Mybatis-plus-找了好久都没看见过这么好的文章
Mbatis-plus
基本实现
1.POM依赖设置
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.0.5version>
dependency>
2.配置yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/test?serverTimezone=CTT&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
logging: #配置日志
level:
root: warn
org.ywb.demo.dao: trace
pattern:
console: '%p%m%n' #输出格式
#mybatis日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
3.创建实体
public class User {
//定义属性: 属性名和表中的列名一样
/**
* 指定主键的方式:
* value:主键字段的名称, 如果是id,可以不用写。
* type:指定主键的类型, 主键的值如何生成。 idType.AUTO 表示自动增长。
*/
@TableId(
value="id",
type = IdType.AUTO
)
private Integer id;
private String name; // null
private String email;
//实体类属性,推荐使用包装类型, 可以判断是否为 null
private Integer age; // 0
}
1、ASSIGN_ID
MyBatis-Plus默认的主键策略是:ASSIGN_ID (使用了雪花算法)
@TableId(type = IdType.ASSIGN_ID)
private String id;
2、AUTO 自增策略
- 需要在创建数据表的时候设置主键自增
- 实体字段中配置 @TableId(type = IdType.AUTO)
@TableId(type = IdType.AUTO)
private Long id;
4.自定义Mapper继承BaseMapper
public interface UserMapper extends BaseMapper<User> {
}
/**
* 自定义Mapper,就是Dao接口。
* 1.要实现BaseMapper
* 2.指定实体类
*
* BaseMapper是MP框架中的对象,定义17个操作方法(CRUD)
*/
5.在启动文件上配置@MapperScan(value=“com.wkcto.plus.mapper”)注解 扫描mapper文件
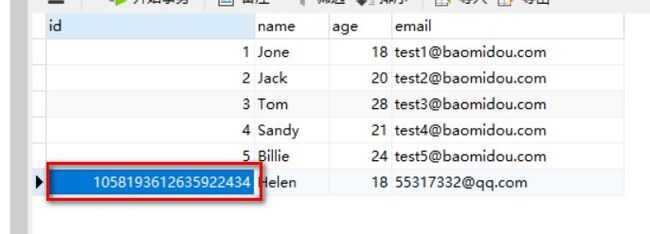
**注意:**数据库插入id值默认为:全局唯一id
数据库分库分表策略
背景
随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。
数据库的扩展方式主要包括:业务分库、主从复制,数据库分表。
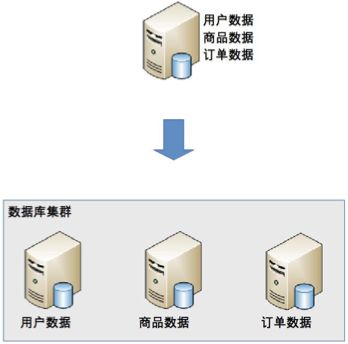
1、业务分库
业务分库指的是按照业务模块将数据分散到不同的数据库服务器。例如,一个简单的电商网站,包括用户、商品、订单三个业务模块,我们可以将用户数据、商品数据、订单数据分开放到三台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上。这样的就变成了3个数据库同时承担压力,系统的吞吐量自然就提高了。
虽然业务分库能够分散存储和访问压力,但同时也带来了新的问题,接下来我进行详细分析。
-
join 操作问题
-
- 业务分库后,原本在同一个数据库中的表分散到不同数据库中,导致无法使用 SQL 的 join 查询。
-
事务问题
-
- 原本在同一个数据库中不同的表可以在同一个事务中修改,业务分库后,表分散到不同的数据库中,无法通过事务统一修改。
-
成本问题
-
- 业务分库同时也带来了成本的代价,本来 1 台服务器搞定的事情,现在要 3 台,如果考虑备份,那就是 2 台变成了 6 台。
2、主从复制和读写分离
读写分离的基本原理是将数据库读写操作分散到不同的节点上。读写分离的基本实现是:
- 数据库服务器搭建主从集群,一主一从、一主多从都可以。
- 数据库主机负责读写操作,从机只负责读操作。
- 数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
- 业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
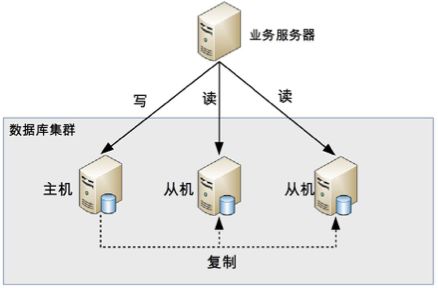
需要注意的是,这里用的是“主从集群”,而不是“主备集群”。“从机”的“从”可以理解为“仆从”,仆从是要帮主人干活的,“从机”是需要提供读数据的功能的;而“备机”一般被认为仅仅提供备份功能,不提供访问功能。所以使用“主从”还是“主备”,是要看场景的,这两个词并不是完全等同。
3、数据库分表
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进行拆分。
单表数据拆分有两种方式:垂直分表和水平分表。示意图如下:
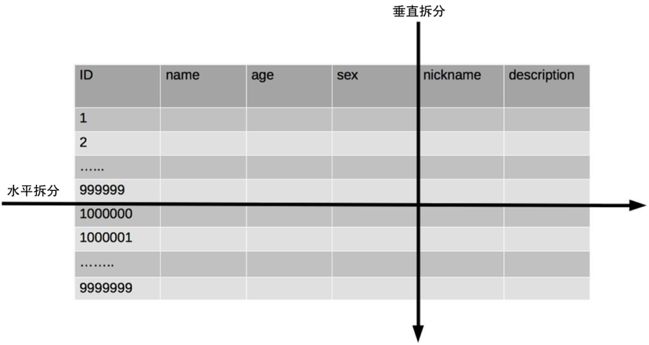
单表进行切分后,是否要将切分后的多个表分散在不同的数据库服务器中,可以根据实际的切分效果来确定。如果性能能够满足业务要求,是可以不拆分到多台数据库服务器的,毕竟我们在上面业务分库的内容看到业务分库也会引入很多复杂性的问题。分表能够有效地分散存储压力和带来性能提升,但和分库一样,也会引入各种复杂性:
-
垂直分表:
-
- 垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
- 例如,前面示意图中的 nickname 和 description 字段,假设我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用 age 和 sex 两个字段进行查询,而 nickname 和 description 两个字段主要用于展示,一般不会在业务查询中用到。description 本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。
-
水平分表:
-
- 水平分表适合表行数特别大的表,有的公司要求单表行数超过 5000 万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过 1000 万就要分表了;而对于一些简单的表,即使存储数据超过 1 亿行,也可以不分表。
- 但不管怎样,当看到表的数据量达到千万级别时,作为架构师就要警觉起来,因为这很可能是架构的性能瓶颈或者隐患。
水平分表相比垂直分表,会引入更多的复杂性,例如数据id:
-
主键自增:
-
- 以最常见的用户 ID 为例,可以按照 1000000 的范围大小进行分段,1 ~ 999999 放到表 1中,1000000 ~ 1999999 放到表2中,以此类推。
- 复杂点:分段大小的选取。分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会导致单表依然存在性能问题,一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。
- 优点:可以随着数据的增加平滑地扩充新的表。例如,现在的用户是 100 万,如果增加到 1000 万,只需要增加新的表就可以了,原有的数据不需要动。
- 缺点:分布不均匀,假如按照 1000 万来进行分表,有可能某个分段实际存储的数据量只有 1000 条,而另外一个分段实际存储的数据量有 900 万条。
-
Hash :
-
- 同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,路由算法可以简单地用 user_id % 10 的值来表示数据所属的数据库表编号,ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户放到编号为 6 的字表中。
- 复杂点:初始表数量的选取。表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。
- 优点:表分布比较均匀。
- 缺点:扩充新的表很麻烦,所有数据都要重分布。
-
雪花算法:分布式ID生成器
-
-
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的主键的有序性。
