跟踪算法报告
文章目录
- 多目标跟踪
- 基于检测的MOT
- 基本流程
- 经典算法
- 不基于检测的MOT
- 单目标跟踪
- 经典算法
- 1.SiamFC
- 2.SiamRPN
- 3.DaSiamRPN
- 4.SiamRPN++
- 5.SiamFC++
本报告这里只探讨基于深度学习的跟踪算法,相关滤波的跟踪算法不予考虑,目标追踪算法主要有两个分支,一个分支是基于深度学习的方案,一个分支是基于相关滤波的方案。由于基于深度学习的方案实时性以及准确率目前都要高一些,所以后文中主要讨论基于深度学习的方案。
多目标跟踪
基于检测的MOT
经典算法 DeepSort
基本流程
(1)给定视频的原始帧;(2)运行对象检测器以获得对象的边界框;(3)对于每个检测到的物体,计算出不同的特征,通常是视觉和运动特征;(4)之后,相似度计算步骤计算两个对象属于同一目标的概率;(5)最后,关联步骤为每个对象分配数字ID。
因此绝大多数MOT算法无外乎就这四个步骤:①检测 ②特征提取、运动预测 ③相似度计算 ④数据关联。**其中影响最大的部分在于检测,检测结果的好坏对于最后指标的影响是最大的。**但是,多目标追踪的研究重点又在相似度计算和数据关联这一块。
经典算法
1.DeepSort
论文链接
Pytorch实现
检测框来自于各种常见的OD算法比如YOLO3,作为卡尔曼滤波器的测量值,卡尔曼滤波器作为运动模型来描述帧与帧目标运动状态之间的关系,更新模块则是包括匹配,跟踪器更新和特征集更新,这部分根本方法还是使用IOU来进行匈牙利算法匹配,但修改了数据顺序,优先匹配与当前帧更接近的轨迹,防止检测结果与遮挡时间更长的轨迹相关联,这种做法的缺点是:可能导致一些新的轨迹被连接到一些旧的轨迹上。
创新点:1.基于匈牙利算法里的代价矩阵。它在IOU Match之前做了一次额外的级联匹配,利用了外观特征和马氏距离。2.用深度学习求得外观特征,外观特征就是通过一个Re-ID的网络提取的,而提取这个特征的过程和NLP里词向量的嵌入过程(embedding)很像。然后是因为欧氏距离忽略空间域分布的计算结果,所以增加里马氏距离作为运动信息的约束。
缺陷
1.因为相机抖动明显,卡尔曼预测所基于的匀速运动模型并不work,所以马氏距离其实并没有什么作用。
2.跟踪的两个目标,其中一个将另一个遮挡了连续多帧后,被遮挡目标的ID会被改变。
3.没有考虑用跟踪来弥补漏检问题
最大优点
1.检测速度快
改进
1.用更好的运动模型,比如不匀速的卡尔曼滤波?
2.对于轨迹段来说,时间越长的轨迹可能不应该得到更多信任,引入轨迹评分机制,《Real-Time Multiple People Tracking with Deeply Learned Candidate Selection And Person Re-ID》的创新点基于这个评分就可以把轨迹产生的预测框和检测框放一起做一个NMS,相当于是用预测弥补了漏检。
未来展望
感觉工业上的应用就是ReID+Kalma的思路去做
不基于检测的MOT
与基于检测的追踪相比建模复杂,很难实时运行,比如蒙特卡洛,光流,多假设追踪等
单目标跟踪
与MOT不同,SOT的研究内容是第一帧给一个bbox,然后进行跟踪,相比MOT,SOT的目标类别不做限定,难以区分相似的类内对象,另一个不同点是SOT的研究趋势逐步从基于Detection的跟踪的思维中摆脱,采用多分支多通道你和目标的位置、姿态等信息。
经典算法
Siam系列
孪生网络是使用深度学习进行目标追踪的重要解决方案,孪生网络家族的最新论文SiamRPN++已经在很多数据集上取得了state of art 的结果,
孪生网络家族有几篇重要的论文,主要包括:SiamFC、SiamRPN、DaSiamRPN、SiamRPN++
核心理念:
- 跟踪任意目标的学习可看成是相似性问题的学习。我们提出学习一个函数 f(x,z) 来比较样本图像 z 和搜索图像 x 的相似性。如果两个图像描述的是同一个目标,则返回高分,否则返回低分。
- 我们用深度神经网络来模拟函数 f ,而深度卷积网络中相似性学习最典型的就是孪生结构。孪生网络对两个输入 z 和 x 进行相同的变换 φ ,然后将得到的输出送入函数 g ,最后得到相似性度量函数为:
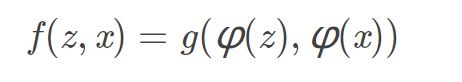
1.函数 g是一个简单的距离或相似性度量
2.φ 相当于特征提取器
Siam家族代码实现
1.SiamFC
参考博客
网络结构如下图所示
1.z 表示样本图像(即目标)
2.x 表示待搜索图像
在密集网格上计算所有平移窗口的相似度。本文的相似度函数使用互相关,公式如下:

1.b1 表示在得分图中每个位置的取值
2.上式可将 φ(z) 看成卷积核,在 φ(x) 上进行卷积
跟踪时以上一帧目标位置为中心的搜索图像来计算响应得分图,将得分最大的位置乘以步长即可得到当前目标的位置。

这个方法在初始离线阶段把深度卷积网络看成一个更通用的相似性学习问题,然后在跟踪时对这个问题进行在线的简单估计。即训练了一个孪生网络在一个较大的搜索区域搜索样本图片。搜索区域x来说,以上一帧预测的bbox的中心为裁剪中心,裁剪出255x255大小的图片。这里,作者为了提高跟踪性能,选取了多尺度进行预测,分别是1.025^{-2,-1,0,1,2},其中255x255对应尺度为1。之后作者又尝试了三种尺度的SiamFC-3s,提升了FPS。
优点1:运行时的帧率远超实时性的要求。
优点2:新的孪生网络结构是一个关于搜索区域的全卷积网络:密集高效的滑动窗口估计可通过计算两个输入的互相关性并插值得到。
缺点1:首先由于没有回归,网络无法预测尺度上的变化,所以只能通过多尺度测试来预测尺度的变化,这里会降低速度。
缺点2:其次,输出的相应图的分辨率比较低,为了得到更高精度的位置,Siamese FC采用插值的方法,把分辨率放大16倍,达到与输入尺寸相近的大小。
2.SiamRPN
参考博客
RPN(Region Proposal Network) 是FasterRCNN中提出的专门用于回归Region Proposal 的网络。
SiameseRPN和SiameseFC使用了相同的数据读入方案,都是构建一个模板区域和一个搜索区域,但是SiameseRPN和SiameseFC不同的是,SiameseRPN在网络的后面加入了一个RPN的结构,RPN的结构可以回归物体的类别以及物体的BBox,这是对SiameseFC的巨大改进,因为SiameseFC中是选择score map中响应最大的点的原始图像感受野作为标定框,所以标定框的大小始终是固定的,这就给算法带来了很多限制,比如说要求被跟踪的物体的大小不能有太大变化等。SiameseRPN使用检测的思路解决了SiameseFC中标定框不能被回归的问题,大大提升了准确率。
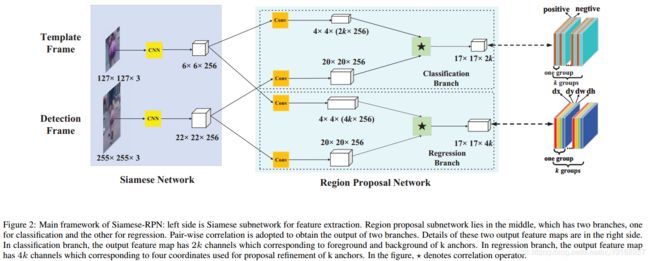
优点:通过引入物体检测领域的区域推荐网络(RPN),通过网络回归避免多尺度测试,一方面提升了速度,另一方面可以得到更为精准的目标框,更进一步,通过RPN的回归可以直接得到更精确地目标位置,不需要通过插值得到最终的结果。
缺点:除了目标得分较高,其他类似的物体得分也很高。(孪生家族的通病)
原因一:无语义信息的目标数量要远远大于有语义信息的目标和数量 在训练过程中,训练的图片对中,大部分区域都是没有语义信息的背景,有语义信息的很少,因此,网络只学习了区分背景和前景的能力。
原因二:有意义的目标中,大部分为干扰目标,而不是要跟踪的目标 在测试过程中,Siamese只使用了第一帧的部分图片,忽略了背景信息,此外Siamese只是将搜索区域附近得分最高的物体标记为目标,但是有可能周围的物体只是跟目标很像,并不是物体。

