pyhton interpreter byterun和底层`code object`的简单了解
pyhton interpreter byterun和底层code object的简单了解
文章目录
- pyhton interpreter byterun和底层`code object`的简单了解
- python interpreter
- python interpreter
- stack 栈机器
- `byte code` 和 `code object`
- python - dis模块:
- frame 帧
- byterun
- 顺序分析
- main
- `run_python_...`
- `run_code_object`
- `VirtualMachine`
- `run_code`
- `make_frame`
- `run_frame`
- `dispatch()`
- `calll_function`
- 整体分析
- `VirtualMachine`
- frame
- function
- stack
- 最后
首先这是对于文章
这是一篇关于python虚拟机底层的一个文章
前部分是主要核心是500line那篇文章的笔记。
后部分主要是对于
byterun的源码分析。
主要参考文档:
500 Lines or Less: python interpreter written in python-原文 、500 Lines or Less: python interpreter – 翻译、实验楼也有一个相关的教程、一个相关的ppt
这几个都是基于原文 讲的差不多的东西。
主要的研究对象:
byterun-github
另外还有一些文章,关注的位置就和我们这个byterun不同了,想进一步了解的朋友可以看下:
python运行原理-淡水、python import 机制 – laike9m、python解释器和java虚拟机
python interpreter
python interpreter
这里是两个点:
- 什么是python interpreter:
我们在这里提到的python解释器,是指python执行代码最后的一步
- python 程序运行:
在解释器接手之前。python会执行:词法分析,语法分析, 编译。
然后将python的源代码生成 code object, 这里面就是python解释器可以识别的指令,然后解释器去解释(运行) 其中的指令。
另外Python的解释器是一个栈堆机器, 其底层使用的逻辑是用栈表示的,而我们普通的电脑底层是寄存器机器,使用的是数据存放在内存地址
这里说明:
- 编译 - compile
python尽管作为一个解释型语言,也存在编译的过程,只是相对于解释的部分占比更少一些。
- 解释器的定位
我们其实可以类比于c语言的过程,两者的源代码,先要形成底层机器可以识别的语言,这个
code object就相当于汇编, 而c编译为了可执行文件运行在机器上,就相当于code object运行在了我们的解释器上,其实个人感觉还是比较类似的过程,只不过解释器实现了一个类似虚拟机的的功能,也有点像java了,两者都是解释型语言。
其实这个所谓的解释器,和虚拟机,是一样的,只不过是两种语言的叫法不通,其定位是一致的。
同样的java虚拟机也是一个堆栈机器。
另外关于java虚拟机和python解释器, 在stack overflow中由一个 相关问题
stack 栈机器
我们的解释器是一个堆栈机器。而计算机是一个寄存器机器。
寄存器机器使用内存地址等保存数据, 运行时主要是使用寄存器去访问和操作各种地址,
堆栈机器的操作都是对堆栈的操作,而数据储存的问题上,pyhton就是在code object的结构中,
这里简单讲一些指令实现思路,详细的可以看后面dis方法的使用,并获得一些结构或语句对比观察,或是翻看相关的详细讲解。
这里简单讲述一个顺序结构, 加法的实现:
python 对于一个加法的实现, 比如: 4 + 8
首先将 4 压栈, 然后将 8 压栈, 然后将栈顶的两位弹出、相加、再将结果压栈,最后将结果弹出:
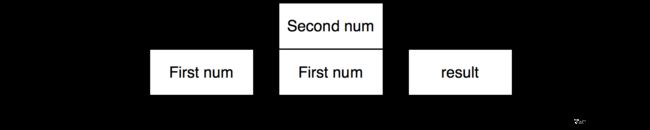
上述就是个简单的循环结构的栈机器运行,当我们运行判断和循环结构,
了解过汇编我们知道,一般汇编中的大部分循环结构其实都是一个往回跳的判断语句,判断结构就是判断和往后跳过一个代码块的跳转语句,所以两者的关键在于判断和跳转的实现。
在指令里, 使用一种类似于汇编中的比较配合跳转的思路,COMPARE_OP将栈顶两个数比较,并将对应的bool类型值压栈, POP_JUMP_IF_FALSE, 讲栈顶的值弹出,由这个值的真假决定是否跳转。
这里我们讲述的这个栈称为数据栈(data stack)。顾名思义。
另外还有 一种块栈(block stack)。 用于特定的控制流,比如循环、异常处理。
另外还有一个每次运行唯一的调用栈,用于保存函数调用信息,详情查看 关于帧-frame的部分。
byte code 和 code object
在pyhton运行的时候,会将源代码转化为code object, 其中的关键部分是 交由 解释器去运行的那一部分代码, 这就是byte code, 其他的部分都是一些解释器必须的数据变量等部分 , 就比如我们前面提到的4和8,
这里特别提到这个byte code是用Python语言转化为的、 python解释器可以运行的中间形态的代码,这类似于汇编和c的关系。
在另一个文档中看到对于byte code的解释:
the internal representation of python program in the interpreter .
