掌握生成对抗网络(GANs),召唤专属二次元老婆(老公)不是梦

全文共6706字,预计学习时长12分钟或更长

近日,《狮子王》热映,其逼真的外形,几乎可以以假乱真,让观众不禁大呼:awsl,这也太真实了吧!

实体模型、CGI动画、实景拍摄、VR等技术娴熟运用,呈现出超真实的画面,获得业内的一致认可。值得一提的是,影片运用人工智能数据分析技术,将其与VR相结合,让人们在虚拟现实的世界中体验更加真实。

人工智能领域的迅速发展和广泛运用,不断拉近二次元与三次元的距离,那些平面上的角色变得栩栩如生。次元壁渐渐被打破,你的纸片人老婆(老公)从屏幕里走出来,形象更加逼真,还可私人定制哦。
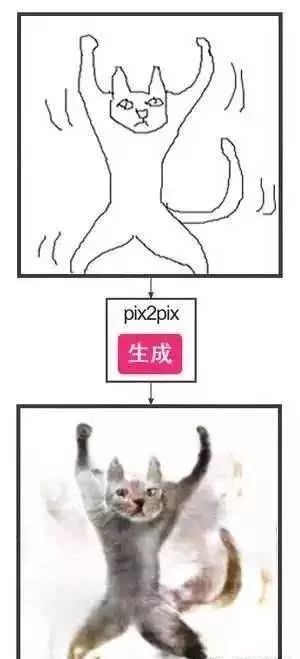
这就需要我们理解生成对抗网络(GANs)的工作模式,并掌握如何创造和构建此类应用程序。
本文将结合生成对抗网络(GANs)的工作模式,通过相关的动漫人物数据库去手把手教你如何创建属于自己的动漫人物,圆梦二次元。

前提概要
这里提到的生成对抗网络中(GAN)的深度卷积生成对抗网络(DC-GAN)不仅广泛应用于人脸生成或者新的动漫人物,还适用于时尚风格的创建,常规内容的创建,同时也用于数据扩增的目的。
生成对抗网络很可能会改变电子游戏和特效的生成方式。这种方法可以根据需要创建逼真的纹理或人物。
Github Repository完整代码传送门:https://github.com/MLWhiz/GAN_Project
Google Colab传送门:https://colab.research.google.com/drive/1Mxbfn0BUW4BlgEPc-minaE_M0_PaYIIX

了解深度卷积生成对抗网络架构
在开始编码之前,对理论深入研究是很有帮助的。
深度卷积生成对抗网络的主要思想来自于亚历克·雷德福,卢克·梅兹,和索米斯·锦塔勒在2016年发表的论文《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》。
论文传送门:https://arxiv.org/pdf/1511.06434.pdf
前方高能,请注意。
生成对抗网络生成伪图像的简介

通常,生成对抗网络会使用两个对抗的神经网络来训练计算机去很好地掌握数据集的本质,从而生成令人信服的赝品。
大家可以把这个看作是两个系统,其中一个利用神经网络去生成赝品(生成器),另一个是利用神经网络(鉴别器)对图像是否是赝品进行分类。
由于生成器和鉴别器网络都在重复各自的工作,网站最终会在各自的任务下更好地工作。
把这个想象的和击剑一样简单。两个新手开始对练模式,一段时候之后,两个人的剑术都会有所提升。
或者可以把生成器想象成一个强盗,把鉴别器想象成一个警察。经过多次盗窃之后,在一个理想的世界里,强盗变得更擅长偷窃,而警察变得更擅长抓强盗。
这些神经网络的损失主要是由其他网络的表现决定的:
· 鉴别器网络的损耗是生成器网络质量的函数——如果鉴别器被生成器的伪图像所欺骗那它的耗损将会很高。
· 生成器网络的损耗是鉴别器网络质量的一个函数——生成器的耗损将会很高如果它无法欺骗鉴别器。
在训练阶段,技术人员会依次训练鉴别器和生成器网络去提高鉴别器和生成器的相关性能。
目标是以权重而结束,帮助生成器生成逼真的图像。最后,人们可以利用生成神经网络从随机噪声中生成伪图像。
生成器架构
生成对抗网络面临的主要问题之一是训练的不稳定性。因此,人们不得不想出一款生成器架构来解决这个问题同时能带来稳定的训练。