3.DaSiamRPN
参考博客
DaSiamRPN是SiamRPN的后续作品,使用的backbone为SiamRPN,本篇论文主要是在数据集扩展、训练方法、loss函数以及local-to-global方面对SiamRPN进行了改进。
针对传统Siam的缺点进行改进:
传统siamese的缺点 :
现象:除了目标得分较高,其他类似的物体得分也很高。
原因一:无语义信息的目标数量要远远大于有语义信息的目标和数量 在训练过程中,训练的图片对中,大部分区域都是没有语义信息的背景,有语义信息的很少,因此,网络只学习了区分背景和前景的能力。
原因二:有意义的目标中,大部分为干扰目标,而不是要跟踪的目标 在测试过程中,Siamese只使用了第一帧的部分图片,忽略了背景信息,此外Siamese只是将搜索区域附近得分最高的物体标记为目标,但是有可能周围的物体只是跟目标很像,并不是物体。
改进1:训练方法
- 通过多种类的正图片对来增加模型的生成能力 作者扩展了训练用的数据集,除了使用VID以及YouTube-BB之外(物体种类较少,分别只包含20和30个类),还通过数据增强的方式,使用ImageNet DET和COCO作为训练集,极大的增加了物体的种类。
- 通过包含语义信息的负图片对来增加模型的判别能力 作者在训练的过程中,有意的使用相同种类但不是目标的负图片对来训练网络,使得网络可以对同种类的不同物体进行有效的区分,增加了鲁棒性。
改进2:损失函数
在函数中增加了Distractor项
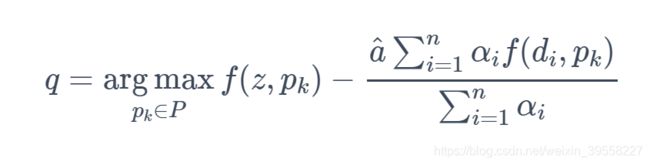
q 为当前的目标,p为top-k个和目标最像的样本
该公式的含义为,当前帧的跟踪结果应该和目标尽可能的像,同时跟Distractors尽可能的不像,有点类似于Re-id中的triplet loss,经过这样的优化以后,网络可以有效的学习检测目标并抑制Distractor的能力。
改进3:Long-term
传统的siameseRPN的输入图片只是局部图片,一旦物体移出图片,就无法找到目标了。
- local-to-global (不是很理解)
通过检测分数,来判断物体是否移出图片,根据效果可以看出,物体一旦移出图片,得分会急剧降低,此时,算法会扩大裁剪的局部图片,直到找到目标为止。由于DasiameseRPN对于图片中的背景和Distractor都能做出有效区分,所以只有当物体出现时,热度图的响应值才会增加,此时再进行局部搜索。
缺点:更换更强的网络后,跟踪效果并没有提升。
4.SiamRPN++
参考博客
参考博客2
这次的motivation就是解决网络问题。
网络升级,效果下降的原因分析:
传统的孪生网络通过相关操作,可以考虑成滑窗的形式计算每个位置的相似度。
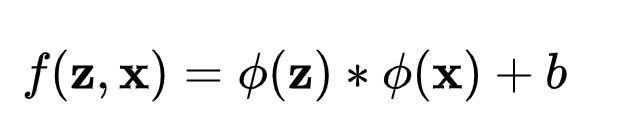
这里带来了两个限制:
1.网络需要满足严格的平移不变性。如SiamFC中介绍的,padding会破坏这种性质。
2.网络有对称性,即如果将搜索区域图像和模板区域图像,输出的结果应该不变。(因为是相似度,所以应该有对称性)。
但是!现代的网络如ResNet肯定不具备严格平移不变性,padding的引入使得网络输出的响应对不同位置有了不同的认知。而我们在这一步的训练希望的是网络学习到如何通过表观来分辨回归物体,这里就限制了深网络在tracking领域的应用
其次是网络对称性:由于SiamRPN的监督不再是相似度,而是回归的偏移量/前背景分数,不再具有对称性。所以在SiamRPN的改进中需要引入非对称的部件,如果完全Siamese的话没法达到目的。
简单的来说就是加入padding的网络训练后会学习到位置偏见,按照SiamFC的训练方法,正样本都在正中心,网络会学到这种统计特性,学到样本中正样本分布的情况。网络只对中心有响应
为什么这个问题在检测和语义分割中并不存在?
