什么是连通图 ?
在图论中,连通图基于连通的概念。在一个无向图 G 中,若从顶点 \(i\) 到顶点 \(j\) 有路径相连(当然从 \(j\) 到 \(i\) 也一定有路径),则称 \(i\) 和 \(j\) 是连通的。如果 G 是有向图,那么连接 \(i\) 和j的路径中所有的边都必须同向。如果图中任意两点都是连通的,那么图被称作连通图。如果此图是有向图,则称为强连通图(注意:需要双向都有路径)。
简单的来讲就是,
强连通的定义是:有向图 G 强连通是指,G 中任意两个结点连通。
强连通分量(Strongly Connected Components,SCC)的定义是:极大的强连通子图。
这里将会介绍的是如何来求强连通分量的算法、割点和桥 以及双连通分量。
Tarjan 算法发明人
Robert E. Tarjan (1948~) 美国人。
你是不是感觉Robert E. Tarjan 这个名字很熟悉?
没错,Robert E. Tarjan和John E. Hopcroft就是发明了深度优先搜索的两个人——1986年的图灵奖得主。
除此之外 Tarjan 发明了很多算法结构。光 Tarjan 算法就有很多,比如求各种连通分量的 Tarjan 算法,求 LCA(Lowest Common Ancestor,最近公共祖先)的 Tarjan 算法。并查集、Splay、Toptree 也是 Tarjan 发明的。
你看牛人们从来都不闲着的。他们到处交流,寻找合作伙伴,一起改变世界。
我们这里要介绍的是他的在有向图中求强连通分量的 Tarjan 算法。
另外,Tarjan 的名字 j 不发音,中文译为塔扬。
DFS 生成树
在介绍该算法之前,先来了解 DFS 生成树 ,我们以下面的有向图为例:
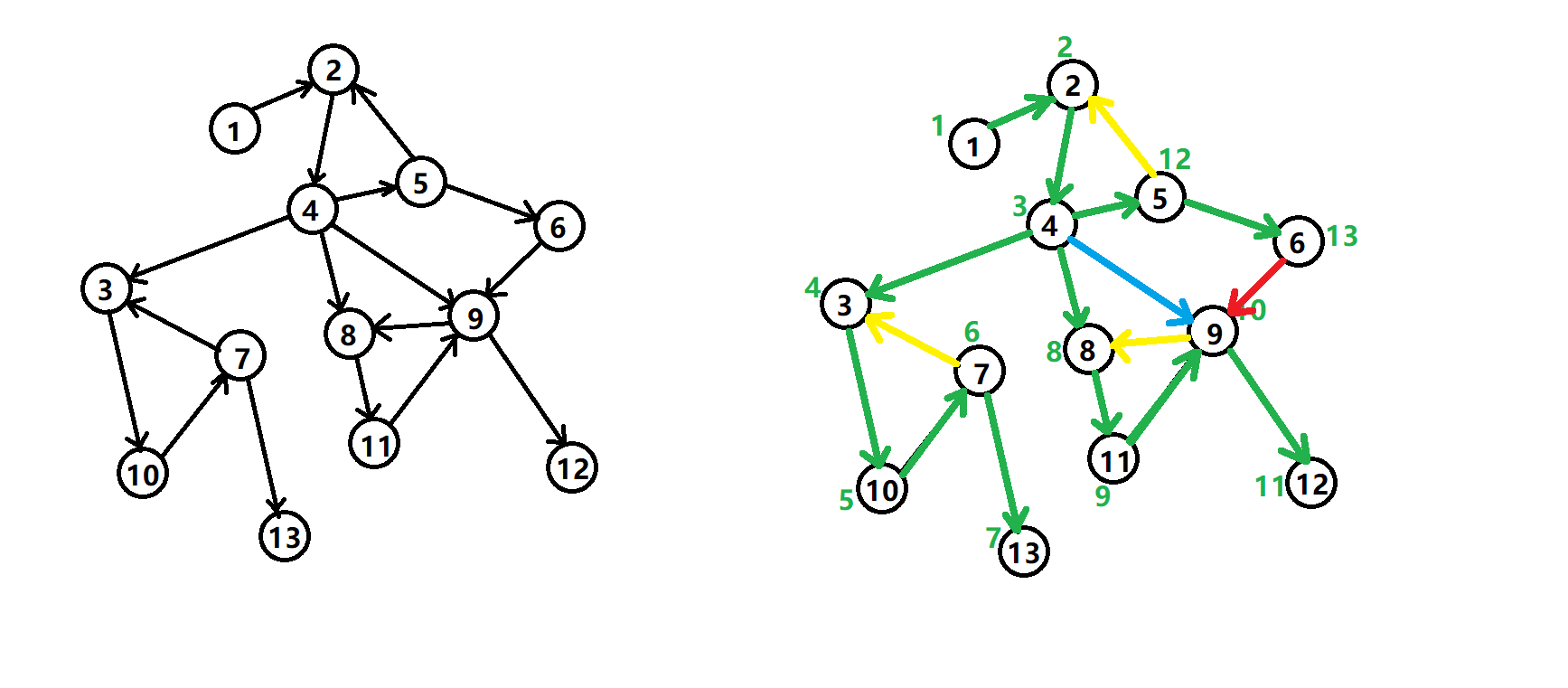
有向图的 DFS 生成树主要有 4 种边(不一定全部出现):
- 树边(tree edge):绿色边,每次搜索找到一个还没有访问过的结点的时候就形成了一条树边。
- 反祖边(back edge):黄色边,也被叫做回边,即指向祖先结点的边。
- 横叉边(cross edge):红色边,它主要是在搜索的时候遇到了一个已经访问过的结点,但是这个结点 并不是 当前结点的祖先时形成的。
- 前向边(forward edge):蓝色边,它是在搜索的时候遇到子树中的结点的时候形成的。
我们考虑 DFS 生成树与强连通分量之间的关系。
如果结点 \(u\) 是某个强连通分量在搜索树中遇到的第一个结点,那么这个强连通分量的其余结点肯定是在搜索树中以 \(u\) 为根的子树中。 \(u\) 被称为这个强连通分量的根。
反证法:假设有个结点 \(v\) 在该强连通分量中但是不在以 \(u\) 为根的子树中,那么 \(u\) 到 \(v\) 的路径中肯定有一条离开子树的边。但是这样的边只可能是横叉边或者反祖边,然而这两条边都要求指向的结点已经被访问过了,这就和 \(u\) 是第一个访问的结点矛盾了。得证。
Tarjan 算法求强连通分量
在 Tarjan 算法中为每个结点 \(u\) 维护了以下几个变量:
-
\(dfn[u]\) :深度优先搜索遍历时结点 \(u\) 被搜索的次序。
-
\(low[u]\) :设以 \(u\) 为根的子树为 \(Subtree(u)\) 。 \(low[u]\) 定义为以下结点的 \(dfn\) 的最小值: \(Subtree(u)\) 中的结点;从 \(Subtree(u)\) 通过一条不在搜索树上的边能到达的结点。
ps:每次找到一个新点,这个点\(low\ []=dfn\ []\)。
一个结点的子树内结点的 dfn 都大于该结点的 dfn。
从根开始的一条路径上的 dfn 严格递增,low 严格非降。
按照深度优先搜索算法搜索的次序对图中所有的结点进行搜索。在搜索过程中,对于结点 \(u\) 和与其相邻的结点 \(v\) (v 不是 u 的父节点)考虑 3 种情况:
- \(v\) 未被访问:继续对 \(v\) 进行深度搜索。在回溯过程中,用 \(low[v]\) 更新 \(low[u]\) 。因为存在从 \(u\) 到 \(v\) 的直接路径,所以 \(v\) 能够回溯到的已经在栈中的结点, \(u\) 也一定能够回溯到。
- \(v\) 被访问过,已经在栈中:即已经被访问过,根据 \(low\) 值的定义(能够回溯到的最早的已经在栈中的结点),则用 \(dfn[v]\) 更新 \(low[u]\) 。
- \(v\) 被访问过,已不在在栈中:说明 \(v\) 已搜索完毕,其所在连通分量已被处理,所以不用对其做操作。
将上述算法写成伪代码:
TARJAN_SEARCH(int u)
vis[u]=true
low[u]=dfn[u]=++dfncnt // 为节点u设定次序编号和Low初值
push u to the stack // 将节点u压入栈中
for each (u,v) then do // 枚举每一条边
if v hasn't been search then // 如果节点v未被访问过
TARJAN_SEARCH(v) // 继续向下搜索
low[u]=min(low[u],low[v]) // 回溯
else if v has been in the stack then // 如果节点u还在栈内
low[u]=min(low[u],dfn[v])
if (DFN[u] == Low[u]) // 如果节点u是强连通分量的根
repeat v = S.pop // 将v退栈,为该强连通分量中一个顶点
print v
until (u== v)对于一个连通分量图,我们很容易想到,在该连通图中有且仅有一个 \(dfn[u]=low[u]\) 。该结点一定是在深度遍历的过程中,该连通分量中第一个被访问过的结点,因为它的 DFN 值和 LOW 值最小,不会被该连通分量中的其他结点所影响。
因此,在回溯的过程中,判定 \(dfn[u]=low[u]\) 的条件是否成立,如果成立,则栈中从 \(u\) 后面的结点构成一个 SCC (强连通分量)。
实现
int dfn[N], low[N], dfncnt, s[N], in_stack[N], tp;
int scc[N], sc; // 结点 i 所在 scc 的编号
int sz[N]; // 强连通 i 的大小
void tarjan(int u) {
low[u] = dfn[u] = ++dfncnt, s[++tp] = u, in_stack[u] = 1;
for (int i = h[u]; i; i = e[i].nex) {
const int &v = e[i].t;
if (!dfn[v]) {
tarjan(v);
low[u] = min(low[u], low[v]);
} else if (in_stack[v]) {
low[u] = min(low[u], dfn[v]);
}
}
if (dfn[u] == low[u]) {
++sc;
while (s[tp] != u) {
scc[s[tp]] = sc;
sz[sc]++;
in_stack[s[tp]] = 0;
--tp;
}
scc[s[tp]] = sc;
sz[sc]++;
in_stack[s[tp]] = 0;
--tp;
}
}时间复杂度 \(O(n + m)\) 。
Tarjan 算法有许多用途,常用的例如求强连通分量,缩点,还有求 2-SAT 的用途等。缩点:
缩点就是要将两两之间可以相互到达的点,缩成一个点来表示(即求无向图的连通分量,或者有向图的强连通分量),他们的求法都是相同的,都是将无向图转化为有向图。
基本上都是以Trajan算法写题的。
Kosaraju 算法
Kosaraju 算法依靠两次简单的 DFS 实现。
第一次 DFS,选取任意顶点作为起点,遍历所有未访问过的顶点,并在回溯之前给顶点编号,也就是后序遍历。
第二次 DFS,对于反向后的图,以标号最大的顶点作为起点开始 DFS。这样遍历到的顶点集合就是一个强连通分量。对于所有未访问过的结点,选取标号最大的,重复上述过程。
两次 DFS 结束后,强连通分量就找出来了,Kosaraju 算法的时间复杂度为 \(O(n+m)\) 。
实现
// g 是原图,g2 是反图
void dfs1(int u) {
vis[u] = true;
for (int v : g[u])
if (!vis[v]) dfs1(v);
s.push_back(u);
}
void dfs2(int u) {
color[u] = sccCnt;
for (int v : g2[u])
if (!color[v]) dfs2(v);
}
void kosaraju() {
sccCnt = 0;
for (int i = 1; i <= n; ++i)
if (!vis[i]) dfs1(i);
for (int i = n; i >= 1; --i)
if (!color[s[i]]) {
++sccCnt;
dfs2(s[i]);
}
}Garbow 算法
\(Tarjan\) 算法和 \(Garbow\) 算法是同一个思想的不同实现,但是 \(Garbow\) 算法更加精妙,时间更少,不用频繁更新 $ low $。
应用
我们可以将一张图的每个强连通分量都缩成一个点。
然后这张图会变成一个 DAG(为什么?)。
DAG 好啊,能拓扑排序了就能做很多事情了。
举个简单的例子,求一条路径,可以经过重复结点,要求经过的不同结点数量最多。
了解完强连通分量的几个算法以后来看看什么是 割点和桥。
割点和桥更严谨的定义参见wiki上 图论相关概念 。
割点
对于一个无向图,如果把一个点删除后这个图的极大连通分量数增加了,那么这个点就是这个图的割点(又称割顶)。
如何实现?
