林炳文Evankaka
原创作品。转载请注明出处 http://blog.csdn.net/evankaka
摘要:本文将使用Python3.4爬网页、爬图片、自动登录。并对HTTP协议做了一个简单的介绍。在进行爬虫之前,先简单来进行一个HTTP协议的讲解,这样下面再来进行爬虫就是理解更加清楚。
一、HTTP协议
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP的请求响应模型
HTTP协议永远都是客户端发起请求,服务器回送响应。见下图:
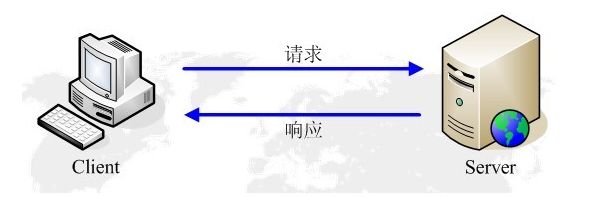
这样就限制了使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端。
HTTP协议是一个无状态的协议,同一个客户端的这次请求和上次请求是没有对应关系。
工作流程
一次HTTP操作称为一个事务,其工作过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了
请求报头
请求报头允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。
常用的请求报头
Accept
Accept请求报头域用于指定客户端接受哪些类型的信息。eg:Accept:image/gif,表明客户端希望接受GIF图象格式的资源;Accept:text/html,表明客户端希望接受html文本。
Accept-Charset
Accept-Charset请求报头域用于指定客户端接受的字符集。eg:Accept-Charset:iso-8859-1,gb2312.如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。
Accept-Encoding
Accept-Encoding请求报头域类似于Accept,但是它是用于指定可接受的内容编码。eg:Accept-Encoding:gzip.deflate.如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
Accept-Language
Accept-Language请求报头域类似于Accept,但是它是用于指定一种自然语言。eg:Accept-Language:zh-cn.如果请求消息中没有设置这个报头域,服务器假定客户端对各种语言都可以接受。
Authorization
Authorization请求报头域主要用于证明客户端有权查看某个资源。当浏览器访问一个页面时,如果收到服务器的响应代码为401(未授权),可以发送一个包含Authorization请求报头域的请求,要求服务器对其进行验证。
Host(发送请求时,该报头域是必需的)
Host请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的,eg:
我们在浏览器中输入:http://www.guet.edu.cn/index.html
浏览器发送的请求消息中,就会包含Host请求报头域,如下:
Host:www.guet.edu.cn
此处使用缺省端口号80,若指定了端口号,则变成:Host:www.guet.edu.cn:指定端口号
User-Agent
我们上网登陆论坛的时候,往往会看到一些欢迎信息,其中列出了你的操作系统的名称和版本,你所使用的浏览器的名称和版本,这往往让很多人感到很神奇,实际上,服务器应用程序就是从User-Agent这个请求报头域中获取到这些信息。User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。不过,这个报头域不是必需的,如果我们自己编写一个浏览器,不使用User-Agent请求报头域,那么服务器端就无法得知我们的信息了。
请求报头举例:
GET /form.html HTTP/1.1 (CRLF)
Accept:image/gif,image/x-xbitmap,image/jpeg,application/x-shockwave-flash,application/vnd.ms-excel,application/vnd.ms-powerpoint,application/msword,*/* (CRLF)
Accept-Language:zh-cn (CRLF)
Accept-Encoding:gzip,deflate (CRLF)
If-Modified-Since:Wed,05 Jan 2007 11:21:25 GMT (CRLF)
If-None-Match:W/"80b1a4c018f3c41:8317" (CRLF)
User-Agent:Mozilla/4.0(compatible;MSIE6.0;Windows NT 5.0) (CRLF)
Host:www.guet.edu.cn (CRLF)
Connection:Keep-Alive (CRLF)
(CRLF)
- GET /form.html HTTP/1.1 (CRLF)Accept:image/gif,image/x-xbitmap,image/jpeg,application/x-shockwave-flash,application/vnd.ms-excel,application/vnd.ms-powerpoint,application/msword,*/* (CRLF)Accept-Language:zh-cn (CRLF)Accept-Encoding:gzip,deflate (CRLF)If-Modified-Since:Wed,05 Jan 2007 11:21:25 GMT (CRLF)If-None-Match:W/"80b1a4c018f3c41:8317" (CRLF)User-Agent:Mozilla/4.0(compatible;MSIE6.0;Windows NT 5.0) (CRLF)Host:www.guet.edu.cn (CRLF)Connection:Keep-Alive (CRLF)(CRLF)
响应报头
响应报头允许服务器传递不能放在状态行中的附加响应信息,以及关于服务器的信息和对Request-URI所标识的资源进行下一步访问的信息。
常用的响应报头
Location
Location响应报头域用于重定向接受者到一个新的位置。Location响应报头域常用在更换域名的时候。
Server
Server响应报头域包含了服务器用来处理请求的软件信息。与User-Agent请求报头域是相对应的。下面是
Server响应报头域的一个例子:
Server:Apache-Coyote/1.1
WWW-Authenticate
WWW-Authenticate响应报头域必须被包含在401(未授权的)响应消息中,客户端收到401响应消息时候,并发送Authorization报头域请求服务器对其进行验证时,服务端响应报头就包含该报头域。
eg:WWW-Authenticate:Basic realm="Basic Auth Test!" //可以看出服务器对请求资源采用的是基本验证机制。
二、Python3.4爬虫编程
1、第一个示例,我们要来进行简单的爬虫来爬别人的网页
- #python3.4 爬虫教程
- #一个简单的示例爬虫
- #林炳文Evankaka(博客:http:
- import urllib.request
- url = "http://www.douban.com/"
- webPage=urllib.request.urlopen(url)
- data = webPage.read()
- data = data.decode('UTF-8')
- print(data)
- print(type(webPage))
- print(webPage.geturl())
- print(webPage.info())
- print(webPage.getcode())
这是爬回来的网页输出:
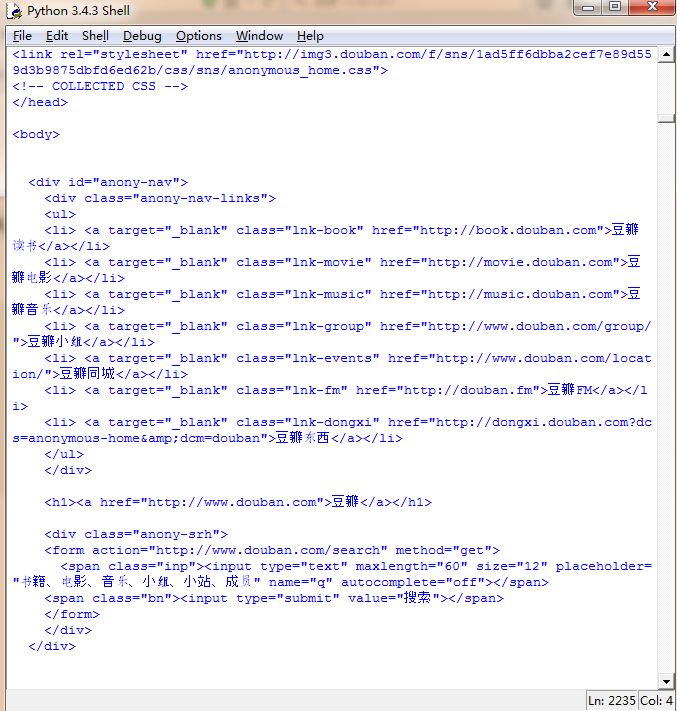
这中间到底发生了什么事呢?让我们打开Fiddler来看看吧:
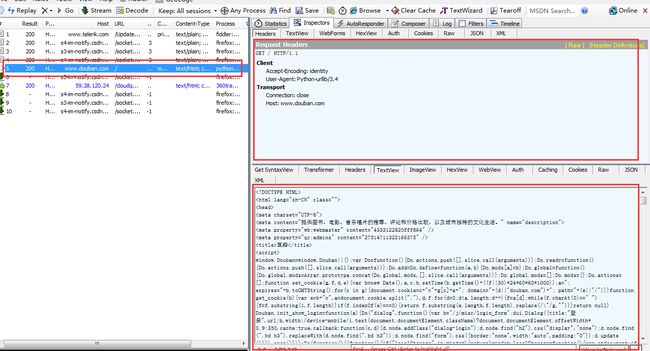
左边标红的就表示我们本次访问成功,为http 200
右边上方这是python生成 的请求报头,不清楚看下面:
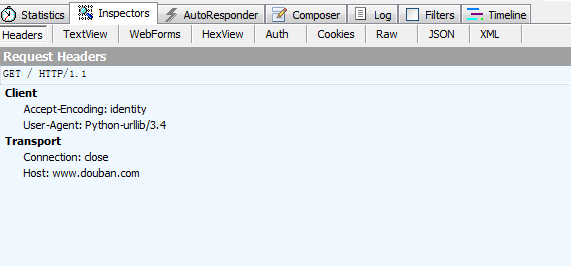
很简单的一个报头,然后再来看看响应回来的html
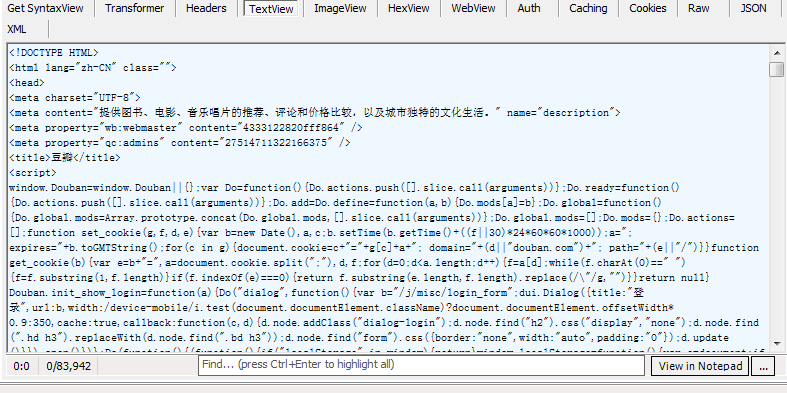
这里响应回来的就是我们上面在python的idle中打印出来的网页了!
2、伪装成浏览器来爬网页
有些网页,比如登录的。如果你不是从浏览器发起的起求,这就不会给你响应,这时我们就需要自己来写报头。然后再发给网页的服务器,这时它就以为你就是一个正常的浏览器。从而就可以爬了!
-
-
-
- import urllib.request
- weburl = "http://www.douban.com/"
- webheader = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
- req = urllib.request.Request(url=weburl, headers=webheader)
- webPage=urllib.request.urlopen(req)
- data = webPage.read()
- data = data.decode('UTF-8')
- print(data)
- print(type(webPage))
- print(webPage.geturl())
- print(webPage.info())
- print(webPage.getcode())
来看看请求报头,就是和我们设置的一个样。