python程序在解释器中的内部显示。
另外那些.pyc文件也是code object保存到硬盘中的表现,一般我们直接运行会编译然后运行,不会产生pyc文件,如果我们import 一个文件,则会将编译产生的code object保存,在下一次import就不需要重新编译,同时判定pyc和py文件是否一致是否需要重新编译,是通过检查时间戳。
关于import 的一些理解在这里可以看到:
python import 机制 – laike9m
而这个code object的结构可以独立的运行在解释器上,已经包含了所有源代码中的数据代码变量名等,则类似于我们一个完整程序,可以独立的运行在我们的机器上,
python - dis模块:
首先我们看下在python中对应的上述两个概念:
这是ipython中的,但是截图里面的
__code__会看不清
In [3]: def cond():
...: x = 1
...: y = 2
...: return x + y
...:
In [4]: cond.__code__
Out[4]: <code object cond at 0x7f037ebeb540, file "" , line 1>
In [5]: type(cond)
Out[5]: function
In [6]: type(cond.__code__)
Out[6]: code
In [7]: cond.__code__.co_code
Out[7]: b'd\x01}\x00d\x02}\x01|\x00|\x01\x17\x00S\x00'
In [8]: type(cond.__code__.co_code)
Out[8]: bytes
这里我们简述:
- 假设一个函数为
cond - 其对应的
code object, 是:cond.__code__ - 其对应的
byte code, 是:cond.__code__.co__code
然后使我们的dis模块:
import dis
In [12]: dis.dis(cond.__code__)
2 0 LOAD_CONST 1 (1)
2 STORE_FAST 0 (x)
3 4 LOAD_CONST 2 (2)
6 STORE_FAST 1 (y)
4 8 LOAD_FAST 0 (x)
10 LOAD_FAST 1 (y)
12 BINARY_ADD
14 RETURN_VALUE
In [13]: dis.dis(cond.__code__.co_code)
0 LOAD_CONST 1 (1)
2 STORE_FAST 0 (0)
4 LOAD_CONST 2 (2)
6 STORE_FAST 1 (1)
8 LOAD_FAST 0 (0)
10 LOAD_FAST 1 (1)
12 BINARY_ADD
14 RETURN_VALUE
In [15]: dis.opname[100]
Out[15]: 'LOAD_CONST'
dis是一个字节码的反汇编器
-
dis.dis()可以反汇编code object, 将字节码和相关信息以一种人类可读方式输出,对于每个字节码做出解释。其中我们直接
dis.dis(cond)和dis.dis(cond.__code__)是一致的,但是dis.dis(cond.__code__.co_code), 就不会包含一些变量名等信息,这这位置我们在关于两结构时提到过,关于code object和byte code 的区别。
-
dis.opname()可以返回指定的字节对应的字节码。
其实到这个位置我们就可以自己写一些语句来查看对应的字节码指令了。
frame 帧
我们已经可以大致的了解一个解释器对于函数得 运行,顺序的加减 条件的跳转循环等的实现,那么对于多个函数的调用, 我们要引入一个新的概念,帧, frame,
一个帧是一些信息集合和代码执行的上下文,frame在代码执行的时候可以动态的创建和销毁,每个frame都对应一次函数调用,并且只和对应的一个code object关联,切拥有自己的数据栈和块栈。
这个概念的确是很像我们的汇编中栈帧的定位,但是这个结构自身的性质也类似于堆的创建的感觉。
另外帧存在于程序内的调用栈(call stack)中。每次函数内调用一次函数就会在当前调用栈上压入所调用的函数的帧,在所调用函数返回后将该帧弹出。
在我们的python 程序运行报错时出现的
Traceback (most recent call last)就是在回溯调用栈的frame确定的错误位置。
另外函数返回值的传递,
当函数返回时,指令为RETURN_VALUE, 这个指令是将调用栈栈顶的frame的数据栈栈顶值弹出,然后讲frame弹出栈并丢弃整个frame, 然后讲这个值压入下一个新调用栈栈顶的frame数据栈中。
最后简图:
byterun
下面开始这个源码分析,在文初已经给出了github链接,直接clone可以。
主要的代码部分在byterun文件夹中,
文件结构:
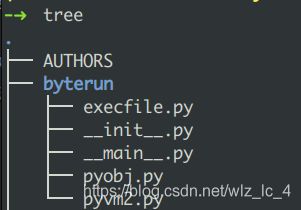
其中的虚拟机在文件pyvm2.py, 使用到的对象定义在pyobj.py, 这是最主要的两个文件。
顺序分析
main
在__init__.py中没有任何东西,我们直接看下__mian__.py文件:
import argparse
import logging
from . import execfile
....
