数据结构与算法 【Python】

数据结构:
想通过计算机解决一个实例问题,需要输入信息A,然后通过在计算机上运行程序,产出以另一种方式输出的信息B。那么就可以认为这个程序完成了该问题实例的求解工作。
- 信息:可以是数字、图像、语音等等有内容的东西
- 数据:在计算机科学领域,数据指计算机(程序)能够处理的符号形式的总和
- 数据元素:在讨论计算机处理时,指最基本的数据单位。在计算机硬件层面,所有被存储和处理的数据最终都编码为二进制代码形式,一切数据最终都表现为二进制位的序列,最基本的数据元素就是一个二进制位。
- 数据结构:数据间的关联和组合形式,总结其中的规律性,发掘特别值得注意的有用结构,研究这些结构的性质,从而研究如何在计算机中实现这些有用的数据结构,以支持相应组合数据的高效使用,支持处理它们的高效算法。
Python变量与对象
Python变量的值都是对象,可以是基本整数、浮点数等类型的对象,也可以是组合类型的对象,如 list等。程序中建立和使用的各种复杂对象,包括Python函数等,都基于独立的存储块实现,通过链接相互关联。程序里的名字(变量、参数、函数名等)关联着作为其值的对象,这种关联可以用赋值操作改变。
Python对象的表示
Python程序内部有一个存储管理系统,负责管理可用内存,为各种对象安排存储,支持灵活有效的内存使用。程序中要求建立对象时,管理系统就会为其安排存储,某些对象不再有用时,就会则收回其占用的存储。存储管理系统屏蔽了集体内存使用的细节,大大减少了编程人员的负担。
一、抽象数据类型和Python类
1、数据类型和数据构造
类型(数据类型)是程序设计领域最重要的基本概念之一。
- 逻辑类型bool:包括两个值(两个对象)True和False,可用操作包括and、or、not
- 数值类型int和float:int类型包含很多值(整数对象),对它们可以做加减乘除等运算
- 字符串类型str
- 还会有一些 组合数据类型(下面讲到的list、tuple、set、dict等结构)
但是,无论编程语言提供了多少内置类型,在处理较为复杂的问题时,程序员或早或晚都会遇到一些情况,内置类型难以满足需要,这时就出现了:
list、tuple、set、dict 等结构(它们也看做是类型),编程时可以利用它们把一组相关数据组织在一起,作为一个数据对象,作为一个整体存储、传递和处理。
总结:
-
1、基本的数据类型包括
1. Number ( 数值 ) ----> 整型 int,浮点型 float
2. String( 字符串 )
3. Tuple( 元组 )-----------------> ( , , , , )
4. List( 列表 ) -------------------> [ , , , , ]
5. set ( 集合 ) -------------------> { ’ ’ , ’ ’ , ’ ’ }
6. Dictionary( 字典 )------------> { " " : 123 , " " : 789 }
可变数据 和 不可变数据 的区分:
不可变数据(3个):Number(数字)、String(字符串)、Tuple(元组)
可变数据(3个):List(列表)、Dictionary(字典)、set(集合)
-
2、数据类型的创建方式
创建 列表:listT = [ 1, 2, 3, 4, 5 ]
创建 元组:tup2 = ( 1, 2, 3, 4, 5 )
创建 字典:dict2={ “abc”:123, “def”:789 }
创建 集合:student={ ‘Tom’ , ‘Jim’ , ‘Mary’ }
2、抽象数据类型的概念
抽象数据类型的基本想法是把数据定义为抽象的对象集合,只为它们定义可用的合法操作,并不暴露其内部实现的具体细节,不论是其数据的表示细节还是操作的实现细节。
当然要使用一种对象,首先需要能构造这种对象,然后操作它们。
数据类型有个很重要的性质,叫 变动性,表示该类型的对象在创建之后是否允许变化。
- 不变(数据)类型:str、tuple、frozenset
- 可变(数据)类型:list、set、dict
在编程中设计或定义抽象数据类型时,也要根据情况,决定将其定义为不变类型 还是 可变类型。
1.抽象数据类型(Abstract Data Type , ADT)
ADT的概念:拥有属性和方法,属性可以存储数据,方法操作属性(增删改查)
ADT的思想:就是抽象,或者说 数据抽象,
咱们通常定义一个类,例如:
class animal()
属性 -----> 干啥用的呢?描述这个animal类的,一个名词性的描述
方法 -----> 这个类所具有的功能
你比如列表最典型了,list 点进去,里面有一堆def方法,说列表干啥干啥,但所有def上面的那一小块属性是说明list是具有存数据的功能的。
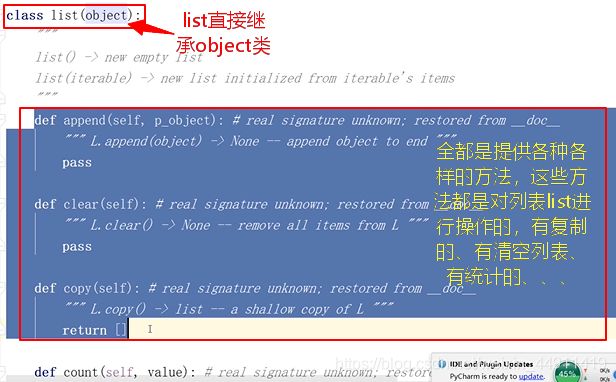
抽象数据类型呢,就是把上面那个属性私有,然后来提供一些方法,这些方法操纵属性,这个属性在抽象数据类型里的作用和目的就是存数据的,
class int 里面也有个
属性是存数据的( 存储 int 类型数据),然后还有方法是对这个属性进行操作的,
class mylist():
def __init__(self,element):
self.__element = element
def delete(self): # 执行删除操作
del self.__element
def set_element(self,element): # 执行重新赋值
self.__element = element
def get_element(self): # 查看
return self.__element
ml = mylist([1,4,5,6])
# ml.delete()
print(ml.get_element())

上述显示结果是获取不到列表,
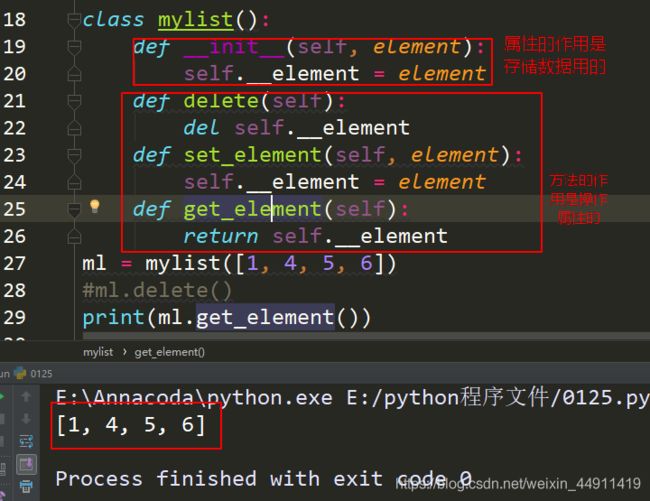
上面两幅截图的对比,得出的结论就是:一个抽象数据类型包括两部分:存储数据的属性__init__和操作属性的方法
抽象数据类型就是一个概念
列表 就是一个抽象数据类型,元组 也是,元组里面也有方法,它能存数据,也能对数据进行操作,int 也是抽象数据类型,float也是抽象数据类型
所以说,只要类里面有属性,能够数据存储;有方法,就能够对属性进行操作,这个东西就叫 抽象数据类型
比如,我现在给你一个列表,我想从最后一位“6”开始删除,而不是从“1”开始按顺序往后删除,那么我们就可以用列表里的一个pop()方法,所以说一个抽象数据类型里有好多操作方法可以进行对存储数据进行操作。
pop( ) 从最后一个开始移除,只提供pop()方法,把remove方法删掉,甚至有一些其他的功能不需要也删掉,实现一个符合要求的特殊的数据类型,还能够对数据进行一些我要求的一些操作
属性的目的是存储数据,方法的目的是操作属性,操作数据,对这些数据进行增、删、改、查
(列表里面提供一个remove可以从中间删)
属性是私有化的,不通过方法你访问不到
集合、列表list 就是一个线性表,就是数据排列像一条线,就是线性表,元组 也是线性表,矩阵 就不是线性表,因为矩阵是二维的,最终画完是一条线y=a*x+b就是线性表
属性:(包含两部分,一部分存储真正的数据,一部分存储下一个地址),一个属性不能存俩值,所以得两属性
1.data-存储数据
2.next-下一个节点的地址
方法:增、删、改、查----> 删 和 插入比较方便,删除和插入需要移位,追加不需要移位
next:后继
pre:前驱
pre永远走的比next走的慢一步,next指向下一个位置,pre换上次next的位置
二、线性表(主要讲:链表)
简称 表,一个线性表是某类元素的一个集合,还记录着元素之间的一种顺序关系。
在程序中,经常需要将一组(通常是同为某个类型)数据元素作为整体管理和使用,需要创建这种元素组,用变量记录它们,传进传出函数等。
1、线性表的概念和表抽象数据类型
表可以看作一种抽象的(数学)概念,也可以作为一种抽象数据类型。
一个表中包含的元素个数称这个表的长度,显然,空表的长度为 0。
在一个非空的线性表里,存在着唯一的一个首元素和唯一的一个尾元素(或称末元素)。除了首元素之外,表中的每个元素e都有且仅有一个前驱元素;除了尾元素之外的每个元素都有且仅有一个后继元素。
通俗来讲,什么叫线性表呢?
外观看起来像一条线,比如:列表list、元组tuple等,就是线性表
顺序表和链表的区别:
链表和列表不一样,它俩有好有坏:
链表(删除 和 插入 比较好)
列表(查看,比较快)
顺序表和链表由于存储结构上的差异,导致它们具有不同的特点,适用于不同的场景。通过系统的学习顺序。
虽然它俩同属于线性表,但
1.数据的存储结构有本质的不同。
- 顺序表存储数据,需预先申请一整块足够大的存储空间,然后将数据按照次序逐一存储,数据之间紧密贴合,不留一丝空隙
- 链表的存储方式与顺序表截然相反,什么时候存储数据,就什么时候才申请存储空间,数据之间的逻辑关系依靠每个数据元素携带的指针维持
2.开辟空间方式不同:
- 顺序表存储数据实行的是“一次开辟,永久使用”,即存储数据之前先开辟好足够的存储空间,空间一旦开辟,后期无法改变大小(使用动态数组的情况除外)
- 而链表则不同,链表存储数据时,一次只开辟存储一个节点的物理空间,如果后期需要还可以再申请
因此,可见,若只从开辟空间方式的角度去看问题的话,当存储数据的个数无法提前确定,又或是物理空间使用紧张以至于无法一次性申请到足够大小的空间时,使用链表更有助于问题的解决。

3.空间利用率:
- 顺序表的空间利用率显然比链表要高,因为链表在存储数据的时候,每次只申请一个节点的空间,且空间的位置是随机的。
这种申请存储空间的方式会产生很多空间碎片,一定程序上造成了空间浪费。不仅如此,由于链表中每个数据元素都必须携带至少一个指针,因此,链表对所申请空间的利用率也没有顺序表高。

2、顺序表的实现
Python的list:
列表中 元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)
[ 插入数据可重复,数据不唯一 ]
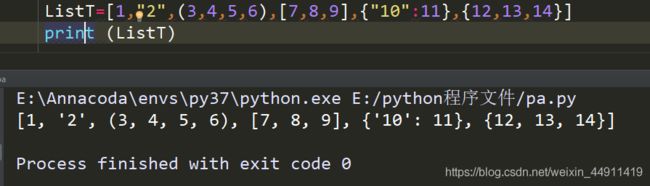
ListT=[1,"2",(3,4,5,6),[7,8,9],{"10":11},{12,13,14}] # 列表可以存储数据类型:数字,字符,元组,列表,字典,set
print (ListT)
列表操作 :
字符串: 短串 长串 遍历
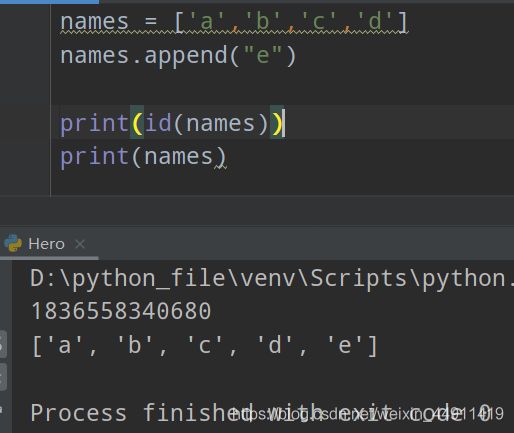
names = ['a','b','c','d']
print(id(names))
(1)追加:append
names = ['a','b','c','d']
names.append("e")
print(id(names))
print(names)
看看编译后,两地址是否一样?
肯定是一样的,要不怎么叫追加呢~
并不是一个新的列表,而是在原来的列表追加
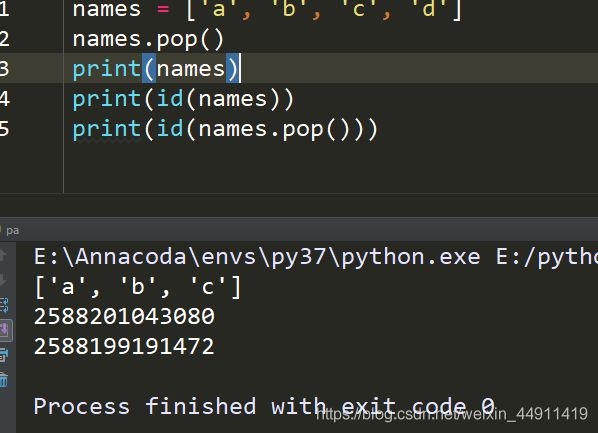
(2)删除: pop, remove, del(三种删除方式)
pop 只删除最后一个元素
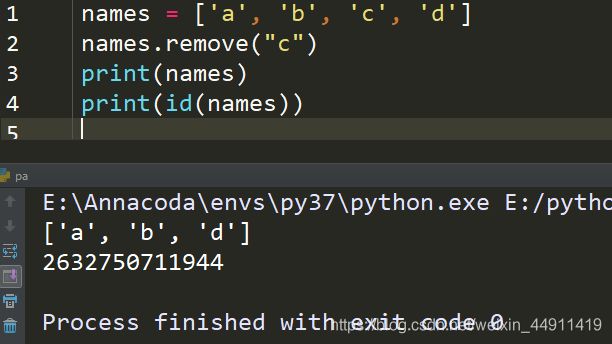
remove 是指定删除
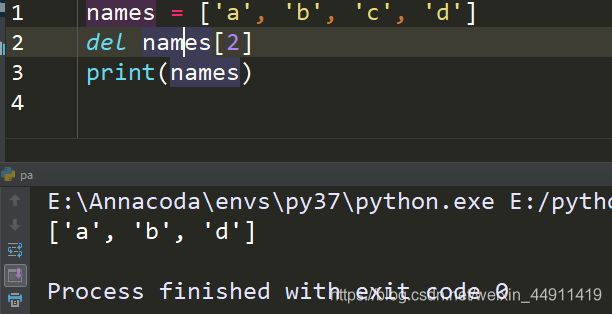
del 是一个关键字,所以想用的时候,要先写del
pop
names = ['a','b','c','d']
names.pop()
print(id(names))
remove:
names = ['a','b','c','d']
names.remove("c")
print(id(names))
del:
names = ['a','b','c','d']
del names[2]
print(names)
(3)查找元素所在位置 index
names = ['a','b','c','d']
index = names.index("b",1,2)
print(index)

(4)统计元素的个数 count
names = ['a','b','c','d']
count = names.count("c")
print(count)
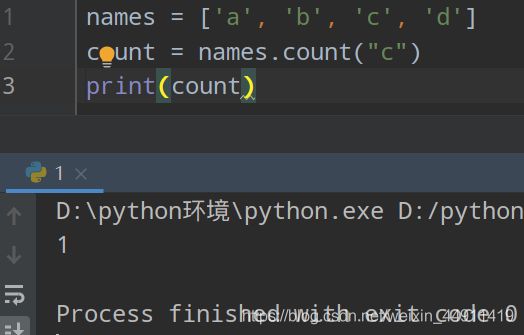
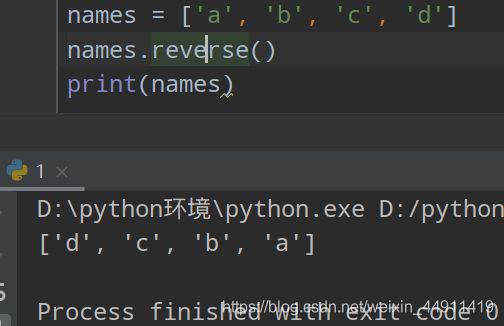
(5)反转 reverse()
names = ['a','b','c','d']
names.reverse()
print(names)
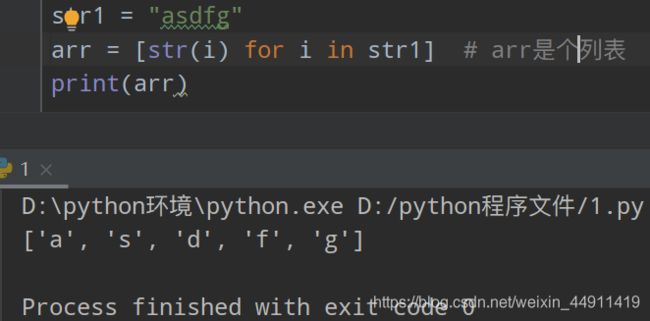
(6)字符串 – 转 --> 列表
str1 = "asdfg"
arr = [str(i) for i in str1] #arr是个列表
print(arr)
str1 = "asdfg"
arr = [str(i) for i in str1] # arr 是 个 列 表
arr.reverse()
print(arr)
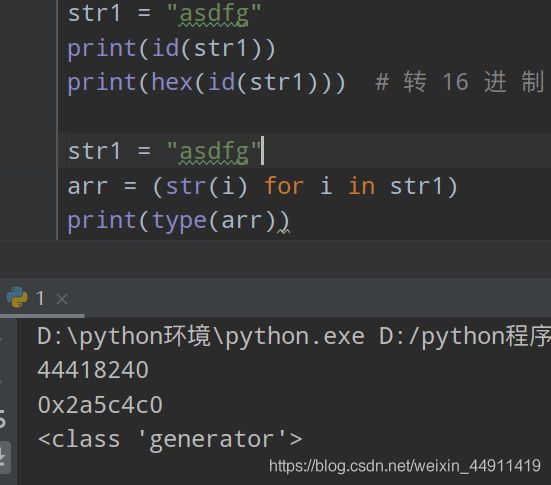
str1 = "asdfg"
print(id(str1))
print(hex(id(str1))) # 转 16 进 制
str1 = "asdfg"
arr = (str(i) for i in str1)
print(type(arr))
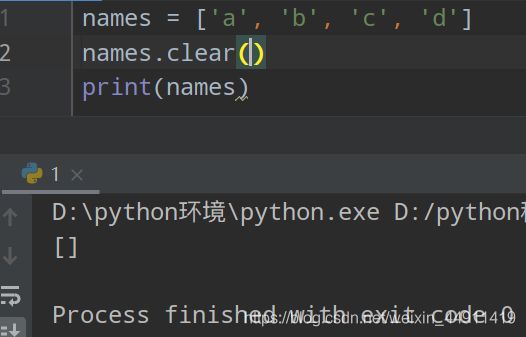
(7)清空 clear()
names = ['a','b','c','d']
names.clear()
print(names)
(8)插入 insert
names = ['a','b','c','d']
names.insert(2,"t")
print(names)

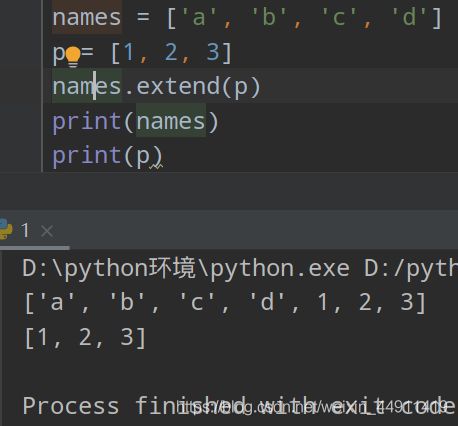
(9)拼接两个列表
names = ['a','b','c','d']
p = [1,2,3]
names.extend(p)
print(names)
print(p)
(10)对列表进行切片处理
# 列出所有的元素
names = ['a','b','c','d']
print(names[::])
print(names[-4])
print(names[0])
print(names[3])
print(names[1:3])
print(names[0:3])

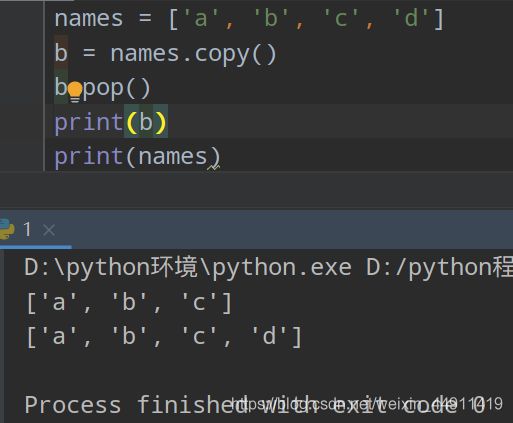
(11 )复制 copy()
names = ['a','b','c','d']
b = names.copy()
b.pop()
print(b)
print(names)
import copy
b = copy.copy(names)
b[1] = "o"
print(id(b))
print(id(names))

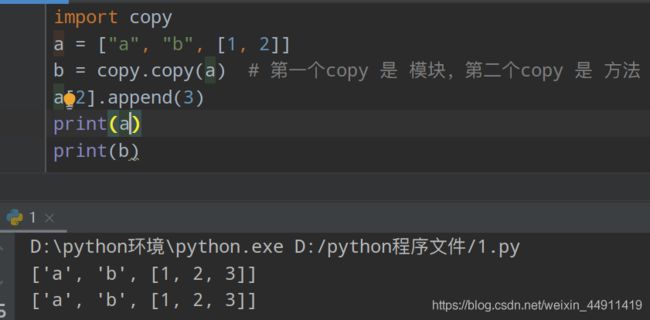
浅表复制
import copy
a = ["a","b",[1,2]]
b = copy.copy(a) # 第一个copy 是 模块,第二个copy 是 方法
a[2].append(3)
print(a)
print(b)
3、链接表
1.线性表的基本需要和链接表
实现线性表的另一种常用方式就是基于链接结构,用链接关系显式表示元素间的顺序关联。基于链接技术实现的线性表称为 链接表 或者 链表。
采用链接方式实现线性表的基本想法:
- 把表中的元素分别存储在一批独立的存储块(称为表的结点)里。
- 保证从组成表结构中的任一个结点可找到与其相关的下一个结点。
- 在前一结点里用链接的方式显式的记录与下一结点之间的关联
这样,只要能找到组成一个表结构的第一个结点,就能顺序找到属于这个表的其它结点,从这些结点里可以看到这个表里的所有元素。
2.单链表(全称:单向链接表)
链接技术是一类非常灵活的数据组织技术,实现链表有多种不同的方式。下面首先讨论最简单的单链表
:下面讨论中,将把 “存储着下一个表元素的结点” 简称为 “下一结点”
单链表的结点是一个二元组:
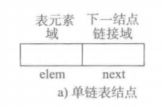
其中,表元素域 elem 保存着作为表元素的数据项(或者数据项的关联信息),链接域 next 里保存同一个表里的下一个结点的标识。
最常见形式的单链表里,与表里的n个元素对应的n个结点通过链接形成一条结点链,如下图:
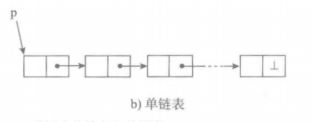
从引用表中首结点的变量P,可以找到这个表的首结点,从表中任一结点可以找到保存着该表下一个元素的结点,这样,从P出发就能找到这个表里的任一个结点。
想掌握单链表,就需要(也只需要)掌握这个表的首结点,从它出发可以找到这个表里的第一个元素(即:在这个表结点里保存的数据,保存在它的elem域中)。按照同样的方式继续下去,就可以找到表里的所有数据元素。
也就是说,为了掌握一个表,只需要用一个变量保存着这个表的首结点的引用(标识 或称为 链接)。今后把这样的变量 称为 表头变量 或 表头指针。
总结:
- 一个单链表由一些具体的表结点构成
- 每个结点是一个对象,有自己的标识,下面也常称其为该结点的链接
- 结点之间通过结点链接建立起单向的顺序联系
为方便讨论,定义一个简单的表结点类:
class LNode:
def __init__(self,elem,next_=None):
self.elem = elem
self.next = next_
# 这个类里面只有一个初始化方法,它给对象的两个域赋值。方法的第二个参数用名字 next_,
# 是为了避免与 Python标准库函数 next 重名。这也是Python程序中命名的一个惯例。
# 第二个参数还提供了默认值,只是为了使用方便。
下面来练习一下链表:

一个node结点有两个存储块,那也就是两个属性,属性1存储本结点的数据,属性2存储下一个结点的前驱
三、字符串
1、字符串的一系列操作
(1)字符串截取:
s = "abcdefg"
print(s[0:3]) # 截取前三个字符
print(s[:]) # 截取全部字符
print(s[::2]) # 步长是正数表示 正序,从左往右,隔一个一取
print(s[::-1]) # 步长是负数表述 倒序,从右往左,一个一个取

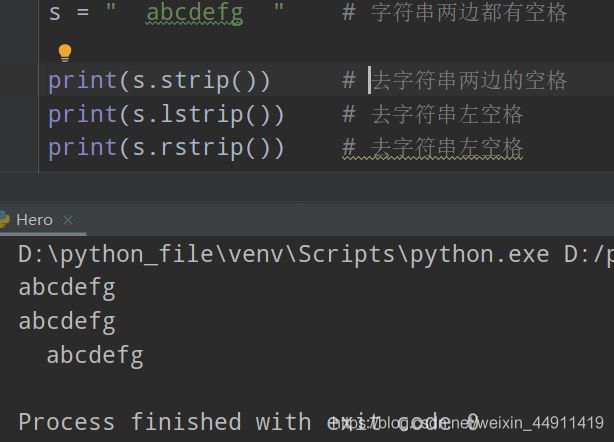
(2)去空格(去左右空格)
s = " abcdefg " # 字符串两边都有空格
print(s.strip()) # 去字符串两边的空格
print(s.lstrip()) # 去字符串左空格
print(s.rstrip()) # 去字符串左空格
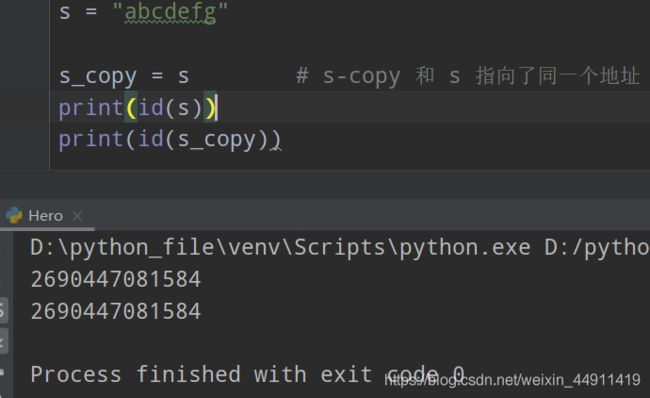
(3)字符串复制
s = "abcdefg"
s_copy = s # s-copy 和 s 指向了同一个地址
print(id(s))
print(id(s_copy))
s = "abcdefg"
s_copy = s
s = s.title()
print(s)
print(s_copy)
print(id(s))
print(id(s_copy))

