Home Credit信贷逾期风险预测
一、引入基础包及文件
#-*- coding:utf-8 –*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from sklearn.preprocessing import LabelEncoder, MinMaxScaler, Imputer
pd.set_option("display.max_columns", None)
warnings.filterwarnings("ignore")
df_train = pd.read_csv('F:\credit\\application_train.csv')
df_test = pd.read_csv('F:\credit\\application_test.csv')
二、探索清洗数据
查看train文件基本信息,由于特征列数太多,这里就不详细列出了。重要的特征包括姓名、性别、收入、工作形式、工作年限等
print df_train.shape
(307511, 122)
print df_train.head()
print df_train.describe()
查看test文件基本信息,同样不列出详细列
print df_test.shape
(48744, 121)
train中,TARGET值为1的,说明未按时归还贷款,值为0的,说明按时归还贷款
print df_train['TARGET'].value_counts()
0 282686
1 24825
df_train['TARGET'].plot.hist()
plt.show()

显示只有8%左右的人群是未能按时归还贷款的。
# 遍历所有特征,查看特征中的空值
def mis_val_counts(df):
mis_val = df.isnull().sum()
mis_val_pec = 100*df.isnull().sum()/len(df)
missing_val_counts = pd.concat([mis_val,mis_val_pec],axis=1)
missing_val_counts_colnums = missing_val_counts.rename(columns={0: 'Missing Values', 1: '% of Total Values'})
missing_val_counts_colnums = missing_val_counts_colnums[missing_val_counts_colnums.iloc[:,1]!=0].sort_values('% of Total Values').round(1)
return missing_val_counts_colnums
print mis_val_counts(df_train)
DAYS_LAST_PHONE_CHANGE 1 0.0
CNT_FAM_MEMBERS 2 0.0
AMT_ANNUITY 12 0.0
AMT_GOODS_PRICE 278 0.1
EXT_SOURCE_2 660 0.2
DEF_60_CNT_SOCIAL_CIRCLE 1021 0.3
OBS_60_CNT_SOCIAL_CIRCLE 1021 0.3
DEF_30_CNT_SOCIAL_CIRCLE 1021 0.3
OBS_30_CNT_SOCIAL_CIRCLE 1021 0.3
NAME_TYPE_SUITE 1292 0.4
AMT_REQ_CREDIT_BUREAU_MON 41519 13.5
AMT_REQ_CREDIT_BUREAU_WEEK 41519 13.5
AMT_REQ_CREDIT_BUREAU_DAY 41519 13.5
AMT_REQ_CREDIT_BUREAU_HOUR 41519 13.5
AMT_REQ_CREDIT_BUREAU_QRT 41519 13.5
AMT_REQ_CREDIT_BUREAU_YEAR 41519 13.5
EXT_SOURCE_3 60965 19.8
OCCUPATION_TYPE 96391 31.3
EMERGENCYSTATE_MODE 145755 47.4
TOTALAREA_MODE 148431 48.3
YEARS_BEGINEXPLUATATION_AVG 150007 48.8
YEARS_BEGINEXPLUATATION_MODE 150007 48.8
YEARS_BEGINEXPLUATATION_MEDI 150007 48.8
FLOORSMAX_AVG 153020 49.8
FLOORSMAX_MEDI 153020 49.8
FLOORSMAX_MODE 153020 49.8
HOUSETYPE_MODE 154297 50.2
LIVINGAREA_AVG 154350 50.2
LIVINGAREA_MODE 154350 50.2
LIVINGAREA_MEDI 154350 50.2
... ... ...
ELEVATORS_AVG 163891 53.3
ELEVATORS_MEDI 163891 53.3
ELEVATORS_MODE 163891 53.3
NONLIVINGAREA_MEDI 169682 55.2
NONLIVINGAREA_MODE 169682 55.2
NONLIVINGAREA_AVG 169682 55.2
EXT_SOURCE_1 173378 56.4
BASEMENTAREA_MEDI 179943 58.5
BASEMENTAREA_AVG 179943 58.5
BASEMENTAREA_MODE 179943 58.5
LANDAREA_MODE 182590 59.4
LANDAREA_MEDI 182590 59.4
LANDAREA_AVG 182590 59.4
