目标检测正负样本区分策略和平衡策略总结(三)
作者:深度眸
编辑:晟 沚
简介
1
本文抛弃网络具体结构,仅仅从正负样本区分和正负样本平衡策略进行分析,大体可以分为正负样本定义、正负样本采样和平衡loss设计三个方面,主要是网络预测输出和loss核心设计即仅仅涉及网络的head部分。所有涉及到的代码均以mmdetection为主。本文是第三部分,重点分析下anchor-free和anchor-base混合学习的Guided Anchoring以及yolo-ASFF,包括思路和代码。下一篇分析各种新型平衡loss。
本文不会按照论文写作顺序一步一步分析,重点分析思想和代码实现。
Guided Anchoring
2
论文名称:Region Proposal by Guided Anchoring
1.核心思想
ga这篇论文我觉得做的蛮好,先不说最终效果提升多少个mAP,他的出发点是非常不错的。anchor-base的做法都需要预设anchor,特别是对于one-stage而言,anchor设置的好坏对结果影响很大,因为anchor本身不会改变,所有的预测值都是基于anchor进行回归,一旦anchor设置不太好,那么效果肯定影响很大。而对于two-stage而言,好歹还有一个rcnn层,其可以对RPN的输出roi(动态anchor)进行回归,看起来影响稍微小一点。
不管是one stage还是two-stage,不管咋预测,肯定都是基于语义信息来预测的,在bbox内部的区域激活值肯定较大,这种语义信息正好可以指导anchor的生成,也就是本文的出发点:通过图像特征来指导 anchor 的生成。通过预测 anchor 的位置和形状,来生成稀疏而且形状任意的 anchor。 可以发现此时的anchor就是动态的了。
如果将faster rcnn进行改造,将RPN层替换为ga层,那肯定也是可以的,如果将retinanet或者yolo的预测层替换为ga,那其实就完全变成了anchor-free了。但是作者采用了一种更加优雅的实现方式,其采用了一种可以直接插入当前anchor-base网络中进行anchor动态调整的做法,而不是替换掉原始网络结构,属于锦上添花,从此anchor-base就变成了anchor-base混合anchor-free了(取长补短),我觉得这就是一个不错的进步。
2.网络设计

作者是以retinanet为例,但是可以应用于所有anchor-base论文中。
核心操作就是在预测xywh的同时,新增两条预测分支,一条分支是loc(batch,anchor_num * 1,h,w),用于区分前后景,目标是预测哪些区域应该作为中心点来生成 anchor,是二分类问题,这个非常好理解,另一条分支是shape(batch,anchor_num * 2,h,w),用于预测anchor的形状。
一旦训练好了,那么应该anchor会和语义特征紧密联系,如下所示: 
其测试流程为:
对于任何一层,都会输出4条分支,分别是anchor的loc_preds,anchor的shape_preds,原始retinanet分支的cls_scores和bbox_preds
使用阈值将loc_preds预测值切分出前景区域,然后提取前景区域的shape_preds,然后结合特征图位置,concat得到4维的guided_anchors(x,y,w,h)
此时的guided_anchors就相当于retinanet里面的固定anchor了,然后和原始retinanet流程完全相同,基于guided_anchors和cls_scores、bbox_preds分支就可以得到最终的bbox预测值了。
可以发现和原始retinanet相比,就是多了anchor预测分支,得到动态anchor后,那就是正常的retinanet预测流程了。
3.loss设计
主要就是anchor的loc_preds和shape_preds的loss设计。
(1) loc_preds
anchor的定位模块非常简单,就是个二分类问题,希望学习出前景区域。这个分支的设定和大部分anchor-free的做法是一样的(例如fcos)。
首先对每个gt,利用FPN中提到的roi重映射规则,将gt映射到不同的特征图层上
定义中心区域和忽略区域比例,将gt落在中心区域的位置认为是正样本,忽略区域是忽略样本(模糊样本),其余区域是背景负样本,这种设定规则很常用,没啥细说的,如图所示:

采用focal loss进行训练
(2) loc_shape
loc_shape分支的目标是给定 anchor 中心点,预测最佳的长和宽,这是一个回归问题。先不用管作者咋做的,我们可以先思考下可以如何做,首先预测宽高,那肯定是回归问题,采用l1或者smooth l1就行了,关键是label是啥?还有哪些位置计算Loss?我们知道retinanet计算bbox 分支的target算法就是利用MaxIoUAssigner来确定特征图的哪些位置anchor是正样本,然后将这些anchor进行bbox回归。现在要预测anchor的宽高,当然也要确定这个问题。
第一个问题:如何确定特征图的哪些位置是正样本区域?,注意作者采用的anchor个数其实是1(作者觉得既然是动态anchor,那么个数其实影响不会很大,设置为1是可以的错),也就是说问题被简化了,只要确定每个特征图的每个位置是否是正样本即可。要解决这个问题其实非常容易,做法非常多,完全可以按照anchor-free的做法即可,例如FOCS,其实就是loc_preds分支如何确定正负样本的做法即可,确定中心区域和忽略区域。将中心区域的特征位置作为正样本,然后直接优化预测输出的anchor shape和对应gt的iou即可。但是很明显论文没有这么做(个人猜测应该是当时anchor-free的做法还没有得到充分认可,ga论文发表时间是1901,而fcos发表时间是1904,当然纯属猜测),我觉得直接按照fcos的做法来确定正样本区域,然后回归shape,是完全可行。本文做法是采用了ApproxMaxIoUAssigner来确定的,ApproxMaxIoUAssigner和MaxIoUAssigner非常相似,仅仅多了一个Approx,其核心思想是:利用原始retinanet的每个位置9个anchor设定,计算9个anchor和gt的iou,然后在9个anchor中采用max操作,选出每个位置9个iou中最高的iou值,然后利用该iou值计算后续的MaxIoUAssigner,此时就可以得到每个特征图位置上哪些位置是正样本了。简单来说,ApproxMaxIoUAssigner和MaxIoUAssigner的区别就仅仅是ApproxMaxIoUAssigner多了一个将9个anchor对应的iou中取最大iou的操作而已。
对于第二个问题:正样本位置对应的shape target是啥,其实得到了每个位置匹配的gt,那么对应的target肯定就是Gt值了。该分支的loss是bounded iou loss,公式如下: 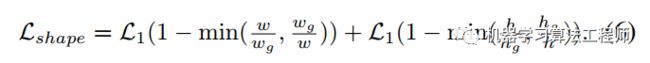
上面写的非常简陋,很多细节没有写,放在第5节代码分析中讲解。
4.结果


可以看出非常符合预期。
5.代码分析
(1) head
本文代码分析以retinanet为主,网络骨架和neck就没啥说的了,直接截图: 
就是ResNet+FPN结构,输出5个分支进行预测。stride为[8, 16, 32, 64, 128]。
对于head部分,可以对比retinanet的head部分进行查看: 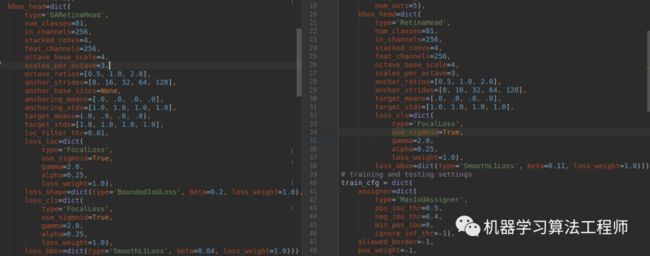
左边是GARetinaHead,右边是RetinaHead,可以看出配置除了loss有区别外,都是一样的。
head部分的forward非常简单,和retinanet相比就是多了两个shape_pred, loc_pred分支: 
关于feature_adaption的作用作者在论文分享中:Guided Anchoring: 物体检测器也能自己学 Anchor说的很清楚了,我就不写了。反正forward后就可以4个分支输出。
(2) loss计算
(2-1) anchor的loc分支loss计算
loc输出特征图大小是(batch,1,h,w),本质上是一个二分类器,用于找出语义前景区域。 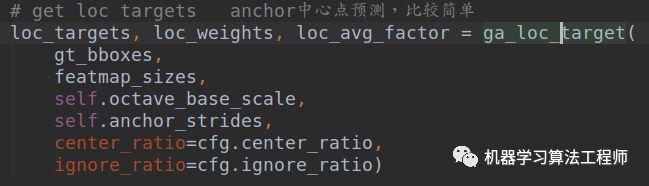
核心参数是中心区域占据比例center_ratio=0.2,忽略区域占比ignore_ratio=0.5.首先需要计算loc分支的target,方便后面计算loss,对应的函数是ga_loc_target,由于代码比较多,不太好写,我只能写个大概流程出来。 

有了每个特征图上,每个位置是正负还是忽略样本的结果,就可以针对预测的Loc特征图计算focal loss了: 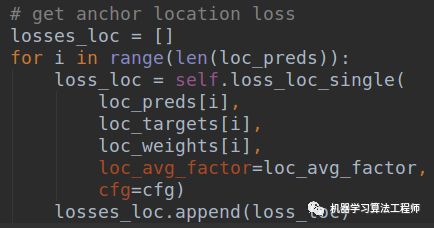
(2-2) anchor的shape分支loss计算
这个分支稍微复杂一点点。首先我们要先熟悉下train_cfg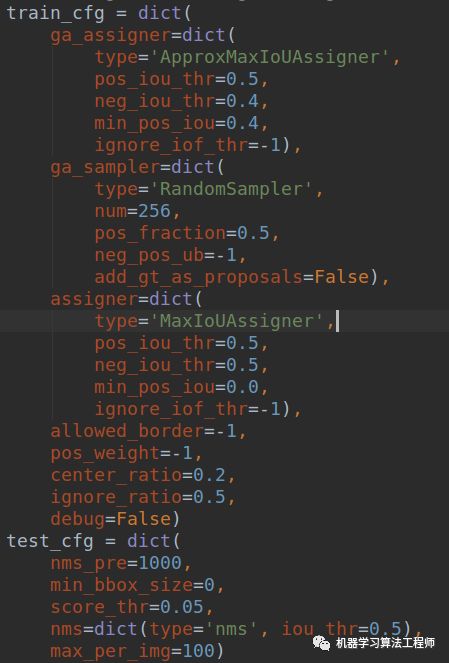
对于GA分支,主要包括ApproxMaxIoUAssigner和RandomSampler,而原始的retinanet分类和回归分支没有任何改变,不再赘述。ApproxMaxIoUAssigner是用来近似计算shape特征图分支上哪些位置负责预测gt bbox,而RandomSampler主要目的不是用来平衡正负样本的,因为shape分支监督的只有正样本,没有啥平衡问题。
上述两个类非常关键,理解清楚了才能理解最核心的shape target计算过程。
(1) 计算5个特征图上,每个位置9个anchor,组成anchor_list 
这个函数和其他anchor-base的anchor生成过程完全相同,就是利用特征图大小、anchor设置得到所有预设anchor的(x0,y0,x1,y1)坐标
(2) 计算每个特征图的每个位置上shape预测的基数 
可能这个不好理解。其实在原文中作者指出shape分支直接预测gt bbox的宽高值不太稳定,因为数值波动范围比较大,为了稳定,作者回归的shape预测值实际上是在某个缩放系数下的值,具体是: 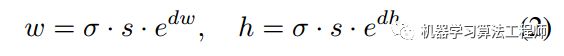
![]() ,s是每个特征图的stride,w就是原始gt bbox宽,dw才是shape分支的预测值。上述的squares_list存储的就是每层特征图的每个位置的基数,用于还原shape预测值到真实比例,由于anchor=1,且对于任意层而言是固定的,所以在代码实现上作者也用了anchor_generate代码来实现
,s是每个特征图的stride,w就是原始gt bbox宽,dw才是shape分支的预测值。上述的squares_list存储的就是每层特征图的每个位置的基数,用于还原shape预测值到真实比例,由于anchor=1,且对于任意层而言是固定的,所以在代码实现上作者也用了anchor_generate代码来实现
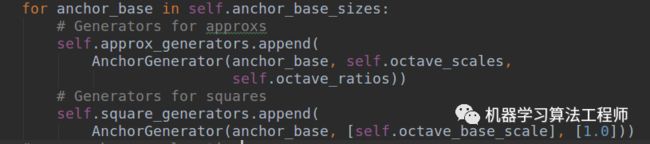
可以明显发现approx_generators是每个位置9个anchor,而square_generators每个位置是1个anchor,且是正方形。为了方便区分,你可以认为squares_list存储的就是每一层的还原基数而已,和anchor没啥关系的,只不过可以等价实现而已。而guided_anchors_list其实就是在squares_list基础上结合loc预测和shape预测得到的动态anchor,用于训练原始的retinanet的分类和回归分支。
而如何利用squares_list、loc_pred和shape_pred得到最终的动态anchor,做法非常简单,如下所示(测试阶段也是这个流程): 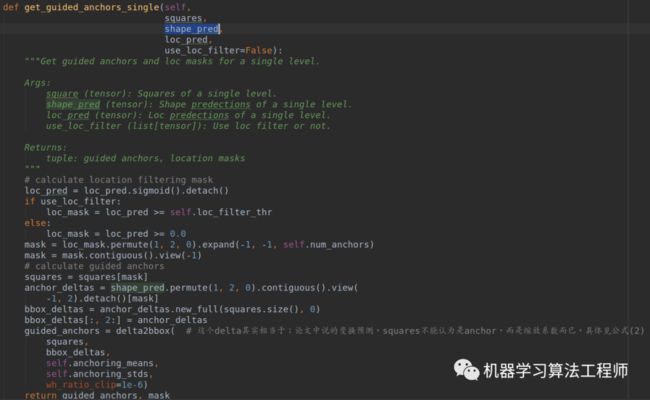
(3) 计算shape target
