Python Pandas库学习笔记(一)
笔记重点
- pd.read_excel()的使用
- 查看导入数据的属性:维度、列名、数据格式、唯一值、所有值、前/后x行等
- 数据清理代码:填充格式、数据类型更改、大小写转换、更改列名、数据替换等
- loc和iloc的使用
1. 文件路径的2种引用方法
path = 'C:/Users/111/Desktop/分析报告/sales.xlsx'
# 将文件路径的"\"改成"/"
或者
path = r'C:\Users\111\Desktop\分析报告\sales.xlsx'
# 在文件路径前面加上"r",可以对后面路径中的"\"进行转义
2. 读取excel中指定位置的sheet
df = pd.read_excel(path,sheet_name=1)
- 如果省略sheet_name参数,则默认读取第一个sheet,也就是sheet_name=0;
- 也可以直接使用sheet表名来引用,如,第2个sheet名字为"order",则sheet_name=1等同于sheet_name=“order”
更多pd.read_excel( )里的参数细节参见 pd.read_excel( )
以下是参考https://www.cnblogs.com/wobujiaonaoxin/articles/11386046.html 的步骤尝试的pandas一些函数的用法记录
一、导入数据的属性查看函数
① df.shape维度查看
![]()
表示该数据为16598行*12列
② df.info()数据表基本信息查看:行/列数、列名、空值、数据格式,占用内存
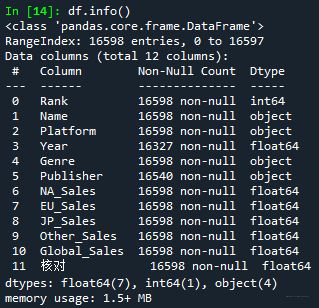
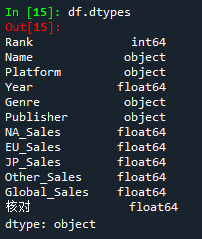
③ df.dtypes 数据格式查看
感觉不如使用上面的df.info()
④ df[ ].unique() 查看某一列的唯一值

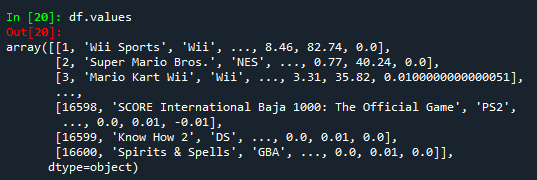
⑤ df.values 查看数据表的所有值
⑥ df.columns查看列名称

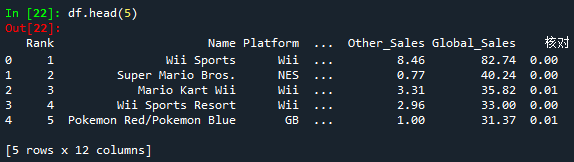
⑦ df.head()查看前x行数据
⑧ df.tail()查看最后x行数据
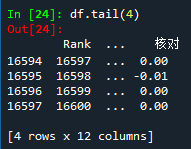
二、数据清理函数
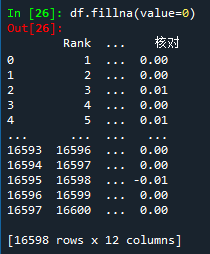
① df.fillna()填充空值数据
好像看不到效果?
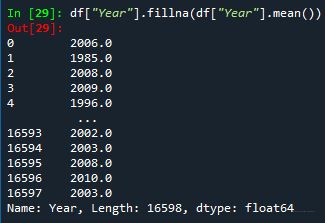
② 进阶填充空值
使用Year这列的均值对Year列的空值进行填充,还是看不到效果,怎么判断填充成功?
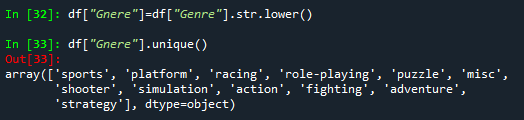
③ 大小写转换 df[“列名”].str.lower()
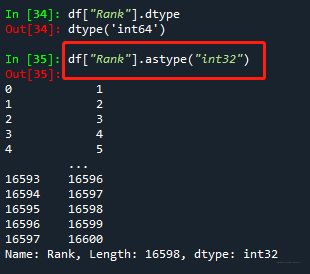
④ 更改数据格式 df[“列名”].astype(“数据格式”)
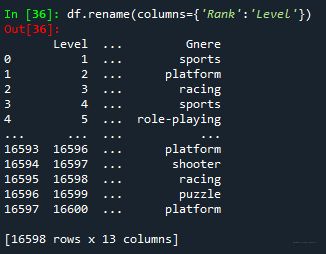
⑤ 更改列名 df.rename(columns={“原名称”:“新名称”})
⑥ 删除重复值
没有理解,是只删除该列对应的重复值,还是删除整行?表格数据不太好尝试,等后续再试试

