0x01 前言
今天用lijiejie师傅的子域名扫描器测试某电商的域名,结果差不多有70000+条子域名,自己手工访问一些网站的时候,有如下结果
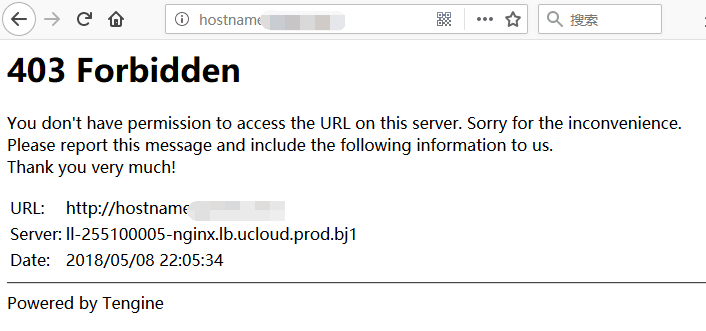
这个结果是tengine服务器的web目录下没有index而造成的现象,而且这种类似的服务器一般不存在漏洞,web服务是没有的,以及端口的开放状况也大多数是80 443端口,我们需要舍弃
还有openresty的403
以及nginx的502 Bad Gateway等等
那么如何在那么多的子域名中找到web服务开放的域名,可能需要(python)的帮助
0x01 80_open_detect_V1.0编写
最初想的是用单线程,每行读取子域名,然后用requests模块进行访问,通过特征来判断是否是有服务的域名。
80_open_detect_V1.0.py
#coding=utf-8
# Author : MrSm1th
import requests
import re
import os
def main(file,newfile):
i=0
j=0
f = open(file,"r")
f1 = open(newfile,"a+")
while 1:
j+=1
line = f.readline()
if not line:
print "[*]done!Found: "+str(i)
break
url = "http://"+"".join(re.findall("(.*).com",line))+".com"
print str(j)+":"+url
try:
if "403 Forbidden" and "Powered by Tengine" in requests.get(url).content:
continue
else:
i+=1
print "[*]found:"+url
f1.write(url+"\n")
except:
print "[-]connect fail:"+url
f1.close()
f.close()
if __name__ == '__main__':
file = raw_input("enter file you want to detect:")
if(os.path.exists(file)==False):
exit("[-]file not exists")
newfile = file+"_80_open_detect.txt"
if(os.path.exists(newfile)==True):
exit("[-]newfile exists")
main(file,newfile)但是经过测试后发现脚本速度很慢。随即发现需要用多线程跑。
0x01 80_open_detect_V2.0效果
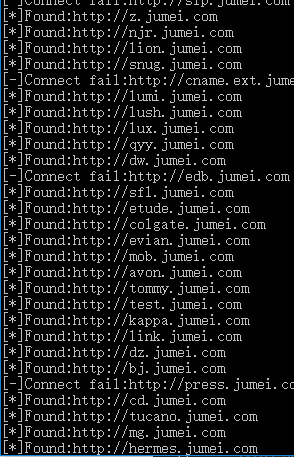
80_open_detect_V2.0.py 具有自定义线程 异常处理等功能 方便平时的漏洞挖掘
记录一下。。