使用Selenium爬取美团网大学城美食并存入MongoDB数据库
Selenium是什么?
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面源代码,做到可见即可爬。对于一些使用 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。
Selenium 适用场景
在网络爬虫中,有的网页可以直接用 requests 来爬取,有的可以直接通过分析 Ajax 来爬取,不同的网站类型有其适用的爬取方法。
而对于带有 JavaScript 渲染的网页,多数情况下是无法直接用 requests 爬取网页源码的,虽然有些情况下可以直接用 requests 来模拟 Ajax 请求来直接得到数据。但有些情况下 Ajax 的一些请求接口可能带有一些加密参数,如 token、sign 等等,如果不分析清楚这些参数是怎么生成的话,就难以模拟和构造这些参数。
此时可以直接选择使用 Selenium 驱动浏览器渲染的方式来解决,实现所见即所爬,则无需关心在该网页背后发生了什么请求、得到什么数据以及怎么渲染页面,我们看到的页面就是最终浏览器帮我们模拟了 Ajax 请求和 JavaScript 渲染得到的最终结果,而 Selenium 正好也能拿到这个最终结果,相当于绕过了 Ajax 请求分析和模拟的阶段,直达目标。
然而 Selenium 也有其局限性,其爬取效率较低,有些爬取需要模拟浏览器的操作,实现相对烦琐。但在某些场景下也是一种有效的爬取手段。
使用Selenium爬取美团网大学城美食
1. 首先分析目标网站

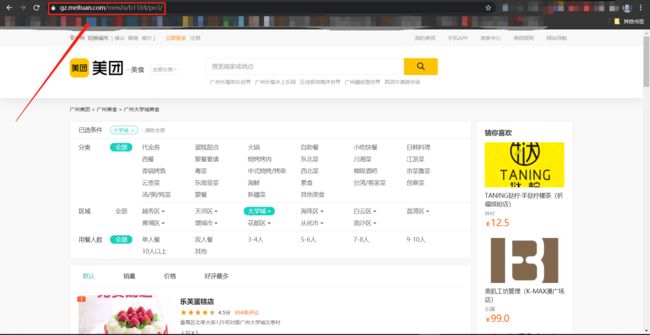
可以发现URL随着页数变化的规律,于是构造一个页面爬取的框架:
import logging
import time
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver import ChromeOptions
from selenium import webdriver
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
INDEX_URL = 'https://gz.meituan.com/meishi/b1184/pn{page}/'
TIME_OUT = 30
TOTAL_PAGE = 12
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
wait = WebDriverWait(browser, TIME_OUT)
def scrape_page(url, condition, locator):
"""
Page scraping framework
Args:
url: pages to be scraped
condition: judgement conditions for page loading
locator: locator
Returns:
None
"""
logging.info('scraping %s', url)
try:
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',
{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})
time.sleep(1)
browser.get(url)
wait.until(condition(locator))
except TimeoutException:
logging.error('error occurred while scraping %s', url, exc_info=True)
def scrape_index(page):
"""
Scrape every page
Args:
page:
Returns:
None
"""
url = INDEX_URL.format(page=page)
scrape_page(url, condition=EC.visibility_of_all_elements_located,
locator=(By.XPATH, '/html/body/div/section/div/div[2]/div[2]/div[1]/ul/li'))
2. 接着分析每个页面中每个商家的URL链接
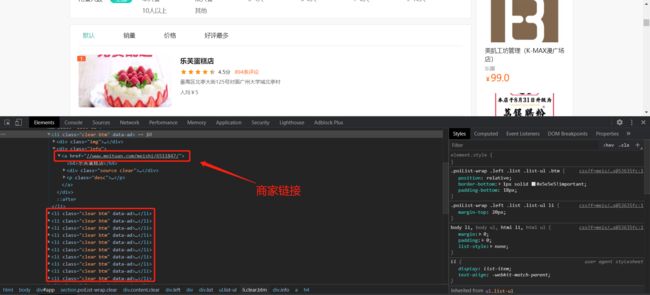
def parse_index():
"""
Get the url of each business
Args:
None
Returns:
generator
"""
elements = browser.find_elements_by_xpath('/html/body/div/section/div/div[2]/div[2]/div[1]/ul/li/div[1]/a')
for element in elements:
url = element.get_attribute('href')
yield url
3. 然后爬取每个商家的页面
def scrape_detail(url):
"""
Scrape the page of each business
Args:
url
Returns:
None
"""
scrape_page(url, condition=EC.visibility_of_element_located,
locator=(By.XPATH, '/html/body/div/section/div/div[2]/div[1]/div[@class="name"]'))
4. 然后使用开发者工具解析商家页面信息

