如何fintune torch 中某些层的参数
在torch7微调网络中某些层的参数
定义训练数据
dataset={};
function dataset:size() return 100 end -- 100 examples
for i=1,dataset:size() do
local input = torch.randn(2); -- normally distributed example in 2d
local output = torch.Tensor(1);
if input[1]*input[2]>0 then -- calculate label for XOR function
output[1] = -1;
else
output[1] = 1
end
dataset[i] = {input, output}
end定义网络以及准则
require 'optim'
require 'nn'
mlp = nn.Sequential(); -- make a multi-layer perceptron
inputs = 2; outputs = 1; HUs = 20; -- parameters
mlp:add(nn.Linear(inputs, HUs))
mlp:add(nn.Tanh())
mlp:add(nn.Linear(HUs, outputs))
criterion = nn.MSECriterion()
optimState = {
learningRate =1E-3,
weightDecay = 0,
momentum = 0.8, --0.6,
nesterov = true,
learningRateDecay = 0,
dampening = 0.0
}冻结其他层仅仅训练某些层的参数进行微调
提取相应层的参数
要想仅仅训练特定层的参数,需要将这些层的weights以及gradients提取出来,送入网络训练,下面举个例子,我需要定义这个函数,该函数返回从start_layer到end_layer层之间所有的权重以及梯度。
function get_flatten_parameters(nets,start_layer,end_layer)
local weights,gradients = {}, {}
for i=start_layer,end_layer do
local w, g = nets:get(i):parameters()
for j=1,#w do
table.insert(weights, w[j])
table.insert(gradients, g[j])
end
end
return nn.Module.flatten(weights), nn.Module.flatten(gradients)
end假如我想冻结其它层,仅仅训练第三层的参数,可以直接使用下式得到第三层的参数。
local weights,gradients=get_flatten_parameters(mlp,3,3)
将得到参数后直接送往网络进行训练即可。
训练过程
训练过程与平常的训练相同,这里不再赘述,下面直接上完整代码。
完整过程代码
require "nn"
require 'optim'
dataset={};
function dataset:size() return 100 end -- 100 examples
for i=1,dataset:size() do
local input = torch.randn(2); -- normally distributed example in 2d
local output = torch.Tensor(1);
if input[1]*input[2]>0 then -- calculate label for XOR function
output[1] = -1;
else
output[1] = 1
end
dataset[i] = {input, output}
end
mlp = nn.Sequential(); -- make a multi-layer perceptron
inputs = 2; outputs = 1; HUs = 20; -- parameters
mlp:add(nn.Linear(inputs, HUs))
mlp:add(nn.Tanh())
mlp:add(nn.Linear(HUs, outputs))
criterion = nn.MSECriterion()
optimState = {
learningRate =1E-3,
weightDecay = 0,
momentum = 0.8, --0.6,
nesterov = true,
learningRateDecay = 0,
dampening = 0.0
}
local o_weights,o_gradients= mlp:getParameters()
print('old full parameters',o_weights)
function get_flatten_parameters(nets)
local weights,gradients = {}, {}
for i=3,3 do
local w, g = nets:get(i):parameters()
for j=1,#w do
table.insert(weights, w[j])
table.insert(gradients, g[j])
end
end
return nn.Module.flatten(weights), nn.Module.flatten(gradients)
end
local weights,gradients=get_flatten_parameters(mlp)
print('old sub weights:',weights)
for epoch=1,110 do
local loss=0
function feval(x)
if weights ~=x then weights:copy(x) end
gradients:zero()
for i=1,dataset:size() do
local input = dataset[i][1]
local target = dataset[i][2]
local output = mlp:forward(input)
local f=criterion:forward(output,target)
loss=loss+f
local df = criterion:backward(output,target)
mlp:backward(input,df)
end
print('loss is ',loss)
return loss,gradients
end
optim.sgd(feval,weights,optimState)
end
print('new sub weights:',weights)
local w,g=mlp:getParameters()
print('full new weights:',w)输出参数:
这里为了方便对比,将参数拷贝到excel表格中:
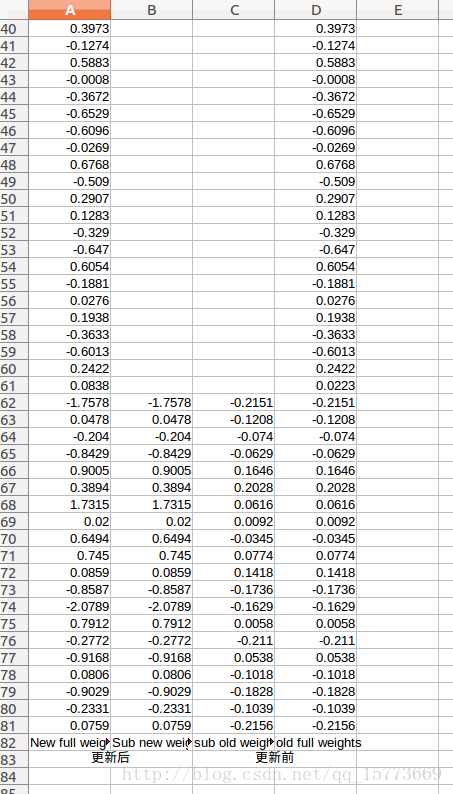
对某些层设置不同的学习率进行微调
设置学习率
对应不同层设置不同的学习率,假如我想将第三层的学习率设置为0.0001,而其他层设置为0.001,示例如下:
local weights, gradients = mlp:parameters()
-- Set the learning rate to 0.001
local learningRates = torch.Tensor(#weights):fill(0.001)
-- Set the learning rate of the second layer to 0.001
learningRates[3] = 0.0001
optimState = {}
for i = 1, #weights do
table.insert(optimState, {
learningRate = learningRates[i],
learningRateDecay = 0.0001,
momentum = 0.9,
dampening = 0.0,
weightDecay = 5e-4
})
end训练网络
注意,这里的训练和上面的方式有点区别,上面的训练与传统方式相同,而这里的训练的时候需要注意每层的权重weights,梯度gradients与相应optimState学习率的对应。
代码如下:
for i=1,#weights do
function feval(x)
return loss,gradients[i]
end
print('loss is ',loss)
optim.sgd(feval,weights[i],optimState[i])
end完整过程代码
require "nn"
require 'optim'
dataset={};
function dataset:size() return 100 end -- 100 examples
for i=1,dataset:size() do
local input = torch.randn(2); -- normally distributed example in 2d
local output = torch.Tensor(1);
if input[1]*input[2]>0 then -- calculate label for XOR function
output[1] = -1;
else
output[1] = 1
end
dataset[i] = {input, output}
end
mlp = nn.Sequential(); -- make a multi-layer perceptron
inputs = 2; outputs = 1; HUs = 20; -- parameters
mlp:add(nn.Linear(inputs, HUs))
mlp:add(nn.Tanh())
mlp:add(nn.Linear(HUs, outputs))
criterion = nn.MSECriterion()
local weights, gradients = mlp:parameters()
local learningRates = torch.Tensor(#weights):fill(0.001)
learningRates[3] = 0.0001
optimState = {}
for i = 1, #weights do
table.insert(optimState, {
learningRate = learningRates[i],
learningRateDecay = 0.0001,
momentum = 0.9,
dampening = 0.0,
weightDecay = 5e-4
})
end
for epoch=1,100 do
local loss=0
mlp:zeroGradParameters()
for i=1,dataset:size() do
local input = dataset[i][1]
local target = dataset[i][2]
local output = mlp:forward(input)
local f=criterion:forward(output,target)
loss=loss+f
local df = criterion:backward(output,target)
mlp:backward(input,df)
end
for i=1,#weights do
function feval(x)
return loss,gradients[i]
end
print('loss is ',loss)
optim.sgd(feval,weights[i],optimState[i])
end
end
至此两种微调方式介绍完毕。