Deeplab笔记
一、Deeplab v2
对应论文是 DeepLab: Semantic Image Segmentiation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Deeplab 是谷歌在FCN的基础上搞出来的。FCN为了得到一个更加dense的score map,将一张500x500的输入图像,直接在第一个卷积层上conv1_1加了一个100的padding,最终在fc7层勉强得到一个16x16的score map。Deeplab这里使用了一个非常优雅的做法:将VGG网络的pool4和pool5层的stride由原来的2改为了1,再加上 1 padding。就是这样一个改动,使得vgg网络总的stride由原来的32变成8,进而使得在输入图像为514x514时,fc7能得到67x67的score map, 要比FCN确实要dense很多很多。这样的话尺寸就缩小为原本的8倍,但是这样的话之后节点的感受野就会发生变化。
1、感受野
感受野的计算公式:
RF=((RF-1)*stride)+fsize
感受野需要层后往前推,也就是“当前这一层的节点往前看能看到多少前几层的节点”。公式中假设当前层的RF=1,stride是上一层的步长,fsize是filter的尺寸,padding不影响感受野大小。这是一个递推公式。详细解释这个问题,请看下面的图
最左边的图就是VGG原来的结构,可以看到最下方的层往前看,能看到4个最上面层的节点,标号从左到右分别是{1,2,3,4},{3,4,5,6},{5,6,7,8},右边是将pooling的stride变为1之后的图,显而易见,最下方的节点的RF减少,只能看到最上面层的三个节点。为了解决这个问题,作者提出了Hole算法。
2.hole算法
为了保证感受野不发生变化,某一层的stride由2变为1以后,后面的层需要采用hole算法。具体来讲就是将连续的连接关系是根据hole size大小变成skip连接的(注意!是将kernel也就是filter加0,而不是featuremap)。pool4的stride由2变为1,则紧接着的conv5_1, conv5_2和conv5_3中hole size为2。接着pool5由2变为1, 则后面的fc6中hole size为4。同时由于Hole算法让feature map更加dense,所以网络直接用差值升采样就能获得很好的结果,而不用去学习升采样的参数了(FCN中采用了de-convolution)。该作者采用的方法是将缩小8倍的featuremap利用线性插值的方法恢复到与原图相同的尺寸。

点击打开链接
点击打开链接
2、多孔金字塔池化(ASPP)
为了解决物体在多尺度图像中状态不同的问题,作者受SPP启发,采用多孔金字塔池化方法。(关于spp详见另一篇博文)

以vgg16网络为例,ASPP的处理方式如下图。对pool5输出的featuremap(处理前的featuremap大小为28*28*512)进行四种rate不同的卷积处理,再将四种处理后的结果concate(方式与spp相同)。

3、全连接条件随机场(CRF)
弱分类器产生的分割图往往很粗糙,通常使用CRF来平滑去噪。而深度学习网络产生的分割图很平滑并且连续,在这种情况下需要使用short-range CRFs来恢复局部结构的细节而不是进一步平滑它。但采用该方法仍无法恢复结构中细小的部分,作者又采用了全连接条件随机场来恢复细节,效果很好。

二、Deeplab v3
对应论文是 Rethinking Atrous Convolution for Semantic Image Segmentation
Deeplab v3部分采用了resnet网络,网络结构如图
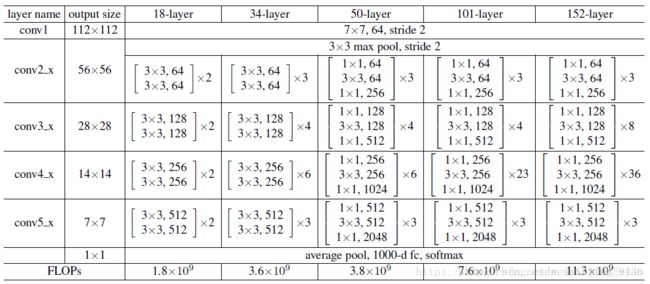
在Deeplab 的基础上,优化了以下几点。
1、加长了esnet网络,即新增block5,block6,block7 ,都是由block4复制而来。在block4到block7的内部都是三个卷积层,设Muliti_Grid=(r1,r2,r3)为这三个卷积的unit rate,最终的atrous rate = unit rate * corresponding rate。 如output_stride = 16,Muliti_Grid =(1,2,4)时,block4 中的rate=2*(1,2,4) = (2,4,8),block5中的rate=4*(1,2,4)=(1,8,16)。

