Kaggle Human Protein Atlas 比赛总结—如何闯入Top1%拿到金牌
点击我爱计算机视觉标星,更快获取CVML新技术
本文来自Gary知乎的文章,感谢大佬分享经验。同时Gary也在52CV-竞赛交流群和求职招聘群里,正在寻找实习机会,欢迎进群与大佬交流~

前言
github链接:我们团队的solution
https://github.com/Gary-Deeplearning/Human_Protein
此文第一版作者是我的队友qrfaction,我将在此作下修改和补充。 此次比赛和队友一起拿下了金牌,最终名次11/2172,我的队友分别有
qrfaction https://www.kaggle.com/action
shisu https://www.kaggle.com/shisususu
lihaowei https://www.kaggle.com/lihaoweicvch
chenjoya https://www.zhihu.com/people/chen-zhuo-76-96/activities
hadxu https://www.kaggle.com/hadxu123
chizhu https://www.kaggle.com/chizhu2018
原本是想着积分榜第一的巨佬bestfitting公开方案后写个方案汇总的 但怕是等不到了。。。 这个比赛是对于believe your cv的死教条的一个很好的反面示例和过拟合public leaderboard,那些不会依据客观事实变通只知道Arm,虽最后一刻被bestfitting反超,但在private榜却shake到第12,这就是overfit的后果。
比赛介绍
任务介绍
本次比赛的问题是场景识别 定位的是蛋白质所处位置的识别,例如在细胞液,细胞核里之类的 依输出分所属多标签分类(Multi-lable Classification)
难点及数据介绍
首先一张示例图如下:
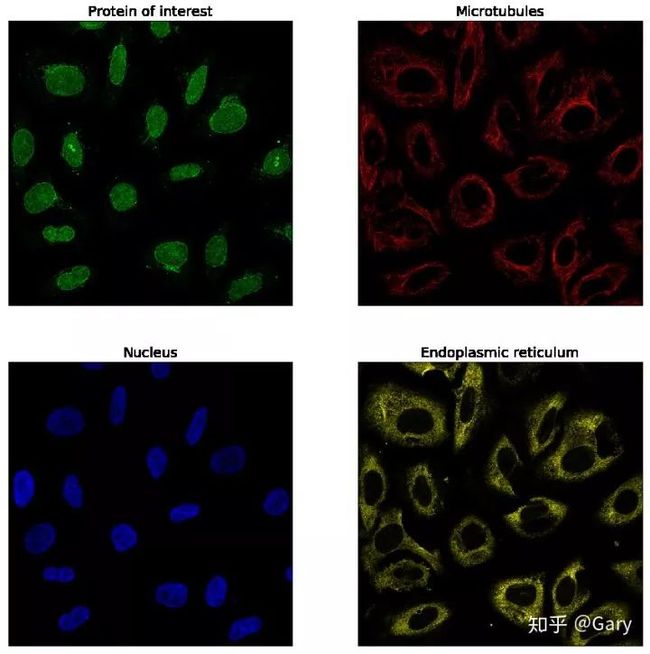
一个样本由四个"通道图"组成(分成四张存储,每个"通道图"单通道),2048*2048大小,官方提供了插值缩小为512大小的数据
外部数据70k(每个"通道图"都是rgb格式)
图片伪重多,然后四个"通道图",id相同但实例不同的情况也很多,如下

