObjectId(toy_id)}) # print(toy.get("friend_list")) for i in toy.get("friend_list"): # 转换成拼音,即使同音字也能匹配 remark_pinyin = "".join(lazy_pinyin(i.get("friend_remark"), style=TONE2)) name_pinyin = "".join(lazy_pinyin(i.get("friend_name"), style=TONE2)) print(name_pinyin) if remark_pinyin in q or name_pinyin in q: res = text2audio(f"可以按消息键,给{i.get('friend_remark')}发消息了") send_str = { "code": 0, "from_user": i.get("friend_id"), "msg_type": "chat", "data": res, "user_type":i.get("user_type") } return send_str if "我要听" in q or "我想听" in q or "唱一首" in q: q = str(q).replace("我要听", "") q = str(q).replace("我想听", "") q = str(q).replace("唱一首", "") print(q) title = lowB_plus.my_nlp(q) sources = setting.MONGO_DB.sources.find_one({"title": title}) for i in sources: if i.get("title") in q: send_str = { "code": 0, "from_user": toy_id, "msg_type": "music", "data": i.get("audio") } return send_str res = text2audio("对不起,我没明白你的意思") send_str = { "code": 0, "from_user": toy_id, "msg_type": "chat", "data": res } return send_str
测试
重启 manager.py和im_serv.py
重新访问网页,让2个玩具开机。左边是小甜甜,右边是小豆芽

