都0202年了,那些经典的目标检测算法你还会看吗?
目标检测算法综述
- Faster R-CNN
- 一、网络结构
- 二、 Backbone-vgg16
- 三、RPN区域建议网络
- 四、ROIPooling
- SSD
- 一、网络结构
- 二、利用处理完的真实框与对应图片的预测结果计算loss
- RetinaNet
- 一、网络结构
- 二、FPN结构
- 三、聚焦损失函数
- 四、困难样本挖掘
- 未完待续
- Mask R-CNN
- 一.网络结构
- 二.RoiAlign
- YOLO v3
- M2Det
- EffienctDet
Faster R-CNN
一、网络结构
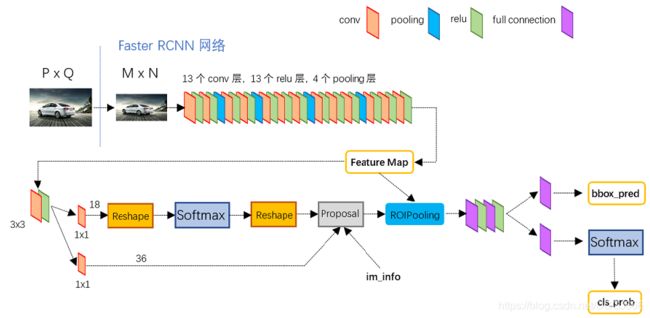
Faster-RCNN可以采用多种的主干特征提取网络,常用的有VGG16,Resnet,Xception等等,本文采用的是VGG16的网络。
首先大概介绍一下VGG网络提出使用3个3x3卷积核代替7x7卷积核,使用2个3x3卷积来代替5*5卷积核,这样做的主要目的是在保证具有相同感受野的条件下,提升了网络的深度,在一定程度上提升了网络效果。
上图的faster-rcnn采用的是vgg16作为特征提取网络,将最后提取的特征层保留为Feature Map,作为经典的双阶段网络鼻祖,其网络将得到的feature map经过一次3x3的卷积进行第一次回归,来产生提议框;这一步也是双阶段网络为什么精度较高的原因,这一步可以较好的使得正样本和负样本框进行均衡。
在得到提议框之后,再次利用之前提取到的Feature Map 进行Roi-pooling,这里得到相同尺寸的特征图,最后再接两个全连接进行分类和回归得到最终的检测框。
二、 Backbone-vgg16
import torch.nn as nn
__all__ = ["vgg11","vgg13","vgg16","vgg19"]
config = {
'A':[64,'M',128,'M',256,256,'M',512,512,'M',512,512,'M'],
'B':[64,64,'M',128,128,'M',256,256,'M',512,512,'M',512,512,'M'],
'D':[64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M'],
'E':[64,64,'M',128,128,'M',256,256,256,256,'M',512,512,512,'M',512,512,512,512,'M']
}
class VGG(nn.Module):
def __init__(self,config,num_classes,batch_norm=True):
super(VGG,self).__init__()
self.features = self.__make_layer(config,batch_norm)
self.classifer = nn.Linear(512,num_classes)
def forward(self,x):
x = self.features(x)
x = x.view(x.size(0),-1)
x = self.classifer(x)
return x
def __make_layer(self,config,batch_norm):
layers = list()
in_channels = 3
for v in config:
if isinstance(v,int):
conv = nn.Conv2d(in_channels,v,3,1,1)
if batch_norm:
layers += [conv,nn.BatchNorm2d(v),nn.ReLU(inplace=True)]
else:
layers += [conv,nn.ReLU(inplace=True)]
in_channels = v
else:
layers.append(nn.MaxPool2d(2))
return nn.Sequential(*layers)
def vgg11(num_classes):
return VGG(config['A'],num_classes)
def vgg13(num_classes):
return VGG(config['B'],num_classes)
def vgg16(num_classes):
