(面试必备)你真的不想知道从浏览器中输入url, 到最终看到页面内容,这中间都经历了哪些过程吗???
网络原理理解(按照层次)和后端理解
- 从网络原理角度从上层到下层,再从下层到上层
- 客户端发送请求的阶段开始
- 应用层
- 传输层
- 网络层
- 数据链路层
- 物理层
- 这时,客户端发送请求的阶段结束
- 服务器端开始
- 物理层
- 数据链路层
- 网络层
- 传输层
- 应用层
- 服务器端返回响应
- 客户端收到响应则开始页面渲染
- 站在后端开发角度
从网络原理角度从上层到下层,再从下层到上层
大致要经历如图这样一个流程

客户端发送请求的阶段开始
应用层
1、输入URL进行搜索
判断用户输入的是搜索内容还是请求的URL
如果是搜索内容,地址栏会使用浏览器默认的搜索引擎合成完整的带搜索关键字的URL
2、查找本地缓存是否有资源
如果有,直接返回缓存资源;
如果没有,进入下一个网络请求阶段
3、DNS解析域名得到IP地址
先查浏览器缓存,再查hosts主机文件,最后查DNS服务器(递归/迭代查询)
4、客户端发送HTTP请求构造HTTP协议的数据包
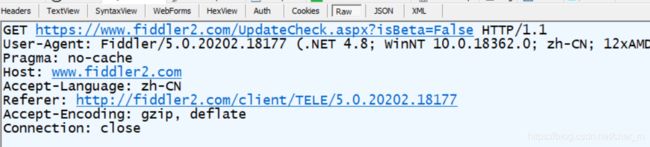
使用方法GET,URL就是输入的URL,浏览器会自动增添报头,之后数据报被交给传输层
5、打开一个Socket与目标IP地址,端口建立TCP连接(三次握手)