if args.module:
run_fn = execfile.run_python_module
else:
run_fn = execfile.run_python_file
level = logging.DEBUG if args.verbose else logging.WARNING
logging.basicConfig(level=level)
argv = [args.prog] + args.args
run_fn(args.prog, argv)
略过中间一部分获取命令行参数等部分,我们看出主要的位置是在最后一行的run_fn(), 看到这个函数由参数而确定run_python_modul还是run_python_file两个函数去运行,
两个函数都是在execfile.py中导入的,我们去看下
run_python_...
在文件中后两个函数就是对应的两个了:
def run_python_module(modulename, args):
....
# Finally, hand the file off to run_python_file for execution.
run_python_file(pathname, args, package=packagename)
def run_python_file(filename, args, package=None):
# Create a module to serve as __main__
....
# Set sys.argv and the first path element properly.
....
try:
# Open the source file.
try:
source = source_file.read()
finally:
source_file.close()
....
# We have the source. `compile` still needs the last line to be clean,
# so make sure it is, then compile a code object from it.
if not source or source[-1] != '\n':
source += '\n'
code = compile(source, filename, "exec")
# Execute the source file.
exec_code_object(code, main_mod.__dict__)
finally:
# Restore the old __main__
....
# Restore the old argv and path
....
我们简单略过中间的部分,
大体上看下run_python_module()会讲参数等处理成一个文件的形式再去调用run_python_file(),
而run_python_file()会将环境参数环境变量进行处理,然后打开源文件,并使用compile()函数进行编译。 然后运行exec_code_object(),
run_code_object
这个函数也在这个文件内:
def exec_code_object(code, env):
vm = VirtualMachine()
vm.run_code(code, f_globals=env)
首先建立了一个虚拟机,然后进入对应的run_code()方法去运行, 这就到了我们的pyvm2.py文件
VirtualMachine
我们先看下VirtualMachine():
class VirtualMachine(object):
def __init__(self):
# The call stack of frames.
self.frames = []
# The current frame.
self.frame = None
self.return_value = None
self.last_exception = None
__init__()中的frames为调用栈,
在次之后设置一些简单的push pop 方法,
然后又是关于运行的make_frame()\ run_code()\ run_frame() \ call_function()几个方法,
再往后大片的以byte_..前缀的都是对应的字节码的操作,我们不再细究。
run_code
def run_code(self, code, f_globals=None, f_locals=None):
frame = self.make_frame(code, f_globals=f_globals, f_locals=f_locals)
val = self.run_frame(frame)
# Check some invariants
if self.frames: # pragma: no cover
raise VirtualMachineError("Frames left over!")
if self.frame and self.frame.stack: # pragma: no cover
raise VirtualMachineError("Data left on stack! %r" % self.frame.stack)
return val
函数显示新建了一个帧, 然后进入运行这个帧,这个地位应该是一个main函数的帧了。
后面部分是当这个main函数的帧运行结束后,返回, 并进行一个check查看错误之类的意思。
make_frame
这里的make_frame()函数创建的frame是一个对象。定义在pyobj.py中。
def make_frame(self, code, callargs={}, f_globals=None, f_locals=None):
log.info("make_frame: code=%r, callargs=%s" % (code, repper(callargs)))
if f_globals is not None:
f_globals = f_globals
if f_locals is None:
f_locals = f_globals
elif self.frames:
f_globals = self.frame.f_globals
f_locals = {}
else:
f_globals = f_locals = {
'__builtins__': __builtins__,
'__name__': '__main__',
'__doc__': None,
'__package__': None,
}
f_locals.update(callargs)
frame = Frame(code, f_globals, f_locals, self.frame)
return frame
run_frame
def run_frame(self, frame):
"""Run a frame until it returns (somehow).