return VGG(config['D'],num_classes)
def vgg19(num_classes):
return VGG(config['E'],num_classes)
三、RPN区域建议网络
在Faster-RCNN中,先验框的数量是9,并且faster-rcnn对输入进来的图片尺寸也没有固定,但是一般会把输入进来的图片短边固定为600,如输入一张1200x1800的图片,会把图片不失真的resize到600x900上。我们假设输入进来的图片大小为600x600x3,那么在经过vgg16特征提取后的特征图大小为38x38x1024。
在38x38的特征图中,将其分为38x38的网格,每个网格对应9个先验框。也就是有38x38x9个先验框。
其中1x1x36的卷积用于预测公共特征层每个先验框的偏移,包括中心点的位置(x,y)和先验框的长宽。1x1x18的卷积用来预测公共特征层每个先验框的类别,是背景还是物体。
其中要注意的是,在预测宽和高的偏移时加入了指数函数进行预测,在后面计算解码时需要加上对数。
四、ROIPooling
对于传统的CNN,当网络训练好输入的图像尺寸必须是固定值,同时网络输出也是固定大小的vector or matrix.如果输入图像大小不定,这个问题就变得比较麻烦。有两种解决办法:
1.从图像中crop一部分传入网路
2.将图像warp成需要的大小后传入网络

可以看到无论采用何种方法,都会破坏原始图像的信息。
下面介绍一下roipooling的原理:
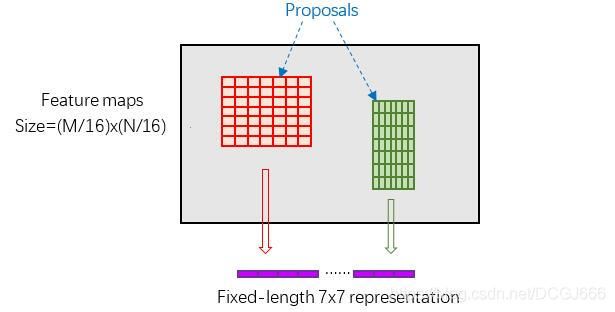
通过RPN得到建议框后,我们将建议框对应在特征图中的尺度分为7x7份,每一块进行max pooling处理,这样经过处理后,即使不同的proposal,输出结构都是7x7大小。实现了固定输出。
SSD
一、网络结构
SSD是一种网络结构清晰明了的单阶段目标检测算法,其多尺度提取特征的方法为后面许多网络提供了借鉴意义。其主要思想是利用VGG特征提取网络,在不同的特征尺度图中设置先验框进行目标检测,可以提高小目标的检测率
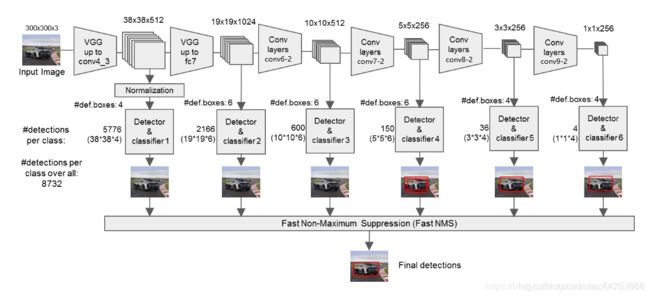
1、输入一张图片后,先被resize到300x300的shape
2、 先经过两次3x3的卷积和一次2x2的最大池化,得到输出为(150,150,64)
3、经过两次3x3的卷积和一次2x2的最大池化,得到输出为(75,75,128)
4、经过三次3x3的卷积和一次2x2的最大池化,得到输出为(38,38,256),在此特征图中每个网格点的先验框为4,一共有38x38x4个先验框
5、经过三次3x3的卷积和一次2x2的最大池化,得到输出为(19,19,512)
6、经过三次3x3的卷积和一次2x2的最大池化,得到输出为(19,19,512)
7、利用卷积代替全连接层,进行了两次3x3卷积网络,输出的特征层为1024,因此输出的net为(19,19,1024),在此特征图中每个网格点的先验框为6,一共有19x19x6个先验框
8、经过一次1x1卷积,调整通道数,一次步长为2的3x3的卷积,输出的net为(10,10,512),在此特征图中每个网格点的先验框为6,一共有10x10x6个先验框
9、经过一次1x1卷积,调整通道数,一次步长为2的3x3的卷积,输出的net为(5,5,256),在此特征图中每个网格点的先验框为6,一共有5x5x6个先验框
10、经过一次1x1卷积,调整通道数,一次padding为valid的3x3卷积网络,输出特征层为256,因此输出为(3,3,256)。先验框个数为3x3x4个
11、经过一次1x1卷积,调整通道数,一次padding为valid的3x3卷积网络,输出特征层为256,因此输出为(1,1,256)。先验框个数为1x1x4个
二、利用处理完的真实框与对应图片的预测结果计算loss
loss的计算分为三个部分:
1.获取所有标签的框的预测结果的回归loss
2.获取所有正标签的种类的预测结果的交叉熵loss
3.获取一定负标签的种类的预测结果的交叉熵loss
由于在ssd的训练过程中,正负样本及其不平衡,即存在对应真实框的先验框可能只有十几个,但是不存在对应真实框的负样本却有几千个,这样会导致负样本的loss值极大,因此我们可以考虑减少负样本的选取,对于SSD的训练来讲,常见的情况是取三倍正阉割版数量的负样本用于训练。
RetinaNet
一、网络结构
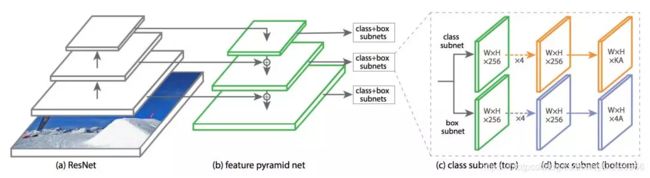