使用 小甜甜给小豆芽发送消息。注意:说话的时候,可以使用儿化音。
比如:发消息 给 小豆芽儿
查看Pycharm控制台输出:
发消息给小豆芽儿
fa1xia1oxi1ge3ixia3odo4uya2e2r
第二个网页,小豆芽,也可以接收消息!
测试同音字
打开玩具表toys,找到 小甜甜的记录,将小豆芽,改成晓逗牙
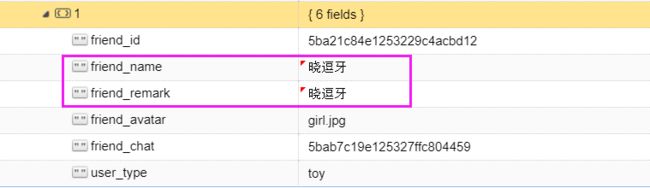
再次测试发送语音给 小豆芽
小豆芽,一样也可以收到消息!
注意:尽可能避免多音字。否则会无法匹配到!
接入图灵
如果说别的话,比如:今天天气怎么样?网页会提示: 对不起,我没明白你的意思
这样用户体验不好,那么这种匹配不到的问题,扔给图灵来处理就可以了!
修改 setting.py,增加图灵配置
import pymongo import os import redis # 数据库配置 client = pymongo.MongoClient(host="127.0.0.1", port=27017) MONGO_DB = client["bananabase"] REDIS_DB = redis.Redis(host="127.0.0.1",port=6379) RET = { # 0: false 2: True "code": 0, "msg": "", # 提示信息 "data": {} } XMLY_URL = "http://m.ximalaya.com/tracks/" # 喜马拉雅链接 CREATE_QR_URL = "http://qr.liantu.com/api.php?text=" # 生成二维码API # 文件目录 AUDIO_FILE = os.path.join(os.path.dirname(__file__), "audio") # 音频 AUDIO_IMG_FILE = os.path.join(os.path.dirname(__file__), "audio_img") # 音频图片 DEVICE_CODE_PATH = os.path.join(os.path.dirname(__file__), "device_code") # 二维码 CHAT_FILE = os.path.join(os.path.dirname(__file__), "chat") # 聊天 # 百度AI配置 APP_ID = '11793552' API_KEY = 'uA6sToQWcvYt2lT6qTW6WFrG' SECRET_KEY = '5rZ1XGYMV39LQBVT4Y1yLNCsmueVe8RQ' SPEECH = { "spd": 4, 'vol': 5, "pit": 8, "per": 4 } #图灵配置: TL_URL = "http://openapi.tuling123.com/openapi/api/v2" TL_DATA = { # 请求的类型 0 文本 1 图片 2 音频 "reqType": 0, # // 输入信息(必要参数) "perception": { # 文本信息 "inputText": { # 问题 "text": "北京未来七天,天气怎么样" } }, # 用户必要信息 "userInfo": { # 图灵机器人的apikey "apiKey": "8fc493d348704ba4af5413e67e6fc90b", # 用户唯一标识 "userId": "xiao" } }
进入utils目录,新建文件 tuling.py
import requests import json from setting import TL_URL as tuling_url from setting import TL_DATA as data def to_tuling(q,user_id): data["perception"]["inputText"]["text"] = q data["userInfo"]["userId"] = user_id res = requests.post(tuling_url, json=data) res_dic = json.loads(res.content.decode("utf8")) # type:dict res_type = res_dic.get("results")[0].get("resultType") result = res_dic.get("results")[0].get("values").get(res_type) print(result) return result
修改 utils-->baidu_ai.py,接入图灵
from aip import AipSpeech import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 项目根目录 import sys sys.path.append(BASE_DIR) # 加入到系统环境变量中 import setting # 导入setting from uuid import uuid4 # from setting import MONGO_DB # import setting import os from bson import ObjectId from utils import lowB_plus from pypinyin import lazy_pinyin, TONE2 from utils import tuling client = AipSpeech(setting.APP_ID,setting.API_KEY,setting.SECRET_KEY) def text2audio(text): res = client.synthesis(text, "zh", 1, setting.SPEECH) file_name = f"{uuid4()}.mp3" file_path = os.path.join(setting.CHAT_FILE, file_name) with open(file_path, "wb") as f: f.write(res) return file_name def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def audio2text(file_name): # 识别本地文件 liu = get_file_content(file_name) res = client.asr(liu, 'pcm', 16000, { 'dev_pid': 1536, }) if res.get("result"): return res.get("result")[0] else: return res # text2audio("你好") def my_nlp(q,toy_id): # 1. 假设玩具说:q = 我要给爸爸发消息 if "发消息" in q: q = "".join(lazy_pinyin(q, style=TONE2)) print(q) toy = setting.MONGO_DB.toys.find_one({"_id": ObjectId(toy_id)}) # print(toy.get("friend_list")) for i in toy.get("friend_list"): # 转换成拼音,即使同音字也能匹配 remark_pinyin = "".join(lazy_pinyin(i.get("friend_remark"), style=TONE2)) name_pinyin = "".join(lazy_pinyin(i.get("friend_name"), style=TONE2)) print(name_pinyin) if remark_pinyin in q or name_pinyin in q: res = text2audio(f"可以按消息键,给{i.get('friend_remark')}发消息了") send_str = { "code": 0, "from_user": i.get("friend_id"), "msg_type": "chat", "data": res, "user_type":i.get("user_type") } return send_str if "我要听" in q or "我想听" in q or "唱一首" in q: q = str(q).replace("我要听", "") q = str(q).replace("我想听", "") q = str(q).replace("唱一首", "") print(q) title = lowB_plus.my_nlp(q) sources = setting.MONGO_DB.sources.find_one({"title": title}) for i in sources: if i.get("title") in q: send_str = { "code": 0, "from_user": toy_id, "msg_type": "music", "data": i.get("audio") } return send_str answer = tuling.to_tuling(q, toy_id) res = text2audio(answer) send_str = { "code": 0, "from_user": toy_id, "msg_type": "chat", "data": res } return send_str
重启 manager.py和im_serv.py
让2个玩具开机,说一段话: 上海的天气怎么样
网页会播放: 上海:周四,多云转阴 东北风4-5级,最低气温22度,最高气温27度
查看Pycharm控制台输出:
上海的天气怎么样
上海:周四,多云转阴 东北风4-5级,最低气温22度,最高气温27度
三、打包apk
单击打原生安装包

必须要登录账号才行
注意:默认是使用HBuilder的图标,这样不好。

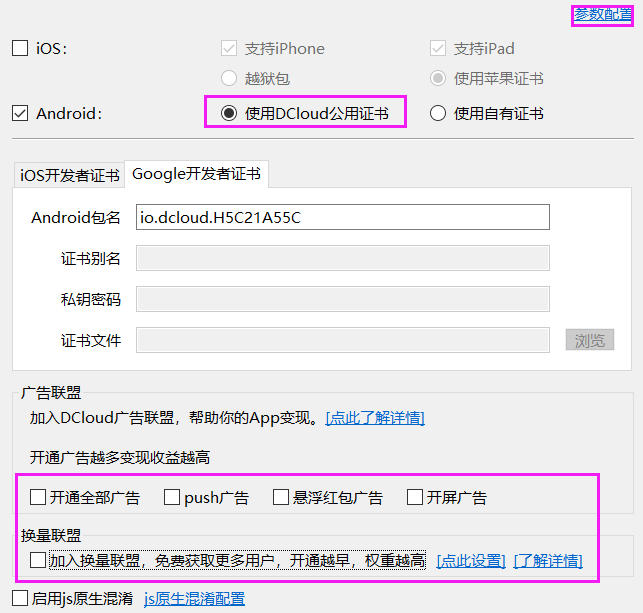
点击android。因为苹果要相关证书才行,我没有。
去掉下面的广告。点击参数配置
输入应用名称

点击图标配置

上传一个图标图片,必须是png格式的!

点击自动生成并替换
点击启动图片配置,就是 app启动的时候,加载的图片

找到android,选择1080p图片,并上传!

这里有很多sdk,可以配置

这里都不用sdk
点击模块权限配置

默认是这些权限,右侧可以增加

点击代码视图
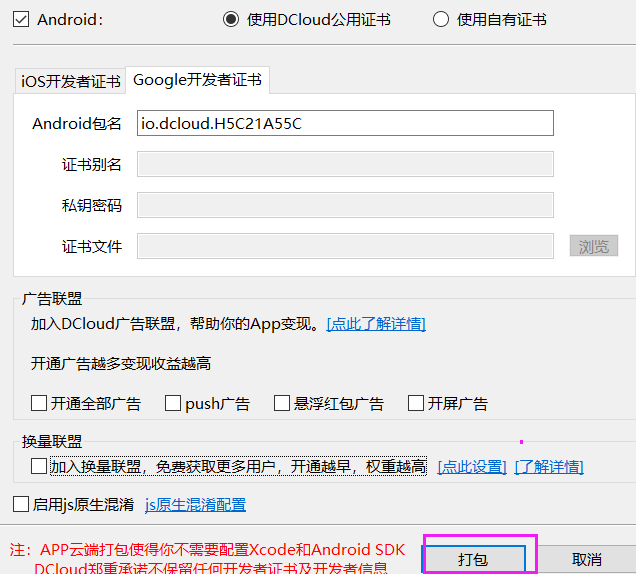
这个,就是刚刚所有的配置, 使用Ctrl+s 进行保存

保存就是这个文件
![]()
重新点击 打原生安装包
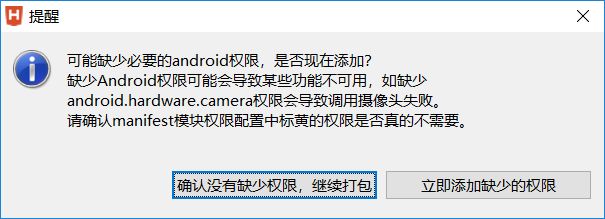
点击忽略

点击确认
它就会在云端打包,它会给你加一个壳子

如果提示报错
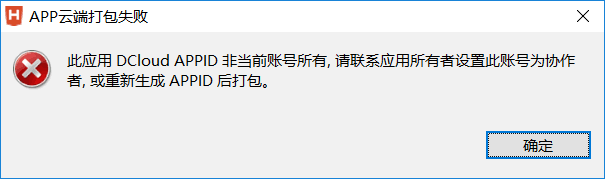
点击 重新打包原生,点击参数配置,在这类,重新云端获取!

打包成功后,查看打包状态
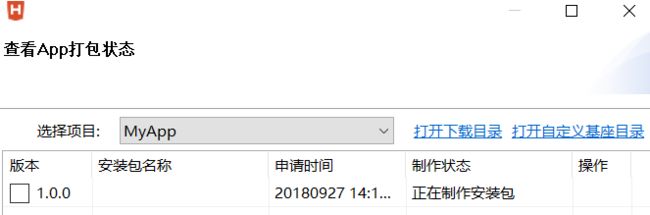
这样,表示成功了!

点击手动下载,下载成功!

直接将apk拖动过去,点击应用

效果如下:
总结:
1.说说你智能玩具的项目: 目的:关爱留守儿童, 让玩具成为父母间沟通的桥梁, 让玩具成为孩子的玩伴 实现无屏社交,依靠孩子的语音指令做出响应,例如我要和爸爸聊天,玩具会提示可以和爸爸聊天了并打开与app通讯的链接 我要听世上只有妈妈好,玩具就会依照指令播放相应的内容 2.智能玩具有什么功能: 功能: 玩具可以语音点播朗诵诗歌,播放音乐,做游戏-成语接龙,与智能机器人聊天,玩具与玩具之间的通讯 手机app的im通讯 ,手机app可以为玩具点播歌曲,通过手机app管理玩具 高人: 3.智能部分使用了什么算法: 两种回答: 1.使用百度ai中的语音合成和语音识别,点播功能是使用Gensim jieba 库进行训练的,聊天做游戏是用的图灵机器人+百度语音合成 2.使用百度ai中的语音合成和语音识别 NLP自然语言处理 点播功能基于百度NLP,聊天做游戏是用的图灵机器人+百度语音合成 4.IM通讯使用了什么机制: Websocket magicString 5.手机app是怎么做的(使用什么方式): mui + html5plus 6.谈谈你对人工智能的理解(说出人工智能技术的关键字至少5个): 语音类 : 语音识别 语音合成 图像类 : 图像识别 文字识别 人脸识别 视频审核 语言类 : 自然语言处理 机器翻译 词法分析 依存句法分析 文本纠错 对话情绪识别 词向量表示 短文本相似度 词义相似度 情感倾向分析 7.mongodb相关: 1.修改器: $push $set $pull $inc $pop 2.说说你对 $ 的理解 : $ 我的理解就是代指符号,代指所查询到的数据或索引位置 3.Mongodb中的数据类型 : ObjectID String Boolean Integer Double Arrays Object(Dict) Null Timestamp Date 4.mongodb的比较符 : $lt $gt $lte $gte ":" 8.公司组织架构: 1.综合人力财务行政:1个小姐姐 2.营销部:老张 3.产品部:老李 + UI小姐姐 4.软件部:闫帅 + 前端小姐姐 + 我 5.硬件部:江老师 9.项目不做底层,只使用三方的原因: 制作底层大量占用人力,公司资金不足以支撑底层研发 将大量成本投入到硬件研发中 10. 项目中,涉及到的技术 智能语音识别 - 第三方百度ai 开机提示 自然语言处理(nlp) 点歌 :内容点播 开启消息发送 基于通讯录的即时通讯(IM) websocket 不用第三方的原因 保护隐私 管理玩具的功能: 1.通过扫描二维码 绑定玩具 2.玩具通讯录管理
完整终极代码,请参考github:
https://github.com/987334176/Intelligent_toy/archive/v1.7.zip
附带项目需要的所有文件,包括音频,图片,数据库等等