Exceptions are raised, the return value is returned.
"""
self.push_frame(frame)
while True:
byteName, arguments, opoffset = self.parse_byte_and_args()
if log.isEnabledFor(logging.INFO):
self.log(byteName, arguments, opoffset)
# When unwinding the block stack, we need to keep track of why we
# are doing it.
why = self.dispatch(byteName, arguments)
if why == 'exception':
# TODO: ceval calls PyTraceBack_Here, not sure what that does.
pass
if why == 'reraise':
why = 'exception'
if why != 'yield':
while why and frame.block_stack:
# Deal with any block management we need to do.
why = self.manage_block_stack(why)
if why:
break
# TODO: handle generator exception state
self.pop_frame()
if why == 'exception':
six.reraise(*self.last_exception)
return self.return_value
这里我们看到在run_frame()中,先是运行了push_frame()将运行的这个帧压入到调用栈, 然后在while循环中持续的运行, 其中的变量why保存方法dispatch()的返回值,用于确定下一步将如何运行,如果返回值为不是几个特殊情况且不为空则跳出循环,运行pop_frame()这个方法,讲帧弹出调用栈,是为函数运行结束。
我们先贴一下两个frame相关的方法:代码比较简洁,意思也很简单,我们之前已经讲过的。
def push_frame(self, frame):
self.frames.append(frame)
self.frame = frame
def pop_frame(self):
self.frames.pop()
if self.frames:
self.frame = self.frames[-1]
else:
self.frame = None
dispatch()
下面看下这个dispatch()方法,应该是运行字节码的函数:
def dispatch(self, byteName, arguments):
""" Dispatch by bytename to the corresponding methods.
Exceptions are caught and set on the virtual machine."""
why = None
try:
if byteName.startswith('UNARY_'):
self.unaryOperator(byteName[6:])
elif byteName.startswith('BINARY_'):
self.binaryOperator(byteName[7:])
elif byteName.startswith('INPLACE_'):
self.inplaceOperator(byteName[8:])
elif 'SLICE+' in byteName:
self.sliceOperator(byteName)
else:
# dispatch
bytecode_fn = getattr(self, 'byte_%s' % byteName, None)
if not bytecode_fn: # pragma: no cover
raise VirtualMachineError(
"unknown bytecode type: %s" % byteName
)
why = bytecode_fn(*arguments)
except:
# deal with exceptions encountered while executing the op.
self.last_exception = sys.exc_info()[:2] + (None,)
log.exception("Caught exception during execution")
why = 'exception'
return why
首先一个try语句里面是是一个if语句块, 然后对应的except是处理异常,
这个if语句中判定的几个部分应该是对于这几个语句做出的优化,且这几个语句运行完后返回空,在run_frame中继续,看起来就是对于几个顺序结构的运算做出的优化之类的,
下面不属于这几类的时候,会调用gatattr来得到对应应该执行的方法,然后去执行,且我们可以看到使用格式'byte_%s' % byteName, 即我们前面提到的,以byte_..开头的方法,是对于字节码的实现。然后获得对应方法,运行并获取返回值,再返回到run_frame中,
那么下面还有一部,我们的函数调用:
calll_function
在之前的执行中我们并没有看到专门处理函数调用的位置,应该是在关于函数调用的字节码的位置,去翻看,果然:
def byte_CALL_FUNCTION(self, arg):
return self.call_function(arg, [], {})
def byte_CALL_FUNCTION_VAR(self, arg):
args = self.pop()
return self.call_function(arg, args, {})
def byte_CALL_FUNCTION_KW(self, arg):
kwargs = self.pop()
return self.call_function(arg, [], kwargs)
def byte_CALL_FUNCTION_VAR_KW(self, arg):
args, kwargs = self.popn(2)
return self.call_function(arg, args, kwargs)
看到根据不同的字节码指令会进行不同的操作,然后调用call_function运行:
def call_function(self, arg, args, kwargs):
lenKw, lenPos = divmod(arg, 256)
namedargs = {}
for i in range(lenKw):
key, val = self.popn(2)
namedargs[key] = val
namedargs.update(kwargs)
posargs = self.popn(lenPos)
posargs.extend(args)
func = self.pop()
frame = self.frame
if hasattr(func, 'im_func'):