所占内存ID不一样的原因,看下图内存模型:
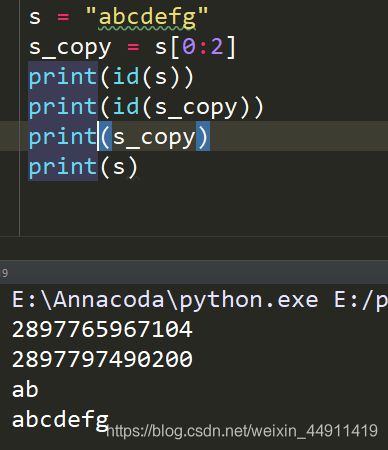
s = "abcdefg"
s_copy = s[0:2] # 字符串 截取,前两个字母
print ( id(s) )
print ( id(s_copy) )
ID不一样和上面同理!
(4)字符串连接
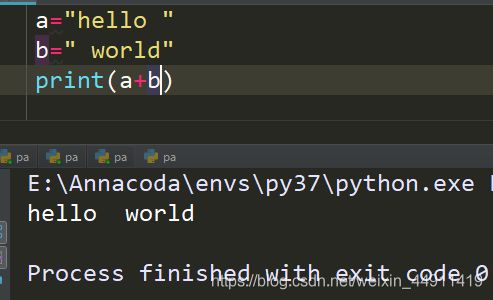
简单的拼接方法:
s = "hello"
s1 = "python"
s2 = s + s1
print(s2)

使用 模块 的拼接方法:
import operator
s = "hello"
s1 = "python"
s2 = operator.concat(s,s1)
print(s2)

lt(a, b) ———— 小于
le(a, b) ———— 小于 等于
eq(a, b) ———— 等于
ne(a, b) ———— 不等于
ge(a, b) ———— 大于 等于
gt(a, b) ———— 大于
import operator
s = " abc "
s1 = " acd "
b = operator.lt(s,s1)
print(b)
print(s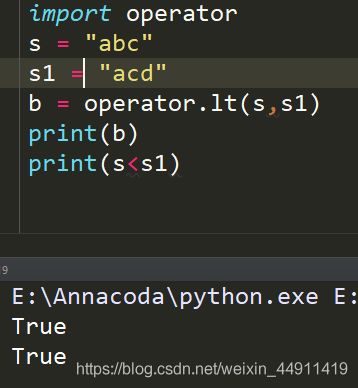
(5)字符串长度
print(len(s),len(s1))
(6)字符串中最大字符,最小字符
print(max(s))
print(min(s1))

(7)字符串大小写转换
upper ———— 转换为大写
lower ———— 转换为小写
title ———— 转换为标题(每个单词首字母大写)
capitalize ———— 首字母大写
swapcase ———— 大写变小写,小写变大写
s = "hello python"
print(s.upper()) # 转换为大写
print(s.lower()) # 转换为小写
print(s.title()) # 转换为标题(每个单词首字母大写)
print(s.capitalize()) # 首字母大写
print(s.swapcase()) # 大写变小写,小写变大写

(8)字符串分割
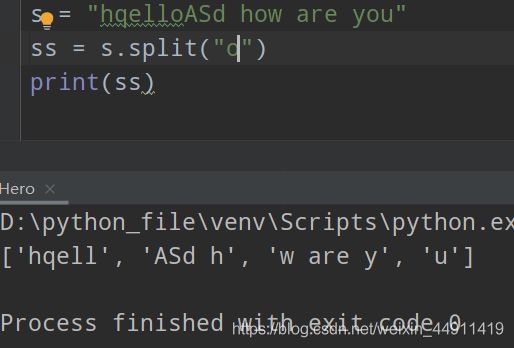
s = "hqelloASd how are you"
ss = s.split("o")
print(ss)
按 “o”进行拆
(9)字符串融合
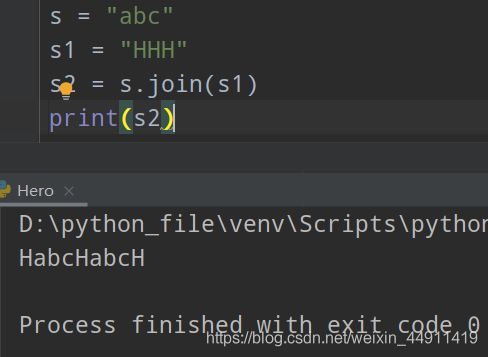
s = "abc"
s1 = "HHH"
s2 = s.join(s1)
print(s2)
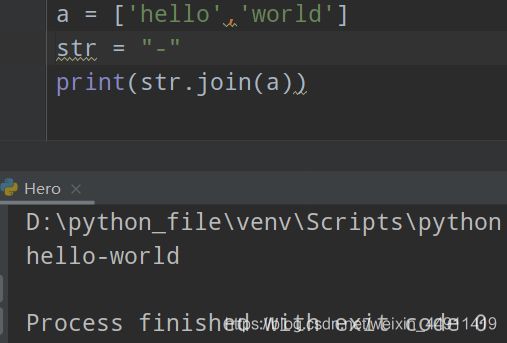
a = ['hello','world']
str = "-"
print(str.join(a))
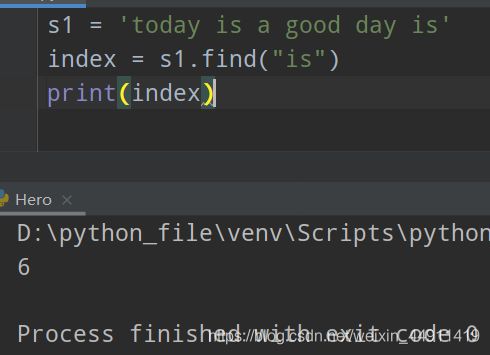
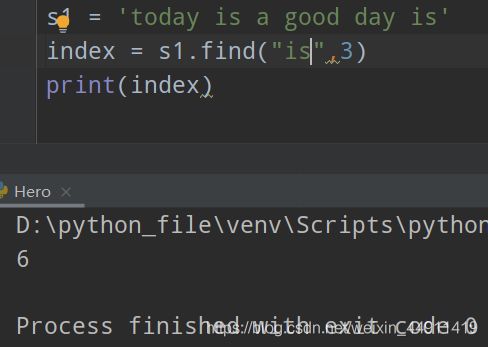
(10)字符串内查找find
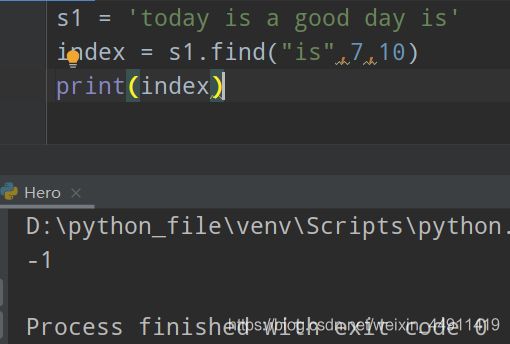
s1 = 'today is a good day is'
index = s1.find("is")
print(index)
(11)字符串内替换
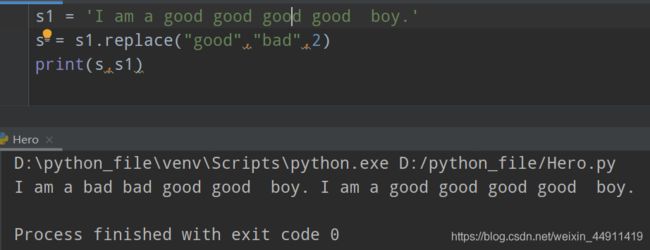
s1 = 'I am a good good good good boy.'
s = s1.replace("good","bad",50)
print(s,s1)
写“1”,替换掉一个: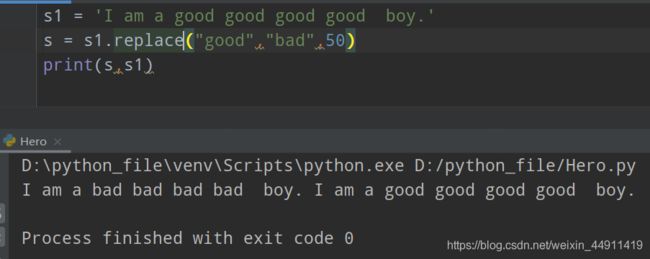
写“2”,替换掉两个:
全替换了:

s 和 s1 不一样,它会创建一个新的空间进行替换
(12)字符串判断
isdigit ———— 检测字符串时候只由数字组成
isalnum ———— 检测字符串是否只由数字和字母组成
isalpha ———— 检测字符串是否只由字母组成
islower ———— 检测字符串是否只含有小写字母
isupper ———— 检测字符串是否只含有大写字母
isspace ———— 检测字符串是否只含有空格
istitle ———— 检测字符串是否是标题(每个单词首字母大写)
s = " d "
print(s.isspace())