上图选自一篇论文,解释了深度卷积生成对抗网络架构,可能看上去会让人比较困惑。
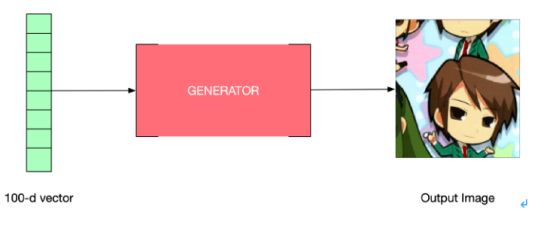
本质上,可以把一个生成器神经网络想象成一个黑匣子,向它输入一个100大小的正常生成的数字作为向量,然后它会给出一个图像:
如何得到这个架构?
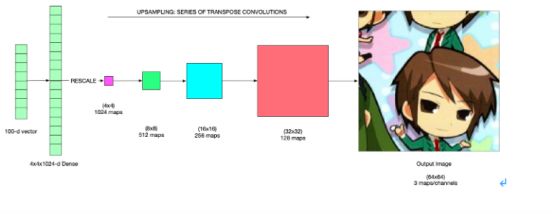
在如下架构中,使用一个大小为4*4*1024大小的致密层去创造100-d致密向量。然后,用1024个过滤器将这个密集向量重塑成4x4的图像大小,如下图所示:
大家现在不需要担心任何权重的问题,因为网络本身在训练时会掌握这些问题。
一旦有了1024张4x4的地图,可以使用一系列的转置卷积来进行上采样,在每次操作之后,图像的大小翻倍并且地图的数量减半。在最后一步中,虽然没有将地图的数量减半,但是需要减少到3个通道/映射只针对每个分量配置(RGB)通道,因为我们需要3个通道来输出图像。
什么是转置卷积?
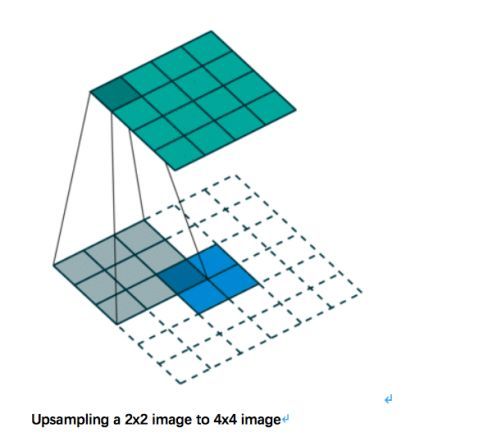
用最简单的术语来说,转置卷积提供了一种向上采样图像的方法。当在卷积操作中,如果尝试从一个4*4的图像中得到一个2*2图像,在转置卷积中,从2*2到4*4进行卷积,如下图所示:
那么,卷积神经网络(CNN)中,上池化(Un-pooling)在输入特征图进行向上采样中的应用日趋广泛。为什么不使用上池化呢?
这是因为上池化不涉及任何学习。然而,转置卷积是可学习的,这就是为什么更推荐转置卷积而不是上池化的原因。它们的参数可以通过生成器学习。
鉴别器架构
现在,对于生成器的架构已经有所了解,而鉴别器就像一个黑匣子。
在实际应用中,在最后,它包含一系列的卷积层和一个稠密层,用来预测图像是否为伪图像,如下图所示:

将图像作为输入,并且预测它是否是真的/假的。每一个图像都永远可以进行卷积操作。
数据预处理和可视化
第一件事就是查看数据集中的一些图像。下面是一些语言指令用于可视化数据集中的一些图像:
filenames = glob.glob('animeface-character-dataset/*/*.pn*')
plt.figure(figsize=(10, 8))
for i in range(5):
img = plt.imread(filenames[i], 0)
plt.subplot(4, 5, i+1)
plt.imshow(img)
plt.title(img.shape)
plt.xticks([])
plt.yticks([])
plt.tight_layout()
plt.show()
相关结果输出如下:

大家可以清楚看到图像的尺寸和图像本身。
在继续接下来的训练之前,在这种特别的情况下,需要将图像预处理为64*64*3的标准大小。
在使用它去训练生成对抗网络之前,规范图像的像素也是需要的一个步骤。可以看到这个代码,它的注解十分详细。
# A function to normalize image pixels.
def norm_img(img):
'''A function to Normalize Images.
Input:
img : Original image as numpy array.
Output: Normailized Image as numpy array
'''
img = (img / 127.5) - 1
return img
def denorm_img(img):
'''A function to Denormailze, i.e. recreate image from normalized image
Input:
img : Normalized image as numpy array.
Output: Original Image as numpy array
'''
img = (img + 1) * 127.5
return img.astype(np.uint8)
def sample_from_dataset(batch_size, image_shape, data_dir=None):
'''Create a batch of image samples by sampling random images from a data directory.
Resizes the image using image_shape and normalize the images.
Input:
batch_size : Sample size required
image_size : Size that Image should be resized to
data_dir : Path of directory where training images are placed.
Output:
sample : batch of processed images
'''
sample_dim = (batch_size,) + image_shape
sample = np.empty(sample_dim, dtype=np.float32)
all_data_dirlist = list(glob.glob(data_dir))
sample_imgs_paths = np.random.choice(all_data_dirlist,batch_size)
for index,img_filename in enumerate(sample_imgs_paths):
image = Image.open(img_filename)
image = image.resize(image_shape[:-1])
image = image.convert('RGB')
image = np.asarray(image)
image = norm_img(image)
sample[index,...] = image
return sample
先前的定义函数将会在代码的训练部分中被使用。
实现深度卷积生成对抗网络(DCGAN)
这部分是关于定义深度卷积生成对抗网络的,将定义人们的噪声发生器功能,生成器架构和鉴别器架构。
为生成器生成噪声向量

下面的代码块是一个为生成器创建一个预定义长度的有用函数。它通过使用生成器架构将产生人们想要转换为图像的噪音。使用一个正态分布去生成噪音向量:

def gen_noise(batch_size, noise_shape):
''' Generates a numpy vector sampled from normal distribution of shape (batch_size,noise_shape)
Input:
batch_size : size of batch
noise_shape: shape of noise vector, normally kept as 100
Output:a numpy vector sampled from normal distribution of shape (batch_size,noise_shape)
'''
return np.random.normal(0, 1, size=(batch_size,)+noise_shape)
生成器架构
生成器是生成对抗网络中的关键部分。
通过添加一些转置卷积层来创建一个生成器,以便对图像中的噪声向量进行上采样。
这个生成器架构与原始的深度卷积生成对抗网络论文中给出的并不相同。
需要做一些架构上的改变来更好地拟合数据,所以在中间添加了一个卷积层,并从生成器架构中清除了所有的密集层,使它达到完全卷积的效果。
笔者还使用了许多动量为0.5的Batch norm层并激活ReLU漏洞。同时使用β= 0.5的亚当优化器。下面的代码块是用来创建生成器的函数:
def get_gen_normal(noise_shape):
''' This function takes as input shape of the noise vector and creates the Keras generator architecture.
'''
kernel_init = 'glorot_uniform'
gen_input = Input(shape = noise_shape)
# Transpose 2D conv layer 1.
generator = Conv2DTranspose(filters = 512, kernel_size = (4,4), strides = (1,1), padding = "valid", data_format = "channels_last", kernel_initializer = kernel_init)(gen_input)
generator = BatchNormalization(momentum = 0.5)(generator)
generator = LeakyReLU(0.2)(generator)
# Transpose 2D conv layer 2.
generator = Conv2DTranspose(filters = 256, kernel_size = (4,4), strides = (2,2), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(generator)
generator = BatchNormalization(momentum = 0.5)(generator)
generator = LeakyReLU(0.2)(generator)
# Transpose 2D conv layer 3.
generator = Conv2DTranspose(filters = 128, kernel_size = (4,4), strides = (2,2), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(generator)
generator = BatchNormalization(momentum = 0.5)(generator)
generator = LeakyReLU(0.2)(generator)
# Transpose 2D conv layer 4.
generator = Conv2DTranspose(filters = 64, kernel_size = (4,4), strides = (2,2), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(generator)
generator = BatchNormalization(momentum = 0.5)(generator)
generator = LeakyReLU(0.2)(generator)
# conv 2D layer 1.
generator = Conv2D(filters = 64, kernel_size = (3,3), strides = (1,1), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(generator)
generator = BatchNormalization(momentum = 0.5)(generator)
generator = LeakyReLU(0.2)(generator)
# Final Transpose 2D conv layer 5 to generate final image. Filter size 3 for 3 image channel
generator = Conv2DTranspose(filters = 3, kernel_size = (4,4), strides = (2,2), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(generator)
# Tanh activation to get final normalized image
generator = Activation('tanh')(generator)
# defining the optimizer and compiling the generator model.
gen_opt = Adam(lr=0.00015, beta_1=0.5)
generator_model = Model(input = gen_input, output = generator)
generator_model.compile(loss='binary_crossentropy', optimizer=gen_opt, metrics=['accuracy'])
generator_model.summary()
return generator_model
绘制出最终生成器模型:
plot_model(generator, to_file='gen_plot.png', show_shapes=True, show_layer_names=True)
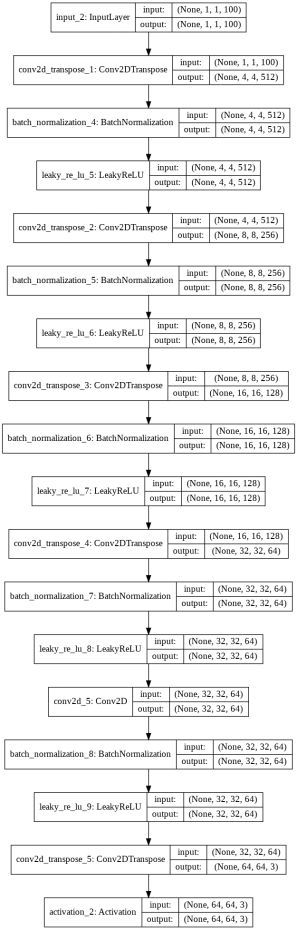
鉴别器架构
最后,在鉴别器架构中使用一系列卷积层和一层致密层用来预测图片是否有虚假或不存的现象。
def get_disc_normal(image_shape=(64,64,3)):
dropout_prob = 0.4
kernel_init = 'glorot_uniform'
dis_input = Input(shape = image_shape)
# Conv layer 1:
discriminator = Conv2D(filters = 64, kernel_size = (4,4), strides = (2,2), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(dis_input)
discriminator = LeakyReLU(0.2)(discriminator)
# Conv layer 2:
discriminator = Conv2D(filters = 128, kernel_size = (4,4), strides = (2,2), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(discriminator)
discriminator = BatchNormalization(momentum = 0.5)(discriminator)
discriminator = LeakyReLU(0.2)(discriminator)
# Conv layer 3:
discriminator = Conv2D(filters = 256, kernel_size = (4,4), strides = (2,2), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(discriminator)
discriminator = BatchNormalization(momentum = 0.5)(discriminator)
discriminator = LeakyReLU(0.2)(discriminator)
# Conv layer 4:
discriminator = Conv2D(filters = 512, kernel_size = (4,4), strides = (2,2), padding = "same", data_format = "channels_last", kernel_initializer = kernel_init)(discriminator)
discriminator = BatchNormalization(momentum = 0.5)(discriminator)
discriminator = LeakyReLU(0.2)(discriminator)#discriminator = MaxPooling2D(pool_size=(2, 2))(discriminator)
# Flatten
discriminator = Flatten()(discriminator)
# Dense Layer
discriminator = Dense(1)(discriminator)
# Sigmoid Activation
discriminator = Activation('sigmoid')(discriminator)
# Optimizer and Compiling model
dis_opt = Adam(lr=0.0002, beta_1=0.5)
discriminator_model = Model(input = dis_input, output = discriminator)
discriminator_model.compile(loss='binary_crossentropy', optimizer=dis_opt, metrics=['accuracy'])
discriminator_model.summary()
return discriminator_model
这是鉴别器的架构:
plot_model(discriminator, to_file='dis_plot.png', show_shapes=True, show_layer_names=True)