OWN_CAR_AGE 202929 66.0
YEARS_BUILD_MODE 204488 66.5
YEARS_BUILD_MEDI 204488 66.5
YEARS_BUILD_AVG 204488 66.5
FLOORSMIN_MODE 208642 67.8
FLOORSMIN_MEDI 208642 67.8
FLOORSMIN_AVG 208642 67.8
LIVINGAPARTMENTS_MODE 210199 68.4
LIVINGAPARTMENTS_MEDI 210199 68.4
LIVINGAPARTMENTS_AVG 210199 68.4
FONDKAPREMONT_MODE 210295 68.4
NONLIVINGAPARTMENTS_MEDI 213514 69.4
NONLIVINGAPARTMENTS_MODE 213514 69.4
NONLIVINGAPARTMENTS_AVG 213514 69.4
COMMONAREA_MODE 214865 69.9
COMMONAREA_AVG 214865 69.9
COMMONAREA_MEDI 214865 69.9
查看所有文本类型的特征,以及每个特征中唯一值的数量
print df_train.select_dtypes('object').apply(pd.Series.nunique)
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
在文本类别数据中,把类别数量小于等于2的特征经过标签化处理,然后全部进行独热编码处理。
for colnums in df_train:
if df_train[colnums].dtype == 'object':
if len(list(df_train[colnums].unique())) <= 2:
le.fit(df_train[colnums])
df_train[colnums] = le.transform(df_train[colnums])
df_test[colnums] = le.transform(df_test[colnums])
df_train = pd.get_dummies(df_train)
df_test = pd.get_dummies(df_test)
print('Training Features shape: ', df_train.shape)
print('Testing Features shape: ', df_test.shape)
('Training Features shape: ', (307511, 243))
('Testing Features shape: ', (48744, 239))
训练集比测试集多了4列,需要删除对齐
df_train_labels = df_train['TARGET']
df_train, df_test = df_train.align(df_test,join= 'inner',axis=1)
df_train['TARGET'] = df_train_labels
print('Training Features shape: ', df_train.shape)
print('Testing Features shape: ', df_test.shape)
('Training Features shape: ', (307511, 240))
('Testing Features shape: ', (48744, 239))
这里多的一列是TARGET
在之前的describe中发现年龄一栏是负值,故转化为正值
print df_train['DAYS_BIRTH'].describe()
count 307511.000000
mean -16036.995067
std 4363.988632
min -25229.000000
25% -19682.000000
50% -15750.000000
75% -12413.000000
max -7489.000000
df_train['DAYS_BIRTH'] = abs(df_train['DAYS_BIRTH'])
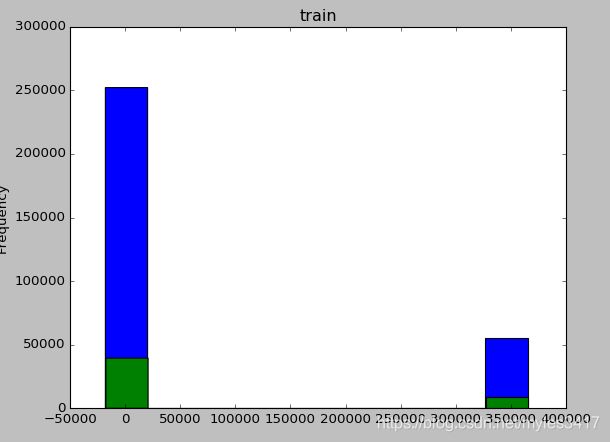
查看工龄特征,发现最大值有异常,超过1000年。
print df_train['DAYS_EMPLOYED'].describe()
count 307511.000000
mean 63815.045904
std 141275.766519
min -17912.000000
25% -2760.000000
50% -1213.000000
75% -289.000000
max 365243.000000
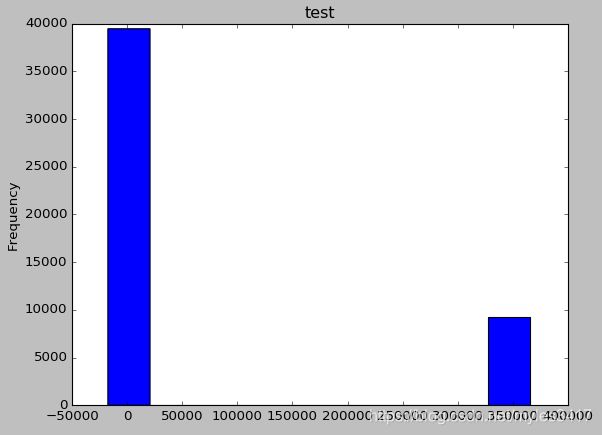
可以看到,test文件有相同的情况
df_train['DAYS_EMPLOYED'].plot.hist()
plt.title('train')
plt.show()
df_test['DAYS_EMPLOYED'].plot.hist()
plt.title('test')
plt.show()
查看具体异常值
a = df_train[df_train['DAYS_EMPLOYED']>50000]['DAYS_EMPLOYED']
print np.unique(a)
[365243]
a = df_test[df_test['DAYS_EMPLOYED']>50000]['DAYS_EMPLOYED']
print np.unique(a)
[365243]
train与test文件,工龄的异常值都是365243,这里先将他们转为na,后面再做处理。
