用深度学习识别海洋生物?飞桨轻松完成挑战!

【飞桨开发者说】文瑞洁,中科院信工所工程师,主要研究计算机视觉、深度学习
海洋中的鱼类资源不仅有一定的食用价值,而且有很高的药用价值,近年来,世界各国对于海洋鱼类资源的重视程度与日俱增。在鱼类资源的开发利用中,必须对鱼类进行识别,从而了解其分布情况。但是由于鱼的种类繁多,形状大小相似,同时考虑到海底拍摄环境亮度低、场景模糊的实际情况,对鱼类资源的识别较为困难。
针对海洋鱼类识别难的问题,本实践使用卷积神经网络(Convolutional Neural Network,CNN)构建深度学习模型,自动提取高质量的特征,从而解决海洋鱼类识别的问题。接下来,让我们一起来学习如何使用百度深度学习框架飞桨来搭建卷积神经网络,实现海洋鱼类资源的识别。
首先,让我们来回顾一下卷积神经网络吧!
01
卷积神经网络
卷积神经网络主要由卷积层、池化层和全联接层三种网络层构成,在卷积层与全联接层后通常会接激活函数。
卷积层
卷积层会对输入的特征图(或原始数据)进行卷积操作,输出卷积后产生的特征图。卷积层是卷积神经网络的核心部分。输入到卷积层的特征图是一个三维数据,不仅有宽、高两个维度,还有通道维度上的数据,因此输入特征图和卷积核可用三维特征图表示。如下图所示,对于一个(3,6,6)的输入特征图,卷积核大小为(3,3,3),输出大小为(1,4,4),当卷积核窗口滑过输入时,卷积核与窗口内的输入元素作乘加运算,并将结果保存到输出相应的位置。
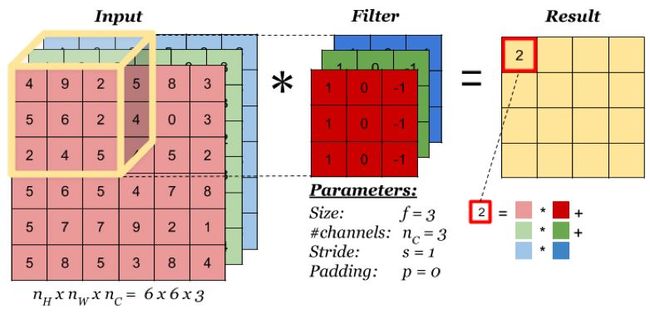
上图中卷积操作输出了一张特征图,即通道数为1的特征图,而一张特征图包含的特征数太少,在大多数计算机视觉任务中是不够的,所以需要构造多张特征图,而输入特征图的通道数又与卷积核通道数相等,一个卷积核只能产生一张特征图,因此需要构造多个卷积核。在RGB彩色图像上使用多个卷积核进行多个不同特征的提取,示意图如下:

池化层
池化层的作用是对网络中的特征进行选择,降低特征数量,从而减少参数数量和计算开销。池化层降低了特征维的宽度和高度,也能起到防止过拟合的作用。最常见的池化操作为最大池化或平均池化。如下图所示,采用了最大池化操作,对邻域内特征点取最大值作为最后的特征值。
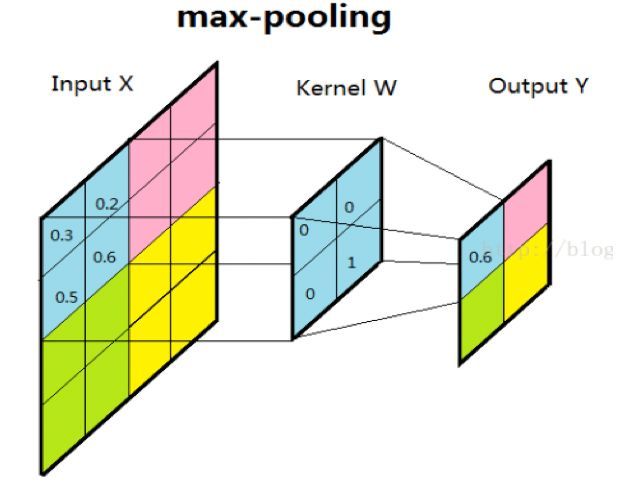
最常见的池化层使用大小为2×2,步长为2的滑窗操作,有时窗口尺寸为3,更大的窗口尺寸比较罕见,因为过大的滑窗会急剧减少特征的数量,造成过多的信息损失。
批归一化层
批归一化层是由Google的DeepMind团队提出的在深度网络各层之间进行数据批量归一化的算法,以解决深度神经网络内部协方差偏移问题,使用网络训练过程中各层梯度的变化趋于稳定,并使网络在训练时能更快地收敛。
02
基于飞桨的海洋鱼类识别
飞桨是以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心框架、基础模型库、端到端开发套件、工具组件和服务平台于一体,2016 年正式开源,是全面开源开放、技术领先、功能完备的产业级深度学习平台。
下面我将为大家展示如何用 PaddlePaddle API 编程并搭建一个简单的卷积神经网络,解决海洋鱼类识别问题。主要分为五个步骤,数据准备、模型配置、模型训练、模型评估以及最后使用训练好的模型进行预测。
本实践代码运行的环境配置如下:Python版本为3.7,飞桨版本为1.6.0,操作系统为Windows64位操作系统。
步骤1:数据准备
本次实践所使用的是fish4knowledge公开数据集。该数据集是海洋水下观景台收集的鱼类图像数据集,包括23类鱼种,共27370张鱼的图像。

#导入必要的包
import os
import paddle
import numpy as np
from PIL import Image
import paddle.fluid as fluid
from multiprocessing import cpu_count
import matplotlib.pyplot as plt
def data_mapper(sample):
img_path, label = sample
#进行图片的读取,由于数据集的像素维度各不相同,需要进一步处理对图像进行变换
img = paddle.dataset.image.load_image(img_path)
img = paddle.dataset.image.simple_transform(im=img,
resize_size=47,
crop_size=47,
is_color=True,
is_train=True)
img= img.flatten().astype('float32')/255.0
return img, label
def data_r(file_list,buffered_size=1024):
def reader():
with open(file_list, 'r') as f:
lines = [line.strip() for line inf]
for line in lines:
img_path, lab =line.strip().split('\t')
yield img_path, int(lab)
return paddle.reader.xmap_readers(data_mapper, reader,cpu_count(),buffered_size)
了解了数据的基本信息之后,我们需要有一个用于获取图片数据的数据提供器,在这里我们定义为data_r(),它的作用就是提供图片以及图片的标签。为了方便对图片进行归一化处理和获得数据的label,我们定义了data_mapper()。
paddle.reader.xmap_readers()是paddle提供的一个方法,功能是多线程下,使用自定义映射器 reader 返回样本到输出队列(详细介绍可在
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/io_cn/xmap_readers_cn.html#xmap-readers中查看)。
有了数据提供器data_r()后,我们就可以很简洁的得到用于训练的数据提供器和用于测试的数据提供提供器了,BATCH_SIZE是一个批次的大小,在这里我们设定为64。
BATCH_SIZE = 64
BUF_SIZE=512
#构造训练数据提供器
train_r=data_r(file_list=TRAIN_LIST_PATH)
train_reader = paddle.batch(
paddle.reader.shuffle(
reader=train_r,buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
#构造测试数据提供器
eval_r = data_r(file_list=EVAL_LIST_PATH)
eval_reader =paddle.batch(eval_r,batch_size=BATCH_SIZE)
步骤2:模型配置
数据准备的工作完成之后,接下来我们将动手来搭建一个CNN网络,进行图片特征的提取,从而实现海洋鱼类的识别。
(1)模型定义
飞桨提供了fluid.layers.con2d()和pool2d()方法分别定义卷积与池化操作,使用fluid.layers.batch_norm()方法定义了批归一化操作。如下述代码所示,使用百度深度学习框架飞桨搭建了一个三层的卷积神经网络,最后经过一个以Softmax为激活函数的全连接输出层,因为存在23类鱼,所以最后的全联接层的输出神经元个数为23。
def convolutional_neural_network(img):
# 第一个卷积-池化层
conv1=fluid.layers.conv2d(input=img, #输入图像
num_filters=20, #卷积核数量,它与输出的通道相同
filter_size=5, #卷积核大小
act="relu") #激活函数
pool1 = fluid.layers.pool2d(
input=conv1, #输入
pool_size=2, #池化核大小
pool_type='max', #池化类型
pool_stride=2) #池化步长
conv_pool_1 = fluid.layers.batch_norm(pool1)
# 第二个卷积-池化层
conv2=fluid.layers.conv2d(input=conv_pool_1,
num_filters=50,
filter_size=5,
act="relu")
pool2 = fluid.layers.pool2d(
input=conv2,
pool_size=2,
pool_type='max',
pool_stride=2,
global_pooling=False)
conv_pool_2 = fluid.layers.batch_norm(pool2)
# 第三个卷积-池化层
conv3=fluid.layers.conv2d(input=conv_pool_2,
num_filters=50,
filter_size=5,
act="relu")
pool3 = fluid.layers.pool2d(
input=conv3,
pool_size=2,
pool_type='max',
pool_stride=2,
global_pooling=False)
# 以softmax为激活函数的全连接输出层,23类鱼,所以size=23
prediction = fluid.layers.fc(input=pool3,
size=23,
act='softmax')
return prediction
接下来进行数据层的定义。由于数据是47*47的三通道彩色图像,所以输入层image的维度为[None,3,47,47],label代表图片的分类标签。
image = fluid.data(name='image',shape=[None,3, 47, 47], dtype='float32')
label = fluid.data(name='label',shape=[None,1], dtype='int64')