-
核心思想:
-
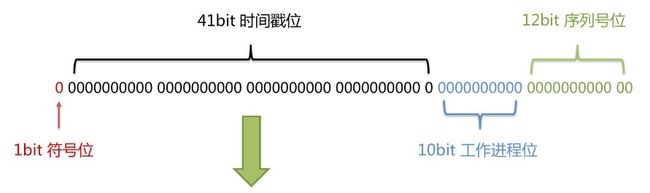
- 长度共64bit(一个long型)。
- 首先是一个符号位,1bit标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
- 41bit时间截(毫秒级),存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年。
- 10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID,可以部署在1024个节点)。
- 12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)。
-
-
-
- **优点:**整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高。
二、自动填充
需求描述:
项目中经常会遇到一些数据,每次都使用相同的方式填充,例如记录的创建时间,更新时间等。
我们可以使用MyBatis Plus的自动填充功能,完成这些字段的赋值工作
1、数据库修改
在User表中添加datetime类型的新的字段 create_time、update_time
2、实体类修改
实体上增加字段并添加自动填充注解
@Data
public class User {
@TableField(fill = FieldFill.INSERT)
private Date createTime;
//@TableField(fill = FieldFill.UPDATE)
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
}
3、实现元对象处理器接口
注意:不要忘记添加 @Component 注解
@Slf4j
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("start insert fill ....");
this.setFieldValByName("createTime", new Date(), metaObject);
this.setFieldValByName("updateTime", new Date(), metaObject);
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("start update fill ....");
this.setFieldValByName("updateTime", new Date(), metaObject);
}
}
三、乐观锁
4、解决方案
数据库中添加version字段取出记录时,获取当前version
SELECT id,`name`,price,`version` FROM product WHERE id=1
更新时,version + 1,如果where语句中的version版本不对,则更新失败
UPDATE product SET price=price+50, `version`=`version` + 1 WHERE id=1 AND`version`=1
接下来介绍如何在Mybatis-Plus项目中,使用乐观锁:
5、乐观锁实现流程
(1)修改实体类
添加 @Version 注解
@Version
private Integer version;
(2)创建配置文件
创建包config,创建文件MybatisPlusConfig.java
此时可以删除主类中的 @MapperScan 扫描注解
@EnableTransactionManagement
@Configuration
@MapperScan("com.atguigu.mybatis_plus.mapper")
public class MybatisPlusConfig {
}
(3)注册乐观锁插件
在 MybatisPlusConfig 中注册 Bean
/**
* 乐观锁插件
*/
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor() {
return new OptimisticLockerInterceptor();
}
BaseMapper的方法
public interface BaseMapper<T> {
int insert(T var1);
int deleteById(Serializable var1);
int deleteByMap(@Param("cm") Map<String, Object> var1);
int delete(@Param("ew") Wrapper<T> var1);
int deleteBatchIds(@Param("coll") Collection<? extends Serializable> var1);
int updateById(@Param("et") T var1);
int update(@Param("et") T var1, @Param("ew") Wrapper<T> var2);
T selectById(Serializable var1);
List<T> selectBatchIds(@Param("coll") Collection<? extends Serializable> var1);
List<T> selectByMap(@Param("cm") Map<String, Object> var1);
T selectOne(@Param("ew") Wrapper<T> var1);
Integer selectCount(@Param("ew") Wrapper<T> var1);
List<T> selectList(@Param("ew") Wrapper<T> var1);
List<Map<String, Object>> selectMaps(@Param("ew") Wrapper<T> var1);
List<Object> selectObjs(@Param("ew") Wrapper<T> var1);
IPage<T> selectPage(IPage<T> var1, @Param("ew") Wrapper<T> var2);
IPage<Map<String, Object>> selectMapsPage(IPage<T> var1, @Param("ew") Wrapper<T> var2);
}
注解的作用
| 注解名称 | 说明 |
|---|---|
@TableName |
实体类的类名和数据库表名不一致 |
@TableId |
实体类的主键名称和表中主键名称不一致 |
@TableField |
实体类中的成员名称和表中字段名称不一致 |
@Data
@TableName("t_user")
public class User {
@TableId("user_id")
private Long id;
@TableField("real_name")
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
排除实体类中非表字段
使用transient关键字修饰非表字段,但是被transient修饰后,无法进行序列化。
使用static关键字,因为我们使用的是lombok框架生成的get/set方法,所以对于静态变量,我们需要手动生成get/set方法。
使用@TableField(exist = false)注解
insert
User user = new User();
user.setName("zhangsan"+i);
user.setAge(20 + i);
user.setEmail("[email protected]");
//调用UserMapper的方法, 也就是父接口BaseMapper中的提供的方法
int rows = userDao.insert(user);
//获取主键id ,刚添加数据库中的数据的id
int id = user.getId();//主键字段对应的get方法
插入返回值int 数据插入成功的行数,成功的记录数,getId()获取主键值
update
User user = new User();
user.setName("修改的数据");
user.setAge(22);
user.setEmail("[email protected]");
user.setId(2);
//执行更新,根据主键值更新
/*UPDATE user SET name=?, email=?, age=? WHERE id=?
*更新了所有非null属性值, 条件where id = 主键值
*/
int rows = userDao.updateById(user);
--------------------------------------------------------------------------------------
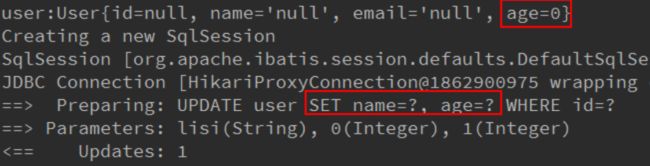
//此时 实体类中age的数据类型为Int,会把不是null的值默认改变
public void testUpdateUser3(){
User user = new User();
user.setId(3);
user.setEmail("[email protected]");
//实体对象 user: [name = null , email = "[email protected]" , age = 0 ]
//没有修改 name ,age
//判断字段是否要修改, 加入到set语句, 是根据属性值是否为null .
//UPDATE user SET email=?, age=? WHERE id=?
int rows = userDao.updateById(user);
null的字段不更新,email没有赋值,是Null,所以没有出现在set语句中,age有默认0,被更新了
delete
//DELETE FROM user WHERE id=?
int rows = userDao.deleteById(3);
/**
* 按主键删除一条数据
* 方法是deleteById()
* 参数:主键值
* 返回值:是删除的成功记录数
*/
//创建Map对象,保存条件值
Map<String,Object> map = new HashMap<>();
//put("表的字段名",条件值) , 可以封装多个条件
map.put("name","zs");
map.put("age",20);
//调用删除方法
//DELETE FROM user WHERE name = ? AND age = ?
int rows = userDao.deleteByMap(map);
/**
* 按条件删除数据, 条件是封装到Map对象中
* 方法:deleteByMap(map对象);
* 返回值:删除成功的记录数
*/
删除条件封装在Map中,key是列名,value是值,多个key直接and链接
/* List ids = new ArrayList<>();
ids.add(1);
ids.add(2);
ids.add(3);
ids.add(4);
ids.add(5);*/
//使用lambda创建List集合
List<Integer> ids = Stream.of(1, 2, 3, 4, 5).collect(Collectors.toList());
//删除操作
//DELETE FROM user WHERE id IN ( ? , ? , ? , ? , ? )
int i = userDao.deleteBatchIds(ids);
/**
* 批处理方式:使用多个主键值,删除数据
* 方法名称:deleteBatchIds()
* 参数: Collection var1
* 返回值:删除的记录数
*/
select
/**
* 实现查询 selectById ,根据主键值查询
* 参数:主键值:
* 返回值: 实体对象(唯一的一个对象)
*/
/**
* 生成的sql: SELECT id,name,email,age FROM user WHERE id=?
* 如果根据主键没有查找到数据, 得到的返回值是 null
*/
User user = userDao.selectById(6);
System.out.println("selectById:"+user);
没有查询结果不会报错
/**
* 实现批处理查询,根据多个主键值查询, 获取到List
* 方法:selectBatchIds
* 参数:id的集合
* 返回值:List
*/
List<Integer> ids = new ArrayList<>();
ids.add(6);
ids.add(9);
ids.add(10);
//查询数据
//SELECT id,name,email,age FROM user WHERE id IN ( ? , ? , ? )
List<User> users = userDao.selectBatchIds(ids);
使用lambda查询数据
List<Integer> ids = Stream.of(6, 9, 10, 15).collect(Collectors.toList());
//SELECT id,name,email,age FROM user WHERE id IN ( ? , ? , ? , ? )
List<User> users = userDao.selectBatchIds(ids);
//遍历集合
users.forEach( u -> {
System.out.println("查询的user对象:"+u);
});
多条件map查询
/**
* 使用Map做多条件查询
* 方法:selectByMap()
* 参数:Map
* 返回值:List
*
*/
//创建Map,封装查询条件
Map<String,Object> map = new HashMap<>();
//key是字段名, value:字段值 ,多个key,是and 联接
map.put("name","zhangsan");
map.put("age",20);
//根据Map查询
//SELECT id,name,email,age FROM user WHERE name = ? AND age = ?
List<User> users = userDao.selectByMap(map);
AR
Active Record(活动记录),是一种领域模型模式,特点是一个模型类对应关系型数据库中的一个表,而模型类的一个实例对应表中的一行记录。ActiveRecord 一直广受动态语言( PHP 、 Ruby 等)的喜爱,而 Java 作为准静态语言,对于 ActiveRecord 往往只能感叹其优雅,所以 MP 也在 AR 道路上进行了一定的探索,仅仅需要让实体类继承 Model 类且实现主键指定方法,即可开启 AR 之旅
实现步骤
- 实体继承mdel
/**
* 使用AR,要求实体类需要继承MP中的Model
* Model中提供了对数据库的CRUD的操作
*/
public class Dept extends Model<Dept> {
//定义属性, 属性名和表的列名一样
//uuid
@TableId(value = "id",type = IdType.UUID)
private String id;
private String name;
private String mobile;
private Integer manager;
2.Mapper继承BaseMapper
DeptMapper是不需要使用的,MP需要使用DeptMapper获取到数据库的表的信息。
public interface DeptMapper extends BaseMapper<Dept> {
}
insert
Dept dept = new Dept();
dept.setName("行政部");
dept.setMobile("010-66666666");
dept.setManager(5);
//调用实体对象自己的方法,完成对象自身到数据库的添加操作
boolean flag = dept.insert();
update
Dept dept = new Dept();
dept.setId(1);
dept.setMobile("010-3333333");
//UPDATE dept SET mobile=? WHERE id=?
boolean result = dept.updateById();//使用dept实体主键的值,作为where id = 1
null的属性不更新
delelte
Dept dept = new Dept();
//DELETE FROM dept WHERE id=?
boolean result = dept.deleteById(1);
----------------------------------------------------------
Dept dept = new Dept();
dept.setId(2);
//DELETE FROM dept WHERE id=?
boolean result = dept.deleteById();
deleteById()删除操作即使没有从数据库中删除数据,也返回是true
selete
Dept dept = new Dept();
//设置主键的值
dept.setId(1);
//调用查询方法
//SELECT id,name,mobile,manager FROM dept WHERE id=?
Dept dept1 = dept.selectById();
Dept dept = new Dept();
Dept dept1 = dept.selectById(3);
主键自增策略
AUTO(0),//数据库自增 依赖数据库
NONE(1),// 表示该类型未甚至主键类型 (如果没有主键策略)默认根据雪花算法生成
INPUT(2),//用户输入ID(该类型可以通过自己注册填充插件进行填充)
//下面这三种类型,只有当插入对象id为空时 才会自动填充。
ID_WORKER(3),//全局唯一(idWorker)数值类型 (实体类采用Long id,表的列用bigint) 分布式id雪花算法
UUID(4),//全局唯一(UUID) (实体类用String id,表用varvhar 50)
ID_WORKER_STR(5);//全局唯一(idWorker的字符串表示)(实体类用String id,表用varvhar 50)
全局主键策略
mybatis-plus:
mapper-locations:
- com/mp/mapper/*
global-config:
db-config:
id-type: uuid/none/input/id_worker/id_worker_str/auto
表示全局主键都采用该策略(如果全局策略和局部策略都有设置,局部策略优先级高)
#全局设置主键生成策略
mybatis-plus.global-config.db-config.id-type=auto
mybatis-plus:
mapper-locations: mapper/*.xml
global-config:
db-config:
# 主键策略
id-type: auto
# 表名前缀
table-prefix: t
field-stratrgy: ignored #所有字段都在 @Tabled(table.stratrgy)
# 表名是否使用下划线间隔,默认:是
table-underline: true
# 添加mybatis配置文件路径
config-location: mybatis-config.xml
# 配置实体类包地址
type-aliases-package: org.ywb.demo.pojo
# 驼峰转下划线
configuration:
map-underscore-to-camel-case: true
自定义sql
1.创建实体
2.创建mapper 继承BaseMapper
3.创建xml映射文件 实现mapper方法
<mapper namespace="com.wkcto.plus.mapper.StudentMapper">
<insert id="insertStudent">
insert into student(name,age,email,status) values(#{name},#{age},#{email},#{status})
insert>
<select id="selectStudentById" resultType="com.wkcto.plus.entity.Student">
select id,name,age,email,status from student where id=#{studentId}
select>
<select id="selectByName" resultType="com.wkcto.plus.entity.Student">
select id,name,age,email,status from student where name=#{name}
select>
mapper>
4.配置xml文件位置
mybatis-plus:
mapper-locations: classpath*:xml/*Mapper.xml
Wrapper
allEq
QueryWrapper<Student> qw = new QueryWrapper<>();
//组装条件
Map<String, Object> param = new HashMap<>();
//map key列名 , value:查询的值
param.put("name", "张三");
param.put("age", 22);
param.put("status", 1);
qw.allEq(param);
//调用MP自己的查询方法
//SELECT id,name,age,email,status FROM student WHERE name = ? AND age = ?
//WHERE name = ? AND age = ? AND status = ?
List<Student> students = studentDao.selectList(qw);
QueryWrapper<Student> qw = new QueryWrapper<>();
//组装条件
Map<String, Object> param = new HashMap<>();
//map key列名 , value:查询的值
param.put("name", "张三");
//age 是 null
param.put("age", null);
//allEq第二个参数为true
qw.allEq(param, false);
//调用MP自己的查询方法
List<Student> students = studentDao.selectList(qw);
/**
* 1) Map对象中有 key的value是null
* 使用的是 qw.allEq(param,true);
* 结果:WHERE name = ? AND age IS NULL
*
* 2) WHERE name = ? AND age IS NULL
* qw.allEq(param,false);
* 结果:WHERE name = ?
*
* 结论:
* allEq(map,boolean)
* true:处理null值,where 条件加入 字段 is null
* false:忽略null ,不作为where 条件
*/
eq
eq("列名",值)
QueryWrapper<Student> qw = new QueryWrapper<>();
//组成条件
qw.eq("name", "李四");
//WHERE name = ?
List<Student> students = studentDao.selectList(qw);
ne表示不等于 <>
QueryWrapper<Student> qw = new QueryWrapper<>();
//组成条件
qw.ne("name", "张三");
// WHERE name <> ?
List<Student> students = studentDao.selectList(qw);
gt 大于( > )
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.gt("age", 30); //age > 30
// WHERE age > ?
List<Student> students = studentDao.selectList(qw);
ge 大于等于 ( >=)
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.ge("age", 31);// >=31
//WHERE age >= ?
List<Student> students = studentDao.selectList(qw);
lt 小于 ( < )
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.lt("age", 32);
// WHERE age < ?
List<Student> students = studentDao.selectList(qw);
le 小于 ( <= )
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.le("age", 32);
// WHERE age <= ?
List<Student> students = studentDao.selectList(qw);
between ( ? and ? )
QueryWrapper<Student> qw = new QueryWrapper<>();
//between("列名",开始值,结束值)
qw.between("age", 22, 28);
// where age >= 12 and age < 28
List<Student> students = studentDao.selectList(qw);
notBetween(不在范围区间内)
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.notBetween("age", 18, 28);
//WHERE age NOT BETWEEN ? AND ?// where age < 18 or age > 28
List<Student> students = studentDao.selectList(qw);
like 匹配某个值
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.like("name", "张");
// WHERE name LIKE %张%
List<Student> students = studentDao.selectList(qw);
notLike 不匹配某个值
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.notLike("name", "张");
// WHERE name NOT LIKE ? %张%
List<Student> students = studentDao.selectList(qw);
likeLeft “%值”
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.likeLeft("name", "张");
//WHERE name LIKE %张
List<Student> students = studentDao.selectList(qw);
likeRight “值%”
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.likeRight("name", "李");
//WHERE name LIKE 李%
List<Student> students = studentDao.selectList(qw);
isNull , 判断字段是 null
QueryWrapper<Student> qw = new QueryWrapper<>();
//判断email is null
//WHERE email IS NULL
qw.isNull("email");
isNotNull , 判断字段是 is not null
QueryWrapper<Student> qw = new QueryWrapper<>();
// WHERE email IS NOT NULL
qw.isNotNull("email");
in 值列表
QueryWrapper<Student> qw = new QueryWrapper<>();
//in(列名,多个值的列表)
//WHERE name IN (?,?,?)
qw.in("name","张三","李四","周丽");
notIn 不在值列表
QueryWrapper<Student> qw = new QueryWrapper<>();
//in(列名,多个值的列表)
//WHERE name NOT IN (?,?,?)
qw.notIn("name","张三","李四","周丽");
in 值列表
QueryWrapper<Student> qw = new QueryWrapper<>();
List<Object> list = new ArrayList<>();
list.add(1);
list.add(2);
//WHERE status IN (?,?)
qw.in("status",list);
inSql() : 使用子查询
QueryWrapper<Student> qw = new QueryWrapper<>();
//WHERE age IN (select age from student where id=1)
qw.inSql("age","select age from student where id=1");
notInSql() : 使用子查询
QueryWrapper<Student> qw = new QueryWrapper<>();
//WHERE age NOT IN (select age from student where id=1)
qw.notInSql("age","select age from student where id=1");
groupBy:分组
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.select("name,count(*) personNumbers");//select name,count(*) personNumbers
qw.groupBy("name");
// SELECT name,count(*) personNumbers FROM student GROUP BY name
orderbyAsc : 按字段升序
QueryWrapper<Student> qw= new QueryWrapper<>();
//FROM student ORDER BY name ASC , age ASC
qw.orderByAsc("name","age");
orderbyDesc : 按字段降序
QueryWrapper<Student> qw= new QueryWrapper<>();
// ORDER BY name DESC , id DESC
qw.orderByDesc("name","id");
order
/**
* order :指定字段和排序方向
*
* boolean condition : 条件内容是否加入到 sql语句的后面。
* true:条件加入到sql语句
* FROM student ORDER BY name ASC
*
* false:条件不加入到sql语句
* FROM student
*/
QueryWrapper<Student> qw = new QueryWrapper<>();
qw.orderBy(true,true,"name")
.orderBy(true,false,"age")
.orderBy(true,false,"email");
// name asc, age desc , email desc
//FROM student ORDER BY name ASC , age DESC , email DESC
and ,or方法
QueryWrapper<Student> qw= new QueryWrapper<>();
//WHERE name = ? OR age = ?
qw.eq("name","张三")
.or()
.eq("age",22);
last : 拼接sql语句到MP的sql语句的最后 有SQL注入的风险!!!
QueryWrapper<Student> qw = new QueryWrapper<>();
//SELECT id,name,age,email,status FROM student WHERE name = ? OR age = ? limit 1
qw.eq("name","张三")
.or()
.eq("age",22)
.last("limit 1");
注意只能调用一次,多次调用以最后一次为准
/**
* 只返回满足条件的一条语句即可
* limit 1
*/
@Test
public void selectWrapper7(){
QueryWrapper queryWrapper = new QueryWrapper<>();
queryWrapper.in("age", Arrays.asList(30,31,34,35)).last("limit 1");
List userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
exists : 判断条件
QueryWrapper<Student> qw= new QueryWrapper<>();
//SELECT id,name,age,email,status FROM student
// WHERE EXISTS (select id from student where age > 20)
//qw.exists("select id from student where age > 90");
//SELECT id,name,age,email,status FROM student WHERE
// NOT EXISTS (select id from student where age > 90)
qw.notExists("select id from student where age > 90");
组合查询
模糊查询
/**
* 查询名字中包含'雨'并且年龄小于40
* where name like '%雨%' and age < 40
*/
@Test
public void selectByWrapper(){
QueryWrapper queryWrapper = new QueryWrapper<>();
queryWrapper.like("name","雨").lt("age",40);
List userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}

嵌套查询
/**
* 创建日期为2019年2月14日并且直属上级姓名为王姓
* date_format(create_time,'%Y-%m-%d') and manager_id in (select id from user where name like '王%')
*/
@Test
public void selectByWrapper2(){
QueryWrapper queryWrapper = new QueryWrapper<>();
queryWrapper.apply("date_format(create_time,'%Y-%m-%d')={0}","2019-02-14")
.inSql("manager_id","select id from user where name like '王%'");
List userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
![]()
apply
上面的日期查询使用的是占位符的形式进行查询,目的就是为了防止SQL注入的风险。
/**
* 例1: apply("id = 1")
* 例2: apply("date_format(dateColumn,'%Y-%m-%d') = '2008-08-08'") !! 会有 sql 注入风险 !!
* 例3: apply("date_format(dateColumn,'%Y-%m-%d') = {0}", LocalDate.now())
*
* @param condition 执行条件
* @return children
*/
Children apply(boolean condition, String applySql, Object... value);
and&or
/**
* 名字为王姓,(年龄小于40或者邮箱不为空)
*/
@Test
public void selectByWrapper3(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.likeRight("name","王").and(wq-> wq.lt("age",40).or().isNotNull("email"));
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
between & and
/**
* 名字为王姓,(年龄小于40,并且年龄大于20,并且邮箱不为空)
*/
@Test
public void selectWrapper4(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.likeRight("name", "王").and(wq -> wq.between("age", 20, 40).and(wqq -> wqq.isNotNull("email")));
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
nested ()在前面
/**
* (年龄小于40或者邮箱不为空)并且名字为王姓
* (age<40 or email is not null)and name like '王%'
*/
@Test
public void selectWrapper5(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.nested(wq->wq.lt("age",40).or().isNotNull("email")).likeRight("name","王");
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
select 查询指定列列
/**
* 查找为王姓的员工的姓名和年龄
*/
@Test
public void selectWrapper8(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("name","age").likeRight("name","王");
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}

排除指定列
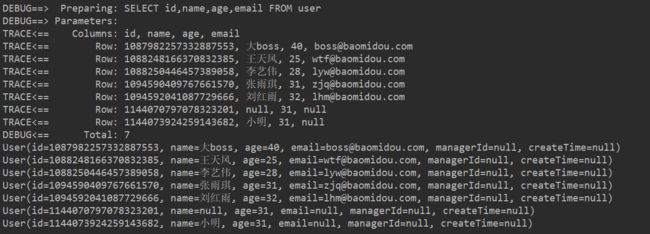
/**
* 查询所有员工信息除了创建时间和员工ID列
*/
@Test
public void selectWrapper9(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select(User.class,info->!info.getColumn().equals("create_time")
&&!info.getColumn().equals("manager_id"));
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
直接传入实体
@Test
public void selectWrapper10(){
User user = new User();
user.setName("刘红雨");
user.setAge(32);
QueryWrapper<User> queryWrapper = new QueryWrapper<>(user);
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}

直接在实体类上进行模糊查询
@TableField(condition = SqlCondition.LIKE)
private String name;
@Test
public void selectWrapper10(){
User user = new User();
user.setName("红");
user.setAge(32);
QueryWrapper<User> queryWrapper = new QueryWrapper<>(user);
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}

Lambda条件构造器
LambdaQueryWrapper<User> lambdaQueryWrapper = new QueryWrapper<User>().lambda();
LambdaQueryWrapper<User> lambdaQueryWrapper1 = new LambdaQueryWrapper<>();
LambdaQueryWrapper<User> lambdaQueryWrapper2 = Wrappers.lambdaQuery();
- 查询名字中包含‘雨’并且年龄小于40的员工信息
@Test
public void lambdaSelect(){
LambdaQueryWrapper<User> lambdaQueryWrapper = Wrappers.lambdaQuery();
lambdaQueryWrapper.like(User::getName,"雨").lt(User::getAge,40);
List<User> userList = userMapper.selectList(lambdaQueryWrapper);
userList.forEach(System.out::println);
}

lambdaQueryWrapper.like(User::getName,"雨");
//可以避免出错
第四种lambda构造器
细心的人都会发现无论是之前的lambda构造器还是queryWrapper,每次编写完条件构造语句后都要将对象传递给mapper 的selectList方法,比较麻烦,MyBatisPlus提供了第四种函数式编程方式,不用每次都传。
//查询名字中包含“雨”字的,并且年龄大于20的员工信息
@Test
public void lambdaSelect(){
List<User> userList = new LambdaQueryChainWrapper<>(userMapper)
.like(User::getName, "雨").ge(User::getAge, 20).list();
userList.forEach(System.out::println);
}
Service
1.service层需要继承IService,当然实现层也要继承对应的实现类。
public interface UserService extends IService<User> {
}
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
@Autowired
private UserService userService;
@Test
public void selectOneService() {
User user = userService.getOne((Wrapper<User>) queryWrapper.gt("age", 30), false);
}
saveOrUpdateBatch
User user1 = new User();
user1.setUserId(1);
user1.setRealName("boss gu");
user1.setAge(38);
User user2 = new User();
user2.setRealName("boss ji");
user2.setAge(20);
userService.saveOrUpdateBatch(Arrays.asList(user1,user2));
使用Lambda进行链式操作
List<User> list = userService.lambdaQuery().eq(User::getAge, 30).list();
list.forEach(System.out::println);
分页
1.配置@Configuration
@Configuration
public class Config {
/***
* 定义方法,返回的返回值是java 对象,这个对象是放入到spring容器中
* 使用@Bean修饰方法
* @Bean等同于 QueryWrapper<Student> qw = new QueryWrapper<>();
qw.gt("age",22);
IPage<Student> page = new Page<>();
//设置分页的数据
page.setCurrent(1);//第一页
page.setSize(3);// 每页的记录数
IPage<Student> result = studentDao.selectPage(page,qw);
//获取分页后的记录
List<Student> students = result.getRecords();
System.out.println("students.size()="+students.size());
//分页的信息
long pages = result.getPages();
System.out.println("页数:"+pages);
System.out.println("总记录数:"+result.getTotal());
System.out.println("当前页码:"+result.getCurrent());
System.out.println("每页的记录数:"+result.getSize());
/**
* 分页:
* 1.统计记录数,使用count(1)
* SELECT COUNT(1) FROM student WHERE age > ?
* 2.实现分页,在sql语句的末尾加入 limit 0,3
* SELECT id,name,age,email,status FROM student WHERE age > ? LIMIT 0,3
*/
MP生成器
1.模板引擎
<dependency>
<groupId>org.apache.velocitygroupId>
<artifactId>velocity-engine-coreartifactId>
<version>2.0version>
dependency>
2.创建生成类
//创建AutoGenerator ,MP中对象
AutoGenerator ag = new AutoGenerator();
//设置全局配置
GlobalConfig gc = new GlobalConfig();
//设置代码的生成位置, 磁盘的目录
String path = System.getProperty("user.dir");
gc.setOutputDir(path+"/src/main/java");
//设置生成的类的名称(命名规则)
gc.setMapperName("%sMapper");//所有的Dao类都是Mapper结尾的,例如DeptMapper
//设置Service接口的命名
gc.setServiceName("%sService");//DeptService
//设置Service实现类的名称
gc.setServiceImplName("%sServiceImpl");//DeptServiceImpl
//设置Controller类的命名
gc.setControllerName("%sController");//DeptController
//设置作者
gc.setAuthor("changming");
//设置主键id的配置
gc.setIdType(IdType.ID_WORKER);
ag.setGlobalConfig(gc);
//设置数据源DataSource
DataSourceConfig ds = new DataSourceConfig();
//驱动
ds.setDriverName("com.mysql.jdbc.Driver");
//设置url
ds.setUrl("jdbc:mysql://localhost:3306/springdb");
//设置数据库的用户名
ds.setUsername("root");
//设置密码
ds.setPassword("123456");
//把DataSourceConfig赋值给AutoGenerator
ag.setDataSource(ds);
//设置Package信息
PackageConfig pc = new PackageConfig();
//设置模块名称, 相当于包名, 在这个包的下面有 mapper, service, controller。
pc.setModuleName("order");
//设置父包名,order就在父包的下面生成
pc.setParent("com.wkcto"); //com.wkcto.order
ag.setPackageInfo(pc);
//设置策略
StrategyConfig sc = new StrategyConfig();
sc.setNaming(NamingStrategy.underline_to_camel);
//设置支持驼峰的命名规则
sc.setColumnNaming(NamingStrategy.underline_to_camel);
ag.setStrategy(sc);
//执行代码的生成
ag.execute();
mp高级
逻辑删除
设定逻辑删除规则
在配置文件中配置逻辑删除和逻辑未删除的值
mybatis-plus:
global-config:
logic-not-delete-value: 0 #未删除
logic-delete-value: 1 #已经删除
mp3.1.1以下要配置
@Configuration
public class MYybatisConfig(){
@Bean
public Isqllnejector sqllnjector(){
return new LogicSqllnjector();
}
}
- 在pojo类中在逻辑删除的字段加注解
@TableLogic
@Data
@EqualsAndHashCode(callSuper = false)
public class User extends Model<User> {
@TableId(type = IdType.AUTO)
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
private Integer version;
@TableLogic
private Integer deleted;
}
1.通过id逻辑删除
@Test
public void deleteById(){
userMapper.deleteById(4566L);
}

2.查询中排除删除标识字段及注意事项
逻辑删除字段只是为了标识数据是否被逻辑删除,在查询的时候,并不想也将该字段查询出来。
我们只需要在delete字段上增加@TableField(select = false)mybatisplus在查询的时候就会自动忽略该字段。
@Test
public void selectIgnoreDeleteTest(){
userMapper.selectById(3456L);
}

自定义sql,MybatisPlus不会忽略deleted属性,需要我们手动忽略
自动填充
MybaitsPlus在我们插入数据或者更新数据的时候,为我们提供了自动填充功能。类似MySQL提供的默认值一样。
如果我们需要使用自动填充功能,我们需要在实体类的相应属性上加@TableField注解,并指定什么时候进行自动填充。mybatisPlus为我们提供了三种填充时机,在FieldFill枚举中
public enum FieldFill {
/**
* 默认不处理
*/
DEFAULT,
/**
* 插入时填充字段
*/
INSERT,
/**
* 更新时填充字段
*/
UPDATE,
/**
* 插入和更新时填充字段
*/
INSERT_UPDATE
}
设置好之后,我们还需要编写具体的填充规则,具体是编写一个填充类并交给Spring管理,然后实现MetaObjectHandler接口中的insertFill和updateFill方法。
eg:
- 插入User对象的时候自动填充插入时间,更新User对象的时候自动填充更新时间。
- 指定实体类中需要自动填充的字段,并设置填充时机
@Data
@EqualsAndHashCode(callSuper = false)
public class User extends Model<User> {
...
@TableField(fill = INSERT)
private LocalDateTime createTime;
@TableField(fill = UPDATE)
private LocalDateTime updateTime;
...
}
- 编写填充规则
@Component
public class MyMetaObjHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
if(metaObject.hasSetter("createTime")){
setInsertFieldValByName("createTime", LocalDateTime.now(),metaObject);
}
}
@Override
public void updateFill(MetaObject metaObject) {
if(metaObject.hasSetter("updateTime")){
setUpdateFieldValByName("updateTime",LocalDateTime.now(),metaObject);
}
}
}
解释一下为什么要用if判断是否有对应的属性mybatisPlus在执行插入或者更新操作的时候,每次都会执行该方法,有些表中是没有设置自动填充字段的,而且有些自动填充字段的值的获取比较消耗系统性能,所以为了不必要的消耗,进行if判断,决定是否需要填充。
有些时候我们已经设置了属性的值。不想让mybatisPlus再自动填充,也就是说我们没有设置属性的值,mybatisPlus进行填充,如果设置了那么就用我们设置的值。这种情况我们只需要在填充类中提前获取默认值,然后使用该默认值就可以了。
@Override
public void updateFill(MetaObject metaObject) {
if(metaObject.hasSetter("updateTime")){
Object updateTime = getFieldValByName("updateTime", metaObject);
if(Objects.nonNull(updateTime)){
setUpdateFieldValByName("updateTime",updateTime,metaObject);
}else{
setUpdateFieldValByName("updateTime",LocalDateTime.now(),metaObject);
}
}
}
乐观锁
1.配置类中注入乐观锁插件
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor(){
return new OptimisticLockerInterceptor();
}
- 实体类中的版本字段增加
@version注解
@Data
@EqualsAndHashCode(callSuper = false)
public class User extends Model<User> {
...
@Version
private Integer version;
...
}
- test
更新王天风的年龄
@Test
public void testLock(){
int version = 1;
User user = new User();
user.setEmail("[email protected]");
user.setAge(34);
user.setId(2345L);
user.setManagerId(1234L);
user.setVersion(1);
userMapper.updateById(user);
}
![]()
数据库中的version已经变成2

注意事项:
- 支持的类型只有:int,Integer,losng,Long,Date,Timestamp,LocalDateTime
- 整数类型下newVerison = oldVersion+1
- newVersion会写到entity中
- 仅支持updateById(id)与update(entity,wrapper)方法
- 在update(entiry,wrapper)方法下,wrapper不能复用
性能分析
- 配置类中注入性能分析插件
@Bean
// @Profile({"dev,test"})
public PerformanceInterceptor performanceInterceptor() {
PerformanceInterceptor performanceInterceptor = new PerformanceInterceptor();
// 格式化sql输出
performanceInterceptor.setFormat(true);
// 设置sql执行最大时间,单位(ms)
performanceInterceptor.setMaxTime(5L);
return performanceInterceptor;
}
执行sql就可以打印sql执行的信息了
image.png
依靠第三方插件美化sql输出
https://mp.baomidou.com/guide/p6spy.html
- 第三方依赖
<dependency>
<groupId>p6spygroupId>
<artifactId>p6spyartifactId>
<version>3.8.5version>
dependency>
- 更改配置文件中的dirver和url
spring:
datasource:
# driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
# url: jdbc:mysql://localhost:3306/test?serverTimezone=CTT&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
url: jdbc:p6spy:mysql://localhost:3306/test?serverTimezone=CTT&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
- 增加spy.properties配置文件
module.log=com.p6spy.engine.logging.P6LogFactory,com.p6spy.engine.outage.P6OutageFactory
# 自定义日志打印
logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger
#日志输出到控制台
appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger
# 使用日志系统记录 sql
#appender=com.p6spy.engine.spy.appender.Slf4JLogger
# 设置 p6spy driver 代理
deregisterdrivers=true
# 取消JDBC URL前缀
useprefix=true
# 配置记录 Log 例外,可去掉的结果集有error,info,batch,debug,statement,commit,rollback,result,resultset.
excludecategories=info,debug,result,batch,resultset
# 日期格式
dateformat=yyyy-MM-dd HH:mm:ss
# 实际驱动可多个
#driverlist=org.h2.Driver
# 是否开启慢SQL记录
outagedetection=true
# 慢SQL记录标准 2 秒
outagedetectioninterval=2
#输出到文件
logfile =log.log
-
test

注意
开启性能分析会消耗系统的性能,所以性能分析插件要配合@Profile注解执行使用的环境。
SQL注入器 ->_-> 封装自定义通用SQL
实现步骤:
- 创建定义方法的类
- 创建注入器
- 在mapper中加入自定义方法
eg: 编写一个删除表所有数据的方法
- 创建定义方法的类
public class DeleteAllMethod extends AbstractMethod {
@Override
public MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo) {
// 执行的sql
String sql = "delete from " + tableInfo.getTableName();
// mapper接口方法名
String method = "deleteAll";
SqlSource sqlSource = languageDriver.createSqlSource(configuration, sql, mapperClass);
return addDeleteMappedStatement(mapperClass, method, sqlSource);
}
}
- 创建注入器。添加自己的方法
@Component
public class MySqlInject extends DefaultSqlInjector {
@Override
public List<AbstractMethod> getMethodList(Class<?> mapperClass) {
List<AbstractMethod> methodList = super.getMethodList(mapperClass);
methodList.add(new DeleteAllMethod());
return methodList;
}
}
- 在mapper中加入自定义方法
public interface UserMapper extends BaseMapper<User> {
/**
* 删除所有表数据
*
* @return 影响行数
*/
int deleteAll();
}
- test
@Test
public void deleteAll(){
userMapper.deleteAll();
}
多租户
https://blog.csdn.net/weixin_38111957/article/details/101161660
动态表名sql解析器
https://blog.csdn.net/weixin_38111957/article/details/101196130
自定义sql语句
https://blog.csdn.net/weixin_38111957/article/details/91539019