在得到squares_list、approxs_list和gt_bboxes,下面核心就是计算shape target了。函数是: 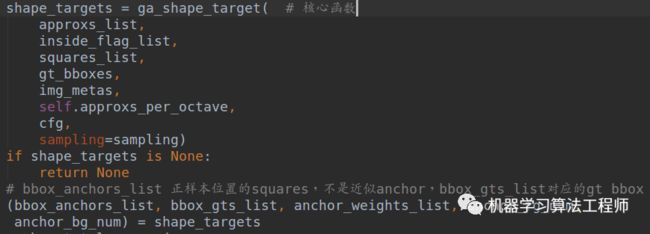
计算shape target的流程包括2步:1、确定哪些位置是正样本,通过ApproxMaxIoUAssigner类实现;2. 每个正样本位置的label,通过RandomSampler实现。这两个操作看起来和faster rcnn的rpn阶段的loss计算相同,其实仅仅思想相同而已,但是实现差别还是很大的。
假设你已经了解了MaxIoUAssigner的实现过程,而ApproxMaxIoUAssigner的实现是继承自MaxIoUAssigner的,其核心差别是: 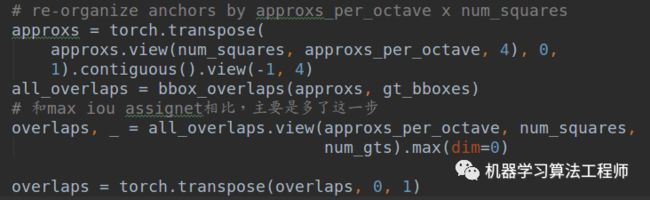
而MaxIoUAssigner仅仅有以下一行而已:
overlaps = bbox_overlaps(gt_bboxes, bboxes)
ApproxMaxIoUAssigner的做法是对于每个位置,先计算9个anchor和gt bbox的iou,然后max选择最大iou,将anchor=9变成anchor=1(因为预测就是只有1个anchor),然后在这个overlaps基础上再进行MaxIoUAssigner分配机制,从而确定哪些位置是正样本,同时会记录每个位置负责的gt bbox索引,方便后面计算。
下一步是RandomSampler函数,但是要非常注意:
retinanet的是RandomSampler调用过程:
assign_result = bbox_assigner.assign(anchors, gt_bboxes,
gt_bboxes_ignore, gt_labels)
而ga分支的调用过程是:
确定了哪些位置是正样本区域后,需要加入正样本区域的squares值。
注意这里加入的anchor不是近似anchor,而是squares sampling_result
= bbox_sampler.sample(assign_result, squares, gt_bboxes)
函数内部实现是一样的,但是由于传入的参数不一样,所有解释就不一样了。第一行的输入是anchor和gt bbox,意思是随机采样正负样本,并且同时将gt bbox作为label,后面直接计算回归loss,但是注意ga分支的输入是assign_result和squares,而不是assign_result和gt bbox,也不是assign_result和approxs。也就是说咱们暂时把每个正样本位置shape预测值的target认为是squares值,后面还会进一步操作。
到这里为止,就已经知道了shape_target返回的各个值含义了。bbox_anchors_list存储的是所有正样本位置的squares值,bbox_gts_list是对应的gt bbox值,在得到所有需要的值后终于可以开始计算shape target的loss了。 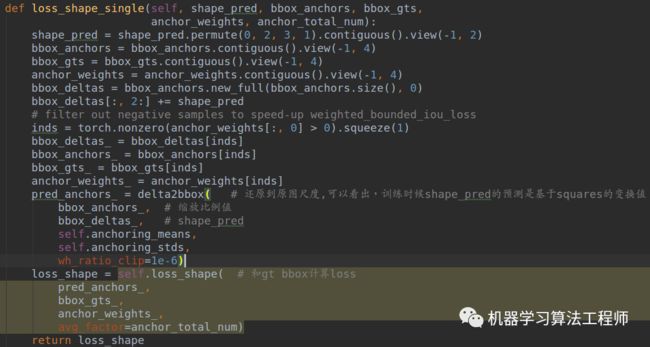
bbox_anchor其实就是bbox_anchors_list,将bbox_anchors_list和shape_pred经过delta2bbox就还原得到真实的bbox预测值了,只不过由于本分支仅仅用于预测shape,故bbox_deltas的前两个维度一直是0,loss_shape是BoundedIoULoss。
到此,核心代码就分析完了。稍微难理解的就是shape target的计算过程了。
yolo-asff
3
论文名称:Learning Spatial Fusion for Single-Shot Object Detection
源码地址:https://github.com/ruinmessi/ASFF
1.简介
先贴性能: 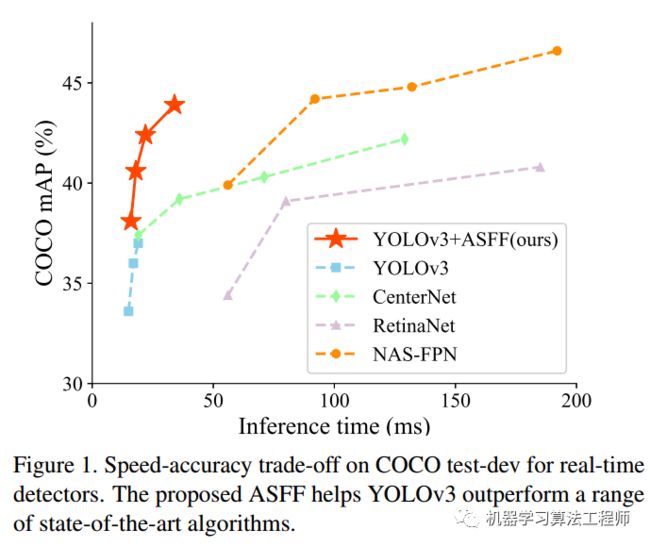
首先可以看出是非常强的。虽然本文题目重点是说ASFF层的牛逼地方,但是我觉得看本文,重点不在这里,而是yolov3的强baseline。 
通过一些训练技巧,将yolov3从33.0mAP,提升到38.8mAP,我觉得这个才是重点需要学习的地方。这其实反映出一个明显问题:骨架的改进固然重要,但是训练技巧绝对要引起重视,很多新提出的算法搞了半天提升了1个mAP点,还不如从训练技巧上面想点办法来的快(在人脸检测领域就会针对人脸尺度问题针对性的提出大量训练技巧,是非常高效的),毕竟训练技巧只会影响训练过程,对推理没有任何额外负担,何乐不为。
2.ASFF
本文先分析不那么重要的部分,即本文最大改进ASFF(Adaptively Spatial Feature Fusion)操作,其实熟悉BiFpn的人应该马上就能get到idea了,我觉得本质上没有啥区别。
FPN操作是一个非常常用的用于对付大小尺寸物体检测的办法,作者指出FPN的缺点是不同尺度之间存在语义gap,举例来说基于iou准则,某个gt bbox只会分配到某一个特定层,而其余层级对应区域会认为是背景(但是其余层学习出来的语义特征其实也是连续相似的,并不是完全不能用的),如果图像中包含大小对象,则不同级别的特征之间的冲突往往会占据要素金字塔的主要部分,这种不一致会干扰训练期间的梯度计算,并降低特征金字塔的有效性。一句话就是:目前这种concat或者add的融合方式不够科学。本文觉得应该自适应融合,自动找出最合适的融合特征,如下所示: 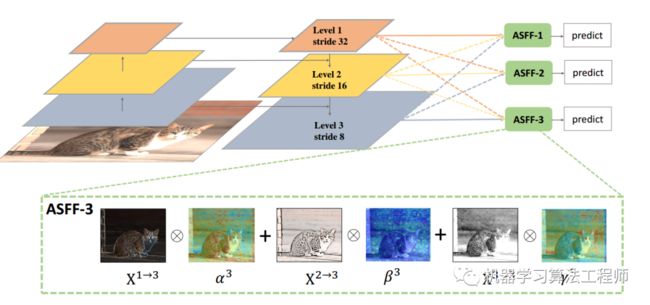
简要思想就是:原来的FPN add方式现在变成了add基础上多了一个可学习系数,该参数是自动学习的,可以实现自适应融合效果,类似于全连接参数。
ASFF具体操作包括 identically rescaling和adaptively fusing。
定义FPN层级为l,为了进行融合,对于不同层级的特征都要进行上采样或者下采样操作,用于得到同等空间大小的特征图,上采样操作是1x1卷积进行通道压缩,然后双线性插值得到;下采样操作是对于1/2特征图是采样3 × 3 convolution layer with a stride of 2,对于1/4特征图是add a 2-stride max pooling layer然后引用stride 卷积。
Adaptive Fusion 
下面讲解具体操作:
(1) 首先对于第l级特征图输出cxhxw,对其余特征图进行上下采样操作,得到同样大小和channel的特征图,方便后续融合
(2) 对处理后的3个层级特征图输出,输入到1x1xn的卷积中(n是预先设定的),得到3个空间权重向量,每个大小是nxhxw
(3) 然后通道方向拼接得到3nxhxw的权重融合图
(4) 为了得到通道为3的权重图,对上述特征图采用1x1x3的卷积,得到3xhxw的权重向量
(5) 在通道方向softmax操作,进行归一化,将3个向量乘加到3个特征图上面,得到融合后的cxhxw特征图
(6) 采用3x3卷积得到输出通道为256的预测输出层 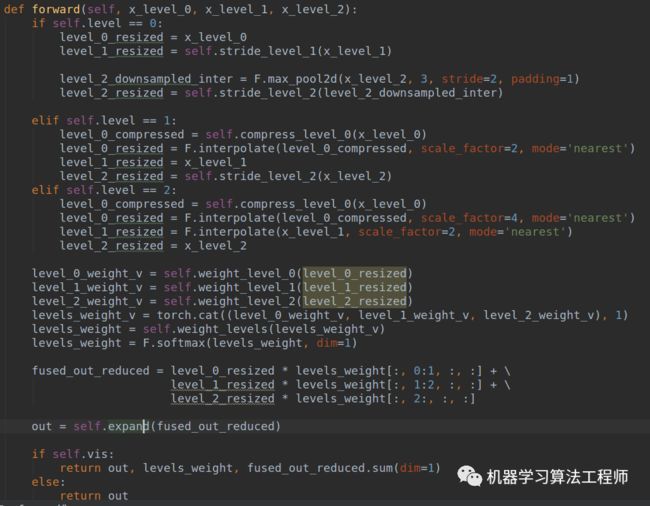
ASFF层学习得到的各种特征可视化效果如下:
3.强baseline
YOLOv3包括darknet53骨架网络和3层特征金字塔网络构成的3个尺度输出。
首先采用基于Bag of freebies for training object detection neural networks里面提出的训练策略来改进性能,主要包括 the mixup algorithm , the cosinelearning rate schedule和 the synchronized batch normalization。
其次,由于最新论文表示iou loss对于边界框回归效果好,故作者也额外引入了一个iou loss来优化bbox。
最后,由于GA论文(Region proposal by guided anchoring)指出采用语义向导式的anchor策略可以得到更好的结果,故作者也引入了GA操作来提升性能。
可以看出,结合这些策略后,在coco上面可以得到38.8的mAP,速度仅仅慢了一点点(多了GA操作),可谓是非常强大,这也反应出训练策略对最终性能的影响非常大。
the mixup algorithm , the cosinelearning rate schedule和 the synchronized batch normalization这三个策略非常常见,没啥好说的。额外引入一个iou loss也是常规操作。我们重点分析GA的实现。为啥要重点分析GA操作呢?因为作者实现的GA和原始论文的GA有点不同,很值得分析。
4.loss代码分析
对应的代码是YOLOv3Head.py
首先和GA一样,也是有FeatureAdaption,用于对动态anchor特征进行自适应。
(1) 初始化函数 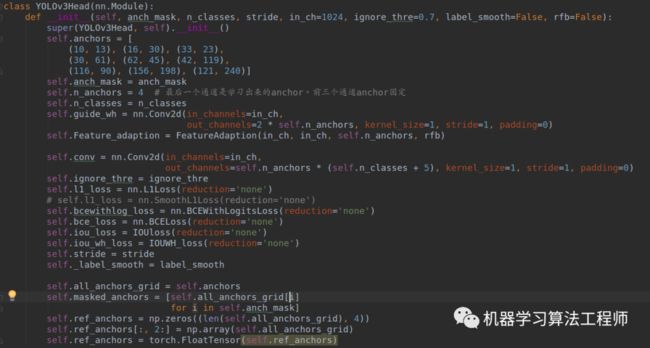