如果我们尝试删除每个点,并且判断这个图的连通性,那么复杂度会特别的高。所以要先序学会常用的算法:Tarjan 。
首先,我们上一个图:
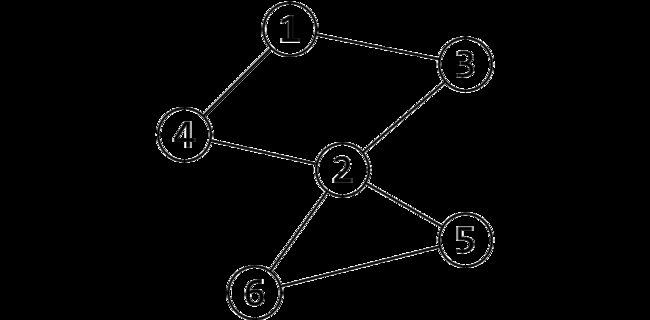
很容易的看出割点是 2,而且这个图仅有这一个割点。
首先,我们按照 DFS 序给他打上时间戳(访问的顺序)。
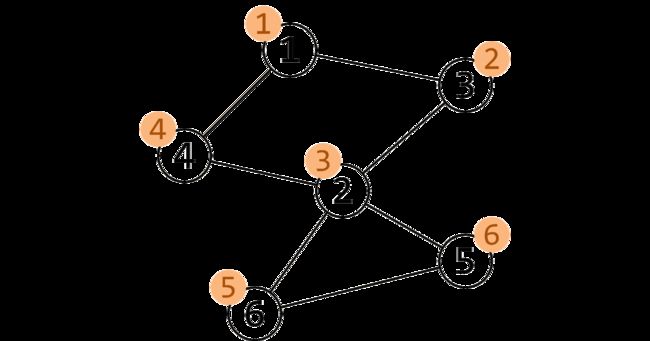
这些信息被我们保存在一个叫做 num 的数组中。
还需要另外一个数组 low ,用它来存储不经过其父亲能到达的最小的时间戳。
例如 low[2] 的话是 1, low[5] 和 low[6] 是 3。
然后我们开始 DFS,我们判断某个点是否是割点的根据是:对于某个顶点 \(u\) ,如果存在至少一个顶点 \(v\) ( \(u\) 的儿子),使得 \(low_v \geq num_u\) ,即不能回到祖先,那么 \(u\) 点为割点。
另外,如果搜到了自己(在环中),如果他有两个及以上的儿子,那么他一定是割点了,如果只有一个儿子,那么把它删掉,不会有任何的影响。比如下面这个图,此处形成了一个环,从树上来讲它有 2 个儿子:
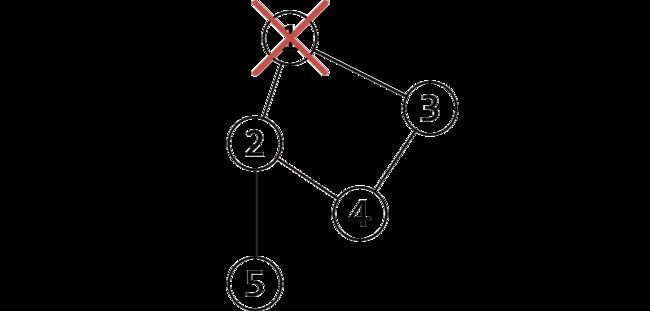
我们在访问 1 的儿子时候,假设先 DFS 到了 2,然后标记用过,然后递归往下,来到了 4,4 又来到了 3,当递归回溯的时候,会发现 3 已经被访问过了,所以不是割点。
更新 low 的伪代码如下:
如果 v 是 u 的儿子 low[u] = min(low[u], low[v]);
否则
low[u] = min(low[u], num[v]);例题
洛谷 P3388【模板】割点(割顶)
#include
using namespace std;
int n, m; // n:点数 m:边数
int num[100001], low[100001], inde, res;
// num:记录每个点的时间戳
// low:能不经过父亲到达最小的编号,inde:时间戳,res:答案数量
bool vis[100001], flag[100001]; // flag: 答案 vis:标记是否重复
vector edge[100001]; // 存图用的
void Tarjan(int u, int father) { // u 当前点的编号,father 自己爸爸的编号
vis[u] = true; // 标记
low[u] = num[u] = ++inde; // 打上时间戳
int child = 0; // 每一个点儿子数量
for (auto v : edge[u]) { // 访问这个点的所有邻居 (C++11)
if (!vis[v]) {
child++; // 多了一个儿子
Tarjan(v, u); // 继续
low[u] = min(low[u], low[v]); // 更新能到的最小节点编号
if (father != u && low[v] >= num[u] &&
!flag[u]) // 主要代码
// 如果不是自己,且不通过父亲返回的最小点符合割点的要求,并且没有被标记过
// 要求即为:删了父亲连不上去了,即为最多连到父亲
{
flag[u] = true;
res++; // 记录答案
}
} else if (v != father)
low[u] = min(low[u], num[v]); // 如果这个点不是自己,更新能到的最小节点编号
}
if (father == u && child >= 2 && !flag[u]) { // 主要代码,自己的话需要 2 个儿子才可以