鉴别器架构
训练阶段

理解在生成对抗网络中训练的运作过程是极其重要的。当然也有可能很有趣。
通过使用之前章节中的函数定义开始创造鉴别器和发生器:
discriminator = get_disc_normal(image_shape)generator = get_gen_normal(noise_shape)
发生器和鉴别器随之结合起来创造最终的生成对抗网络。
discriminator.trainable = False
# Optimizer for the GAN
opt = Adam(lr=0.00015, beta_1=0.5) #same as generator
# Input to the generator
gen_inp = Input(shape=noise_shape)
GAN_inp = generator(gen_inp)
GAN_opt = discriminator(GAN_inp)
# Final GAN
gan = Model(input = gen_inp, output = GAN_opt)
gan.compile(loss = 'binary_crossentropy', optimizer = opt, metrics=['accuracy'])
plot_model(gan, to_file='gan_plot.png', show_shapes=True,
show_layer_names=True)
这是整个生成对抗网络的的架构:

训练循环
这是需要大家明白目前创造的区块如何集合并共同运作成一体的主要区域。
# Use a fixed noise vector to see how the GAN Images transition through time on a fixed noise.
fixed_noise = gen_noise(16,noise_shape)
# To keep Track of losses
avg_disc_fake_loss = []
avg_disc_real_loss = []
avg_GAN_loss = []
# We will run for num_steps iterations
for step in range(num_steps):
tot_step = step
print("Begin step: ", tot_step)
# to keep track of time per step
step_begin_time = time.time()
# sample a batch of normalized images from the dataset
real_data_X = sample_from_dataset(batch_size, image_shape, data_dir=data_dir)
# Genearate noise to send as input to the generator
noise = gen_noise(batch_size,noise_shape)
# Use generator to create(predict) images
fake_data_X = generator.predict(noise)
# Save predicted images from the generator every 10th step
if (tot_step % 100) == 0:
step_num = str(tot_step).zfill(4)
save_img_batch(fake_data_X,img_save_dir+step_num+"_image.png")
# Create the labels for real and fake data. We don't give exact ones and zeros but add a small amount of noise. This is an important GAN training trick
real_data_Y = np.ones(batch_size) - np.random.random_sample(batch_size)*0.2
fake_data_Y = np.random.random_sample(batch_size)*0.2
# train the discriminator using data and labels
discriminator.trainable = True
generator.trainable = False
# Training Discriminator seperately on real data
dis_metrics_real = discriminator.train_on_batch(real_data_X,real_data_Y)
# training Discriminator seperately on fake data
dis_metrics_fake = discriminator.train_on_batch(fake_data_X,fake_data_Y)
print("Disc: real loss: %f fake loss: %f" % (dis_metrics_real[0], dis_metrics_fake[0]))
# Save the losses to plot later
avg_disc_fake_loss.append(dis_metrics_fake[0])
avg_disc_real_loss.append(dis_metrics_real[0])
# Train the generator using a random vector of noise and its labels (1's with noise)
generator.trainable = True
discriminator.trainable = False
GAN_X = gen_noise(batch_size,noise_shape)
GAN_Y = real_data_Y
gan_metrics = gan.train_on_batch(GAN_X,GAN_Y)
print("GAN loss: %f" % (gan_metrics[0]))
# Log results by opening a file in append mode
text_file = open(log_dir+"\\training_log.txt", "a")
text_file.write("Step: %d Disc: real loss: %f fake loss: %f GAN loss: %f\n" % (tot_step, dis_metrics_real[0], dis_metrics_fake[0],gan_metrics[0]))
text_file.close()
# save GAN loss to plot later
avg_GAN_loss.append(gan_metrics[0])
end_time = time.time()
diff_time = int(end_time - step_begin_time)
print("Step %d completed. Time took: %s secs." % (tot_step, diff_time))