# Methods get self as an implicit first parameter.
if func.im_self:
posargs.insert(0, func.im_self)
# The first parameter must be the correct type.
if not isinstance(posargs[0], func.im_class):
raise TypeError(
'unbound method %s() must be called with %s instance '
'as first argument (got %s instance instead)' % (
func.im_func.func_name,
func.im_class.__name__,
type(posargs[0]).__name__,
)
)
func = func.im_func
retval = func(*posargs, **namedargs)
self.push(retval)
这个函数来自于前面的一个byte_MAKE_FUNCTION()中定义出的,来源于对象Function, 在文件pyobj.py中,其中的一个方法:
def __call__(self, *args, **kwargs):
if PY2 and self.func_name in ["" , "" , "" ]:
# D'oh! http://bugs.python.org/issue19611 Py2 doesn't know how to
# inspect set comprehensions, dict comprehensions, or generator
# expressions properly. They are always functions of one argument,
# so just do the right thing.
assert len(args) == 1 and not kwargs, "Surprising comprehension!"
callargs = {".0": args[0]}
else:
callargs = inspect.getcallargs(self._func, *args, **kwargs)
frame = self._vm.make_frame(
self.func_code, callargs, self.func_globals, {}
)
CO_GENERATOR = 32 # flag for "this code uses yield"
if self.func_code.co_flags & CO_GENERATOR:
gen = Generator(frame, self._vm)
frame.generator = gen
retval = gen
else:
retval = self._vm.run_frame(frame)
return retval
我们可以看到前面make_frame()会生成一个关于这个函数的一个帧,
注意后面部分, 会由一个参数决定是讲函数先挂起,还是直接去运行,注意这个run_fra me(), 这里表示的是直接去运行这个函数的情况, 就将原本的帧挂起,运行这个帧,这里我们也可以看到之前提到的东西, 关于调用栈, 每次运行一个栈开始和结束时的push和pop,
整体分析
以上我们简单的了解了运行流程,以下是和原文一样,对于几个对象简单分析:
VirtualMachine
VirtulMachine是定义的虚拟机/解释器对象,每次byterun的运行都只会有一个实例产生,它拥有最高的控制,维护调用栈, 处理异常信息,并负责传递函数返回值,
唯一的一个入口位置就是run_code方法,这个方法创建第一个帧,并运行,此后解释器将会执行里面对应的字节码,并由此,开始处理数据,处理函数调用,返回的调用栈增长和收缩,传递函数返回值,
当建立的第一个帧运行结束返回时, 整个程序执行完毕。
整个这个对象都在文件
pyvm2.py中和自身虚拟机相关的是一个
__init__()定义 和run_code()一个入口方法的定义。
frame
这个对象是一些属性的梳理和设定,而并不会提供相对应的可运行的方法,
主要的属性包括,被编译后的code object, 命名空间, 保存调用自身的前一个帧,一个自身独立的数据栈和块栈,当前执行的最后一句指令,
并且配合这个对象,在虚拟机对象中设定相对应的三个方法:
make_frame创建帧,pop_frame和push_frame两个对应帧和调用栈的操作,run_frame开始运行当前调用栈栈顶的帧。
function
文章中指出这个对象的实现和理解有些曲折。
这个位置也的确是在我前面分析中卡住一下的位置,关于这里面的函数调用的实现。
我们需要注意他其中的__call__()方法创建了新的帧,并开始运行它。
def __call__(self, *args, **kwargs):
if PY2 and self.func_name in ["" , "" , "" ]:
# D'oh! http://bugs.python.org/issue19611 Py2 doesn't know how to
# inspect set comprehensions, dict comprehensions, or generator
# expressions properly. They are always functions of one argument,
# so just do the right thing.
assert len(args) == 1 and not kwargs, "Surprising comprehension!"