RetinaNet是何凯明大神提出的,为了解决单阶段正负样本不均衡的问题,提出了focal loss,在特征提取中引入了FPN特征金字塔网络,弥补了SSD的两个缺陷,在单阶段网络中取得了不错的成绩。
由于SSD放弃使用已经计算出来的低层特性,而从基础网络中的高层开始构建金字塔,然后添加几个新层。因此,SSD错过了复用特征层级中具有更高分辨率的特征图的机会,而这些低层特征对于检测小目标而言非常重要。
二、FPN结构
FPN中自顶向下建造特征图的构建块,使用最近邻采样将较低分辨率的特征图上采样为2倍,然后按元素相加,将上采样后的特征图与相应分辨率的低层特征图合并,得到一个进行了特征融合的较高分辨率的特征图。最后对每个进行了特征融合的特征图进行一次3x3的卷积操作,生成最终的特征图。
三、聚焦损失函数
单阶段目标检测比双阶段检测精度低的原因主要是因为前者会面临极端不平衡的目标–背景数据分布。双阶段目标检测方法可以通过候选区域滤除大部分背景区域,但单阶段目标检测方法需要直接面对类别不平衡的问题。
聚焦损失函数通过改进经典的交叉熵损失函数,降低了网络训练过程中简单背景样本的学习权重,并且可以实现对难样本的聚焦和对网络学习能力的重新分配,感觉有点像注意力机制。
聚焦损失函数通过改进softmax分类的损失函数,将原来的同权重损失改进为不同权重的损失。在损失中给正负样本加上权重(负样本数量越多,权重越小;正样本数量越少,权重越大)。
四、困难样本挖掘
用分类器对样本进行分类,把其中错误分类的样本放入负样本集合再继续训练分类器。
对于目标检测中我们会事先标记出GT,然后再算法中生成一系列proposals,proposals与GT的IOU超过一定阈值的则认定为是正样本,低于一定阈值的则是负样本。然后扔进网络训练。但是最终会出现一个问题就是正样本的数量远远小于负样本,这样训练出来的分类器的效果总是有限的,会出现许多false positive.把其中得分高的这些false positive。把其中得分较高的这些false positive当做难负样本。
未完待续
Mask R-CNN
一.网络结构
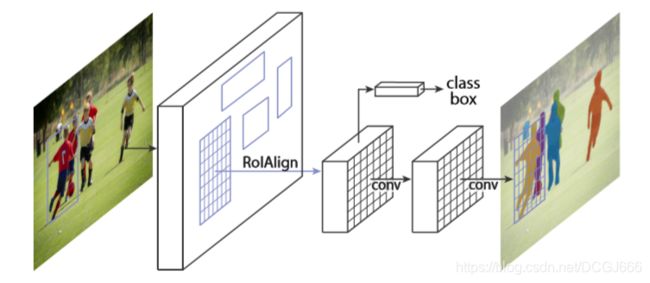
和Faster R-CNN一样,Mask R-CNN采用了两阶段的结构。第一个阶段的结构是RPN。在第二个阶段中,Mask R-CNN 在预测类别和边界框的基础上,为每个Roi预测一个二值掩码。掩码对目标的空间布局进行了编码。与类别标签不同,这个空间结构可以通过卷积操作所提供的像素到像素的对应关系自然地使用掩码提取出来。Mask R-CNN使用一个全卷积网络,对每个Roi预测K个mxm的掩码。这种像素到像素的操作,要求Roi特征很好地对齐,以显式地保持逐像素的空间对应关系。
二.RoiAlign
由于Faster-RCNN中的RoiPooling是将特征图进行7x7的切分,并且进行量化,导致一些浮点数会被约分。最后会导致边界框预测的不是那么准确,但这对于目标检测是足够了,但对于Mask-RCNN的实例分割任务还远远不够。
因此MaskRCNN提出了RoIAlign的操作代替RoiPooling,RoiAlign的思想如下图所示。
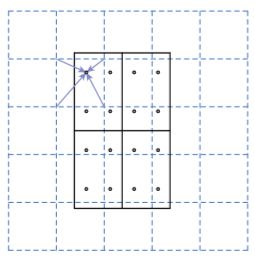
Roi池化的作用是:根据候选框的位置坐标,在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和边界框回归操作。用RoiAlign举个例子就是,原图片中大小为665x665的候选区域映射到特征图中,大小为665/32 x 665/32=20.78 x 20.78。此时,不需要像Roi池化那样进行取整操作,RoiAlign会保留20.78这个浮点数。同样采用7x7的特征图,将大小为20.78x20.78的映射区域划分成49个同等大小的bin,每个bin的大小为20.78/7 x 20.78/7 = 2.97x2.97(在这里同样不进行取整处理)。设置一个采样点数,对每个bin采用双线性插值法计算其中采样点的像素值,再进行最大池化操作,即可得到代表该单元的最终值。
YOLO v3
M2Det
EffienctDet
https://blog.csdn.net/wfei101/article/details/76400672
https://blog.csdn.net/weixin_44791964/article/details/104981486