上面我们定义好了卷积神经网络结构,这里我们使用定义好的网络来获取分类器。
predict=convolutional_neural_network(image)
(2)损失函数
接着是定义损失函数,这里使用的是交叉熵损失函数,该函数在分类任务上比较常用。定义了一个损失函数之后,还要对它求平均值,因为定义的是一个Batch的损失值。同时还可以定义一个准确率函数,可以在训练的时候输出分类的准确率。
cost =fluid.layers.cross_entropy(input=predict, label=label)
avg_cost = fluid.layers.mean(cost)
accuracy =fluid.layers.accuracy(input=predict, label=label)
为了区别测试和训练,在这里我们克隆一个test_program()。
test_program=fluid.default_main_program().clone(for_test=True)
(3)优化方法
接着定义优化算法,这里使用的是Adam优化算法,指定学习率为0.0001。
optimizer = fluid.optimizer.Adam(learning_rate=0.0001)# Adam是一阶基于梯度下降的算法,基于自适应低阶矩估计该函数实现了自适应矩估计优化器
optimizer.minimize(avg_cost)
用户完成网络定义后,一段Paddle程序中通常存在两个Program:
fluid.default_startup_program:定义了创建模型参数,输入输出,以及模型中可学习参数的初始化等各种操作,由框架自动生成,使用时无需显示地创建;
fluid.default_main_program:定义了神经网络模型,前向反向计算,以及优化算法对网络中可学习参数的更新,使用Fluid的核心就是构建起 default_main_program。
步骤3:模型训练
在上一步骤中定义好了网络模型,即构造好了两个核心Program,接下来将介绍飞桨如何使用Excutor来执行Program。首先在正式进行网络训练前,首先进行参数初始化。
use_cuda = True
place = fluid.CUDAPlace(0) if use_cudaelse fluid.CPUPlace()#定义训练设备为CPU或GPU
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program()) #执行参数初始化操作
定义好模型训练需要的Executor,在执行训练之前,需要告知网络传入的数据分为两部分,第一部分是images值,第二部分是label值:
feeder= fluid.DataFeeder(place=place, feed_list=[image, label])
之后就可以进行正式的训练了,本实践中设置训练轮数20。在Executor的run方法中,feed代表以字典的形式定义了数据传入网络的顺序,feeder在上述代码中已经进行了定义,将data[0]、data[1]分别传给image、label。fetch_list定义了网络的输出。
在每轮训练中,每100个batch,打印一次训练平均误差和准确率。每轮训练完成后,使用验证集进行一次验证。
EPOCH_NUM = 20
for pass_id in range(EPOCH_NUM):
train_cost = 0
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(
program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost,accuracy])
if batch_id % 100 == 0:
print("\nPass %d, Step %d,Cost %f, Acc %f" %
(pass_id, batch_id, train_cost[0],train_acc[0]))
test_accs = []
test_costs = []
# 每训练一轮 进行一次测试
for batch_id, data in enumerate(eval_reader()):
test_cost, test_acc = exe.run(program=test_program, 、
feed=feeder.feed(data),
fetch_list=[avg_cost, accuracy]
test_accs.append(test_acc[0])
test_costs.append(test_cost[0])
test_cost = (sum(test_costs) / len(test_costs))
test_acc = (sum(test_accs) / len(test_accs)) 平均准确率
print('Test:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, test_cost, test_acc))