callargs = {".0": args[0]}
else:
callargs = inspect.getcallargs(self._func, *args, **kwargs)
frame = self._vm.make_frame(
self.func_code, callargs, self.func_globals, {}
)
CO_GENERATOR = 32 # flag for "this code uses yield"
if self.func_code.co_flags & CO_GENERATOR:
gen = Generator(frame, self._vm)
frame.generator = gen
retval = gen
else:
retval = self._vm.run_frame(frame)
return retval
然后相对应的在虚拟机对象的位置,
这里主要讲下对于程序执行的相关:
- 关于如何在解析code object
在虚拟机对象下的方法parse_nyte_and_args()中,进行语法分析,
在这里主要使用dis中的方法,显示提取出来byte code, 然后dis.opname得到对应的命名,
这里要提到一点,这个字节码就是一串数据,一般来说语句自身会占有一个byte,如果没有参数后面就是跟着下一个语句,如果有参数则会是后面两位代表其参数值或者是其参数在code object 中的index。
并可以判断其是否有参数,然后对于参数跟在其后的直接取出,如果是直接其值,则直接取出,如果是对应的index 则做出对应的处理,
并且这里注意,调用这里分析,只会分析一句,返回这一句的对应的数据,然后运行完后再解析下一句。于是这还保存着上一句分析后的位置,( 其实这个道理应该是比较容易理解的,就是一个类似机器码转化为汇编代码并标注好参数数据位置的一个过程)
终归就是在这里, 将我们汇编以后的二进制数据,转化成对应的的人类可读的名称,并处理出来其参数,最后返回回去一个此语句对应操作名称,对应的参数,还有对应分析到的位置。
def parse_byte_and_args(self):
""" Parse 1 - 3 bytes of bytecode into
an instruction and optionally arguments."""
f = self.frame
opoffset = f.f_lasti
byteCode = byteint(f.f_code.co_code[opoffset])
f.f_lasti += 1
byteName = dis.opname[byteCode]
arg = None
arguments = []
if byteCode >= dis.HAVE_ARGUMENT:
arg = f.f_code.co_code[f.f_lasti:f.f_lasti+2]
f.f_lasti += 2
intArg = byteint(arg[0]) + (byteint(arg[1]) << 8)
if byteCode in dis.hasconst:
arg = f.f_code.co_consts[intArg]
elif byteCode in dis.hasfree:
if intArg < len(f.f_code.co_cellvars):
arg = f.f_code.co_cellvars[intArg]
else:
var_idx = intArg - len(f.f_code.co_cellvars)
arg = f.f_code.co_freevars[var_idx]
elif byteCode in dis.hasname:
arg = f.f_code.co_names[intArg]
elif byteCode in dis.hasjrel:
arg = f.f_lasti + intArg
elif byteCode in dis.hasjabs:
arg = intArg
elif byteCode in dis.haslocal:
arg = f.f_code.co_varnames[intArg]
else:
arg = intArg
arguments = [arg]
return byteName, arguments, opoffset
- 关于如何执行字节码
这一部分在虚拟机对象的dispatch方法中。
首先是在虚拟机对象下定义好字节码对应的方法,他们使用byte_xx作为前缀,然后使用getattr 就可以获取到对应的方法,然后去执行。
最后每次执行都会返回一个指示下一次运行状态的变量,称为why,
注意这个why不要和我们函数调用(帧的切换)里面的返回值混为一谈。
stack
关于栈的操作。
关于调用栈的操作我们在前面frame部分写了。
- 然后关于数据栈的操作:
主要是top()返回当前栈顶, pop和push 压栈和弹出,popn弹出指定的最后n个数据组成的一个列表。
算是实现了几个基本的对于数据栈的操作。
其后的一些基础指令和顺序结构的指令基本会由这几个构成,
- 关于块栈的操作
这个块栈主要用于循环结构,还有一些生成器。并且会存在指示下一句运行状态的变量, 我们前面提到的变量why ,
最后
其实这里只是对于整体做出一个了解,写的还是比较简单的,下一步准备去看看关于其中的大批byte_xx系列的字节码实现,
原本是准备去在后面写关于ctf中python逆向的题目,但是发现大部分和解释器没太大关系的样子,主要是pyc文件,简单题目直接得到源码,一些难的会做出混淆,少的直接看字节码,大一些的想办法修复pyc文件转为源码。觉得写在一篇有些前后不搭,后面的文章再整理吧。
然后关于python的解释器部分,在源码的/cpython/python/ceval.c