python编程学习——第五周
第五周
python学习笔记和做的一些习题 (python编程快速上手——让繁琐工作自动化)
第九章 组织文件
shutil模块:
这个模块中的函数可以实现在python程序中复制、移动改名和删除文件。
复制文件和文件夹:调用 shutil.copy(source, destination),将路径 source 处的文件复制到路径 destination处的文件夹(source 和 destination 都是字符串)。如果 destination 是一个文件名,它将作为被复制文件的新名字。该函数返回一个字符串,表示被复制文件的路径。

复制整个文件夹:
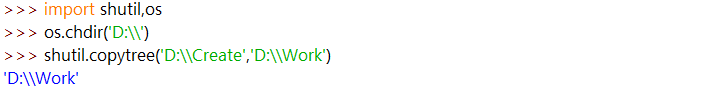
文件和文件夹的移动和改名:调用 shutil.move(source, destination),将路径 source 处的文件夹移动到路径destination,并返回新位置的绝对路径的字符串。如果 destination 指向一个文件夹,source 文件将移动到 destination中,并保持原来的文件名。

移动文件夹并改名:
永久删除文件或文件夹:利用 os 模块中的函数,可以删除一个文件或一个空文件夹。但利用 shutil 模块,可以删除一个文件夹及其所有的内容。
• 用 os.unlink(path)将删除 path 处的文件。
• 调用 os.rmdir(path)将删除 path 处的文件夹。该文件夹必须为空,其中没有任何文件和文件夹。
• 调用 shutil.rmtree(path)将删除 path 处的文件夹,它包含的所有文件和文件夹都会被删除。
用send2trash 模块安全删除:使用send2trash.send2trash()函数来删除文件和文件夹。虽然它将文件发送到垃圾箱,让你稍后能够恢复它们,但是这不像永久删除文件,不会释放磁盘空间。

遍历目录树:
os.walk()函数被传入一个字符串值,即一个文件夹的路径。你可以在一个 for
循环语句中使用 os.walk()函数,遍历目录树,就像使用 range()函数遍历一个范围的数字一样。不像 range(),os.walk()在循环的每次迭代中,返回 3 个值:
1.当前文件夹名称的字符串。
2.当前文件夹中子文件夹的字符串的列表。
3.当前文件夹中文件的字符串的列表。所谓当前文件夹,是指 for 循环当前迭代的文件夹。程序的当前工作目录,不会因为 os.walk()而改变。
用zipfile模块压缩文件:
利用 zipfile 模块中的函数,Python 程序可以创建和打开(或解压)ZIP 文件。
读取zip文件:创建一个 ZipFile对象,就调用 zipfile.ZipFile()函数,向它传入一个字符串,表示.zip 文件的文件名。请注意,zipfile 是 Python 模块的名称,ZipFile()是函数的名称。ZipFile 对象有一个 namelist()方法,返回 ZIP 文件中包含的所有文件和文件夹的字符串的列表。
从ZIP文件中解压缩: ZipFile 对象的 extractall()方法从 ZIP 文件中解压缩所有文件和文件夹,放到当前工作目录中。ZipFile 对象的 extract()方法从 ZIP 文件中解压缩单个文件。传递给 extract()的字符串,必须匹配 namelist()返回的字符串列表中的一个。或者,你可以向 extract()传递第二个参数,将文件解压缩到指定的文件夹,而不是当前工作目录。如果第二个参数指定的文件夹不存在,Python 就会创建它。
创建和添加到ZIP文件:要创建你自己的压缩 ZIP 文件,必须以“写模式”打开 ZipFile 对象,即传入’w’作为第二个参数,如果向 ZipFile 对象的 write()方法传入一个路径,Python 就会压缩该路径所指的文件,将它加到 ZIP 文件中。write()方法的第一个参数是一个字符串,代表要添加的文件名。第二个参数是“压缩类型”参数,它告诉计算机使用怎样的算法来压缩文件。
项目:将带有美国风格日期的文件改名为欧洲风格日期
下面是程序要做的事:
• 检查当前工作目录的所有文件名,寻找美国风格的日期。
• 如果找到,将该文件改名,交换月份和日期的位置,使之成为欧洲风格。这意味着代码需要做下面的事情:
• 创建一个正则表达式,可以识别美国风格日期的文本模式。
• 调用 os.listdir(),找出工作目录中的所有文件。
• 循环遍历每个文件名,利用该正则表达式检查它是否包含日期。
• 如果它包含日期,用 shutil.move()对该文件改名。对于这个项目,打开一个新的文件编辑器窗口,将代码保存为 renameDates.py。
import shutil,os,re
#为美国日期创建一个正则表达式
datePattern = re.compile(r"""^(.*?)
((0|1)?\d)-
((0|1|2|3)?\d)-
((19|20)\d\d)
(.*?)$
""",re.VERBOSE)
#识别文件名中的日期成分
for amerFilename in os.listdir('.'):
mo = datePattern.search(amerFilename)
#忽略没有日期的文件
if mo == None :
continue
#获取欧洲日期风格的不同部分
beforePart = mo.group(1)
monthPart = mo.group(2)
dayPart = mo.group(4)
yearPart = mo.group(6)
afterPart = mo.group(8)
#构成新的日期风格
euroFilename = beforePart + dayPart + '-' + monthPart + '-' + yearPart + afterPart
#构成新文件名,并对文件改名
absWorkingDir = os.path.abspath('-')
amerFilename = os.path.join(absWorkingDir,amerFilename)
euroFilename = os.path.join(absWorkingDir,euroFilename)
print('Renaming "%s" to "%s"...' % (amerFilename,euroFilename))
项目:将一个文件夹备份到一个ZIP文件
import zipfile, os
def backupToZip(folder):
folder = os.path.abspath(folder)
number = 1
while True:
zipFilename = os.path.basename(folder) + '_' + str(number) + '.zip'
if not os.path.exists(zipFilename):
break
number = number + 1
print('Creating %s...' % (zipFilename))
backupZip = zipfile.ZipFile(zipFilename,'w')
for foldername, subfolders, filenames in os.walk(folder):
print('Adding files in %s...' % (foldername))
backupZip.write(foldername)
for filename in filenames:
newBase / os.path.basename(folder) + '_'
if filename.startswith(newBase) and filename.endswith('.zip'):
continue
backupZip.write(os.path.join(foldername, filename))
backupZip.close()
print('Done.')
backupToZip('C:\\delicious')
第九章习题
1.shutil.copy()和 shutil.copytree()之间的区别是什么?
前者是拷贝整个文件,后者是拷贝整个文件夹。
2.什么函数用于文件改名?
shutil.move()函数用于文件的改名和移动。
3.send2trash 和 shutil 模块中的删除函数之间的区别是什么?
前者是将文件夹或文件移到回收站,后者则是永久删除。
4.ZipFile 对象有一个 close()方法,就像 File 对象的 close()方法。ZipFile 对象的什么方法等价于 File 对象的 open()方法?
zipfile.ZipFile()
第九章实践项目
选择性拷贝
编写一个程序,遍历一个目录树,查找特定扩展名的文件(诸如.pdf 或.jpg)不论这些文件的位置在哪里,将它们拷贝到一个新的文件夹中。
import os,shutil
#创建函数,其中第一个参数是目录名,第二个参数是要复制文件的后缀名
def copyfile(folder,extname):
for foldername,subfolder,filenames in os.walk(folder):
for filename in filenames:
#判断是否文件的后缀名是否符合,忽略不符合的文件
if not filename.endswith(extname):
continue
# 合成路径
absfilename = os.path.join(foldername,filename)
print('添加 %s...'%(absfilename))
#复制文件
shutil.copy(absfilename,'D:\\Create')
copyfile('D:\Work','txt')