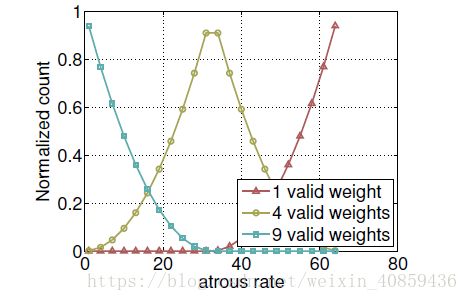
2、发现使用多孔卷积存在的问题:随着rate的增加,有效特征区域减小,如图所示。
为了解决这一问题,deeplab v3中提出的新的结构。改进的ASPP由一个1*1的卷积和3个3*3,rate=(6,12,18)的卷积组成(如果output_stride为8,则rate是两倍),将这四部分的特征图与gloabal average pooling得到的结果concat,经过一层1*1的卷积后,再送入最终的1*1卷积得到logits。
注:output_stride = input_image_size/output_feature_size

补充知识点:global average pooling (GAP)是将特征图进行整张图的均值池化,形成一个特征点,将这些特征点组成最后的向量。示意图如下:

GAP的真正意义是:对整个网路在结构上做正则化防止过拟合。其直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的内别意义。实践证明其效果还是比较可观的,同时GAP可以实现任意图像大小的输入。但是值得我们注意的是,使用gap可能会造成收敛速度减慢。
Global Average Pooling
相对应的代码为:
image_level_features = tf.reduce_mean(net, [1, 2], name=’image_level_global_pool’, keep_dims=True)
image_level_features = slim.conv2d(image_level_features, depth, [1, 1], scope=”image_level_conv_1x1″, activation_fn=None)
image_level_features = tf.image.resize_bilinear(image_level_features, (feature_map_size[1], feature_map_size[2]))
3、修改的训练时小trick有:
(1)batch normalization:在增加的每个module上都运用了batch normalization,因为训练batch normalization的参数需要batch size较大,这里采用了output_stride=16,并在batch size=16的条件下计算batch normalization statistics。
(2)上采样logits:在之前的工作中,都采用将groundtruth下采样8倍后的结果与生成的featuremap做logits,但他们研究发现这种方式会因为细节部分没有反向传播而造成好的标注被剔除。在这篇文章中,作者将生成的featuremap上采样8倍,groundtruth保持不变的方式进行训练。
(3)在训练过程中,采用output_stride = 16, 在inference过程中,采用output_stride = 8
(4)数据增强,变换图片大小(0.5-2倍),翻转
新引入了decoder和Xception来提高网络表现能力并降低计算复杂度
(1)Decoder
在Deeplabv3中,特征图被直接双线性插值上采样16倍变为与输入图像相同大小的图像,这种方法无法获得分割目标的细节。因此本文提出了一种简单有效的decoder如下图。encoder features来自于Deeplabv3(output_stride=16)。encoder features首先双线性插值上采样4倍,然后与网络中产生的空间分辨率相同的低层特征concate。在concate之前,先让低层特征通过一个1*1的卷积核以将channel减少到256,。concate之后,通过几个3*3卷积来重新定义特征,紧接着双线性插值上采样4倍。
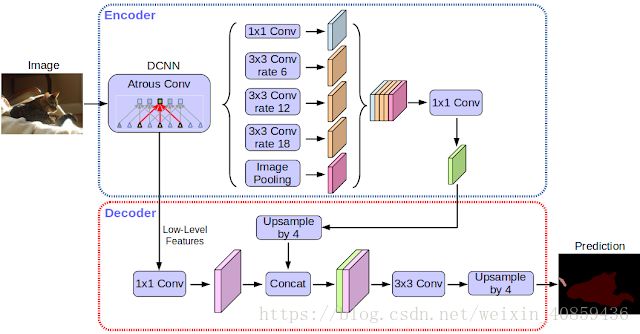
(2)Xception
关于Xception介绍请见另一篇博客。
作者修改了Xception模型以适应图像分割任务。作者修改内容如下:层数更多;将所有的最大池化操作换成depthwise separable convolutions with striding;每3个depthwise separable convolutions 后加一个batch normalizaiton和Relu。
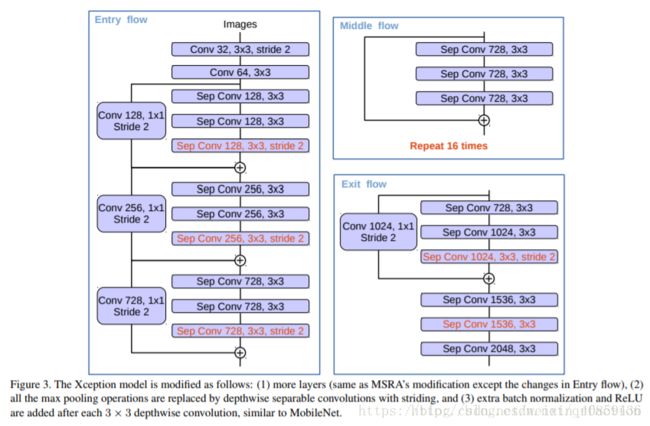
但在作者提出的这个网络中,只在ASPP(带孔卷积模块)和decoder模块采用depthwise separable convolution,以加快计算速度。
点击打开链接