每轮训练完成后,对模型进行一次保存,使用飞桨提供的fluid.io.save_inference_model()进行模型保存:
model_save_dir ="/home/aistudio/work/model"
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
# 保存训练的模型,executor 把所有相关参数保存到 dirname 中
fluid.io.save_inference_model(model_save_dir,#保存模型的路径
['image'], #预测需要 feed 的数据
[predict], #保存预测结果的变量
exe) #executor 保存预测模型
步骤4:模型评估
通过观察训练过程中误差和准确率随着迭代次数的变化趋势,可以对网络训练结果进行评估。
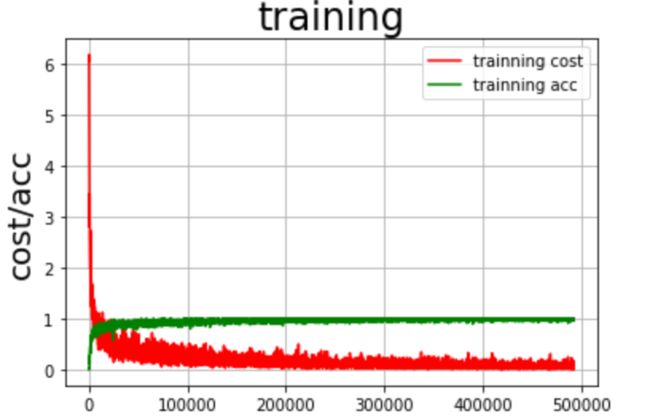
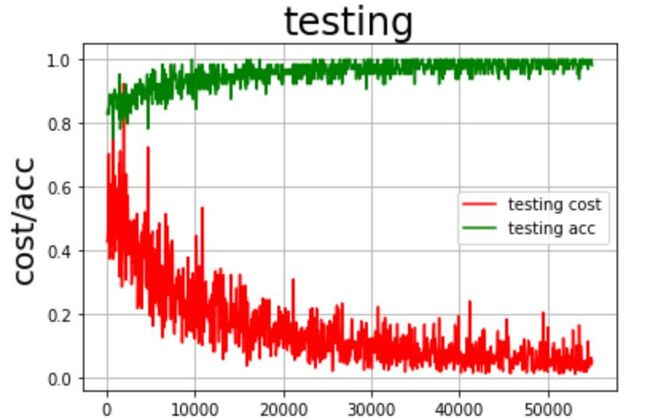
通过上图可以观察到,在训练和验证过程中平均误差是在逐步降低的,与此同时,训练与验证的准确率逐步趋近于100%。
步骤5:模型预测
前面已经进行了模型训练,并保存了训练好的模型。接下来就可以使用训练好的模型对海洋鱼类图片进行识别了。
预测之前必须要对预测的图像进行预处理,首先将图像大小缩放至与训练数据相同大小47*47,接着将图像转换为与训练数据维度相同的numpy数组,最后对图像进行归一化处理。代码实现如下所示:
# 图片预处理
def load_image(file):
im = Image.open(file)
im = im.resize((47, 47), Image.ANTIALIAS)
im = np.array(im).reshape(1, 3, 47, 47).astype(np.float32)
im = im / 255.0
return im
接下来使用训练好的模型对经过预处理的图片进行预测。首先从指定目录中加载训练好的模型,然后喂入要预测的图片向量,返回模型的输出结果,即为预测概率,这些概率的总和为1。
#with fluid.scope_guard(inference_scope):
#从指定目录中加载预测模型
[inference_program,# 预测用的program
feed_target_names,# 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(params_dirname,infer_exe)
img = Image.open(infer_img)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
image=load_image(infer_img)
# 开始预测
results = infer_exe.run(
inference_program, #运行预测程序
feed={feed_target_names[0]: image},#喂入要预测的数据
fetch_list=fetch_targets) #得到推测结果
print('results',results)
label_list = ["fish_21", "fish_19","fish_15", "fish_20","fish_1","fish_5","fish13","fish2","fish4","fish_14","fish_16","fish_6","fish_18","fish_17","fish_22","fish_8","fish_3","fish_23","fish_9","fish_7","fish_12","fish_11","fish_10"]
print("infer results: %s" % label_list[np.argmax(results[0])])得

至此,恭喜您!已经成功使用飞桨核心框架搭建了一个简单的卷积神经网络并实现了海洋生物的识别。本实践代码已在AI Studio上公开,访问:
https://aistudio.baidu.com/aistudio/projectdetail/155063 可在页面中找到对应实践代码。
文章配套视频、文档及notebook请点击课程
https://aistudio.baidu.com/aistudio/course/introduce/996,进行学习
如果您还想尝试更多,可以继续阅读相关的文档及更多丰富的模型实例:
飞桨官网地址:
https://www.paddlepaddle.org.cn/
GitHub地址:
https://github.com/paddlepaddle/paddle
想与更多的深度学习开发者交流,请加入飞桨官方QQ群:796771754。
或者您可以参考由中国科学院大学专家、百度深度学习工程师团队共同编著,清华大学出版社出版的《深度学习导论与应用实践》,该教材理论、实践深度结合,源于开源深度学习平台飞桨,独家融合大量实践案例,希望能帮助到想深入了解深度学习或者想进行深度学习实践的您!