难点:
对比我们发现了外部数据总共有4 * 3个通道,而官方数据只有4 * 1个
最麻烦的是伪重问题,伪重造成验证集leak,不能制作一个好的验证集
外部数据处理后加入训练集,要制作一个好的验证集就得跨过两道坎
外部数据无论咋处理总是和测试集分布有些不一样的
训练集里伪重过多,如何保证验证集不leak
这个问题貌似只有bestfitting解决了,从他以往的比赛经验来看,他一直都很擅长这种类型的比赛,真是神人,但是他还没公开方案。。。 上面提到的几个点共同造成的线下val的不可靠,这时候线上比线下可靠,但仍需注意不要过拟合线上。
our solution
以下所有的参数或方法都是我们队经过许多的实验和总结出来的最优版本。
model config1
1. 数据增广(亮度对比度调整,crop_resize,flip,other)
我们总共用了12倍的TTA
亮度对比度主要用于让模型对外部数据和官方数据差异的鲁棒性更好
crop_resize对于显微镜下实例大小方差巨大的情况,带来了较好的线下收益 受限于调试成本,为了不避免数据增广带来的分布偏移问题,于是只选择性的尝试了上述几种,不过也一蒙及中。
def get_augumentor(mode):
if mode =='train':
return iaa.SomeOf(n=(1,6),children=[
iaa.Noop(),
iaa.Sequential([
iaa.Add((-5,5),per_channel=True),
iaa.Multiply((0.8,1.2),per_channel=True)
]),
iaa.Crop(percent=(0,0.15)),
iaa.Affine(shear=(-16, 16)),
iaa.OneOf([
iaa.Affine(rotate=90),
iaa.Affine(rotate=180),
iaa.Affine(rotate=270),
iaa.Fliplr(1),
iaa.Flipud(1),
])
])
elif mode == 'TTA0':
return iaa.Noop()
elif mode == 'TTA1':
return iaa.Flipud(1)
elif mode == 'TTA2':
return iaa.Fliplr(1)
elif mode == 'TTA3':
return iaa.Affine(rotate=90)
elif mode == 'TTA4':
return iaa.Affine(rotate=180)
elif mode == 'TTA5':
return iaa.Affine(rotate=270)
elif mode == 'TTA6':
return iaa.Sequential([
iaa.Crop(percent=0.15),
iaa.Flipud(1)
])
elif mode == 'TTA7':
return iaa.Sequential([
iaa.Crop(percent=0.15),
iaa.Fliplr(1)
])
elif mode == 'TTA8':
return iaa.Sequential([
iaa.Crop(percent=0.15),
iaa.Affine(rotate=90)
])
elif mode == 'TTA9':
return iaa.Sequential([
iaa.Crop(percent=0.15),
iaa.Affine(rotate=180)
])
elif mode == 'TTA10':
return iaa.Sequential([
iaa.Crop(percent=0.15),
iaa.Affine(rotate=270)
])
elif mode == 'TTA11':
return iaa.Crop(percent=0.15)
else:
raise ValueError("aug error")2. Models
res18 (batchsize=64)
res34 (batchsize=32)
bninception (batchsize=32)
inceptionv3 (batchsize=32)
xception (batchsize=24, P40-24G)
se-resnext50(batchsize=24, P40-24G)
其中模型对batchsize大小十份敏感,正确来说是模型对参与batchnorm计算的样本数十分敏感,需用sync-bn或者P40(24G)显存实现。
同时,如果按照榜上的分数来体现,融合有效的模型为res18,xception,se-resnext50,融合无效的模型原来是模型之间的差异性较小。
3. lr schedule
Nadam优化器
阶段性学习率衰减(根据小模型的log而手动设置了衰减的位置)
差分学习率(其中初层用于转换通道的卷积和最后的model head同学习率,中间的backbone学习率小一倍)
model config2
这个方案来自后来加入的队友shisu 只简述一下差异的部分
1. 优化器和schedule的不同
lr schedule
SGD 优化器(init=5e-2, momontum=0.9, weight_decay=4e-4)
cosine lr
2. 数据增强
fair_img_tsfm = Compose([
Flip(p=0.75),
Transpose(),
RandomBrightnessContrast(brightness_limit=(-0.25, 0.1), contrast_limit=(-0, 0)),
])weighted_img_tsfm = Compose([
ShiftScaleRotate(rotate_limit=45, shift_limit=0.1, scale_limit=0.1, p=1,
border_mode=cv2.BORDER_CONSTANT)
])3. custom f1 loss
def f1_loss(predict, target):
loss = 0
lack_cls = target.sum(dim=0) == 0
if lack_cls.any():
loss += F.binary_cross_entropy_with_logits(
predict[:, lack_cls], target[:, lack_cls])
predict = torch.sigmoid(predict)
predict = torch.clamp(predict * (1-target), min=0.01) + predict * target
tp = predict * target
tp = tp.sum(dim=0)
precision = tp / (predict.sum(dim=0) + 1e-8)
recall = tp / (target.sum(dim=0) + 1e-8)
f1 = 2 * (precision * recall / (precision + recall + 1e-8))
return 1 - f1.mean() + loss4. 杂项
res18/34 (96batchsize + float16 + 过采样)
这套方案具有高效率,只需要train 10 epochs即可收敛到最好的点,但需要大的batch_size(f1_loss)
Threshold
在阈值的选取上,我们试过多种固定阈值,和search不同类不同阈值,但根据public榜的分数都没有很好的效果,最终选取了我手调适应public最高分的threshold=0.205(也是怕overfit榜啊,笑哭),但队友们都佛系对待了,没什么关系了。
postprocess
基本是利用了伪重的性质 将测试集中的相似图片的预测进行共享,其中预测选择图片质量较高的那张,约0.002的收益
ensemble
外部数据灰度化和外部数据取高范数的通道两种方案得到了两份数据 两份数据上训练出来的模型进行差异化集成 model config1 和 config2进行集成
遗憾点
根据private榜的分数,我们队最高分竟然是se-resnext50单模五折所获得的[0.562(private), 0.606(public)],不出意料的我们最终选择的肯定是融合多模型的提交。
写到最后
附上其他高质量的分享,个人感觉都不是很新颖
8th place solution
7th place solution
4th place solution
3th place solution
12th place solution
看完这些,会看到有部分LSEP loss,GapNet,autoAugment等花哨的东西 但私以为仍不是重点。 其中各种大小的图进行ensemble才是重点,特别是1024*1024 。。。 正确的数据增强和不要太低的线上
其中一个比较具有通用性的trick,可供大家参考 cnn with image patches (lb 0.619) 图片分成多个patch,将baseline模型对这些块输出分数,拿那些响应最高的patch重新训练一次模型, 相当于一个hard attention。
加群交流
关注机器学习、计算机视觉竞赛,欢迎加入52CV-竞赛交流群,感兴趣的童鞋扫码微信Your-Word拉你入群,(验证信息请注明:竞赛)

喜欢在QQ交流的童鞋可以加52CV官方QQ群:928997753。
(不会时时在线,如果没能及时通过还请见谅)
更多技术干货,详见:
新年快乐!"我爱计算机视觉"干货集锦与新年展望
长按关注我爱计算机视觉

麻烦给我一个好看!