- parquet数据
- hive表数据
- mysql表数据
- hive与mysql结合
1.处理parquet数据
- 启动
spark-shell:
spark-shell --master local[2] --jars ~/software/mysql-connector-java-5.1.27-bin.jar
在spark-shell模式下,执行 标准的加载方法 :
val path = "file:///home/hadoop/app/xxx.parquet"//处理的parquet文件的路径
val userDF = spark.read.format("parquet").load(path)
userDF.printSchema()//打印DataFrame的Schema
userDF.show()//显示数据
userDF.select("name","favorite_color").show//选择性的显示两列
userDF.select("name","favorite_color").write.format("json").save("file:///home/hadoop/tmp/jsonout")//将查询到的数据以json形式写入到指定路径下
第二种加载parquet文件的方法,不指定文件format:
spark.read.load("file:///home/hadoop/app/users.parquet").show
第三种加载文件方法,option:
spark.read.format("parquet").option("path", "file:///home/hadoop/app/users.parquet")
- 注意,
load方法默认加载的文件形式是parquet
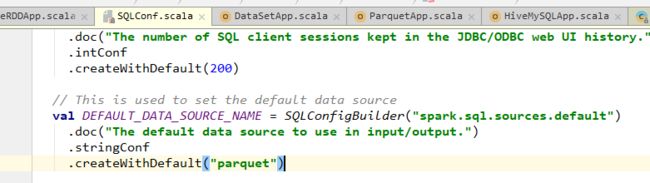 image.png
image.png
比如,下面这样,使用load方法处理一个parquet文件,不指定文件形式:
val userDF = spark.read.load("file:///home/hadoop/app/spark/examples/src/main/resources/people.json")
报错信息:
RuntimeException: file:/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json is not a Parquet file
- 也可以进入sql模式下通过表来操作文件,执行
spark-sql:
spark-sql --master local[2] --jars ~/software/mysql-connector-java-5.1.27-bin.jar
CREATE TEMPORARY VIEW parquetTable
USING org.apache.spark.sql.parquet
OPTIONS (
path "/home/hadoop/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet"
)
SELECT * FROM parquetTable
2.操作hive表数据
在spark-shell模式下,
spark.sql("show tables").show //显示表
spark.table("emp").show //显示emp表的数据
spark.sql("select empno,count(1) from emp group by empno").show //按照empno分组显示
spark.sql("select empno,count(1) from emp group by empno").filter("empno is not null").write.saveAsTable("emp_1") //按照empno分组且过滤掉null的行,然后存储到hive表里
然而,执行下面的语句时,
spark.sql("select empno,count(1) from emp group by empno").filter("empno is not null").write.saveAsTable("emp_1")
报错:
org.apache.spark.sql.AnalysisException: Attribute name "count(1)" contains invalid character(s) among " ,;{}()\n\t=". Please use alias to rename it.;
需要加上别名才能存储到hive表中
spark.sql("select deptno, count(1) as mount from emp where group by deptno").filter("deptno is not null").write.saveAsTable("hive_table_1")
在生产环境中要注意设置spark.sql.shuffle.partitions,默认是200
spark.sqlContext.setConf("spark.sql.shuffle.partitions","10")
spark.sqlContext.getConf("spark.sql.shuffle.partitions") //结果为10
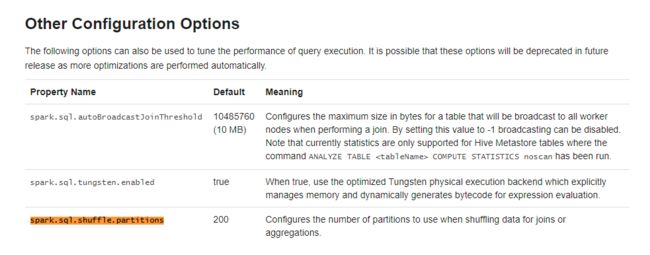
当然也可以访问SparkUI页面的jobs标签页,查看相关信息。
3.操作mysql数据(替代Sqoop)
scala实现:
spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/hive").option("dbtable", "hive.TBLS").option("user", "root").option("password", "root").option("driver", "com.mysql.jdbc.Driver").load()
- 注意:如果没有
driver option的话,会报错:java.sql.SQLException: No suitable driver
java实现:
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "root")
connectionProperties.put("driver", "com.mysql.jdbc.Driver")
val jdbcDF2 = spark.read.jdbc("jdbc:mysql://localhost:3306", "hive.TBLS", connectionProperties)
spark-sql实现:
CREATE TEMPORARY VIEW jdbcTable
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:mysql://localhost:3306",
dbtable "hive.TBLS",
user 'root',
password 'root',
driver 'com.mysql.jdbc.Driver'
)
4.hive和mysql数据源数据查询
由于hive加载的数据,和mysql加载的数据源,都可以抽象为DataFrame,所以,不同的数据源可以通过DataFrame的select,join方法来处理显示。
5. third-party packages
A community index of third-party packages for Apache Spark
https://spark-packages.org/?q=tags%3A%22Data%20Sources%22