小练习:
s =
'Variables are used to store information to be referenced and manipulated in a computer program.
They also provide a way of labeling data with a descriptive name, so our programs can be understood
more clearly by the reader and ourselves. It is helpful to think of variables as containers that
hold information. Their sole purpose is to label and store data in memory. This data can then be
used throughout your program.'
#取出所有to
'''
c = s.find("to")
while c!=-1:
print(s[c:c+2])
c = s.find("to",c+2)
'''
'''
import urllib.request as ur
from lxml import etree
html_str = ur.urlopen("http://www.hxci.com.cn/index.php?
m=content&c=index&a=lists&catid=193").read().decode("utf-8")
print(html_str)
html = etree.HTML(html_str)
print(html)
print(html.xpath('//h3/text()'))
'''
up = ('tang', 'guo', 'li','xiu')
del up # 元素对象不支持删除
2、Python正则表达式
Python语言的正则表达式功能由 标准包re 提供。利用正则表达式可以较容易地实现许多复杂字符串操作。要想正确使用 re包,需要:
- 理解正则表达式的描述规则(语法)和效用(语义)
- 了解正则表达式的一些典型使用方法和情景。
Python正则表达式采用字符串字面量的形式描述(即:引号括起的字符序列)。从Python语音的角度看它们就是普通的字符串,但在用于re包提供的一些特殊操作时,一个具有正则表达式形式的字符串代表一个字符串模式,描述了一个特定的字符串集合。这类操作就是re包提供的正则表达式匹配操作。
re包的正则表达式描述形式实际上构成了一个特殊的小语言:
- 语法:re包规定的一套特殊描述规则,符合这组规则的字符串就是正则表达式,可以用在re包提供的各种匹配操作中
- 语义:一个正则表达式所描述的字符串集,这也是介绍的重点。
正则表达式的使用
在一些情况中,目标串里可能存在一些(可能很多)与所用正则表达式匹配的子串,需要逐个处理。这种情况下,采用匹配迭代器的方法最简便。编程模式是:
rel = re.compile(pattern) # 这里写实际的模式串
for mat in rel.finditer(text): # text是被匹配的目标串
... mat.group() ... # 取得被匹配的子串,做所需操作
...text[mat.start()] ... text[mat.end()] ...
注意:
操作 mat.group()、mat.start() 和 mat.end() 都只能访问被匹配串的内容,所做操作不能(也不会)修改目标串。如果需要基于正则表达式做字符串的匹配和代换(生成代还后的串),首先应该考虑能不能用正则表达式的sub方法。如果能直接写出准备代入的新串与被匹配的子串有关,可以按某种规则从被匹配的串构造出来,就应该定义一个函数来生成新串,以这个函数作为sub方法的repl参数。
处理更复杂的匹配情况时,可能需要逐一确定匹配成功的位置,然后完成所需操作。每次匹配可能使用不同的模式。这种循环自然应该用while描述:用一个记录位置的变量pos存储匹配的起始位置,在每次循环迭代中正确更新pos的值。
四、栈和队列
什么是栈,什么是队列?
答:
栈像个杯子,它是有底的,进栈的顺序是1—>2—>3,那么从栈里取数据的顺序就是3—>2—>1;先进后出!
队列就像一个管道,下面是通的,存数据是1—2---3,那么取数据呢,因为没有底,就是1—2---3;先进先出!
2.栈:概念和实现
先进后出FILO
栈的实现也可以用列表实现
追加 — push,
删除最后一个 — pop
查看 — peek
长度 — length
#栈实现
# 空 栈 异 常
class NullStackError(BaseException):
def __init__(self):
super().__init__("null stack error !!!")
class MyStack():
def __init__(self,len=0,list=None): # 构造函数;list有个默认值None
self.__len = 0
self.__list = list
#追 加
def push(self,data):
self.__list.append(data)
self.__len += 1
#删 除 最 后 一 个
def pop(self):
temp = None
if self.__len == 0:
raise NullStackError()
else:
temp = self.__list.pop()
self.__len -= 1
return temp
#查 看 最 后 一 个 元 素
def peek(self):
if self.__len == 0:
raise NullStackError()
else:
return self.__list[-1]
#查 看 长 度
def length(self):
return self.__len
三种表达式:
前缀表达式
中缀表达式
后缀表达式
前缀表达式 后缀表达式 中缀表达式(从右往左查)
a+b*c -d abc*+ d- -d +*bca
(a+b)*c ab+c* *c+ab
(a+b)*(c-d)/e ab+ cd- * e/ /e*-cd+ab
优先级 高 就 入栈,
优先级 低 就 往外取

3、队列
增只能增队尾,删只能删队头
先进先出FIFO
1-普通队列
#普通队列
class myQuene(object):
def __init__(self,list=[]):
self.__list = list
def size(self):
return len(self.__list)
def delete(self):
if self.size()==0:
print("空队列布不能删除")
else:
temp_delete = self.__list[0]
del self.__list[0]
return temp_delete
def insert(self,data):
self.__list.append(data)
def peek(self):
if self.size()==0:
print("空队列布不能删除")
else:
return self.__list[0]
2-优先队列
#优先级队列
class myQuene(object):
def __init__(self,list=[]):
self.__list = list
def size(self):
return len(self.__list)
def delete(self):
if self.size()==0:
print("空队列布不能删除")
else:
temp_delete = self.__list[0]
del self.__list[0]
return temp_delete
def insert(self,data):
if self.size()==0:
self.__list.append(data) #若队列为空,将数据直接插入
else:
temp = -1
for i in range(len(self.__list)):
if self.__list[i] > data:
temp = i
break
if temp==-1:
self.__list.append(data)
else:
self.__list.insert(temp,data)
def peek(self):
if self.size()==0:
print("空队列布不能删除")
else:
return self.__list[0]
q = myQuene()
q.insert(1)
q.insert(2)
q.insert(4)
q.insert(3)
print(q.delete())
print(q.delete())
print(q.delete())
print(q.delete())
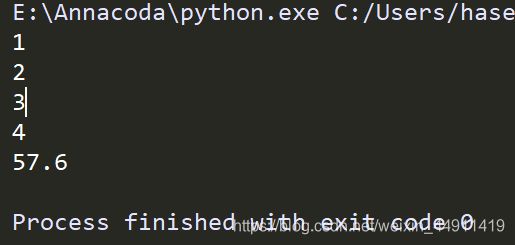
3-循环队列
class xunhuan():
def __init__(self,list=[],first=None,last=None):
self.__list = list
self.__last = last
self.__first = first
def size(self):
length = 0
if self.__last > self.__first:
length = self.__last-self.__first+1
elif self.__last == self.__first and self.__last != None:
length = 1
elif self.__last == self.__first and self.__last == None:
length =0
else:
length = len(self.__list)-(self.__first - self.__last-1)
return length
def insert(self,data):
if self.size()==0:
self.__list.append(data)
self.__first = 0
self.__last = 0
else:
if self.size()==len(self.__list):
self.insert(self.__last+1,data)
self.__last = self.__last+1
else:
if self.__last+1==len(self.__list):
self.__list[0] = data
self.__last = 0
else:
self.__list[self.__last+1] = data
self.__last = self.__last+1
def delete(self):
if self.size() == 0:
print("空队列,无法删除")
elif self.size() == 1:
temp = self.__list[self.__first]
self.__first = None
self.__last = None
return temp
else:
temp = self.__list[self.__first]
if self.__first+1==len(self.__list):
self.__first = 0
else:
self.__first = self.__first+1
return temp
def peek(self):
if self.size() == 0:
print("空队列")
else:
return self.__list[self.__first]

五、二叉树和树
1、二叉树:概念和性质
2、二叉树的 list实现
3、优先队列
4、应用:离散事件模拟
5、二叉树的类实现
6、哈夫曼树
7、树和森林
六、图
1、概念、性质和实现
2、图结构的Python实现
3、基本图算法
4、最小生成树
5、最短路径
6、AOV/AOE网及其算法
七、字典和集合
1、数据存储、检索和字典
2、字典线性表实现
3、散列和散列表
4、集合
set是一个无序的不重复元素序列
set={1,"2",(3,2)}
print (set)
# 得:set([1, (3, 2), '2']) ;
# 看到数据结构后着实让人发现原来set集合内部结构也是一个列表。
# 这就不难理解为什么可以用set给list列表去重
set={1,"2",(3,2)} # 集合只能存放不可变类型,可变类型放入后会报错
print (set)
list=[4,5,6]
dict2={"9":"10"}
set={6,7,8}
# set.add(list) #TypeError: unhashable type: 'list'
# set.add(dict2) #TypeError: unhashable type: 'dict'
# set.add(set) #TypeError: unhashable type: 'set'
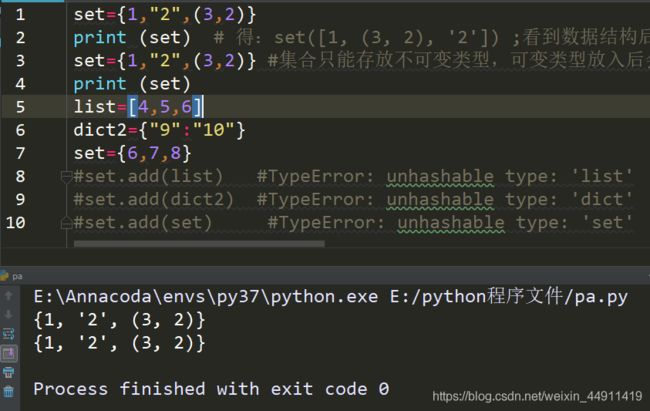
5、Python的标准字典类dict和set
字典Dictionary:
列表 是有序的对象集合,字典 是无序的对象集合
【 键 必须是唯一的,但值则不必;值 可以取任何数据类型,但键必须是不可变的 】
d = {(2,3):1,(1,2):2,(1,3):4}
import operator
ds = sorted(d.items(),key = operator.itemgetter(0))
print(ds)
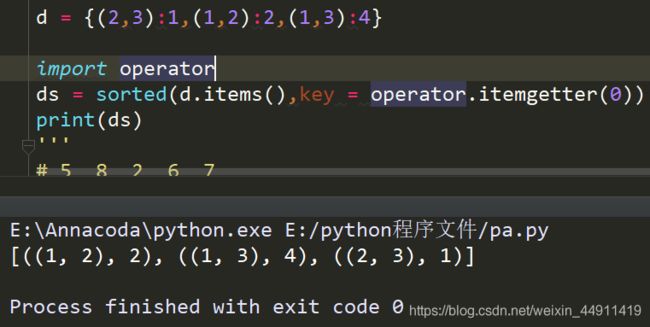
dict2={ 1:1, "2":"2", (3):(3) }
print (dict2) # 得 {3: 3, 1: 1, '2': '2'} 元组类型发生了改变
dict2={ 1:1, "2":"2", (3,2):(3,2) }
print (dict2) # {1: 1, (3, 2): (3, 2), '2': '2'} 元组未发生改变
dict2={ 1:1, "2":"2", (3,2):(3,2), 4:[5], "5":{"66":"66"}, (3):{"77","88"} } #键必须是不可变的,值可以是任何类型:依次为数字,字符,元组,列表,字典,set集合
print (dict2) # 得 {1: 1, (3, 2): (3, 2), 3: set(['77', '88']), 4: [5], '2': '2', '5': {'66': '66'}}
6、二叉排序树和字典
7、平衡二叉树
8、动态多分支排序树
八、排序
- 内置排序(没什么技术含量,一个方法就给排了)
- 冒泡排序
- 插入排序
- 选择排序
- 希尔排序
- 堆排序(需要数据结构的基础)
- 快速排序
- 归并排序
1. 内置排序
a = [9,5,8,7,4,3,1,6,2,0] # 列表
b = a.sort()
print(b) # 没有return 就没有返回值
print(a) # 升序排列

验证一个问题:看查询地址,看两次a的地址是不是一样
a = [9,5,8,7,4,3,1,6,2,0] # 列 表
print(id(a))
a.sort()
print(id(a))
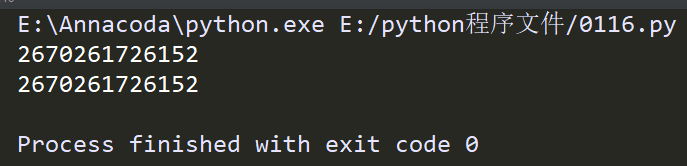
a = [9,5,8,7,4,3,1,6,2,0]
b = sorted(a)
print(id(a))
print(id(b))
print(b)

两种方法的 id 值一样,那是应该选择上面的还是选择下面的呢?
——如果排完序之后,原数组就没有用了,那就选上面的(因为原数组如果用不上了,就占内存了),如果原数组还有用,就选下面的!
2. 冒泡排序
简单冒泡:
思想:
用第一个数 和 后面的每一个数进行比较,前面的如果比后面的值大就换一下位置,如果前面比后面小 就不换,循环一次可以把最小的数给确定
第一次循环把 第一位数 给确定了,第二次排序把 第二位数 确定了。。。
a = [5,8,9,3,2] # 五个值得循环四次,从最小,次小,,,的找,直到只剩最大值,就是最后一位
for i in range(len(a)-1): # i 代表前面比较数的下标,第一次i代表“5”
for j in range(i+1,len(a)): # j 代表后面几个待被比较数的下标,第一次j代表“8,9,,3,2’”
if a[i] > a[j]: # 前面的值和后面的值比较
# 比 较 出 大 小 了 ,下 面 进 行 交 换 ;需 要 定 义 一 个 临 时 变 量 temp
temp = a[i]
a[i] = a[j]
a[j] = temp
del temp # 只是删除temp这个地址
print(a)

复杂点的冒泡:
思想:相邻两元素进行相比

a = [5,8,9,3,2]
for i in range(len(a)-1): # 5个数,循环四次,总长是5,减1
for j in range(len(a)-1-i):
if a[j]>a[j+1]: # 第一个数和相邻的数相比
temp = a[j]
a[j] = a[j+1]
a[j+1] = temp
del temp
print(a)
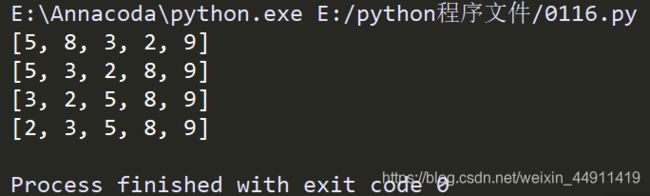
改进冒泡排序:
思想:第一次循环确定最大值
a = [1, 2, 3, 4, 5, 6, 8, 9, 7]
count = 0
for i in range(len(a) - 1):
flag = False # 加 一 个 标 记
count += 1 # 计 数 ,循 环 几 次
for j in range(len(a) - 1 - i):
if a[j] > a[j + 1]:
temp = a[j]
a[j] = a[j + 1]
a[j + 1] = temp
del temp
flag = True
if not flag: # 如 果 flag 为 非 ,不 走
break
print(a)
print(count) # 打 印 count ,看 循 环 了 几 次
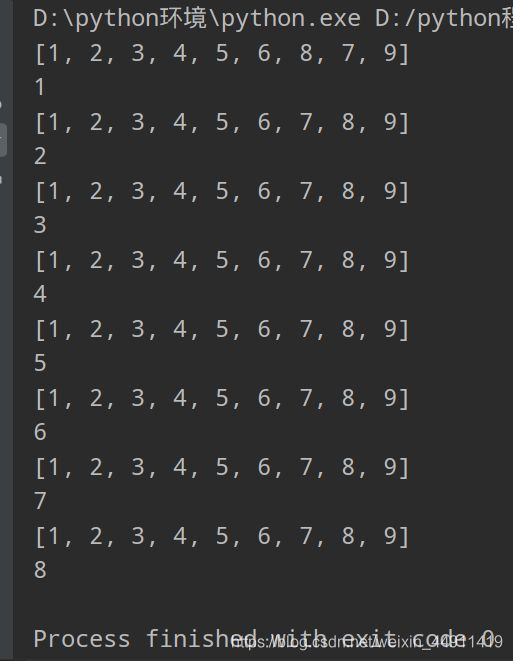
3. 选择排序
思想:每个排序都有下标
a = [5,8,9,3,2]
for i in range(0,len(a)-1): # i 代表要交换的位置
min_index = i
for j in range(i+1,len(a)): #
if a[min_index]>a[j]: # 每次都和最小值比
min_index = j
if min_index!=i: # 只有它不等于 i 的时候才可以交换
temp = a[i]
a[i] = a[min_index]
a[min_index] = temp
del temp
# temp可以删,可以不删,其实就算del了,也没有真删掉(内存清理还是靠垃圾回收机制,
# 垃圾回收机制也是线程,只是级别很低,属于守护线程,所以cpu调用它的时候概率很低)
print(a)

