hadoop跑第一个python wordcount程序
参考博客:https://www.cnblogs.com/kaituorensheng/p/3826114.html
https://blog.csdn.net/wangato/article/details/70173682
hadoop集群框架搭建完了,试了几次很稳定,但是这只是第一步,编程才是重要的,另外,虽然hadoop的教程大多数都是用java编写也很清晰,但是对我来说最大的问题就是:我不会闸瓦,于是,找了几篇python实现wordcount的博客试着做一下
一:首先是编写python 的 mapreduce代码:
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print "%s\t%s" % (word, 1)
此处采用的是标准输入输出,将其作为hadoop的接口。此段代码的作用是将文件分割成一个个的 1的形式,其中strip是删除头尾空白符。
写完之后要增加可执行权限(reducer.py也是)
chmod +x hadoop-0.20.2/test/code/mapper.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError: #count如果不是数字的话,直接忽略掉
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word: #不要忘记最后的输出
print "%s\t%s" % (current_word, current_count)
中间还要插入一个sort,对应该段代码中的:判断下一个单词是不是没变,没变数量就加一
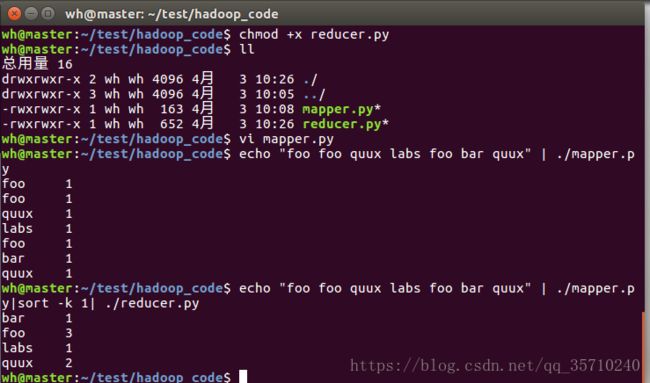
其中sort就是排序 选择项-k是按列排序 1是按照第一列排序
二 在hadoop上运行python代码 这个难度就增加点了
流程就是:
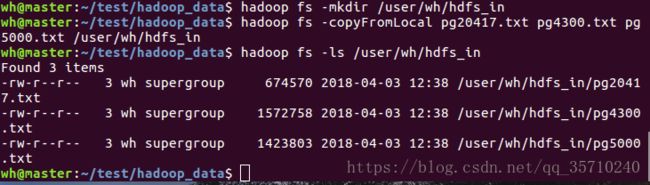
1.先上传文件(数据)到hdfs, 创建文件夹 复制
(查看文件,确认存在) 注意层级建立目录要用 -p
2 执行MapReduce.job
hadoop jar $STREAM \
-file /home/wh/test/hadoop_code/mapper.py \
-file /home/wh/test/hadoop_code/reducer.py \
-mapper /home/wh/test/hadoop_code/mapper.py \
-reducer /home/wh/test/hadoop_code/reducer.py \
-input /user/wh/hdfs_in \
-output /user/wh/output
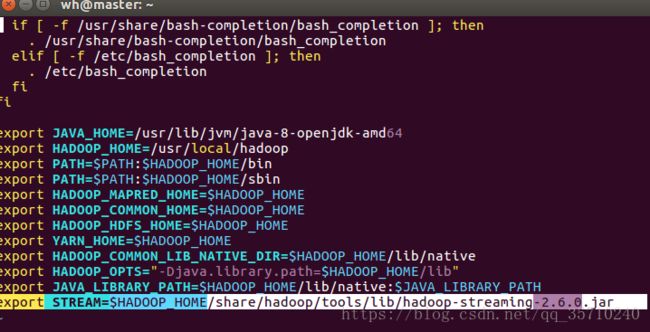
其中STEARM为hadoopde streaming,jar所在路径,加到了环境变量里面,过程为:
进入hadoop目录,查找.jar文件,编辑环境变量:
cd $HADOOP_HOMEfind ./ -name "*streaming*.jar"
vi ~/.bashrc
export STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.6.0.jar
加入之后就是执行的过程:-file:把所需要的mapper.py reducer.py路径加入框架, -mapper -reducer :告诉框架map和reducer程序是什么,-input :HDFS中的数据文件路径,-output
3 执行结果不能直接输出,要保存在某个文件中

4 查看结果(最后几幅图的顺序有颠倒,因为用CSDN编写博客太费劲......)
结果中出现类似乱码(比如说一大条长线)是因为文本中确实存在,而split的时候按照空格切割,所以就成了这样,另外yours yours! yours?这种也是按照3中不同word统计的。