删除不需要的文件
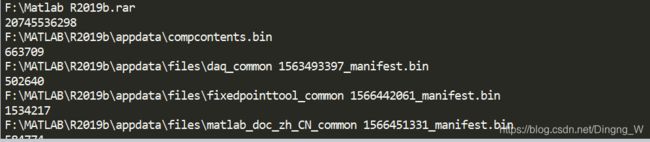
一些不需要的、巨大的文件或文件夹占据了硬盘的空间,这并不少见。如果你试图释放计算机上的空间,那么删除不想要的巨大文件效果最好。但首先你必须找到它们。编写一个程序,遍历一个目录树,查找特别大的文件或文件夹,比方说,超过100MB 的文件(回忆一下,要获得文件的大小,可以使用 os 模块的 os.path.getsize())。将这些文件的绝对路径打印到屏幕上。
import os,shutil
for foldername,subfolders,filenames in os.walk('F:\\'):
for filename in filenames:
absname = os.path.join(foldername,filename)
if os.path.getsize(absname)>=500000:
print(absname)
print(os.path.getsize(absname))
消除缺失的编号
编写一个程序,在一个文件夹中,找到所有带指定前缀的文件,诸如 spam001.txt, spam002.txt 等,并定位缺失的编号(例如存在 spam001.txt 和 spam003.txt,但不存在 spam002.txt)。让该程序对所有后面的文件改名,消除缺失的编号。作为附加的挑战,编写另一个程序,在一些连续编号的文件中,空出一些编号,以便加入新的文件。
import os,re,shutil
num = 1
for foldername,subfolders,filenames in os.walk('D:\\Work\\top'):
pattern = re.compile(r'spam\d{3}.*(\.\w*)$')
for filename in filenames:
mo = pattern.search(filename)
if mo == None :
continue
else:
if num < 10:
temp = 'spam00' + str(num) + '.txt'
if num >= 10 and num < 100:
temp = 'spam0' + str(num) + '.txt'
if num >= 100 and num < 1000:
temp = 'spam' + str(num) + '.txt'
print(temp)
shutil.move(os.path.join(foldername,filename),os.path.join(foldername,temp))
num = num + 1
![]()
第十章 调试
抛出异常
当python试图执行无效代码时,就会抛出异常。你可以在自己的代码中抛出自己的异常,抛出异常相当于是说:“停止运行这个函数中的代码,将程序执行转到expect语句。”
抛出异常使用 raise 语句。在代码中,raise 语句包含以下部分:
• raise 关键字;
• 对 Exception 函数的调用;
• 传递给 Exception 函数的字符串,包含有用的出错信息。

注意: 如果没有try和except语句覆盖抛出异常的raise语句,该程序就会崩溃,并显示出异常的出错信息。
通常是调用该函数的代码知道如何处理异常,而不是该函数本身。所以你常常会看到 raise 语句在一个函数中,try 和 except 语句在调用该函数的代码中。
这里我们定义了一个 boxPrint() 函数,它接受一个字符、一个宽度和一个高度。它按照指定的宽度和高度,用该字符创建了一个小盒子的图像。这个盒子被打印到屏幕上。假定我们希望该字符是一个字符,宽度和高度要大于2。我们添加了 if 语句,如果这些条件没有满足,就抛出异常。稍后,当我们用不同的参数调用 boxPrint()时,try/except 语句就会处理无效的参数。
def boxPrint(symbol, width, height):
if len(symbol) != 1:
raise Exception('Symbol must be a single character string.')
if width <= 2:
raise Exception('Width must be greater than 2.')
if height <= 2:
raise Exception('Height must be greater than 2.')
print(symbol * width)
for i in range(height - 2):
print(symbol + (' ' * (width - 2)) + symbol)
print(symbol * width)
for sym, w, h in (('*', 4, 4), ('O', 20, 5), ('x', 1, 3), ('ZZ', 3, 3)):
try:
boxPrint(sym, w, h)
except Exception as err:
print('An exception happened: ' + str(err))

使用try和except语句,我们可以更加优雅地处理错误。
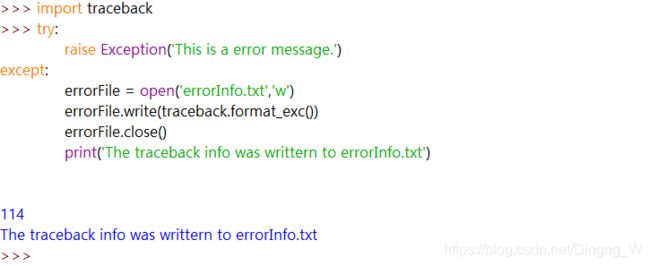
取得反向跟踪的字符串
如果 Python 遇到错误,它就会生成一些错误信息,称为“反向跟踪”。反向跟踪包含了出错消息、导致该错误的代码行号,以及导致该错误的函数调用的序列。这个序列称为“调用栈”。
通过“反向跟踪”我们可以清楚的知道错误发生在我们代码的第几行。在从多个位置调用函数的程序中,调用栈就能帮助你确定哪次调用导致了错误。
只要抛出的异常没有被处理,Python 就会显示反向跟踪。但你也可以调用traceback.format_exc(),得到它的字符串形式。如果你希望得到异常的反向跟踪的信息,但也希望 except 语句优雅地处理该异常,这个函数就很有用。在调用该函数之前,需要导入 Python 的 traceback 模块。