4.插入排序
( 找到一个合适位置:左侧比它小,右侧比它大的位置插入进去 )
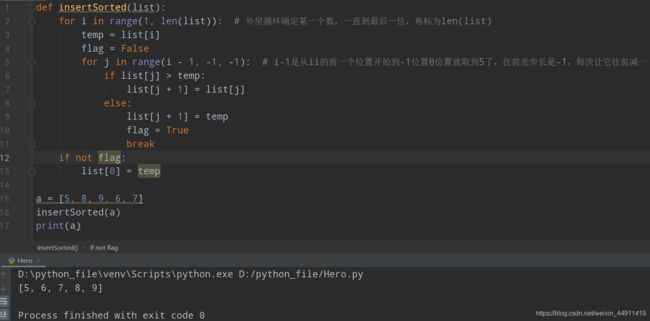
def insertSorted(list):
for i in range(1,len(list)): # 外层循环确定某一个数,一直到最后一位,角标为len(list)
temp = list[i]
flag = False
for j in range(i-1,-1,-1): # i-1是从ii的前一个位置开始到-1位置0位置就取到5了,往前走步长是-1,每次让它往前减一
if list[j]>temp:
list[j+1] = list[j]
else:
list[j+1] = temp
flag = True
break
if not flag:
list[0] = temp
a = [5,8,9,6,7]
insertSorted(a)
print(a)
1、简单排序算法
2、快速排序
3、归并排序
4、其它排序方法
4. 元组Tuple:
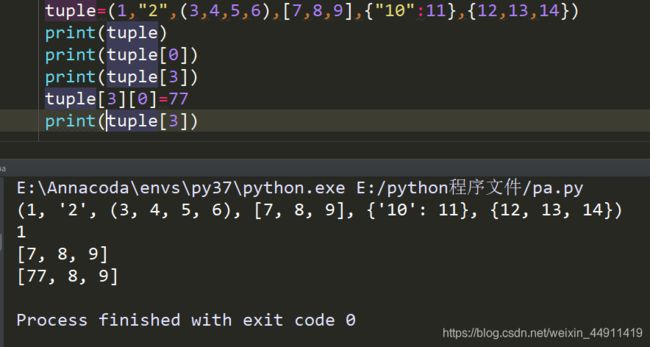
元组(tuple) 与 列表 类似,元组不能二次赋值。
[ 元组本身是只读对象,如果元组中的对象是可变类型数据,可变类型数据依然可以修改 ]
tuple=(1,"2",(3,4,5,6),[7,8,9],{"10":11},{12,13,14})
print(tuple)
print(tuple[0])
print(tuple[3])
tuple[3][0]=77
print(tuple[3])
总结:
-
list列表 可以存储的数据类型: 数字,字符串,元组,列表,字典,set
-
tuple元组 可以存储数据类型: 数字,字符,元组,列表,字典,set
-
dict字典 可以存储数据类型: 分别说:键(不可变),值(数字,字符,元组,列表,字典,set集合)
-
set集合 可以存储数据类型: 不可变类型(数字,字符,元组)
续:怎么给列表中检查入元素?
‘’’
class first_linked_last():
def __init__(self,first=None,last=None):
self.__first = first
self.__last = last
# 插入
def insert_first(self,data):
n = node(data)
if self.__first == None:
self.__first = n
self.__last = n
else:
n.set_next(self.__first)
self.__first = n
def insert_last(self,data):
n = node(data)
if self.__first == None:
self.__first = n
self.__last = n
else:
self.__last.set_next(n)
self.__last = n
def insert(self,data0,data):
n = node(data)
if self.__first == None:
self.__first = n
self.__last = n
else:
currentnode = self.__first
flag = False
while currentnode.get_next()!=None:
if currentnode.get_data()==data0:
flag = True
break
else:
currentnode = currentnode.get_next()
if flag:
n.set_next(currentnode.get_next())
currentnode.set_next(n)
else:
if currentnode.get_data()==data0:
self.insert_last(data)
# 删 除
def delete_first(self):
if self.__first == None: # 先判断是不是空链表,如果是 空链表 给个打印异常的操作
print("空链表,不能删除")
else:
self.__first = self.__first.get_next()
def delete(self,data): # 删除一个元素data
if self.__first == None: # 判断是不是空链表
print("空链表,不能删除")
else:
currentnode = self.__first
precurrentnode = self.__first # 记录上一个元素的node值
flag = False
while currentnode.get_next!=None: # 开始找,不等于零,证明后面有很多元素
if currentnode.get_data()==data: # 判断,如果他俩相等了
flag = True
break
else:
precurrentnode = currentnode
currentnode = currentnode.get_next()
if flag:
if currentnode == precurrentnode:
self.delete_first()
else:
precurrentnode.set_next(currentnode.get_next())
else:
if currentnode.get_data() == data:
precurrentnode.set_next(None)
self.__last = precurrentnode
# 修 改
def update_first(self,data):
if self.__first == None:
print("空链表,不能修改")
else:
self.__first.set_data(data)
def update_last(self,data):
if self.__first == None:
print("空链表,不能修改")
else:
self.__last.set_data(data)
def update(self,data0,data): # 传俩值,一个是原值,一个是新值,替换成data
if self.__first == None:
print("空链表,不能修改")
else:
currentnode = self.__first
flag = False
while currentnode.get_next!=None:
if currentnode.get_data() == data0: # 咱们要找的值,要修改它data1
flag = True
break
else:
currentnode = currentnode.get_next()
if flag: # 循环结束,判断
currentnode.set_data(data)
else:
self.update_last(data)
# 查 询
def show(self):
if self.__first == None:
print("该链表为空")
else:
currentnode = self.__first
while currentnode!=None:
print(currentnode.get_data())
currentnode = currentnode.get_next()
a = first_linked_last()
a.inser_first("小一")
a.inser_last("小二")
a.insert("小三","小四")
a.inser_first("小五")
a.update_first("小六")
a.update_last("小七")
a.update(“小七’","小九")
a.delete_first()
a.delete("小九")
a.show()

单链表
双端链表
双向链表
class NullLinkedError(BaseException):
def __init__(self):
super().__init__("null linked error")
class node():
#content:创建节点,表示链表中元素,有三个属性,
# pre-前驱结点地址
# data-数据
# next-后继结点地址
def __init__(self,data,pre=None,next=None):
self.__pre = pre
self.__data = data
self.__next = next
def get_data(self):
return self.__data
def set_data(self,data):
self.__data = data
def get_next(self):
return self.__next
def set_next(self,next):
self.__next = next
def get_pre(self):
return self.__pre
def set_pre(self,pre):
self.__pre = pre
class double_linked():
def __init__(self,len=0,first=None,last=None):
self.__len = 0
self.__first = first
self.__last = last
def insert_first(self,data):
#首先判断是否是空链表
n = node(data=data)
if self.__len==0:
self.__first = n
self.__last = n
else:
n.set_next(self.__first)
self.__first.set_pre(n)
self.__first = n
self.__len += 1
def insert_last(self,data):
n = node(data=data)
if self.__len == 0:
self.__first = n
self.__last = n
else:
n.set_pre(self.__last)
self.__last.set_next(n)
self.__last = n
self.__len += 1
def insert(self,data0,data):
n = node(data=data)
if self.__len == 0:
raise NullLinkedError()
else:
currentnode = self.__first
flag = False
while currentnode!=None:
if currentnode.get_data()==data0:
if currentnode.get_next()!=None:
n.set_next(currentnode.get_next())
n.set_pre(currentnode)
currentnode.set_next(n)
currentnode.get_next().set_pre(n)
self.__len += 1
else:
self.insert_last(data)
flag = True
break
else:
currentnode = currentnode.get_next()
if flag:
print("插入成功")
else:
print("插入失败")
#删除头结点,若空抛出异常,否则删除头元素
def delete_first(self):
if self.__len == 0:
raise NullLinkedError()
else:
if self.__len == 1:
self.__first = None
self.__last = None
else:
self.__first = self.__first.get_next()
self.__first.set_pre(None)
self.__len -= 1
# 删 除 尾 结 点,若 空 抛 出 异 常,否 则 删 除 尾 元 素
def delete_last(self):
if self.__len == 0:
raise NullLinkedError()
else:
if self.__len == 1:
self.__first = None
self.__last = None
else:
self.__last = self.__last.get_pre()
self.__last.set_next(None)
self.__len -= 1
def delete(self,data):
if self.__len == 0:
raise NullLinkedError()
elif self.__len == 1 :
if self.__first.get_data()==data:
self.__first = None
self.__last = None
self.__len -= 1
else:
currentnode = self.__first
while currentnode!=None:
if currentnode.get_data()==data:
if currentnode.get_pre()==None:
self.delete_first()
elif currentnode.get_next()==None:
self.delete_last()
else:
currentnode.get_pre().set_next(currentnode.get_next())
currentnode.get_next().set_pre(currentnode.get_pre())
self.__len -= 1
break
else:
currentnode = currentnode.get_next()
# 修 改
def update_first(self,data):
if self.__len == 0:
raise NullLinkedError()
else:
self.__first.set_data(data)
def update_last(self,data):
if self.__len == 0:
raise NullLinkedError()
else:
self.__last.set_data(data)
def update(self,data0,data):
if self.__len == 0:
raise NullLinkedError()
else:
currentnode = self.__first
flag = False
while currentnode!=None:
if currentnode.get_data()==data0:
currentnode.set_data(data)
flag = True
break
else:
currentnode = currentnode.get_next()
if flag:
print("修改成功")
else:
print("修改失败")
def show_info(self):
if self.__len == 0:
print("空链表")
else:
currentnode = self.__first
while currentnode!=None:
print(currentnode.get_data())
currentnode = currentnode.get_next()
def length(self):
return self.__len
d = double_linked()
d.insert_first("啊啊啊")
d.insert_first("caoyang")
d.insert_last("huojinxu")
d.insert_last("wangyexiu")
print(d.length())
d.show_info()
d.delete_first()
d.delete_last()
print(d.length())
d.show_info()
d.insert_first("ABC")
d.insert_last("cy")
d.insert_last("hh")
d.delete("cy")
d.show_info()
print(d.length())
四、树
从根往下一个一个往下找
树可以用几种方式定义。定义树的一种自然的方式是递归方式。一棵树是一些节点的集合。这个集合可以是空集;
根、边、树叶(叶子)、兄弟、祖父和孙子、路径(从一条节点到另一条节点所经过的路径)、路径的长(所经过的边数)、深度(从根节点到该节点所走路径的长)、广度、高度(从该节点到底下最深处的节点)(树的高度,还是 对于某个根节点的高度)、真祖先和真后裔(祖先n1和后裔n2,n1 和 n2 不相等)
给你一个A,需要把它变成节点 node, 然后写进树里
树的实现:
class TreeNode():
def __init__(self, data, firstchild, nextSibling): # 定义三个属性
self.data = data
self.firstchild = firstchild
self.nextSibling = nextSibling
-------------------------------------------
class Tree():
# 树要一个树根
def __init__(self):
self.root = None
def append(self,data,firstchild,nextSibling):
# 树里面存的是一个节点一个节点的,把一个数data先变成node,再把node添加到树里
node = TreeNode(data,firstchild,nextSibling)#括号里得传三个参数
if self.root == None:
self.root = node
else:
pass
def
树的遍历:
深度优先(一层一层查)
广度优先(一条一条查)
先序遍历: 根–左--右
中序遍历: 左–根--右
后序遍历: 左–右--根
1、 二叉树:
二叉树最多两个孩子
一般 左边的孩子 小;右边的孩子 大
左右孩子都是空的节点是 叶子节点
1. 平衡二叉树
2. 二叉查找树
一个树,想找一个数还是挺难的
思想是:拿一个数和根节点比较,比根节点小就往左找,比根节点大就往右找
查找树ADT —— 二叉查找树(也叫搜索树),左小 右大
class TreeNode():
def __init__(self,data,firstchild,nextSibling):#定义三个属性
self.data = data
self.firstchild = firstchild
self.nextSibling = nextSibling
class Tree():
def __init__(self):
self.root = None # 树根
# 二叉树不用什么又是增加,又是插入的,增 方 法
def add(self,data): # 首先看里面数据
node = TreeNode(data) #创建一个node对象,data是默认值
if self.root == None: # 说明这是一个空树
self.root = node
else:
currentNode = self.root # 如果不是空,就和根节点进行比较
while True:
#大于往右走,小于往左走
if data < self.root.data:
if currentNode.left==None:
currentNode.left = node
break
else:
currentNode = currentNode.left # currentNode是根节点
continue # 结束当前循环
else:
if currentNode.right == None:
currentNode.right = node
break
else:
currentNode = currentNode.right
continue
# 是 否 包 含 数 据
def contains(self,data):
flag = False
if self.root == None:
print("空树")
else:
currentNode = self.root
while True:
if currentNode.data==data:
flag = True
break
else:
if currentNode.data > data:
currentNode = currentNode.left
else:
if currentNode.right == None:
break
currentNode = currentNode.right
return flag
# 查 找 最 小 值,一 路 向 左
def findMin(self):
temp_min = None
if self.root == None:
print("空树")
else:
currentNode = self.root
while currentNode.left != None: # 判断左孩子是不是等于空
currentNode = currentNode.left # 如果左孩子不等于空,让当前节点等于左孩子
return temp_min
#找 最 大 值,一 路 往 右
def findMax(self):
temp_max = None
if self.root == None:
print("空树")
else:
currentNode = self.root
while currentNode.right != None:
currentNode = currentNode.right:
return temp_max
# 删 除
def remove(self,data):
# 没有孩子的子节点
if self.contains(data):
# 树 中 有 要 删 除 的 数 据
pre_currentNode = None
currentNode = self.root
while true:
if currentNode.data == data:
# 第一种情况:叶子节点
if currentNode.left==None and currentNode.right == None:
del currentNode
# 第二种情况:一个孩子的节点
elif currentNode.left == None and currentNode.right != None
if pre_currentNode == None:
self.root = currentNode.right
else:
if pre_currentNode.right.data == currentNode.data:
pre_currentNode.right = currentNode.right
else:
pre_currentNode.left = currentNode.right
# 第三种情况:两个孩子的节点
else:
if data < currentNode
else:
if data < currentNode.data:
pre_currentNode = currentNode
currentNode = currentNode.left
else:
pre_currentNode = currentNode
currentNode = currentNode.right
else:
# 树 中 没 有 要 删 除 的 数 据
print("数 据 不 存 在")
# (遍历 深度优先) 于 show 的 遍 历 尽 量 不 用 循 环 ,, 递 归 就 是 在 自 己 方 法 里 面 自 己 调 用 自 己
def showAll(self,root):
if root == None:
print("空树")
else:
if self.root.data==root.data:
print(root.left.data) # 根节点不为空,先把根节点打出来
if root.left != None: # 左不为空调自己(递归)
print(root.left.data)
self.showAll(root.left)
if root.right!=None: # 右不为空调自己(递归)
print(root.right.data)
self.showAll(root.right)
tree = Tree()
tree.add(1)
tree.add(2)
tree.add(3)
tree.add(4)
tree.add(5)
tree.add(6)
tree.showAll(tree.root) # 传tree.root, 它是根节点
f = tree.contains(3)
print(f)
3. 平衡二叉查找树
1- AVL树(平衡树)
是一棵比较特殊的二叉查找树--------> 带有平衡的二叉查找树
左右子树高度差不大于1
插入 或者 删除 时会出现不平衡
单旋转:左旋 和 右旋
双旋转:先局部,再整体(其实就是两步单旋合并); 两种情况,先左后右 和 先右后左
插入数据后,看树平不平衡,不平衡就旋转,具体看是 左旋 还是 右旋
实现:
step1: 判断插入操作是否破坏平衡
step2: 如果平衡破坏了,选择单旋还是双旋
1. 对该节点的左儿子的左子树进行行一次插入。(右)
2. 对该节点的左儿子的右子树进行行一次插入。(先左后右)
3. 对该节点的右儿子的左子树进行行一次插入。(先右后左)
4. 对该节点的右儿子的右子树进行行一次插入。(左)
step3: 旋转
2- 红黑树
树 ---> 二叉树 ---> 查找树 ---> 红黑树(红黑树的优缺点:提高了插入速度,但是查询速度和平衡树相比稍微降低了)
|-----> 平衡树(平衡树的优缺点:提高了查找速度,但是降低了插入速度)
字典的底层就是一个红黑树,是一个接近于平衡树的一个二叉树
二叉查找树特性:左子树上所有的节点的值都小于或者等于它的根节点上的值;右子树上所有的节点的值均大于或等于它的根节点的值,左右子树也分别为平衡二叉树
特性:
节点是红色或者黑色,根节点一定是黑色,每个叶节点都是黑色的空节点(NIL节点);
每个红节点的两个子节点都是黑色的(从每个叶子到根的所有路径上不能有两个连续的红节点)(即对于层来说除了NIL节点,红黑节点是交替的,第一层是黑节点那么其下一层肯定都是红节点,反之一样)
从任一节点到其每个叶子节点的所有路径都包含相同数目的黑色节点。正是由于这些原因使得红黑树是一个平衡二叉树
3- 伸展树
4- 三叉树
五、散列表:
散列表 的实现常常叫做 散列。散列是一种用于以常数平均时间执行插入、删除和查找的技术。但是,那些需要元素间任何排序信息的数操作将不会得到有效的支持。因此,诸如findMin、findMax以及以线性时间将排过序的整个表进行打印的操作都是散列所不支持的。
解决冲突的第一种方法,叫分离链接法,将散列到同一个值(散列函数:f(x)=x%10)的所有元素保留到一个表中(单向链表)
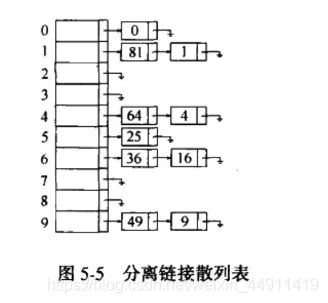
一、哈希表:
1.存储结构:
- 普通哈希表
- 带有单向链表的哈希(冲突)
- 单向链表可换成查找树
2.散列函数(太多太多了,现在只举一种):f(x)=x%10
3.锁,分段锁
二、哈夫曼编码:
压缩