df_train['DAYS_EMPLOYED'] = df_train['DAYS_EMPLOYED'].replace({365243: np.nan})
df_test['DAYS_EMPLOYED'] = df_test['DAYS_EMPLOYED'].replace({365243: np.nan})
三、因子分析
查看各个独立特征与标签之间的相关度,除了三个外部因素之外(文档中未给出外部因素的意义,中年龄相关性较高,其次是工龄与城市评级。
print abs(df_train.corr()['TARGET']).sort_values().tail(10)
NAME_EDUCATION_TYPE_Higher education 0.056593
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_EMPLOYED 0.074958
DAYS_BIRTH 0.078239
EXT_SOURCE_1 0.155317
EXT_SOURCE_2 0.160472
EXT_SOURCE_3 0.178919
TARGET 1.000000
这里年龄是用天表示的,这里加一个AGE特征,用年表示年龄
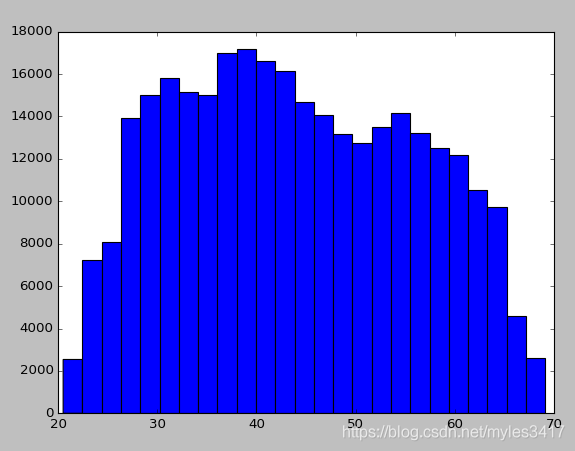
查看年龄分布
df_train['AGE'] = df_train['DAYS_BIRTH']/365
plt.hist(df_train['AGE'],bins=25)
plt.show()
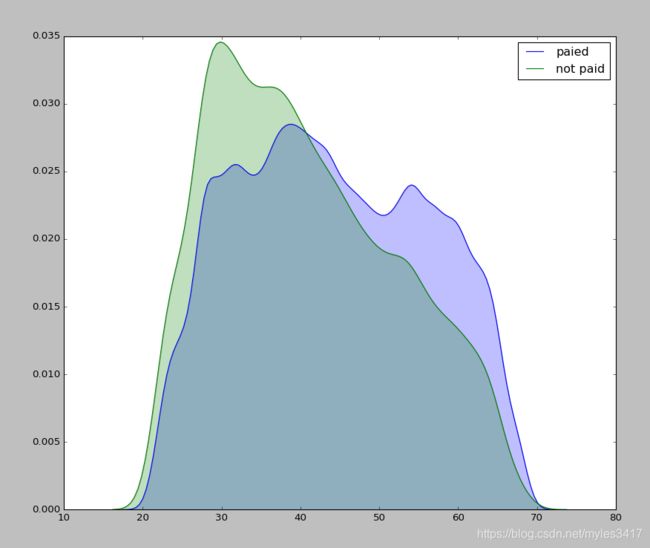
查看年龄与逾期之间的分布,可以看到年轻越小,逾期的概率越大
plt.figure(figsize = (12, 10))
sns.kdeplot(df_train.loc[df_train['TARGET']==0, 'AGE'],label= 'paied',shade=True)
sns.kdeplot(df_train.loc[df_train['TARGET']==1, 'AGE'],label= 'not paid',shade=True)
plt.show()
将年龄分为11个分组,查看各个年龄分组的平均逾期率,可以看到,平均逾期率随着年龄增长而降低
age_data = df_train[['TARGET', 'DAYS_BIRTH', 'AGE']]
age_data['AGE_BINNED'] = pd.cut(age_data['AGE'], bins=np.linspace(20, 70, num=11))
age_group = age_data.groupby('AGE_BINNED').mean()
AGE_BINNED
(65.0, 70.0] 0.037270
(60.0, 65.0] 0.052737
(55.0, 60.0] 0.055314
(50.0, 55.0] 0.066968
(45.0, 50.0] 0.074171
(40.0, 45.0] 0.078491
(35.0, 40.0] 0.089414
(30.0, 35.0] 0.102814
(25.0, 30.0] 0.111436
(20.0, 25.0] 0.123036
四、特征处理
把标签从训练集中除去。之后用IMputer处理空置,用各个特征的中位数填充。随后全部进行归一化处理,最终train与test的特征数一致。
train = df_train.drop('TARGET',axis=1)
train = train.drop('AGE',axis=1)
feature_names = list(train.columns)
test = df_test.copy()
imputer = Imputer(strategy='median')
sclar = MinMaxScaler(feature_range=(0,1))
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(test)
sclar.fit(train)
train = sclar.transform(train)
test = sclar.transform(test)
print train.shape
print test.shape
(307511L, 239L)
(48744L, 239L)
五、建模
使用逻辑斯特线性回归进行预测,并求出每个分类的概率,最后将结果保存在CSV中
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression(C=0.0001, max_iter=100)
log_reg.fit(train, df_train_labels)
pre_values = log_reg.predict_proba(test)[:,1]
results = pd.DataFrame({'ID':df_test['SK_ID_CURR'], 'TARGET':pre_values})
results.to_csv('F:\\credit\predict_values.csv')
print results.head(15)
0 100001 0.087932
1 100005 0.164337
2 100013 0.110671
3 100028 0.076574
4 100038 0.155924
5 100042 0.074731
6 100057 0.107673
7 100065 0.144810
8 100066 0.061533
9 100067 0.121077
10 100074 0.094727
11 100090 0.144906
12 100091 0.140260
13 100092 0.132175
14 100106 0.185343
在结果中,越接近于0,逾期风险越小。