flag[u] = true;
res++; // 记录答案
}
}
int main() {
cin >> n >> m; // 读入数据
for (int i = 1; i <= m; i++) { // 注意点是从 1 开始的
int x, y;
cin >> x >> y;
edge[x].push_back(y);
edge[y].push_back(x);
} // 使用 vector 存图
for (int i = 1; i <= n; i++) // 因为 Tarjan 图不一定连通
if (!vis[i]) {
inde = 0; // 时间戳初始为 0
Tarjan(i, i); // 从第 i 个点开始,父亲为自己
}
cout << res << endl;
for (int i = 1; i <= n; i++)
if (flag[i]) cout << i << " "; // 输出结果
return 0;
} 割边
和割点差不多,叫做桥。
对于一个无向图,如果删掉一条边后图中的连通分量数增加了,则称这条边为桥或者割边。严谨来说,就是:假设有连通图 \(G=\{V,E\}\) , \(e\) 是其中一条边(即 \(e \in E\) ),如果 \(G-e\) 是不连通的,则边 \(e\) 是图 \(G\) 的一条割边(桥)。
比如说,下图中,
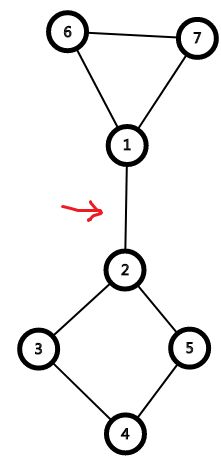
红色箭头指向的就是割边。
实现
和割点差不多,只要改一处: \(low_v>num_u\) 就可以了,而且不需要考虑根节点的问题。
割边是和是不是根节点没关系的,原来我们求割点的时候是指点 \(v\) 是不可能不经过父节点 \(u\) 为回到祖先节点(包括父节点),所以顶点 \(u\) 是割点。如果 \(low_v=num_u\) 表示还可以回到父节点,如果顶点 \(v\) 不能回到祖先也没有另外一条回到父亲的路,那么 \(u-v\) 这条边就是割边。
代码实现
下面代码实现了求割边,其中,当 isbridge[x] 为真时, (father[x],x) 为一条割边。
int low[MAXN], dfn[MAXN], iscut[MAXN], dfs_clock;
bool isbridge[MAXN];
vector G[MAXN];
int cnt_bridge;
int father[MAXN];
void tarjan(int u, int fa) {
father[u] = fa;
low[u] = dfn[u] = ++dfs_clock;
for (int i = 0; i < G[u].size(); i++) {
int v = G[u][i];
if (!dfn[v]) {
tarjan(v, u);
low[u] = min(low[u], low[v]);
if (low[v] > dfn[u]) {
isbridge[v] = true;
++cnt_bridge;
}
} else if (dfn[v] < dfn[u] && v != fa) {
low[u] = min(low[u], dfn[v]);
}
}
} 理解了基本的Tarjan算法、割点和桥的概念以后就可以开始处理双连通分量问题了。
双连通分量定义
在一张连通的无向图中,对于两个点 \(u\) 和 \(v\) ,如果无论删去哪条边(只能删去一条)都不能使它们不连通,我们就说 \(u\) 和 \(v\) 边双连通 。
在一张连通的无向图中,对于两个点 \(u\) 和 \(v\) ,如果无论删去哪个点(只能删去一个,且不能删 \(u\) 和 \(v\) 自己)都不能使它们不连通,我们就说 \(u\) 和 \(v\) 点双连通 。
边双连通具有传递性,即,若 \(x,y\) 边双连通, \(y,z\) 边双连通,则 \(x,z\) 边双连通。
点双连通 不 具有传递性,反例如下图, \(A,B\) 点双连通, \(B,C\) 点双连通,而 \(A,C\) 不 点双连通。
DFS
对于一张连通的无向图,我们可以从任意一点开始 DFS,得到原图的一棵生成树(以开始 DFS 的那个点为根),这棵生成树上的边称作 树边 ,不在生成树上的边称作 非树边 。
由于 DFS 的性质,我们可以保证所有非树边连接的两个点在生成树上都满足其中一个是另一个的祖先。
DFS 的代码如下:
void DFS(int p) {
visited[p] = true;
for (int to : edge[p])
if (!visited[to]) DFS(to);
}DFS 找桥并判断边双连通
首先,对原图进行 DFS。
如上图所示,黑色与绿色边为树边,红色边为非树边。每一条非树边连接的两个点都对应了树上的一条简单路径,我们说这条非树边 覆盖 了这条树上路径上所有的边。绿色的树边 至少 被一条非树边覆盖,黑色的树边不被 任何 非树边覆盖。
我们如何判断一条边是不是桥呢?显然,非树边和绿色的树边一定不是桥,黑色的树边一定是桥。
如何用算法去实现以上过程呢?首先有一个比较暴力的做法,对于每一条非树边,都逐个地将它覆盖的每一条树边置成绿色,这样的时间复杂度为 \(O(nm)\) 。
怎么优化呢?可以用差分。对于每一条非树边,在其树上深度较小的点处打上 -1 标记,在其树上深度较大的点处打上 +1 标记。然后 \(O(n)\) 求出每个点的子树内部的标记之和。对于一个点 \(u\) ,其子树内部的标记之和等于覆盖了 \(u\) 和 \(u\) 的父亲之间的树边的非树边数量。若这个值非 \(0\) ,则 \(u\) 和 \(u\) 的父亲之间的树边不是桥,否则是桥。
用以上的方法 \(O(n+m)\) 求出每条边分别是否是桥后,两个点是边双连通的,当且仅当它们的树上路径中 不 包含桥。
DFS 找割点并判断点双连通
如上图所示,黑色边为树边,红色边为非树边。每一条非树边连接的两个点都对应了树上的一条简单路径。
考虑一张新图,新图中的每一个点对应原图中的每一条树边(在上图中用蓝色点表示)。对于原图中的每一条非树边,将这条非树边对应的树上简单路径中的所有边在新图中对应的蓝点连成一个连通块(这在上图中也用蓝色的边体现出来了)。
这样,一个点不是桥,当且仅当与其相连的所有边在新图中对应的蓝点都属于同一个连通块。两个点点双连通,当且仅当它们在原图的树上路径中的所有边在新图中对应的蓝点都属于同一个连通块。
蓝点间的连通关系可以用与求边双连通时用到的差分类似的方法维护,时间复杂度 \(O(n+m)\) 。
Reference
清晰的图示:https://www.byvoid.com/zhs/blog/scc-tarjan,
可视化过程(英文讲解):https://www.youtube.com/watch?v=TyWtx7q2D7Y
Garbow算法:https://blog.csdn.net/zhouzi2018/article/details/81623747
其它
文章开源在 Github - blog-articles,点击 Watch 即可订阅本博客。 若文章有错误,请在 Issues 中提出,我会及时回复,谢谢。
如果您觉得文章不错,或者在生活和工作中帮助到了您,不妨给个 Star,谢谢。
(文章完)