6、浏览器端构建请求行(方法 URL 版本号)、请求头(Headers)信息,还要把cookie数据附加到请求头中(如果浏览器此时保存了Cookie字段的话),接下来这个数据报就会被交给传输层
传输层
7、传输层的TCP协议就会把这个数据构造成一个TCP数据报(在构造这个包之前,已经经历三次握手建立连接),然后交给网络层的IP协议
网络层
8、IP协议构造成一个IP数据报
IP协议把TCP分割好的各种数据包传送给接收方
(此处要根据数据报的长度,以及MTU的限制,考虑是否分包(分包过程和组包))
9、查路由表,决定从哪个端口转发,然后将数据交给数据链路层。
IP地址和MAC地址是一一对应的关系,一个网络设备的IP地址可以更换,但是MAC地址一般是固定不变的。ARP协议可以将IP地址解析成对应的MAC地址。
数据链路层
10、构造一个以太网数据帧,源mac,就是本机mac,目的mac,根据上面IP确定的转发端口来决定(mac学习ARP)再将其交给物理层
构造以太网数据帧的时候需要填写源MAC地址(就是当前主机的MAC地址)和目的MAC地址(如果不知道目的MAC地址 就要根据ARP协议来进行 MAC学习) 最后根据上面IP地址来确认转发的端口号
物理层
11、在物理层会将数据帧转换二进制bit流最后变成光信号或者电信号进行传输
12、先传输到下一台路由器上,路由器进行解析和分组(解析到传输层),
进行NAT,然后进行路由选择,继续查路由表,把数据再次封装,往下一个路由器设备上转发(封装和分用)
13、中间经历多个路由器转发过程,之后到达目标服务器
在找到对方的MAC地址后,就将数据发送到数据链路层传输。
这时,客户端发送请求的阶段结束
=====================================================================================
服务器端开始
物理层
14、服务器又会对信息进行分用,物理层把光电信号转成二进制bit流,交给数据链路层
数据链路层
15、数据链路层解析出IP数据报,交给网络层
网络层
16、网络层可能进行组包,解析出其中的传输层数据,交给传输层
传输层
17、TCP解析出其中的应用层数据,交给应用程序.
返回ACK(确认序号、窗口大小、延时应答、捎带应答),ACK也是一个TCP数据报,也会涉及到一系列封装和分用过程。
应用层
18、服务器的应用程序,读取数据,根据请求计算响应,得到一个html页面,把页面构造成一个HTTP响应报文,经过一系列封装、分用、传输,把上述的过程再走一遍,最终回到客户端
服务器端返回响应
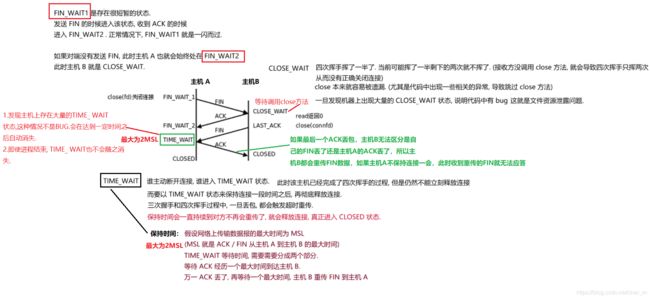
19.、客户端的浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重用,关闭TCP连接的四次挥手如下:
20、客户端浏览器,把响应报文解析出来
解析响应报文的时候会首先重点看其首行 (版本号 状态码 状态码描述)
响应行返回状态码200,请求成功,进入下一步
响应行返回状态码301或302,浏览器需要重定向到响应头Location字段的URL地址,重新开始发起请求
响应行返回状态码 40xx客户端错误
响应行返回状态码 5xx 服务器错误
接下来再解析Headers部分 解析body部分
21. 响应数据类型处理
响应头Content-Type返回值是application/octet-stream,表示返回的数据是字节流类型,浏览器会按下载类型来处理,将请求提交给浏览器的下载管理器,请求流程结束。
响应头Content-Type返回值是text/html,表返回的数据是HTML格式,进入下一步
客户端收到响应则开始页面渲染
22、渲染html,显示到浏览器上。渲染阶段
页面解析和子资源加载
构建DOM树(DOM是保存在内存中浏览器可以理解的树状结构,可以通过JS进行增删改查)
样式计算
把css转换为浏览器能够理解的结构——styleSheets
转换样式表中的属性值,使其标准化,例如:
em、rem等单位解析成px
颜色设置解析为rgb格式
bold、lighter等单次解析成对应的数值
…
计算出DOM树中每个节点的具体样式,被保存到ComputedStyle结构内
样式继承
样式层叠
布局,计算DOM树中可见元素的几何位置
创建布局树(只包含可见元素)
布局计算(计算每个可见元素的坐标位置)
分层,生成图层树
布局树的节点不一定有对应的图层,若没有,则从属于父节点的图层
有明确定位属性、透明属性、css滤镜、剪裁等地方会被创建为图层
图层绘制
把图层的绘制拆分成很多绘制指令
按照顺序把绘制指令组成待绘制列表,提交到合成线程
分块(页面很长的时候,可视区域只能看到很小的一部分,合成线程将图层划分为图块,优先处理可视区域附近的图块,可以减小开销)
栅格化
将图块转换为位图的过程
使用GPU来加速生成,生成的位图保存在GPU内存中
合成
所有图块栅格化后,合成线程生成一个绘制图块的命令,提交给浏览器进程
浏览器接收到命令后将页面内容绘制到内存中,再将内存显示在屏幕上
23. 页面生成完成后,渲染进程会发送消息给浏览器进程
24. 浏览器进程收到消息后,停止标签图标的loading加载动画,一个完整的页面就生成了
站在后端开发角度
从后端角度,就不考虑网络传输

1、比如要请求百度首页,可能直接请求到达CDN服务器,就直接返回了,不需要真正到百度的机房。
CDN是网络运营商架设的服务器.全国各地有很多 CDN. (百度可以把一些常用的静态资源直接部署到CDN上)
2、如果CDN. 上没有,请求可能会到达百度机房中的反向代理服务器(缓存)
3、如果反向代理中也没有,需要访问百度的应用服务器(负载均衡)
4、如果是百度搜素,先到搜索web服务器,再到分词和检索服务器获取用户服务器,针对用户信息进行推荐,再从物料服务器对信息整合,物料服务器后面连接数据库和爬虫程序。