强化学习策略梯度梳理1 - REINFORCE(附代码)
策略梯度梳理 REINFORCE
- 策略梯度(PG)
- REINFORCE
- REINFORCE-baseline
- 对比DQN
- 总结
主要参考文献 Reinforcement Learning: An introduction,Sutton
主要参考课程 Intro to Reinforcement Learning,Bolei Zhou
相关文中代码 https://github.com/ThousandOfWind/RL-basic-alg.git
策略梯度(PG)
首先定义遵从一般约定
s ∈ S , a ∈ A ( s ) , θ ∈ R d ′ s \in \mathcal{S}, a \in \mathcal{A}(s), \boldsymbol{\theta} \in \mathbb{R}^{d'} s∈S,a∈A(s),θ∈Rd′
既然策略是 π ( a ∣ s , θ ) = Pr { A t = a ∣ S t = s , θ t = θ } \pi(a \mid s, \boldsymbol{\theta})=\operatorname{Pr}\left\{A_{t}=a \mid S_{t}=s, \boldsymbol{\theta}_{t}=\boldsymbol{\theta}\right\} π(a∣s,θ)=Pr{At=a∣St=s,θt=θ}
我们假设这个策略有表现 J ( θ ) J\left(\boldsymbol{\theta}\right) J(θ)
我们希望能够根据 J J J的梯度更新策略 θ t + 1 = θ t + α ∇ J ( θ t ) ^ \boldsymbol{\theta}_{t+1}=\boldsymbol{\theta}_{t}+\alpha \widehat{\nabla J\left(\boldsymbol{\theta}_{t}\right)} θt+1=θt+α∇J(θt)
方向导数本质上研究的是函数在某点处沿某特定方向上的变化率问题,梯度反映的是空间变量变化趋势的最大值和方向。方向导数与梯度在微分学中有重要的运用。
具体等我把相关算法搞定再去看高数
这样问题就变成了怎么把表现和策略联合起来
然后sutton就说了,既然如此
J ( θ ) ≐ v π θ ( s 0 ) J(\boldsymbol{\theta}) \doteq v_{\pi_{\boldsymbol{\theta}}}\left(s_{0}\right) J(θ)≐vπθ(s0)
v π ( s ) = [ ∑ a π ( a ∣ s ) q π ( s , a ) ] v_{\pi}(s)=\left[\sum_{a} \pi(a \mid s) q_{\pi}(s, a)\right] vπ(s)=[∑aπ(a∣s)qπ(s,a)]
⚠️用状态 s 0 s_0 s0的价值是因为他还假设了条件 γ = 1 \gamma = 1 γ=1,所以 v π θ ( s 0 ) v_{\pi_{\boldsymbol{\theta}}}\left(s_{0}\right) vπθ(s0) 实际上能够代表轨迹上的收益和
因此 J J J的梯度可以参考状态值的梯度
∇ v π ( s ) = ∇ [ ∑ a π ( a ∣ s ) q π ( s , a ) ] , for all s ∈ S = ∑ a [ ∇ π ( a ∣ s ) q π ( s , a ) + π ( a ∣ s ) ∇ q π ( s , a ) ] = ∑ a [ ∇ π ( a ∣ s ) q π ( s , a ) + π ( a ∣ s ) ∇ ∑ s ′ , r p ( s ′ , r ∣ s , a ) ( r + v π ( s ′ ) ) ] = ∑ a [ ∇ π ( a ∣ s ) q π ( s , a ) + π ( a ∣ s ) ∇ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] = ∑ a [ ∇ π ( a ∣ s ) q π ( s , a ) + π ( a ∣ s ) ∇ ∑ s ′ p ( s ′ ∣ s , a ) ( ∑ a ′ [ ∇ π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) + π ( a ′ ∣ s ′ ) ∇ ∑ s ′ ′ p ( s ′ ′ ∣ s ′ , a ′ ) v π ( s ′ ′ ) ] ) ] \begin{aligned} \nabla v_{\pi}(s) &=\nabla\left[\sum_{a} \pi(a \mid s) q_{\pi}(s, a)\right], \quad \text { for all } s \in \mathcal{S} \\ &=\sum_{a}\left[\nabla \pi(a \mid s) q_{\pi}(s, a)+\pi(a \mid s) \nabla q_{\pi}(s, a)\right] \\ &=\sum_{a}\left[\nabla \pi(a \mid s) q_{\pi}(s, a)+\pi(a \mid s) \nabla \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left(r+v_{\pi}\left(s^{\prime}\right)\right)\right]\\ &=\sum_{a}\left[\nabla \pi(a \mid s) q_{\pi}(s, a)+\pi(a \mid s) \nabla \sum_{s^{\prime} } p\left(s^{\prime} \mid s, a\right)v_{\pi}\left(s^{\prime}\right)\right]\\ &=\sum_{a}\left[\nabla \pi(a \mid s) q_{\pi}(s, a)+\pi(a \mid s) \nabla \sum_{s^{\prime} } p\left(s^{\prime} \mid s, a\right)\left(\sum_{a'}\left[\nabla \pi(a' \mid s') q_{\pi}(s', a')+\pi(a' \mid s') \nabla \sum_{s''} p\left(s'' \mid s', a'\right)v_{\pi}\left(s''\right)\right]\right)\right]\\ \end{aligned} ∇vπ(s)=∇[a∑π(a∣s)qπ(s,a)], for all s∈S=a∑[∇π(a∣s)qπ(s,a)+π(a∣s)∇qπ(s,a)]=a∑⎣⎡∇π(a∣s)qπ(s,a)+π(a∣s)∇s′,r∑p(s′,r∣s,a)(r+vπ(s′))⎦⎤=a∑[∇π(a∣s)qπ(s,a)+π(a∣s)∇s′∑p(s′∣s,a)vπ(s′)]=a∑[∇π(a∣s)qπ(s,a)+π(a∣s)∇s′∑p(s′∣s,a)(a′∑[∇π(a′∣s′)qπ(s′,a′)+π(a′∣s′)∇s′′∑p(s′′∣s′,a′)vπ(s′′)])]
然后接下这一步其实我没懂。。罪过。我看完这个立刻去学
= ∑ x ∈ S ∑ k = 0 ∞ Pr ( s → x , k , π ) ∑ a ∇ π ( a ∣ x ) q π ( x , a ) =\sum_{x \in \mathcal{S}} \sum_{k=0}^{\infty} \operatorname{Pr}(s \rightarrow x, k, \pi) \sum_{a} \nabla \pi(a \mid x) q_{\pi}(x, a) =x∈S∑k=0∑∞Pr(s→x,k,π)a∑∇π(a∣x)qπ(x,a)