anchors里面存储的就是原始yolov3的9组anchor,但是特别需要注意的是这里实现的anchor个数是4个,而不是GA原文的1个anchor,这个小差别会导致后面代码有些差别。按照GA论文做法,其实1个anchor就足够了。而且需要注意这里的GA分支没有输出Loc,仅仅有shape预测。原因是loc分支的目的仅仅是用于进行前后景提取,是个二分类问题,但是由于yolo有confidence分支,其有前后景提取功能,故不再需要loc分支。
loss函数方面,就是多了shape预测的IOUWH_loss函数,以及bbox回归额外引入的IOUloss,其余相同。
(2) forward函数
(2-1) 输出预测值 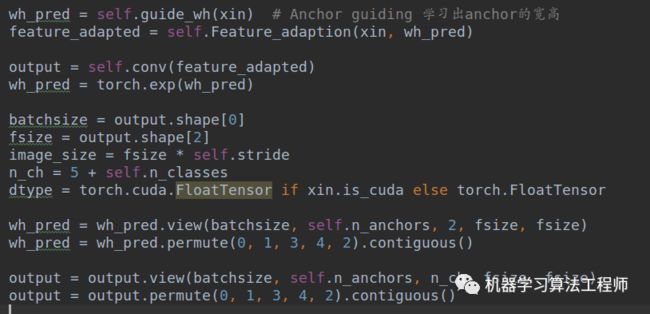
对ASFF层输出的每一层特征图xin,进行GA分支推理,并且经过Feature_adaption,得到最终的bbox预测输出output,由于wh预测肯定是大于0的,故作者采用了exp函数强制大于0.此时就得到了wh_pred(batch,4,2,h,w)和output(batch,4,5+class,h,w)。
(2-2) 将预测anchor变换到原图尺度,得到guide anchor 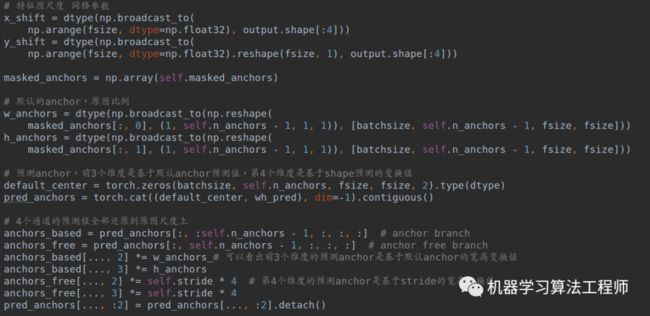
(2-3) 前向模式下基于预测anchor直接进行回归即可得到最终bbox 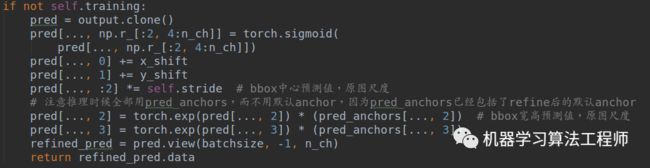
(2-4) 训练模式下准备target
先准备数据: 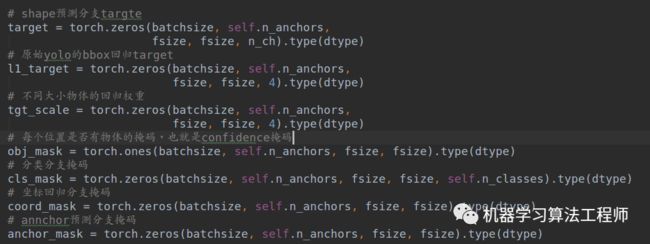
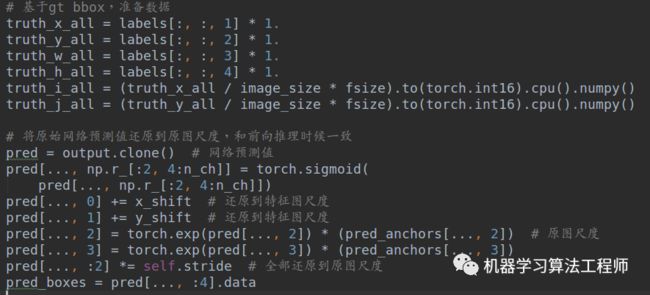
计算匹配anchor和confidence mask 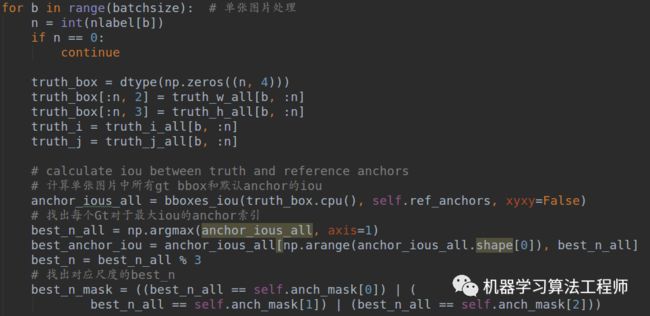
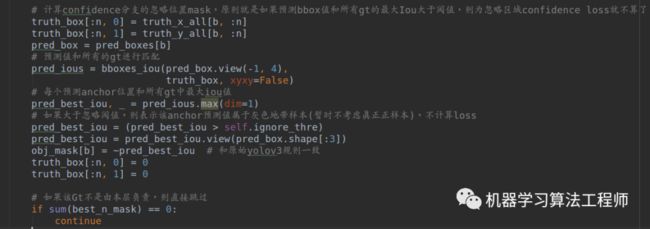
理解下面的操作才是理解了本文核心:
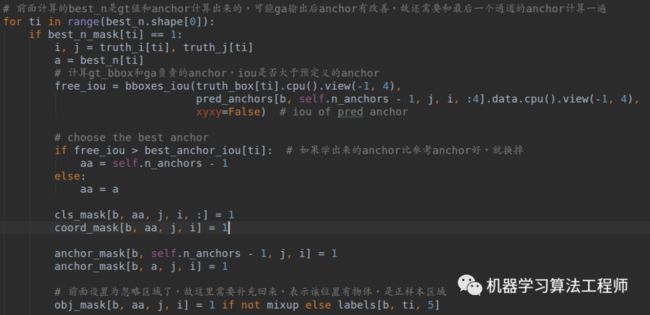
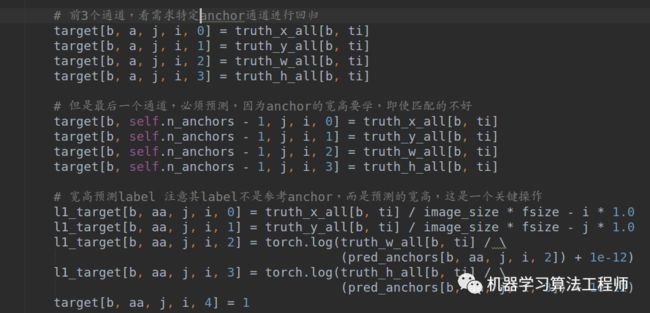
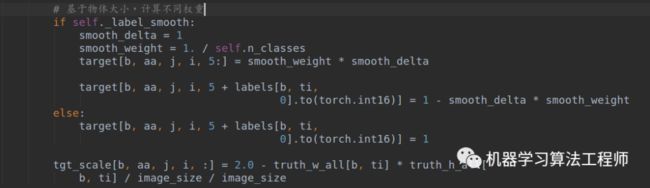
前面所有准备都好了后,就是计算loss了: 
可以看出前两个loss是额外加入的。
GA的引入可以实现:
(1) 在anchor设置不合理时候,动态引导anchor预测分支得到更好的anchor
(2) 在anchor设置合理时候,可以加速收敛,且可以进一步refine 默认anchor
我觉得本文的GA实现过程非常好,思路清晰,很好理解,可以实现anchor-base混合anchor-free,发挥各自的优势。后续会进行各种对比实验,验证GA在yolo中的引导作用。
机器学习算法全栈工程师
一个用心的公众号


长按,识别,加关注
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助

公众号商务合作请联系 ▶▶▶
