SVM简介、SVM与感知机、逻辑回归LR的区别
硬间隔SVM
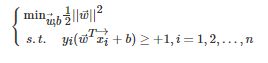
软间隔SVM
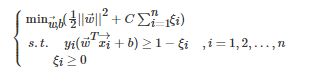
.
核函数:
![]()
SVM与感知机的区别
SVM分类超平面的解是唯一的,要满足间隔最大化
感知机的解不唯一,没有间隔最大化的约束条件,满足分开数据点的分界面都是可以的
SVM与逻辑回归的区别
https://blog.csdn.net/yan456jie/article/details/52524942
相同点:
第一,LR和SVM都是分类算法。
第二,如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的
第三,LR和SVM都是监督学习算法。
第四,LR和SVM都是判别模型。
两种方法都是常见的分类算法,其中心思想都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。
而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。两者的根本目的都是一样的。
比较:
0、概率值
LR给出了后验概率,SVM只有01分类,没有后延概率
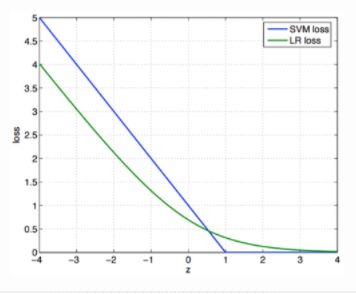
1、损失函数
LR采用logistic损失(误差平方和损失)
SVM采用合页(Hinge)损失。(损失函数是二者的本质区别)
SVM的损失函数就自带正则!!!(损失函数中的1/2||w||^2项),这就是为什么SVM是结构风险最小化算法的原因!!!而LR必须另外在损失函数上添加正则项!!

2、异常值
LR对异常值敏感;SVM对异常值不敏感,泛华能力强,分类效果好。
3、训练数据体量
在训练集较小时,SVM较适用,而LR需要较多的样本。
4、起作用点的范围
LR模型找到的那个超平面,是尽量让所有点都远离他,而SVM寻找的那个超平面,是只让最靠近中间分割线的那些点尽量远离,即只用到那些支持向量的样本。
5、非线性问题的处理方式
对非线性问题的处理方式不同,LR主要靠特征构造,必须组合交叉特征,特征离散化;
SVM也可以这样,还可以通过kernel,kernel很强大。
6、理解性:
LR相对来说模型更简单,好理解,实现起来,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些。但是SVM的理论基础更加牢固,有一套结构化风险最小化的理论基础.
7.线性SVM依赖数据表达的距离测度,所以需要对数据先做normalization,LR不受其影响
一个机遇概率,一个机遇距离
线性回归和逻辑回归
线性回归:

实际应用中,概率p与因变量往往是非线性的,为了解决该类问题,我们引入了logit变换,使得logit(p)与自变量之
间存在线性相关的关系,
逻辑回归:

通过推导,概率p变换如下,这与Sigmoid函数相符,也体现了概率p与因变量之间的非线性关系。以0.5为界限,预
测p大于0.5时,我们判断此时y更可能为1,否则y为0。

(非线性情况下,可以加kernel,或者特征相乘 )
Logistic优缺点:
优:计算代价不高,易于理解和实现。
缺:容易欠拟合,分类精度可能不高。
SVM优缺点:
优:泛化错误率低,计算开销不大,结果易解释。
缺:SVM对参数调节和核函数的选择敏感,原始分类器不加修改仅适用于处理二类问题。
svm: https://blog.csdn.net/liugan528/article/details/79448379
https://blog.csdn.net/u011204487/article/details/60590070
https://blog.csdn.net/jfhdd/article/details/52319422
https://blog.csdn.net/u010692239/article/details/52345754
https://www.cnblogs.com/daguankele/p/6652597.html