# save model at every 500 steps
if ((tot_step+1) % 500) == 0:
print("-----------------------------------------------------------------")
print("Average Disc_fake loss: %f" % (np.mean(avg_disc_fake_loss)))
print("Average Disc_real loss: %f" % (np.mean(avg_disc_real_loss)))
print("Average GAN loss: %f" % (np.mean(avg_GAN_loss)))
print("-----------------------------------------------------------------")
discriminator.trainable = False
generator.trainable = False
# predict on fixed_noise
fixed_noise_generate = generator.predict(noise)
step_num = str(tot_step).zfill(4)
save_img_batch(fixed_noise_generate,img_save_dir+step_num+"fixed_image.png")
generator.save(save_model_dir+str(tot_step)+"_GENERATOR_weights_and_arch.hdf5")
discriminator.save(save_model_dir+str(tot_step)+"_DISCRIMINATOR_weights_and_arch.hdf5")
不必担心,接下来会尽量将以上代码一步步分解开来。在每一个训练迭代中的主要步骤有:
第一步:从数据集目录中采集一批规范化的图像样本。
# Use a fixed noise vector to see how the GAN Images transition through time on a fixed noise.
fixed_noise = gen_noise(16,noise_shape)
# To keep Track of losses
avg_disc_fake_loss = []
avg_disc_real_loss = []
avg_GAN_loss = []
# We will run for num_steps iterations
for step in range(num_steps):
tot_step = step
print("Begin step: ", tot_step)
# to keep track of time per step
step_begin_time = time.time()
# sample a batch of normalized images from the dataset
real_data_X = sample_from_dataset(batch_size, image_shape, data_dir=data_dir)
第二步:生成噪声以输入到发生器中。
# Generate noise to send as input to the generator
noise = gen_noise(batch_size,noise_shape)
第三步:通过使用在使用生成器时的随机噪音生成图像。
# Use generator to create(predict) images
fake_data_X = generator.predict(noise)
# Save predicted images from the generator every 100th step
if (tot_step % 100) == 0:
step_num = str(tot_step).zfill(4)
save_img_batch(fake_data_X,img_save_dir+step_num+"_image.png")
第四步:使用生成器图像(伪图像)和真正归一化处理的图像(真实图像)以及其噪声标签训练鉴别器。
# Create the labels for real and fake data. We don't give exact ones and zeros but add a small amount of noise. This is an important GAN training trick
real_data_Y = np.ones(batch_size) - np.random.random_sample(batch_size)*0.2
fake_data_Y = np.random.random_sample(batch_size)*0.2
# train the discriminator using data and labels
discriminator.trainable = True
generator.trainable = False
# Training Discriminator seperately on real data
dis_metrics_real = discriminator.train_on_batch(real_data_X,real_data_Y)
# training Discriminator seperately on fake data dis_metrics_fake = discriminator.train_on_batch(fake_data_X,fake_data_Y) print("Disc: real loss: %f fake loss: %f" % (dis_metrics_real[0], dis_metrics_fake[0]))
# Save the losses to plot later
avg_disc_fake_loss.append(dis_metrics_fake[0])
avg_disc_real_loss.append(dis_metrics_real[0])
第五步:在保持鉴别器不可训练的状态下以噪声为X,以1’s(噪声的)为Y,训练生成对抗网络。
# Train the generator using a random vector of noise and its labels (1's with noise)
generator.trainable = True
discriminator.trainable = False
GAN_X = gen_noise(batch_size,noise_shape)
GAN_Y = real_data_Y
gan_metrics = gan.train_on_batch(GAN_X,GAN_Y)
print("GAN loss: %f" % (gan_metrics[0]))
通过循环重复步骤直至获得优秀的鉴别器和生成器。
成果显示
最终输出图像即如下所示。正如所见,生成对抗网络能为内容编辑的朋友们生成非常棒的图像。
对个人爱好来说这些图像也许略显粗糙,但对研究生成对抗网络来说,这个项目是个开始。

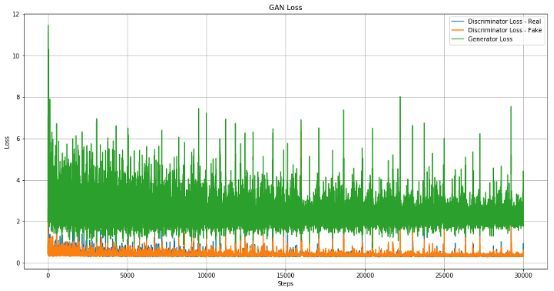
训练期间的损失
这是关于损失的图表。如图所示,生成对抗网络的损失在一个平均下降的趋势,并且随着步骤的增加,方差也在下降。为了得到更好的结果甚至可能需要更多的迭代训练。
每1500步生成的图像
在Colab中可以见到输出和运作中的代码:
# Generating GIF from PNGs
import imageio
# create a list of PNGs
generated_images = [img_save_dir+str(x).zfill(4)+"_image.png" for x in range(0,num_steps,100)]
images = []
for filename in generated_images:
images.append(imageio.imread(filename))
imageio.mimsave(img_save_dir+'movie.gif', images)
from IPython.display import Image
with open(img_save_dir+'movie.gif','rb') as f:
display(Image(data=f.read(), format='png'))
以下给出的代码是在不同训练步骤中用来生成一些图像的代码。正如所见,随着步骤数量的增加,图像质量也越来越好。
# create a list of 20 PNGs to show
generated_images = [img_save_dir+str(x).zfill(4)+"fixed_image.png" for x in range(0,num_steps,1500)]
print("Displaying generated images")
# You might need to change grid size and figure size here according to num images.
plt.figure(figsize=(16,20))
gs1 = gridspec.GridSpec(5, 4)
gs1.update(wspace=0, hspace=0)
for i,image in enumerate(generated_images):
ax1 = plt.subplot(gs1[i])
ax1.set_aspect('equal')
step = image.split("fixed")[0]
image = Image.open(image)
fig = plt.imshow(image)
# you might need to change some params here
fig = plt.text(20,47,"Step: "+step,bbox=dict(facecolor='red', alpha=0.5),fontsize=12)
plt.axis('off')
fig.axes.get_xaxis().set_visible(False)
fig.axes.get_yaxis().set_visible(False)
plt.tight_layout()
plt.savefig("GENERATEDimage.png",bbox_inches='tight',pad_inches=0)
plt.show()
以下给出的是不同时间步骤中生成对抗网络的结果:

深度卷积层生成对抗网络不仅适用于生成人脸或新的动漫人物,还可以用作生成新的时尚风格,用于普通内容创建,有时也用于数据扩张。
如果大家手中握有训练数据,现在就可以行动起来,按需求创造并召唤自己的二次元老婆(老公)啦!


留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
编译组:陈曼芳、鲍歆祎
相关链接:
https://towardsdatascience.com/an-end-to-end-introduction-to-gans-bf253f1fa52f
如需转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你