因为对于物体检测和语义分割而言,训练过程中,物体本身就是在全图的每个位置较为均匀的分布。我们可以很容易的验证,如果在物体检测网络只训练标注在图像中心的样本,而边缘的样本都不进行训练,那么显然,这样训练的网络只会对图像的中心位置产生高响应,边缘位置就随缘了,不难想象这种时候边缘位置的性能显然会大幅衰减。而更为致命的是,按照SiamFC的训练方式,中心位置为正样本,边缘位置为负样本。那么网络只会记录下边缘永远为负,不管表观是什么样子了。这完全背离了我们训练的初衷。
解决方法:
因此得到一个改进措施:在训练过程中,我们不再把正样本放在中心,而是以均匀分布的采样方式让目标在中心点附近进行偏移。所以说,通过均匀分布的采样方式让目标在中心点附近进行偏移,可以缓解网络因为破坏了严格平移不变性带来的影响,即消除了位置偏见,让现代化网络可以应用于跟踪中。
因此本文就可以使用更深的网络:resnet50
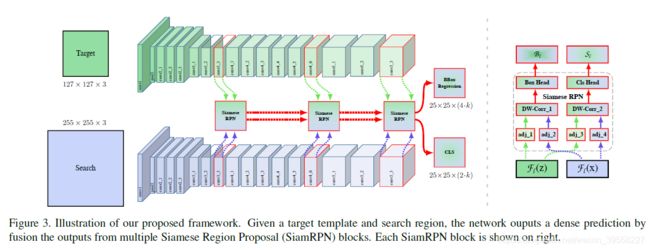 进一步改进:多层融合
进一步改进:多层融合
选择了网络最后三个block的输出进行融合(由于之前对网络的改动,所以分辨率一致,融合时实现起来简单)。对于融合方式上我们并没有做过多的探究,而是直接做了线性加权。
进一步改进:Depthwise Cross Correlation
这一点是一个通用的改进,并不是只针对于深网络的。
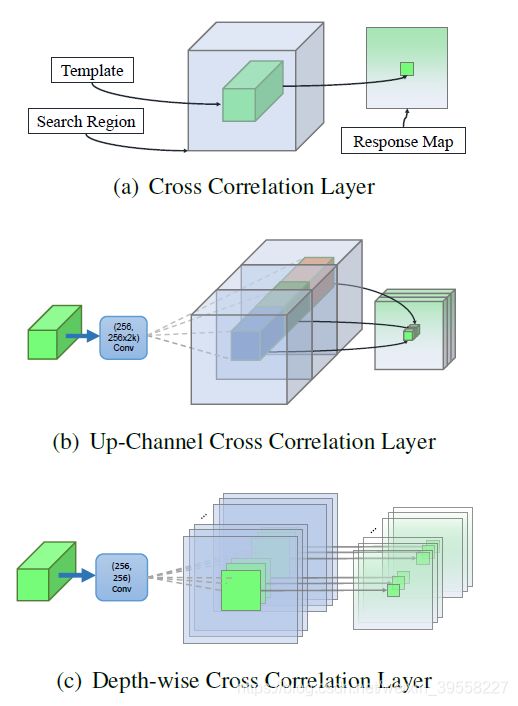

缺点:虽然能够找到优秀的精确的状态值,但是对于较大的尺度变化等困难样例来说,锚点与框的先验因素限制了追踪器的鲁棒性,容易产生lost。
5.SiamFC++
参考博客
一种基于SiamFC的新型孪生网络SiamFC++
本文的改进主要存在于4个方面:
-
分解分类与状态估计:分类器专攻将目标物体与背景分离,而状态估计则是为了产生更准确的BB,那些多尺度的方法忽略了后项,因此精度低下;
-
明确分类得分:分类得到应该直接表示为目标在视野中存在的置信度分数,而不是像预定义的anchor一样设置,对于RPN的思想极其容易产生假阳性样本。
-
去除先验知识:追踪应该符合通用的精神,即比例等因素不该成为搜索或者检测的因素,RPN的思想阻碍了追踪器的泛化能力;
-
作者借鉴了2019年另一篇论文,增加了评估质量的分支,边界框进行分类置信度会导致性能的下降。

论文的结果如上图所示,可以看到还是非常规整的Siamese网络结构。绿色的部分是传统的SiamFC分支,后面的红色部分加入了质量评估分支,而蓝色部分则是新加入的回归分支。中间的部分还是用一个cross-correlation的操作,和之前的Siamtracker都是一致的,回归与分类的分支的结合是用了一个argmax。