anyway,
J ( θ ) ∝ ∑ s μ ( s ) ∑ a q π ( s , a ) ∇ π ( a ∣ s , θ ) J(\boldsymbol{\theta}) \propto \sum_{s} \mu(s) \sum_{a} q_{\pi}(s, a) \nabla \pi(a \mid s, \boldsymbol{\theta}) J(θ)∝s∑μ(s)a∑qπ(s,a)∇π(a∣s,θ)
符号 ∝ \propto ∝ 是“正比于”的意思,就很合理,策略梯度也因此有很好的收敛性保证
进一步,我们可以推
∑ s μ ( s ) ∑ a q π ( s , a ) ∇ π ( a ∣ s , θ ) = E π [ ∑ a q π ( S t , a ) ∇ π ( a ∣ S t , θ ) ] = E π [ ∑ a π ( a ∣ S t , θ ) q π ( S t , a ) ∇ π ( a ∣ S t , θ ) π ( a ∣ S t , θ ) ] = E π [ q π ( S t , A t ) ∇ ln ( π ( A t ∣ S t , θ ) ) ] \begin{aligned} \sum_{s} \mu(s) \sum_{a} q_{\pi}(s, a) \nabla \pi(a \mid s, \boldsymbol{\theta}) & =\mathbb{E}_{\pi}\left[\sum_{a} q_{\pi}\left(S_{t}, a\right) \nabla \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right)\right]\\ &=\mathbb{E}_{\pi}\left[\sum_{a} \pi(a \mid S_{t}, \boldsymbol{\theta}) q_{\pi}(S_{t}, a) \frac{\nabla \pi(a \mid S_{t}, \boldsymbol{\theta})} {\pi(a \mid S_{t}, \boldsymbol{\theta})}\right] \\ &= \mathbb{E}_{\pi}\left[q_{\pi}(S_{t},A_t) \nabla \operatorname{ln}(\pi(A_t \mid S_t, \boldsymbol{\theta}))\right] \end{aligned} s∑μ(s)a∑qπ(s,a)∇π(a∣s,θ)=Eπ[a∑qπ(St,a)∇π(a∣St,θ)]=Eπ[a∑π(a∣St,θ)qπ(St,a)π(a∣St,θ)∇π(a∣St,θ)]=Eπ[qπ(St,At)∇ln(π(At∣St,θ))]
所以虽然J值是我们用来评估策略表现的,但是很多时候,我们说 ln ( π ( a ∣ s , θ ) ) \operatorname{ln}(\pi(a \mid s, \boldsymbol{\theta})) ln(π(a∣s,θ))是score function
(我怀疑我又在胡说八道了。。。。
REINFORCE
如果用真实奖赏估计 v π ( s ) v_{\pi}(s) vπ(s),我们就得到了这个算法
他的核心思路是用MC方法估计 q π ( S t , A t ) q_{\pi}(S_{t},A_t) qπ(St,At)项
也就是说
J ( θ ) ∝ E π [ G ( S t , A t ) ∇ ln ( π ( A t ∣ S t , θ ) ) ] J(\boldsymbol{\theta}) \propto \mathbb{E}_{\pi}\left[G(S_{t},A_t) \nabla \operatorname{ln}(\pi(A_t \mid S_t, \boldsymbol{\theta}))\right] J(θ)∝Eπ[G(St,At)∇ln(π(At∣St,θ))]
突然意识到两年了我都没写过MC的代码,然后决定试试看
首先就是教科书里的伪代码

然后python实现是这个样
def get_action(self, observation, *arg):
obs = th.FloatTensor(observation)
pi = self.pi(obs=obs)
m = Categorical(pi)
action_index = m.sample()
self.log_pi_batch.append((m.log_prob(action_index)))
return int(action_index), pi
def learn(self, memory):
batch = memory.get_last_trajectory()
# build G_t
G = copy.deepcopy(batch['reward'][0])
for index in range(2, len(G)+1):
G[-index] += self.gamma * G[-index + 1]
G = th.FloatTensor(G)
log_pi = th.stack(self.log_pi_batch)
J = - (G * log_pi).mean()
self.writer.add_scalar('Loss/J', J.item(), self._episode )
self.optimiser.zero_grad()
J.backward()
grad_norm = th.nn.utils.clip_grad_norm_(self.params, 10)
self.optimiser.step()
self._episode += 1
但是但是,
我先试了一下小车爬坡效果很不行,参考了周老师的tutorial里推荐的源码: https://github.com/cuhkrlcourse/RLexample/blob/master/ policygradient/reinforce.py
用的环境是’CartPole-v1’,然而效果还是很糟糕。。。
这里贴贴一下结果
loss & score虽然说收敛了但是解很不好, 是我哪里写错了吗。。。
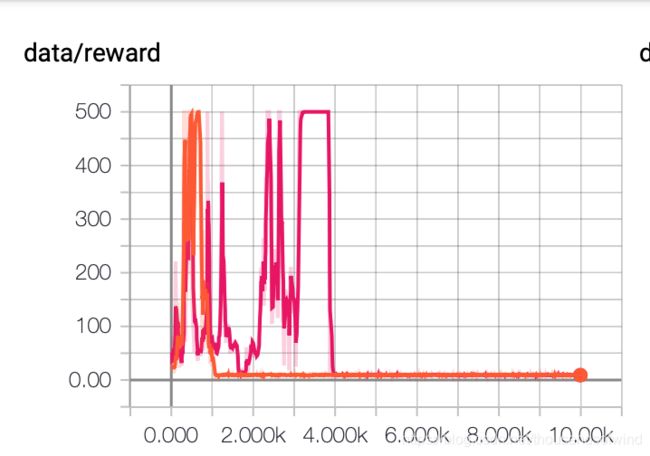
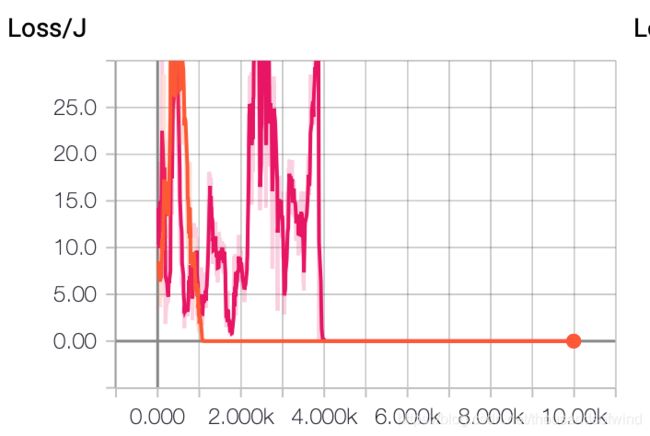
然后可视化了他的行动策略,红色和绿色分别是一个动作
,这样看的话它只有在做一个动作而已

REINFORCE-baseline
因为上文用的是
∇ J ( θ ) ∝ E π [ G ( S t , A t ) ∇ ln ( π ( A t ∣ S t , θ ) ) ] \nabla J(\boldsymbol{\theta}) \propto \mathbb{E}_{\pi}\left[G(S_{t},A_t) \nabla \operatorname{ln}(\pi(A_t \mid S_t, \boldsymbol{\theta}))\right] ∇J(θ)∝Eπ[G(St,At)∇ln(π(At∣St,θ))]
baseline的使用是因为 G ( S t , A t ) G(S_{t},A_t) G(St,At)的会带来很高的方差, 为了缓解这个问题我们考虑存在一个baseline 满足
∑ a b ( s ) ∇ π ( a ∣ s , θ ) = b ( s ) ∇ ∑ a π ( a ∣ s , θ ) = b ( s ) ∇ 1 = 0 \sum_{a} b(s) \nabla \pi(a \mid s, \boldsymbol{\theta})=b(s) \nabla \sum_{a} \pi(a \mid s, \boldsymbol{\theta})=b(s) \nabla 1=0 a∑b(s)∇π(a∣s,θ)=b(s)∇a∑π(a∣s,θ)=b(s)∇1=0
这样
∇ J ( θ ) ∝ ∑ s μ ( s ) ∑ a ( q π ( s , a ) − b ( s ) ) ∇ π ( a ∣ s , θ ) \nabla J(\boldsymbol{\theta}) \propto \sum_{s} \mu(s) \sum_{a}\left(q_{\pi}(s, a)-b(s)\right) \nabla \pi(a \mid s, \boldsymbol{\theta}) ∇J(θ)∝s∑μ(s)a∑(qπ(s,a)−b(s))∇π(a∣s,θ)
然后一般会用状态值作为baseline

def get_action(self, observation, *arg):
obs = th.FloatTensor(observation)
pi = self.pi(obs=obs)
m = Categorical(pi)
action_index = m.sample()
self.log_pi_batch.append(m.log_prob(action_index))
self.b_batch.append(self.B(obs=obs))
return int(action_index), pi
def learn(self, memory):
batch = memory.get_last_trajectory()
# build G_t
G = copy.deepcopy(batch['reward'][0])
reward = th.FloatTensor(batch['reward'][0])
for index in range(2, len(G) + 1):
G[-index] += self.gamma * G[-index + 1]
G = th.FloatTensor(G)
log_pi = th.stack(self.log_pi_batch)
b = th.stack(self.b_batch)
J = - ((G-b).detach() * log_pi).mean()
value_loss = F.smooth_l1_loss(b.squeeze(-1), reward).mean()
loss = J + value_loss
self.writer.add_scalar('Loss/J', J.item(), self._episode)
self.writer.add_scalar('Loss/B', value_loss.item(), self._episode)
self.writer.add_scalar('Loss/loss', loss.item(), self._episode)
self.optimiser.zero_grad()
loss.backward()
grad_norm = th.nn.utils.clip_grad_norm_(self.params, 10)
self.optimiser.step()
self._episode += 1
然而结果也很悲剧
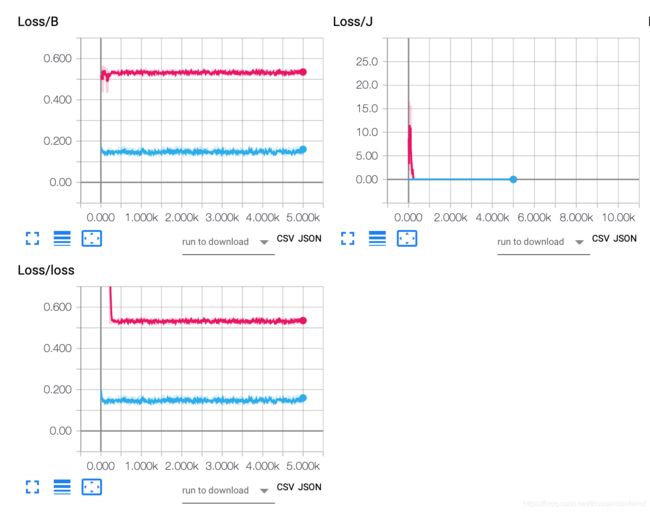
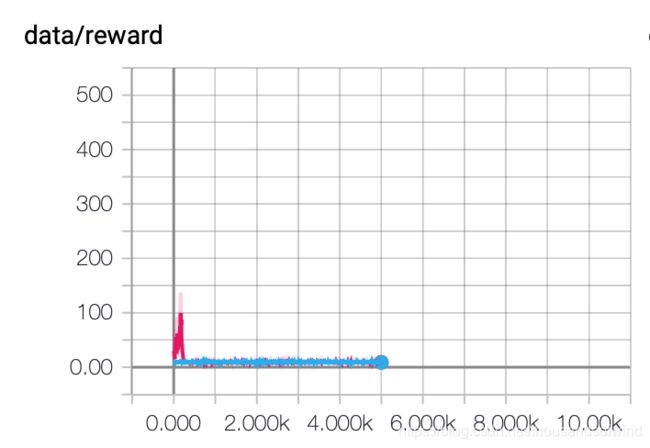

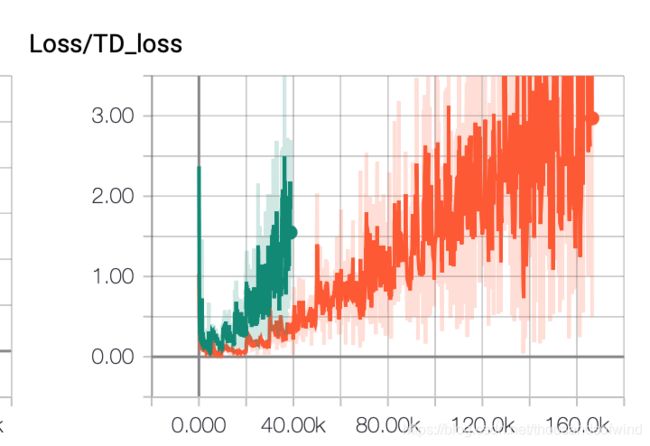
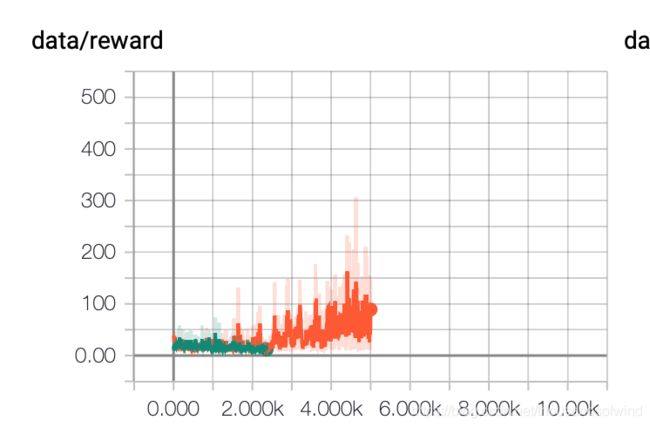
对比DQN
因为我很怀疑是不是我的代码有什么问题就决定对比一下dqn,虽然dqn发散,但是效果果然好很多,而且策略的颜色也是比较理想的那种

总结
onpolicy 果然收敛的很好然而效果不好
offpolicy 虽然不收敛但是又能看到效果
然而两个结果都很糟糕,
可能原因包括
- 可能我的参数不好
- 网络结构不够好,一般经验来看可能换rnn会好一些
- 我写的代码有问题。。。。等我找到原因会回来改改的