备战秋招——常规算法笔试题集锦(持续更新)
1.任何一个递归过程都可以转换成非递归过程(✓)
2.Hanoi问题
假设 个盘子的Hanoi问题需要
个盘子的Hanoi问题需要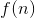 次操作来完成,三根柱子分别为A,B,C,则实现算法主要分为三个步骤:
次操作来完成,三根柱子分别为A,B,C,则实现算法主要分为三个步骤:
1)把n-1个盘子由 A 移到 B
2)把第n个盘子 由 A 移到 C
3)把n-1个盘子由 B 移到 C
可以看出,此问题是一个递归问题:![]() 。
。
个盘子的Hanoi问题的总移动次数为: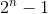 。
。
3.设哈希表长为11,哈希函数为Hash (key)=key%11。存在关键码{43,7,29,22,16,92,44,8,19},采用二次探测法处理冲突,建立的hash表为
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 22 | 44 | 92 | 16 | 19 | 7 | 29 | 8 | 43 |
采用开放定址法处理冲突中的二次探测再散列(也即是题目中的二元探测法),哈希函数变为![]()
对于43,代入公式为Hash(43) = 43 % 11 = 10, 则地址为10;
对于7,代入公式为Hash(7) = 7 % 11 = 7,则地址为7;
对于29,代入公式为Hash(29) = 29 % 11 = 7, 与7冲突,则采用二次探测进行消除冲突, 继续(7 + 1) % 11 = 8,没有冲突,则地址为8;
对于22,代入公式Hash(22) = 22 % 11 = 0, 则地址为0;
对于16,代入公式Hash(16) = 16 % 11 = 5, 则地址为5;
对于92,代入公式Hash(92) = 92 % 11 = 4,则地址为4;
对于44,代入公式Hash(44) = 44 % 11 = 0, 与22的地址冲突,则继续(0 + 1) % 11 = 1,没有冲突,则地址为1;
对于8, 代入公式Hash(8) = 8 % 11 = 8, 与29有冲突,则继续(8 + 1) % 11 = 9, 没有冲突,则地址为9;
对于19,代入公式Hash(19) = 19 % 11 = 8. 与 29有冲突,则继续(8 + 1) * 11 = 9, 与8有冲突,继续(8 - 1) % 11 = 7, 与7有冲突,则继续(8 + 4) % 11 = 1, 与44有冲突,则继续(8 - 4) % 11 = 4, 与92有冲突,则继续(8 + 9) % 11 = 6, 没有冲突,则地址为6。
4.有关希尔排序算法叙述正确的是( AB )
A. 最后一次的步长增量一定为1
B. 分割后子序列内部的排序算法是直接插入排序
C. 分割后子序列内部的排序算法是直接选择排序
D. 希尔排序是稳定排序算法
希尔排序时间复杂度最坏情况是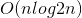 ,最好情况是
,最好情况是 。希尔排序没有快速排序算法快
。希尔排序没有快速排序算法快 ![]() ,因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比
,因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比 复杂度的算法快得多。
复杂度的算法快得多。
5.广义表K=(m,n,(p,(q,s)),(h,f)),则head[tail[head[tail[tail(K)]]]]的值为( q )
tail(K) = (n,(p,(q,s)),(h,f))
tail[tail(K)] = ((p,(q,s)),(h,f))
head[tail[tail(K)]] = (p,(q,s))
tail[head[tail[tail(K)]]] = (q,s)
head[tail[head[tail[tail(K)]]]] = q
6.在一个空的5阶B-树中依次插入关键字序列{6,8,15,16,22,10,18,32,20},插入完成后,关键字6所在结点包含的关键字个数为( 3 )
B树又叫平衡多路查找树。一棵m阶的B树的特性如下:
1. 树中每个结点最多含有m个孩子(m >= 2)
2. 除根结点和叶子结点外,其它每个结点至少有ceil(m / 2)个孩子
3. 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根节点为叶子结点,整棵树只有一个根结点)
4. 所有叶子都出现在同一层
5. 每个非终端结点中包含有n个关键字信息:![]() 其中 (1)n为该结点的关键字的总个数,满足ceil(m/2) - 1 <= n <= m -1 (2)ki(i = 1, .., n)为关键字,且关键字按升序排序 (3)pi为指向子树根的结点,且指针p(i-1)指向子树中所有结点的关键字均小于ki,但都大于k(i-1)。
其中 (1)n为该结点的关键字的总个数,满足ceil(m/2) - 1 <= n <= m -1 (2)ki(i = 1, .., n)为关键字,且关键字按升序排序 (3)pi为指向子树根的结点,且指针p(i-1)指向子树中所有结点的关键字均小于ki,但都大于k(i-1)。
插入时首先插入6,8,15,16; 再插入22时结点个数大于4,因此取15为中间结点拆分,变成15 - (6,8),(16,22),继续插入10,18,32变成15 - (6,8,10),(16,18,22,32),再插入20时结点个数大于4,取20为中间结点拆分,合并到根节点上变为(15,20) - (6,8,10),(16,18),(22,32)。
7. 在求两个集合并集的过程中,可能需用到的操作是( ABCD )
A. 取元素
B. 插入元素
C. 比较操作
D. 求表长
求表长的原因暂搁,之后更新
8.TCP协议与UDP协议负责端到端连接,下列那些信息只出现在TCP报文,UDP报文不包含此信息( AD )