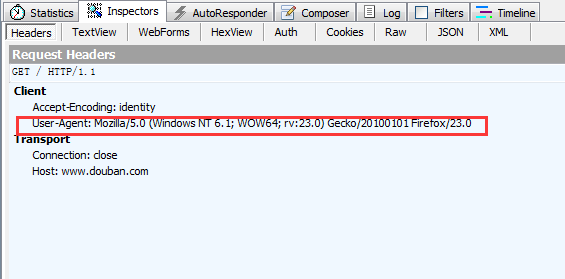
返回的是一样的:
再来一个复杂一点的请求报头:
-
-
-
- import urllib.request
- weburl = "http://www.douban.com/"
- webheader1 = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
- webheader2 = {
- 'Connection': 'Keep-Alive',
- 'Accept': 'text/html, application/xhtml+xml, */*',
- 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
-
- 'Host': 'www.douban.com',
- 'DNT': '1'
- }
- req = urllib.request.Request(url=weburl, headers=webheader2)
- webPage=urllib.request.urlopen(req)
- data = webPage.read()
- data = data.decode('UTF-8')
- print(data)
- print(type(webPage))
- print(webPage.geturl())
- print(webPage.info())
- print(webPage.getcode())
看看生成 的结果:
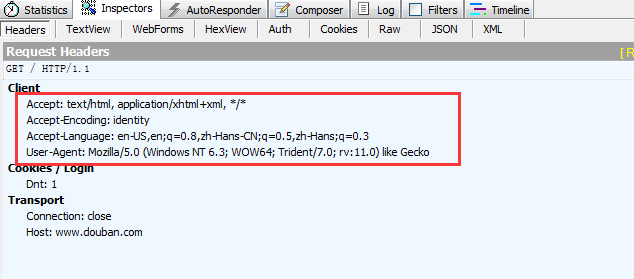
返回还是:
3、爬取网站上的图片
前面我们可以爬网页了,下一步我们就可以批量的自动下载该网页上的各种数据了~,比如,这里我要下载该网页上的所有图片
-
-
-
- import urllib.request
- import socket
- import re
- import sys
- import os
- targetDir = r"D:\PythonWorkPlace\load"
- def destFile(path):
- if not os.path.isdir(targetDir):
- os.mkdir(targetDir)
- pos = path.rindex('/')
- t = os.path.join(targetDir, path[pos+1:])
- return t
- if __name__ == "__main__":
- weburl = "http://www.douban.com/"
- webheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
- req = urllib.request.Request(url=weburl, headers=webheaders)
- webpage = urllib.request.urlopen(req)
- contentBytes = webpage.read()
- for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
- print(link)
- try:
- urllib.request.urlretrieve(link, destFile(link))
- except:
- print('失败')
-
这是正在运行的过程:

打开电脑上对应的文件夹,然后来看看图片,这里只是一部分哦!!。。

真实的网页上的图片

4、保存爬取回来的报文
- def saveFile(data):
- save_path = 'D:\\temp.out'
- f_obj = open(save_path, 'wb')
- f_obj.write(data)
- f_obj.close()
-
-
-
-
-
-
- saveFile(dat)
比如:
-
-
-
- import urllib.request
- def saveFile(data):
- save_path = 'D:\\temp.out'
- f_obj = open(save_path, 'wb')
- f_obj.write(data)
- f_obj.close()
- weburl = "http://www.douban.com/"
- webheader1 = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
- webheader2 = {
- 'Connection': 'Keep-Alive',
- 'Accept': 'text/html, application/xhtml+xml, */*',
- 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
-
- 'Host': 'www.douban.com',
- 'DNT': '1'
- }
- req = urllib.request.Request(url=weburl, headers=webheader2)
- webPage=urllib.request.urlopen(req)
- data = webPage.read()
- saveFile(data)
- data = data.decode('UTF-8')
- print(data)
- print(type(webPage))
- print(webPage.geturl())
- print(webPage.info())
- print(webPage.getcode())
然后看看D盘:
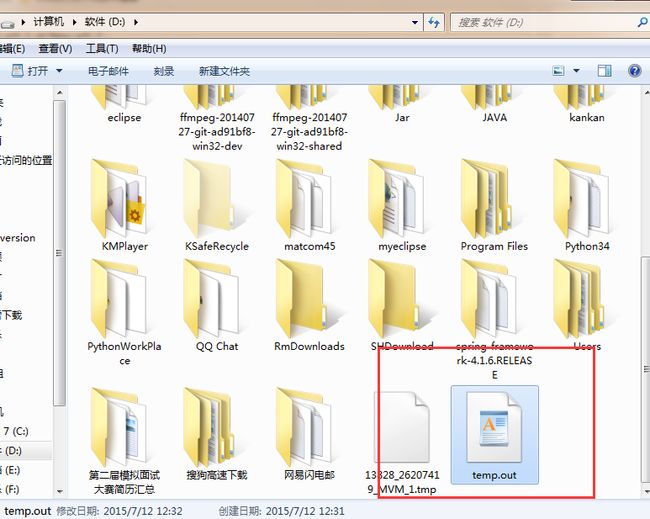
用NotePad打开:
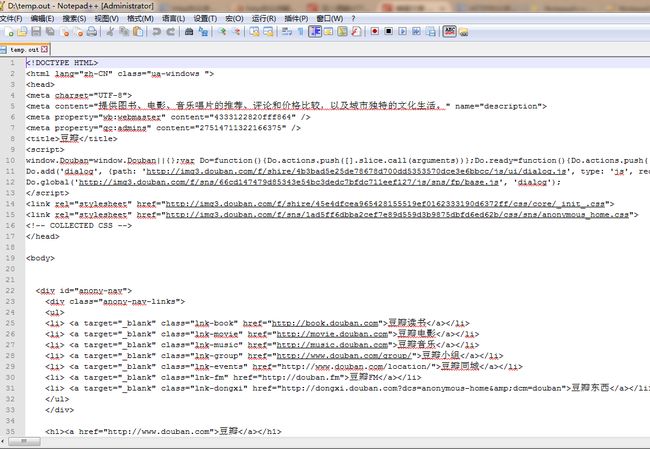
嗯嗯。是对的。网页已经被爬下来了。
三、Python3.x 自动登录
普通情况下我们输入邮箱和密码后,登录。来看看。这就是提交表单的内容
python3.4代码编写:
- import gzip
- import re
- import http.cookiejar
- import urllib.request
- import urllib.parse
-
- def ungzip(data):
- try:
- print('正在解压.....')
- data = gzip.decompress(data)
- print('解压完毕!')
- except:
