利用python程序抓爬网页,获取城市楼市价格(Python学习实例二)
通过Python语言抓取某房地产网页楼盘数据,用于后期楼盘分析。
1、最后输出:某城市楼盘信息(即excel表格)。
2、页面解析方法:正则表达式 + lxml第三方包
二、详细代码
1、网页解析方法详解(本文只对使用到的两种解析方法进行讲解,别的方法后期使用时再补充)
1)、正则表达式
主要原理是通过正则匹配,查询网页源代码中符合条件的数据,并把其提取出来。
如:下面这段代码,实现了在html这个对象(某个网页的源代码)中匹配有多少给“item-mod”字符串。
其中findall方法,要求匹配完html对象中的全部元素。
h = r"item-mod" #正则代码
h_re = re.compile(h) #生成正则
href_all = h_re.findall(html)·
若需匹配字符串不确定,可以用正则表达式中的特定字符进行代替,如下面代码,通过[0-9]+代替数字进行匹配。
lppriceh = r"[0-9]+"
lppriceh_re = re.compile(lppriceh)
lppriceh_all = lppriceh_re.findall(html)2)、利用lxml包进行解析
该包的解析方法,类似于DOM数据的层次解析。如下图:
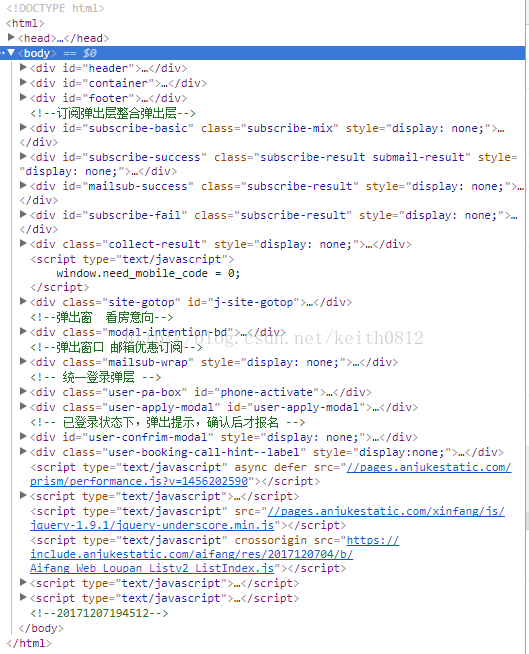
其中层次关系是如下:
第一层:html
第二层:head + body
第三层:head 下面(......)
body 下面(div,div,......)
.......................
代码:
lpnamePath = '/html/body/div[2]/div[2]/div/div[4]/div/div/a/h3/span/text()'
lpnameOBJ = htmlOBJ.xpath(lpnamePath)就是提取html -> body -> div[2](第二个div) -> div[2] ......-> span 标签中的文本。(如下图)
2、xls的写入调用了,xlsxwriter第三方包进行实现
3、完整代码如下:
import requests,re
from lxml import etree
import os
import string
import xlsxwriter
#所需抓去的网页地址
url = 'https://cd.fang.anjuke.com/loupan/all/p'
#结果xlsx保存地址
if os.path.exists(r'C:\cd\demo\result1.xlsx'):
os.remove(r'C:\cd\demo\result1.xlsx)
wb = xlsxwriter.Workbook(r'C:\cd\demo\result1.xlsx)
sheet = wb.add_worksheet()
j=1
#存储表头
name_row = [u'楼盘名',u'楼盘地址',u'楼盘状态1',u'楼盘状态2',u'楼盘价格',u'楼盘面积',u'无信息']
sheet.write(0,0,name_row[0])
sheet.write(0,1,name_row[1])
sheet.write(0,2,name_row[2])
sheet.write(0,3,name_row[3])
sheet.write(0,4,name_row[4])
sheet.write(0,5,name_row[5])
for page in range(1,50):
#获取相应的页数 并 拼接网址
target_url = url + str(page) +'/'
#获取目标网址文档
r = requests.get(target_url)
#获取html代码
html = r.text
#需匹配的正则字符串
h = r"item-mod"
#全文匹配
h_re = re.compile(h)
href_all = h_re.findall(html)
#获取网页中有多少个"item-mod"
length = len(href_all)
#需对解析的网页源代码,进行utf-8格式表面,否则会乱码
urlHTML = r.text.encode("utf-8")
htmlOBJ = etree.HTML(urlHTML)
#减5是因为"item-mod"比网页中。楼盘个数多5个,所以需要减5
for i in range(0,length-5):
#获取楼盘名
lpnamePath = '/html/body/div[2]/div[2]/div/div[4]/div['+str(i+1)+']/div/a/h3/span/text()'
lpnameOBJ = htmlOBJ.xpath(lpnamePath)
sheet.write(j,0,lpnameOBJ[0])
#获取楼盘地址
lpadrPath = '/html/body/div[2]/div[2]/div/div[4]/div['+str(i+1)+']/div/a[2]/span/text()'
lpadrOBJ = htmlOBJ.xpath(lpadrPath)
sheet.write(j,1,lpadrOBJ[0])
#获取楼盘状态
lpztPath = '/html/body/div[2]/div[2]/div/div[4]/div['+str(i+1)+']/div/a[4]/div/i/text()'
lpztOBJ = htmlOBJ.xpath(lpztPath)
print len(lpztOBJ)
#如果部分楼盘信息为空,则显示无信息
if len(lpztOBJ) >= 2 :
sheet.write(j,2,lpztOBJ[0])
sheet.write(j,3,lpztOBJ[1])
elif len(lpztOBJ) < 2 & len(lpztOBJ) >=1:
sheet.write(j,2,lpztOBJ[0])
sheet.write(j,3,name_row[6])
else:
sheet.write(j,2,name_row[6])
sheet.write(j,3,name_row[6])
#获取楼盘价格
#判断是否有价格字段
lppricePath = '/html/body/div[2]/div[2]/div/div[4]/div['+str(i+1)+']/a[2]/p[2]/span/text()'
lppriceOBJ = htmlOBJ.xpath(lppricePath)
if len(lppriceOBJ) <= 0:
lppricePath = '/html/body/div[2]/div[2]/div/div[4]/div['+str(i+1)+']/a[2]/p[1]/span/text()'
lppriceOBJ = htmlOBJ.xpath(lppricePath)
if len(lppriceOBJ) <= 0:
sheet.write(j,4,name_row[6])
else:
sheet.write(j,4,lppriceOBJ[0])
else:
sheet.write(j,4,lppriceOBJ[0])
#获取楼盘面积
squPath = '/html/body/div[2]/div[2]/div/div[4]/div['+str(i+1)+']/div/a[3]/span/text()'
squOBJ = htmlOBJ.xpath(squPath)
if len(squOBJ)-1 <= 0:
sheet.write(j,5,name_row[6])
else:
sheet.write(j,5,squOBJ[len(squOBJ)-1])
j = j + 1
#关闭写入通道
wb.close()注:
1、在xls中写入表头是,在定义中文数组的时候一定要在没有元素前加U,如下:
name_row = [u'楼盘名',u'楼盘地址',u'楼盘状态1',u'楼盘状态2',u'楼盘价格',u'楼盘面积',u'无信息']
2、因为网页页面在不断变化,可能代码在运行中报错,需要根据其报错原因进行修改。