def parse_detail():
"""
Parse the information of each business
Args:
None
Returns:
data
"""
try:
name = browser.find_element_by_xpath(
"/html/body/div[1]/section/div/div[2]/div[1]/div[1]").text.strip('食品安全档案').strip()
except:
name = '无'
try:
star = browser.find_element_by_xpath("/html/body/div/section/div/div[2]/div[1]/div[2]/p").text[0]
except:
star = '无'
if star == '暂':
star = '无'
try:
per_capita_consumption = browser.find_element_by_xpath(
"/html/body/div/section/div/div[2]/div[1]/div[2]/p/span").text.strip().strip('人均')
except:
per_capita_consumption = '无'
try:
address = browser.find_element_by_xpath("/html/body/div/section/div/div[2]/div[1]/div[3]/p[1]").text.strip(
'地址:')
except:
address = '无'
try:
telephone = browser.find_element_by_xpath("/html/body/div/section/div/div[2]/div[1]/div[3]/p[2]").text.strip(
'电话:')
except:
telephone = '无'
try:
business_hours = browser.find_element_by_xpath(
"/html/body/div/section/div/div[2]/div[1]/div[3]/p[3]").text.strip('营业时间:')
except:
business_hours = '无'
try:
raw_recommended_dishes = browser.find_element_by_xpath(
"/html/body/div/section/div/div[3]/div[1]/div[2]/div/ul").text
recommended_dishes = ','.join(re.findall(u"[\u4e00-\u9fa5]+", raw_recommended_dishes))
except:
recommended_dishes = '无'
try:
review_people = browser.find_element_by_xpath(
"/html/body/div/section/div/div[3]/div[1]/div[3]/div[1]").text.strip(
'条网友点评').strip('质量排序时间排序').strip()
except:
review_people = '无'
url = browser.current_url
try:
cover = browser.find_element_by_xpath(
"/html/body/div/section/div/div[2]/div[2]/div/div/img").get_attribute('src')
except:
cover = '无'
return {"NAME": name, "STAR": star, "PER_CAPITA_CONSUMPTION": per_capita_consumption, "ADDRESS": address,
"TELEPHONE": telephone, "BUSINESS_HOURS": business_hours, "RECOMMENDED_DISHES": recommended_dishes,
"REVIEW_PEOPLE": review_people, "URL": url, "COVER": cover}
5. 最后将爬取的数据存入MongoDB数据库
def save_to_MongoDB(data):
"""
Store data in MongoDB database
Args:
data
Returns:
None
"""
collection.update_one({
'NAME': data.get('NAME')
}, {
'$set': data
}, upsert=True)
6. 主函数
if __name__ == "__main__":
for each_page in range(1, TOTAL_PAGE + 1):
scrape_index(each_page)
detail_urls = parse_index()
for detail_url in list(detail_urls):
scrape_detail(detail_url)
detail_data = parse_detail()
save_to_MongoDB(detail_data)
logging.info('save data %s', detail_data)
7. 爬取结果
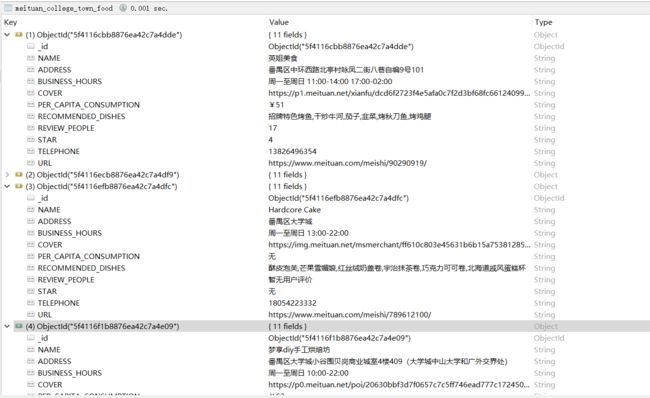
完整源代码:
https://github.com/Giyn/PythonSpider/blob/master/MeiTuan/CollegeTownFood/college_town_food.py