- print('未经压缩, 无需解压')
- return data
-
- def getXSRF(data):
- cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)
- strlist = cer.findall(data)
- return strlist[0]
-
- def getOpener(head):
-
- cj = http.cookiejar.CookieJar()
- pro = urllib.request.HTTPCookieProcessor(cj)
- opener = urllib.request.build_opener(pro)
- header = []
- for key, value in head.items():
- elem = (key, value)
- header.append(elem)
- opener.addheaders = header
- return opener
-
- header = {
- 'Connection': 'Keep-Alive',
- 'Accept': 'text/html, application/xhtml+xml, */*',
- 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
- 'Accept-Encoding': 'gzip, deflate',
- 'Host': 'www.zhihu.com',
- 'DNT': '1'
- }
-
- url = 'http://www.zhihu.com/'
- opener = getOpener(header)
- op = opener.open(url)
- data = op.read()
- data = ungzip(data)
- _xsrf = getXSRF(data.decode())
-
- url += 'login/email'
- id = '这里写自己的邮箱'
- password = '这里写自己的密码'
-
- postDict = {
- '_xsrf':_xsrf,
- 'email': id,
- 'password': password,
- 'rememberme': 'y'
- }
-
- postData = urllib.parse.urlencode(postDict).encode()
- op = opener.open(url, postData)
- data = op.read()
- data = ungzip(data)
-
- print(data.decode())
来看看结果:
这时运行返回的
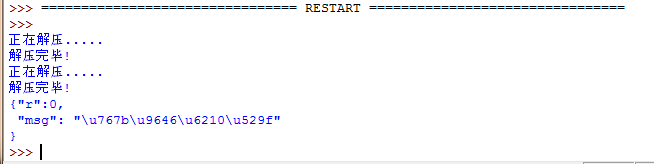
发送出去的请求头
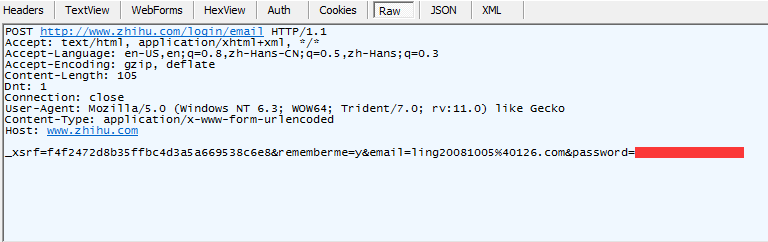
接收回来 的报头
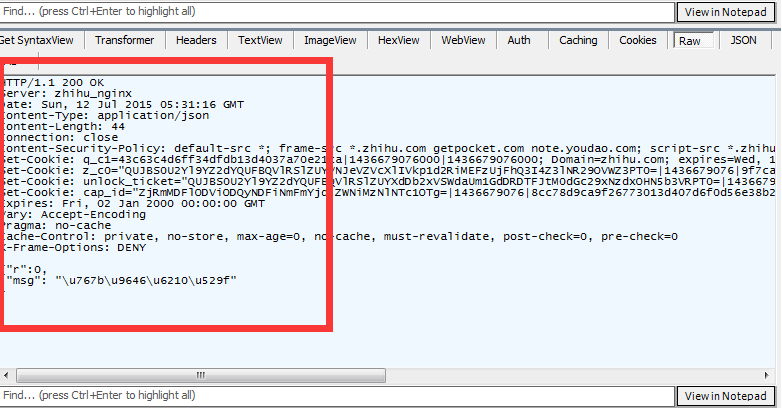
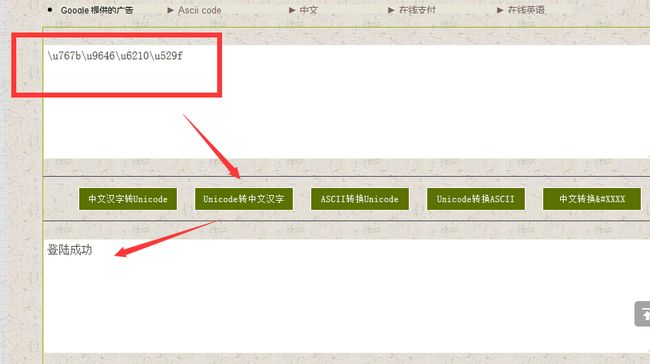
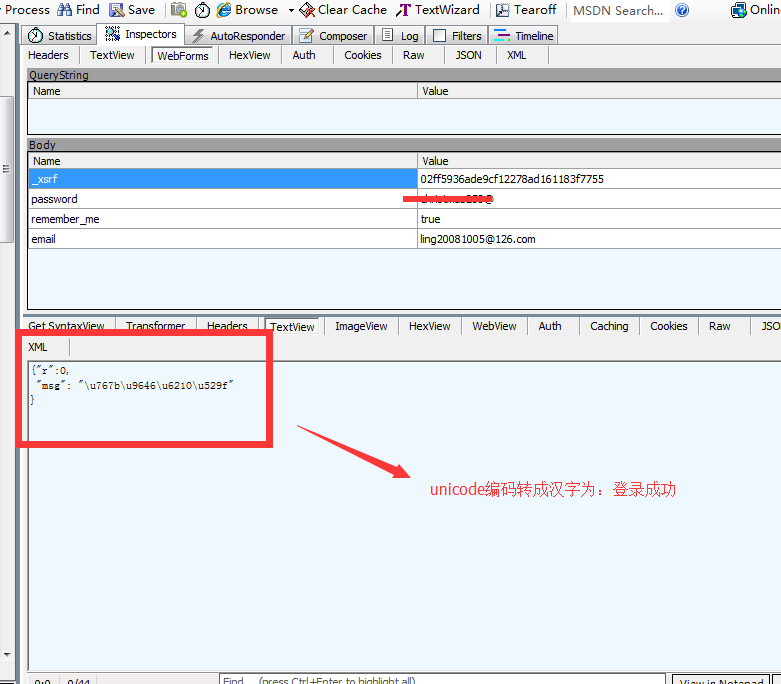
返回的数据是什么意思呢:
很简单, 我们转码下: