在线上服务中使用 Spark MLlib
推荐系统的在线(Online)计算和离线(Offline)计算
根据计算环境的不同,推荐系统的预测大体上可以分为在线(Online)、离线(Offline)两种。在线计算,指的是在线上的推荐服务中,对接受到的请求,进行实时计算,生成推荐结果并直接返回给请求方。离线计算,是指以一定时间周期运行的,对数据库中的大批量数据进行的计算。离线计算的结果通常会写入数据库中,供后续任务读取。除此之外,还有介于在线和离线之间的近线(Nearline)计算,它主要以流处理的方式对近实时的数据进行处理,并将结果写入数据库。
在推荐系统中,在线计算和离线计算有各自的优缺点,及其适合的使用场景。在线计算能够做到实时地对用户行为作出反馈,从而可以针对用户当前所处的环境和临时萌生的兴趣,为其提供更即时、更精准的推荐。但是,受限于系统对于延迟的要求,在线计算必须在算法的复杂性上作出一些牺牲。此外,在线计算能够处理的数据量通常也是比较小的。
离线计算对于算法的复杂性要求则没有那么高。它通常是以批处理的方式在分布式集群上计算。因此,它往往可以处理更大量的数据,考虑更多的特征。但由于离线计算通常是每天一次,因此也就相应的损失了一些实时性,无法对用户行为作出及时反馈。除了预测任务,模型的训练过程也可以算作为一种离线计算。它使用日志系统收集的历史数据,训练得到一个模型,并对其进行性能评估。产出的模型,将会被用于后面的离线和在线预测。模型训练过程,占用的资源多,花费的时间长,比较适合在分布式集群上计算。
离线训练与在线预测的矛盾
在常用的计算平台上,离线预测任务可以和模型训练无缝衔接。Spark MLlib 提供了 Pipeline 的接口。它可以将模型训练,连同训练前的特征预处理、特征工程、特征交叉等阶段,按照一定次序组合成为一个流水线,并支持将训练好的整个流水线持久化到磁盘上。在预测阶段,只需将训练时存下的流水线模型整个加载到集群上,然后将原始特征直接输入进流水线,即可得到模型预测的结果了。模型分布式训练中使用 DataFrame 包装训练数据,模型离线预测时也是在分布式环境中使用 DataFrame 包装待预测数据。这种使用方法,也是 Spark MLlib 官方文档中推荐的用法。
但是,正如上面提到的,离线预测最大的弊端是,它缺少实时性。为了为推荐系统提供更好的实时性,我们需要在线上服务中,使用用户当前的实时特征和反馈,为其推荐出她当下可能感兴趣的东西。在线上服务中,我们想对用户可能感兴趣的物品进行排序,使得最合口味的物品被排在推荐列表的前列。因此,需要将离线训练的模型部署到线上服务中。
即刻推荐系统的离线计算使用 Spark MLlib 以分布式的方式在集群上,在线计算则是在用 Java 写的线上服务中完成的。不同于离线预测,在线的模型预测没有直接使用离线训练储存的流水线模型,而是独立实现了模型预测的算法,以及输入模型前的全套特征预处理过程。因此,在每次离线训练结束,将模型部署到线上时,需要将训练得到的模型参数拷贝到线上服务中,同时特征预处理过程需要的参数也需要同步更新到线上服务中。换句话说,我们需要在线上原封不动地再实现一遍离线训练中定义的特征预处理操作和具体的模型结构。
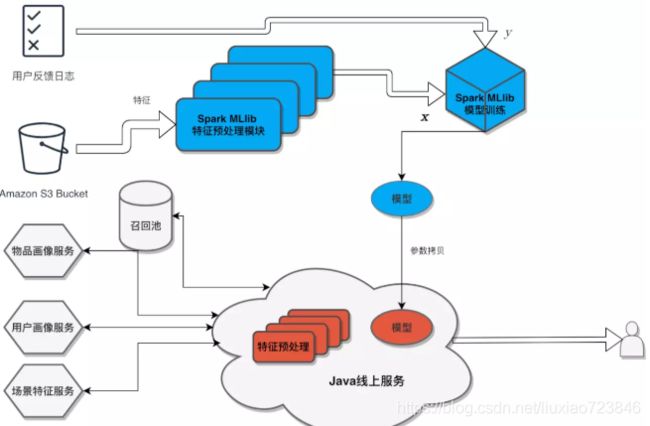
这就意味着,在线下模型训练时做的任何一点改动,都必须在线上服务中同步修改。这种方式不仅使得模型的更新链路冗长,不利于模型的快速迭代与验证, 而且增加了线上服务开发的工程师和离线模型优化的算法研究员之间的沟通成本,迫使实现线上服务的工程师不得不感知具体的模型实现细节。此外,同一套逻辑需要两套代码实现,这种方式也对之后代码的维护造成了很多麻烦。
软件工程,强调代码复用的重要性。那么在离线模型训练和在线模型预测之间,如何做到代码复用?在深度学习领域,最受工业界欢迎的框架 TensorFlow 为了解决这个问题,提出了 TensorFlow Serving。它是一个为生产环境设计的模型部署系统,目的是使得训练好的模型可以方便地部署在服务器上,做实时的预测。传统的机器学习框架,尤其是分布式机器学习框架,很少有类似的解决方案。其中最主要的问题在于,类似于 Spark MLlib 这样的分布式学习框架,主要适用于数据规模较大的应用场景。它采用分布式批处理(batch processing)的机制,能够在多台机器上并行地处理大量预测样本,具有较高的吞吐量。然而,对于实时推荐这样的线上服务来 说,高吞吐量并不是它需要的,低延迟才是这种线上服务最大的要求。Spark MLlib 在预测时需要将数据转换为 DataFrame 这样的分布式数据结构,而这种转换会产生秒级别的经常性开支(overhead),这在毫秒级延迟的线上服务中是不可以接受的。
因此,我们面临了一个两难的困境:既希望模型可以以分布式高吞吐量的方式进行离线训练,同时又希望训练好的模型可以在线上以低延迟的方式进行实时预测。这就是在线预测和离线训练之间的矛盾。
面向实时预测的接口
为了解决上面所说的矛盾,我们考虑在 Spark MLlib 的接口上做一些改动,给它加上实时预测的接口。
Spark MLlib 的 Pipeline 接口的通用性,在很大程度上依赖 DataFrame 这一通用的数据结构。对于 Spark MLlib 来说,在 Pipeline 中流动的数据,都是使用 DataFrame 包装的,每个 Transformer 都接收一个 DataFrame,对其做一个「变形」的操作,然后输出一个新的 DataFrame。DataFrame 的 schema 通过 Transformer 的参数(Param)来约定。
这一套行事方式在分布式计算中非常好用,但在对延迟要求很高的线上服务中,就不太适用了。其中,最主要的原因是,在线上单机计算的环境中将数据转化为 DataFrame 会有很多不必要的开销,影响服务的延迟。因此,一个直观的想法是:在 Spark MLlib 中为 Transformer 提供一个不依赖 DataFrame 的接口,使其内部核心的计算逻辑直接暴露出来,然后在线上服务中使用这一接口,从而绕过将数据用 DataFrame 封装这一耗时的操作。
经过观察,我们发现,推荐系统中最常用的模型预测流水线,主要由三个部分组成:特征向量化,特征预处理,和模型预测。其中,特征向量化是将各种数据类型的原始特征转化为向量的过程,它可以由一个特征向量化器(feature vectorizer)完成,其输入是一个某种数据类型的原始特征(比如说一个Map),输出是一个特征向量;特征预处理是对特征向量进行变形、归一化等操作的过程,它可以由一个或多个特征转换器(feature transformer)组成,其中每个转换器的输入和输入都是一个向量类型的特征;模型预测是指将特征输入一个训练好的分类器、回归器,或排序器中,得到一个「分数」的过程,其中「分数」可以表示离散的标签(分类器),也可以表示连续的值(回归器),甚至可以是一个排名(排序器),它的输入是一个向量类型的特征,输出是一个标量值。由于样本特征在存储的时候可能不是采用向量这种类型,而通用的特征处理器都是假设了特征为向量,所以一般我们会在第一步首先将非向量类型的特征转化为向量类型。
基于上面的分析,我们设计了两个面向实时预测的接口,分别用于特征向量化、预处理和模型预测。
预测器的抽象接口是 OnlinePredictor。它有一个类型参数 FeaturesType,表示这个预测器可以接收的特征类型。我们注意到,对于某些预测器,我们有时需要得到两种类型的预测得分,比如对于二分类器,可能不仅需要输出分类标签,还要输出原始的预测得分。因此,在 OnlinePredictor 中有 predict 和 predictRaw 两个预测接口,根据具体的模型实现需要,可以分别设定两个接口结果的含义。

OnlinePredictor 是一个可供线上实时预测时使用的接口,因此它的 predict 函数接受的输入类型直接是特征的类型,而非 Spark 提供的 DataFrame。 此外,它同时继承了 Spark MLlib 中的 Transformer,因此它也可以在 transform 函数中接受一个 DataFrame 作为输入,从而支持大批量分布式场景下的预测。
如果说 OnlinePredictor 是模型预测的抽象的话,那么 FeatureTransformer 就是特征向量化和预处理的抽象。FeatureTransformer 有两个类型参数,IN 和 OUT,分别表示输入特征类型和输出特征类型。与 OnlinePredictor 类似,它除了提供批量处理的 DataFrame 接口之外,还提供了在线上实时预测时使用的 transformOne 和 transformBatch,可以直接接收特征,无须使用 DataFrame 包装。

为了在 FeatureTransformer 的实时预测接口和分布式计算接口共享处理逻辑,它在内部提供了一 个 transformFunc,它是一个 IN => OUT 类型的函数。具体的特征处理器只需在这个函数中实现处理逻辑,在处理线上接口时,会直接调用这个函数,而在处理批量数据时会将这个函数包装为 Spark 中的用户定义函数(user defined function, UDF),广播到每个节点上对数据进行分布式处理。
在特征预处理中,一个典型的操作是特征标准化。它会统计特征在每个维度上的平均值和标准差,并对输入的特征进行标准化——即减去均值后除以标准差——使所有特征的均值都为 0,标准差都为 1。在面向实时预测的接口中,特征标准化的操作则可以由一个 FeatureTransformer[Vector, Vector] 类型的特征转换器来完成,它可以接收一个向量类型的原始特征,输出一个向量类型的标准化后的特征。在内部,它的实现方式与 Spark MLlib 中的相似,只不过它的特征转换逻辑是实现在 transformFunc 函数中的。因此,它不仅可以转换一个 DataFrame 中的特征列,也可以直接转换一个向量类型的特征值。
特征向量化则可以看作是一类特殊的特征预处理,它是一个 FeatureTransformer[FeaturesType, Vector] 的特征转换器,其中 FeaturesType 表示自定义的输入特征类型,输出一个向量类型的特征。
面向实时预测的流水线
有了 OnlinePredictor 和 FeatureTransformer,我们可以构建各种各样的预测器和特征预处理器,并同时在离线分布式环境和线上实时预测中使用它们。 为了更好地封装模型训练过程,使得在线上不再需要感知任何关于模型训练的细节, 我们又进一步提出了面向实时预测的流水线——OnlinePredictionPipeline。
正如上面所说,推荐系统中最常用的模型预测流水线,主要由特征向量化,特征预处理,和模型预测三个部分组成。因此,在 OnlinePredictionPipeline 中,我们将组件也分成了三个部分:一个特征向量化处理器(vectorizer)、一个或多个特征转换器(transformers),和一个最终的预测器 (predictor)。原始的特征像流水线上的物品一样,依次通过向量化、特征变形,以及最后的模型预测,最终输出一个预测的分数。

在 API 层面,OnlinePredictionPipeline 也是一种 OnlinePredictor,它可以接受一个原始特征,并对其进行向量化、预处理和模型预测;也可以在离线计算环境中处理一个 DataFrame,对批量的数据进行预测并输出一个 DataFrame。
在离线分布式训练时,可以对整个 OnlinePredictionPipeline 进行组装和训练,并将训练得到的流水线模型整个持久化到文件系统中。在预测阶段,如果是离线计算环境,可以使用 Spark MLlib 的 transform 接口进行分布式计算;如果是在线服务,可以在不感知内部具体流程和实现的情况下,将其看成为 一个 OnlinePredictor,使用 predict 接口对输入的单条原始特征进行预测。

有了 OnlinePredictionPipeline,在线下模型训练时,不论是增加特征处理器,还是替换预测模型,都不需要改动线上服务的预测逻辑,做到了「一套系统,两处运行」。
同时,由于 OnlinePredictor 和 FeatureTransformer 两个面向实时预测的接口直接将计算逻辑暴露了出来,不需要在线上服务中将特征转化为 DataFrame,减小了线上服务的延迟。实验表明,在线上环境中,相比于直接使用 Spark MLlib 的 DataFrame 接口,面向实时预测的接口可以有效降低延迟。
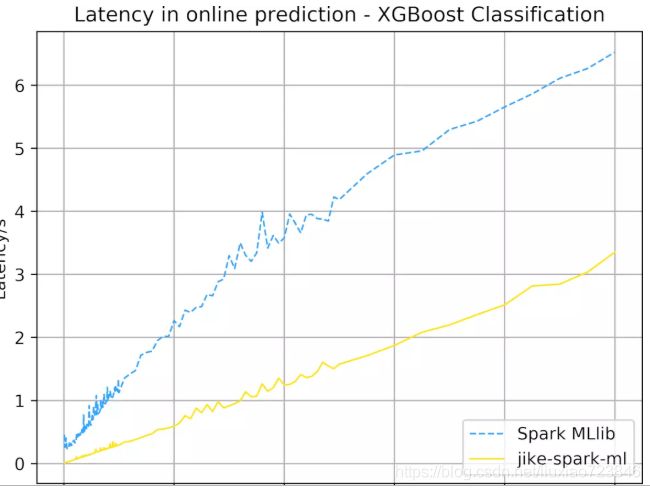
我们分析了推荐系统对于机器学习的使用场景和模式,指出了离线训练和在线预测两个计算场景的特点,提出了在这两个场景下复用代码的可能性和现有框架无法解决的问题。对此,我们在 Spark MLlib 提出的流水线接口上做了进一步扩展,提出了一种面向实时预测的接口,使得机器学习流水线不仅保留了在批量处理时高吞吐量的特性,而且显著降低了在实时预测场景下的延迟。除此之外,它还使得模型的离线训练与在线预测的代码得以复用,简化了模型的部署与维护。
一个成熟的推荐系统,离不开一个健壮的机器学习库的支撑。在即刻,我们持续研究复杂的前沿机器学习算法,并将其应用于真实的推荐系统中;我们还关注如何建立一套灵活、敏捷的部署流程,方便快速迭代模型。