A. 序列号
B. 源端口
C. 目标端口
D. 窗口大小
这道题说明了一个问题,本科时候的计算机网络一定要好好学。TCP和UDP是OSI模型中的运输层中的协议。TCP提供可靠的通信传输,需要三次握手建立连接。而UDP是一个非连接的协议,传输数据之前源端和终端不建立连接,当它想传送时就简单地去抓取来自应用程序的数据,并尽可能快地把它扔到网络上。UDP吞吐量不受拥挤控制算法的调节,只受应用软件生成数据的速率、传输带宽、源端和终端主机性能的限制。
TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。UDP信息包的标题很短,只有8个字节,相对于TCP的20个字节信息包的额外开销很小。TCP对系统资源的要求较多,UDP对系统资源的要求较少。
UDP的包头结构:
源端口 16位
目的端口 16位
长度 16位
校验和 16位
TCP的包头结构:
源端口 16位
目标端口 16位
序列号 32位
回应序号 32位
TCP头长度 4位
reserved 6位
控制代码 6位
窗口大小 16位
偏移量 16位
校验和 16位
选项 32位(可选)
9. 程序员编写程序时使用文件系统提供的系统调用将内存中由address地址开始的n个字节或n个记录的信息写入指定文件中,但发现文件名不可用,可行的解决办法是( AB )
A. 使用文件描述符代替文件名
B. 使用文件句柄代替文件名
C. 使用当前进程的PCB编号代替
D. 以上办法都不可行
无论是文件句柄(Windows中概念),还是文件描述符(Linux中概念),其最终目的都是用来定位打开的文件在内存中的位置,只是他们的映射方式不一样。文件句柄定位到的是文件对象,而非文件。而文件对象是对这个文件的一些状态、属性的封装,例如读到的文件位置等。
10.某软件公司正在升级一套水务管理系统。该系统用于县市级供排水企业、供水厂、排水厂中水务数据的管理工作。系统经重新整合后,开发人员决定不再使用一张备份数据表waterinfo001表,需永久删除。符合要求的语句是:( C )
A. DELETE TABLE waterinfo001
B. DELETE FROM TABLE waterinfo001
C. DROP TABLE waterinfo001
D. DROP FROM TABLE waterinfo001
drop table:删除内容和定义,释放空间,简单来说是把整个表都去掉
truncate table:删除内容,释放空间,不删除定义,简单来说只是清空表的数据
drop table:每次删除一行数据
11.32位系统线程最大内存为(4GB)
以32位Windows为例,最大内存寻址空间为4G。
系统分前半部分(2G)作为进程私有空间;后半部分(2G)作为公用空间,用来存放内核代码、驱动代码、IO缓存区。
12.下面关于Adaboost算法的描述中,错误的是( D )
A. AdaBoost模型是弱分类器的线性组合
B. 提升树是以分类树或者回归树为基本分类器的提升办法,提升树被认为是统计学系中最有效的办法之一
C. AdaBoost算法的一个解释是该算法实际上是前向分步算法的一个实现,在这个方法里,模型是加法模型,损失函数是指数损失,算法是前向分步算法
D. AdaBoost同时独立地学习多个分类器
有关Adaboost,参考:
https://wizardforcel.gitbooks.io/dm-algo-top10/content/adaboost.html
https://zhuanlan.zhihu.com/p/39972832
有关提升树(Boosting Tree),参考:
https://www.cnblogs.com/daguankele/p/6557328.html
13.下面关于随机森林和Adaboost说法正确的是( ACD )
A. 和Adaboost相比,随机森林对错误和离群点更鲁棒
B. 随机森林准确率不依赖于个体分类器的实例和他们之间的依赖性
C. 随即森林对每次划分所考虑的属性数很偏感
D. Adaboost初始时每个训练元组被赋予相等的权重
随机森林可参考:https://zhuanlan.zhihu.com/p/22097796
除了 Bagging 树模型的一般局限性外,随机森林还有一些局限性:
1)训练和预测都慢
2)如果需要区分的类别多,随机森林表现不会好
3)当我们需要推断超出范围的独立变量或者非独立变量,随机森林做的并不好,应该使用MARS那样的算法
14.《同义词词林》的词类分类体系中,将词分为大类、种类、小类,下列说法正确的是( D )
A. 大类以小写字母表示
B. 小类以大写字母表示
C. 中类以阿拉伯数字表示
D. 中类有94个
大类12个,中类94个,小类1438个,标题词3933个。大类编号为大写拉丁字母,中类为小写字母,小类为阿拉伯两位数字。
15. 文本信息检索的一个核心问题是文本相似度计算,将查询条件和文本之间的相似程度数值化,从而方便比较。当文档和查询都表示成向量时,可以利用向量的内积的大小近似地表示两个向量之间的相关程度。
设有两个文档和查询抽取特征和去除停用词后分别是:
文档d1: a、b、c、a、f、b、a、f、h
文档d2: a、c
查询q: a、c、a
特征项集合为 {a、b、c、d、e、f、g、h}
如果采用二值向量表示,那么利用内积法计算出q和d1、d2的相似度分别是( B )
A. 1、1
B. 2、2
C. 7、3
D. 0、0
NLP相关,完全不熟悉
16. 在统计语言模型中,通常以概率的形式描述任意语句的可能性,利用最大相似度估计进行度量,对于一些低频词,无论如何扩大训练数据,出现的频度仍然很低,下列哪种方法可以解决这一问题( C )
A. 一元切分
B. 一元文法
C. 数据平滑
D. N元文法
NLP相关,完全不熟悉
17. 命名实体识别是指出文本中的人名、地名等专有名词和时间等,其中有有监督的命名实体识别和无监督的命名实体识别,下列选项哪些是属于有监督的学习方法( BCD )
A. 字典法
B. 决策树
C. 隐马尔可夫模型
D. 支持向量机