Python2字符串小结
1. 字符编码问题
- 字符的编码
计算机只能处理数字,这也就意味着当我们需要处理文本的时候,需要先把文本内容转换成数字。这一转换过程就是一个编码的过程。编码就相当于一个查字典的过程,我们要处理的文本就是我们不认识的字,然后需要通过查字典获知它的读音,这就是转换后的数字。这一过程就叫做编码,而我们所查的字典就叫做一个编码集。一般来说,我们最早接触的编码方式就是ASCII编码。这种方式是使用8个比特(bit)来编码一个字符的,这种方式最对只能编码256个字符。 - 字符与字符串
字符串是一组字符的集合,这倒是没什么可说的。不过,在C语言中,这个字符的定义还是和字符串有那点不同的,这个是由于编程语言本身机制所致。C语言就使用ASCII编码。
2. Unicode与UTF-8
根据上面所说的字符编码问题,就不难理解为什么会有多种编码方式的存在了。ASCII是好,但是它只能满足美国人哪。那怎么办?别的国家的人只好再造些字符集出来了。反正就是字典嘛,你能造,我也能造,这样一来,就有了各种字符编码集了。就汉字编码集来说,已经有好多种了。像GB2312、BIG5还有GBK等。这样以来倒是可以各国人民都用上自家语言上网了。但是彼此间交流怎么办?
就好像美国人有美国人韦氏词典,英国人有牛津词典,中国人有新华字典一样。这么多字典,彼此不同哪,这是一个问题。但是如果我们把所有这些字典内容都放到一本字典里去,这不就成了全世界通用的字典了么。前提是,这字典得足够大。这和Unicode的思想是一致的。
那么,大家就都用Unicode编码就是了,都能用嘛。但是问题就是Unicode要编码所有的字符,那么,这样一来就不是一个字符能解决的问题了。但是这就引发问题了,大家可不太乐意用比一个字节更多的存储空间去存储一个像’a’、’b’这样的字符了。这不明摆着浪费空间哪。这个时候,就该UTF-8排上用场了。UTF-8的原则是能省则省,比如,能用一个字节编码的字符,那就用一个。这样一来,就能省不少空间了。
3. 系统编码、文件编码与Python编码
操作系统是要有编码的,在 Linux 下获取系统编码结果如下:
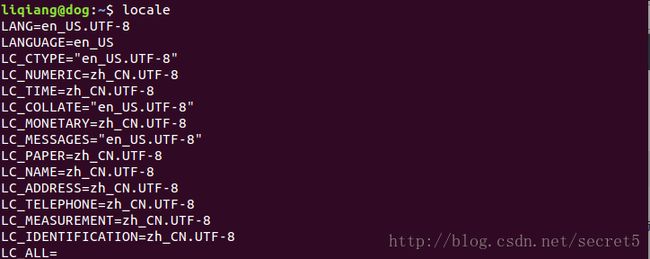
Linux 下默认使用UTF-8编码。比如:

也就是说在 Linux 环境下默认文件会使用 UTF-8 编码。那么,文件编码不言而喻了,就是该文件使用哪种编码方式。下面在 notepadqq 中使用不同的编码方式编码一个文件,查看其效果。
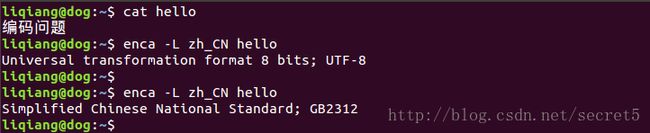
使用 encov 和 iconv 做编码转换的时候始终有乱码问题,就用了编辑器来做。可以看到,系统编码总是确定的,文件编码总是对应所选择的不同的编码方式。

这意味着 Python 解释器会用 ASCII 编码的方式去解读 Python 源文件。这样导致的直接问题就是,当在 Python 源文件中存在非 ASCII 字符时,会导致 Python 解释器无法识别,继而导致编码错误。
# coding.py
print '编码问题'运行结果如下:

所以,这个时候需要告诉 Python 解释器用 UTF-8 去读 Python 源文件。
# -*- coding: utf8 -*-
# coding.py
print '编码问题'![]()
4. Python2 字符串编码
Python2 中以 Unicode 为中间码,即所有的编解码都是以 Unicode 为媒介进行的。
1 #coding=utf-8
2
3 s='汉字'
4
5 if isinstance(s, unicode):
6 # 判断 s 是否是 unicode 字符
7 gs = s.encode('gb2312')
8 else:
9 gs = s.decode('utf8').encode('gb2312') 这个其实就是通过 unicode 进行的。下面再看一个例子:
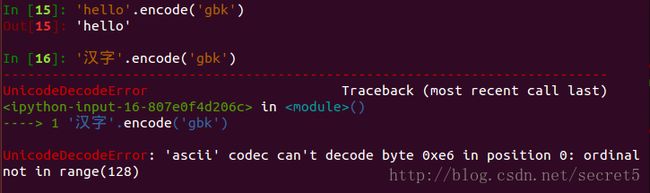
可以看到,’hello’ 字符串包含的都是 ascii 可编码字符,由于 python2 默认使用 ascii 编码,可以通过。而 ‘汉字’ 则是不可用 ascii 编码的字符,所以,这个时候 python 再去用 ascii 对其 decode 的时候,就出错了。其实,上面的这个 encode 方法的机制应该是先通过指定的编码方式(python2 默认 ascii)对目标字符串进行 decode 成 unicode 码,然后该 unicode 码作为中间代码接着 encode 成指定的编码方式。所以,在 ‘汉字’.encode(‘gbk’) 的过程中,python 首先使用 ascii 对 ‘汉字’ 进行 decode,当然这个时候是错误的。
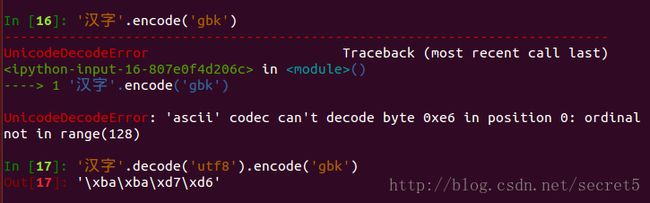
所以,python 字符串编解码的全部问题都在于这个中间码 —— Unicode码。
5. 字符串、Unicode字符串及原始字符串
python2 中有两类字符串,分别是 str 与 unicode。这两类字符串都派生自一个抽象类 basestring。

那么,对于一个 python 字符串来说,就有两种选择了。
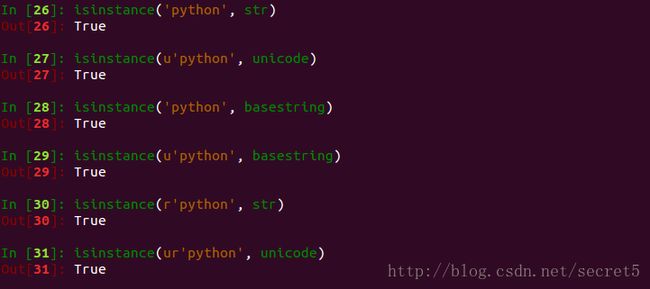
至于原始字符串(或者说是原生)则是一种转义了反斜线(‘\’)的字符串。

可以看到,在原始字符串中,反斜线已经被转义了。
6. 字符串两个方法
- 字符串转列表:
s = 'str,list,tuple,dict,set'
rs = s.split(',')- 列表转字符串:
s = '&'.join(['java', 'python', 'js'])