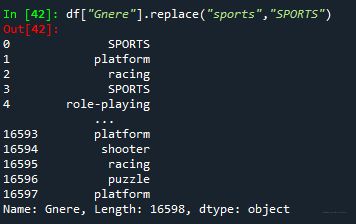
⑦ 数据替换df[“列名”].replace(“原值”,“新值”)
loc 和 iloc的使用
① loc
- df.loc[3],提取第4行的数据

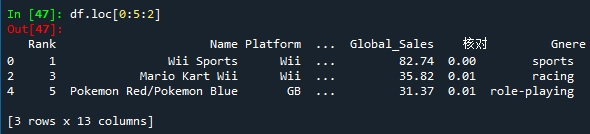
- df.loc[0:5:2],提取前5行,以2行为步长,也就是0,2,4行
- df.loc[0:5,1:3],报错,只能提取行,不能提取列

② iloc
- df.iloc[3],输出第4行数据
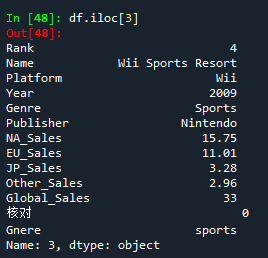
- df.iloc[0:5:2],提取前5行,以2行为步长。结果同df.loc[0:5:2]
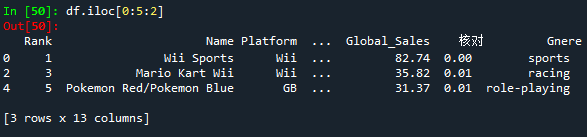
- df.iloc[0:5:2,1:3],提取前5行,以2行为步长切片,并提取第1:3列数据
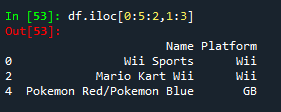
③ 按位置单独检索某几行数据
- df.loc[0,3,5,7] 或者 df.iloc[0,3,5,7],提取第0,3,5,7行数据,都报错


- df.iloc[[0,3,5,7],[1,2,3]],提取第0,3,5,7行,第1,2,3列数据,成功
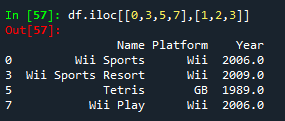
- df.loc[[0,3,5,7],[1,2,3]]报错,但是使用df.loc[[0,3,5,7],[“Platform”,“Year”]]是可以查询的,但是将loc改为iloc,也就是df.iloc[[0,3,5,7],[“Platform”,“Year”]]后就会报错
,有意思,搜了一下loc和iloc的区别,将总结写在最后面去
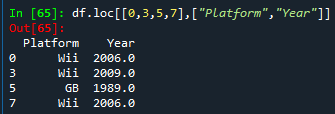
④ 提取符合包含某些条件的数据
- df.loc[df[‘Platform’].isin([‘Will’,‘GB’])],判断Platform里面是否包含“Will”和“GB”,并提取出来
是否可以嵌套函数,查询包含这些条件的前X项数据?或者继续嵌套,按照某一列排序后提取前X项?
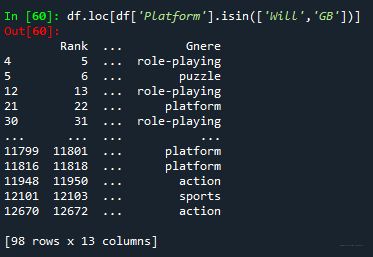
- 将上述函数用的loc更换为iloc后,报错,不能用iloc来提取限定条件的数据
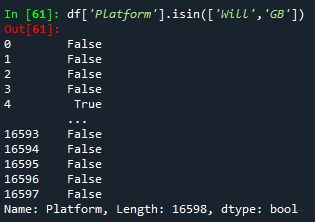
- 其中,单独使用loc里面嵌套的函数df[‘Platform’].isin([‘Will’,‘GB’]),判断“Will”和“GB”是否在“Platform"里,输出结果如下:
总结
loc是指location的意思,iloc中的i是指integer
- loc works on labels in the index
- iloc works on the positions in the index (so it only takes integers)
即: - loc是根据行/列标签来索引
- iloc是根据行/列号来索引
- loc或者iloc,切片方式和列表类型的切片方式类似