Python2 Json字典里面包含英文乱码解决
由于Python2默认是使用ascii格式编码的,对中文有时候不是太友好,Python3会解决那些问题,今天笔者遇到了上述问题,就总结跟大家分享了下,途中也有上网查阅过相关的资料。
str_text= u'\u8bf7\u6c42\u6210\u529f'
print(str_text.encode("utf-8").decode("utf-8"))
执行结果为:

可以看到能够正常转换,这是对字符串形式来用的一般转换方式但不适用于以下的转换方式,会让你花一段时间去网络上遨游去寻找解决方法。tips:可以提前使用print(type(变量)先查看变量的类型在查找解决的方法,可以少走弯路!
执行示例:

下面是本文的重点!对Json字典里面包含英文乱码解决方法:
dict_text = {u'message': u'\u8bf7\u6c42\u6210\u529f', u'data': {u'eventId': u'1.572837157446E9', u'eventCode': u'INSTALL_AGENT', u'logId': 12895, u'projectTaskLogDetailModels': [{u'updateTime': 1572837170, u'resourceId': u'10.153.1.23', u'createTime': 1572837170, u'taskStatus': 0, u'logId': 12895, u'taskSource': None, u'taskId': None, u'message': u'\u5904\u7406\u4e2d', u'managerIp': None, u'proxyIp': None, u'id': 12849}], u'eventMessage': u'\u5904\u7406\u4e2d', u'eventStatus': 0}, u'msgCode': 200}
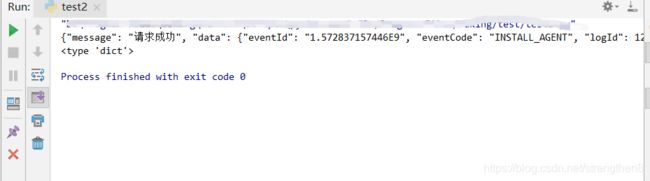
print json.dumps(dict_text, ensure_ascii=False, encoding='UTF-8')
print(type(dict_text))
执行结果如下: