【目标检测系列:十】Anchor Free | GARPN | Region Proposal by Guided Anchoring
CVPR 2019
商汤
Region Proposal by Guided Anchoring
https://github.com/open-mmlab/mmdetection
DCN
anchor
- Dense–>sparse
- fix --> deformable
proposed method
- center of objects
- scales and aspect

With Guided Anchoring, we achieve
- 9.1% higher recall on MS COCO with 90% fewer anchors than the RPN baseline
- We also adopt Guided Anchoring in Fast R-CNN, Faster R-CNN and RetinaNet, respectively improving the detection mAP by 2.2%, 2.7% and 1.2%.
Introduce
anchor策略
- 目前anchor都是人工预设好的( FPN版的Faster-RCNN提前设定,如1:2,1:1,2:1 一种 scale 8,而YOLOv2则通过聚类得到)
存在的问题- anchor需要根据数据不同进行设计,还有IoU阈值设置、超参数设计困难等一系列问题。
- 为了保持较高的召回率,需要大量的anchor,而其中大多数都是负样本(导致正负样本严重失衡)
- 论文提出了一种可学习的anchor机制,由图像本身的语义信息来学习产生得到(主要是位置和上下文信息)
Our method generates sparse anchors in two steps:
- first identifying sub-regions that may contain objects
- then determining the shapes at different locations
Guided Anchoring
- 基于语义特征指导anchor生成。主要思想是定位可能的目标中心点,然后根据中心点设置最优的anchor box。该方法联合预测各个位置可能的目标的中心点以及相应的尺度和宽高比
训练时相比于RPN
- GA-RPN产生的正样本数目更多,而且高IoU的proposal占的比例更大。
- GA-RPN采用更高的阈值、使用更少的样本
使用高质量proposal的前提是根据proposal的分布调整训练样本的分布
GA-RPN相比RPN减少90%的anchor,并且提高9.1%的召回率,将其用于不同的物体检测器Fast R-CNN, Faster R-CNN and RetinaNet,分别提高 检测mAP 2.2%,2.7% ,1.2%
Guided Anchoring
预定义的anchor尺度和宽高比对于不同的数据集和算法需要单独调整。怎样生成稀疏且形状自适应的anchor呢?
首先识别可能包含对象的子区域,然后确定不同位置的尺度和宽高比
将目标的位置和形状用一个四元组表示:(x, y, w, h),其中(x, y)是目标中心坐标,w和h分别是宽和高。则其分布满足:

这种因式分解抓住了两个重要的直觉:
- 给定一幅图像,物体可能只存在于某些区域
- 一个物体的 shape (i.e. scale and aspect ratio) 与它的位置密切相关
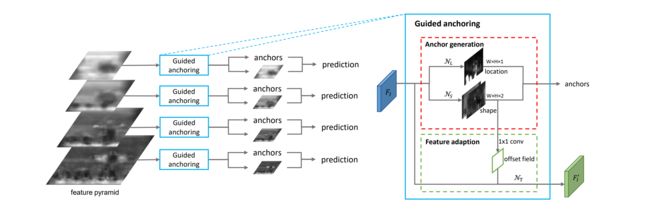
-
Anchor generation module
-
based on a single feature map
-
由 位置预测 和 形状预测 两个分支组成的网络
-
image I I I
-
feature map F I F_I FI
-
在 F I F_I FI 上,位置预测分支生成一个概率图,该概率图指示对象的可能位置,形状预测分支则预测与位置相关的形状
-
通过两个分支,我们通过选择 预测概率高于某个阈值的位置 和 每个选择位置的最可能形状 来生成一组 anchors
-
-
feature adaptation module
Anchor generation
直接预测anchor 的位置和形状(长宽)
生成anchor过程可以分解为两个步骤,anchor 位置预测和形状预测
Location Prediction
-
目标
预测那些区域应该作为中心点来生成 anchor -
conv 1×1,channel 1 , element-wise sigmoid
-
the probability map p ( i , j ∣ F I ) p(i, j|F_I ) p(i,j∣FI) is predicted using a sub-network N L N_L NL
-
二分类
预测是不是物体的中心 -
根据生成的概率图,我们可以通过选择相应概率值高于预定义阈值 ε L ε_L εL 的位置来确定目标可能存在的区域
(这个过程可以过滤掉 90% 的 region ,同时仍然保持相同的 recall ) -
replace the ensuing convolutional layers by masked convolution for more efficient inference
天空、海洋等区域不包括在内,锚点密集分布在人和冲浪板周围。由于不需要考虑这些被排除的区域,为了得到更有效的 inference ,我们用 masked conv 代替了 随后的卷积层

Shape Prediction
- conv 1×1,channel 2 (dw和dh值)
- s是stride,σ是一个尺度系数(文中取8),只需要预测dw和dh,通过下面的方法将训练目标的范围从约[0,1000]缩小到了[-1,1]。
(虽然我们的目标是预测宽度w和高度h的值,但我们从经验上发现,直接预测这两个数字是不稳定的,因为它们的范围很大。)

与传统的基于anchor的方法的不同:
- 每个位置只与动态预测形状的一个 anchor 有关,而不是一组预定义形状的anchor
- 召回率更高,而且能更好的 capture extremely tall or wide objects
Feature adaptation
变形卷积的思想,根据形状对各个位置单独进行转换
-
大一点的anchor对应的感受野应该大一点,小一点的anchor对应的感受野应该小一点,作者想到用可变形卷积的思想。
-
先对每个位置预测一个卷积的offset(1x1卷积,输入为shape prediction)
-
然后根据该 offset field 对原始的 feature map 进行 3x3的可变形卷积 得到 f I ′ f'_I fI′ , 就完成了对feature map的adaption
-
On top of the adapted features,
can then perform further classification and bounding-box regression.
Training
Joint objective
多任务loss进行端到端的训练(除了基本的分类损失和回归损失以外,guided anchor方法还需要学习anchor location和anchor shape,因此还有两个额外的损失函数),损失函数为:
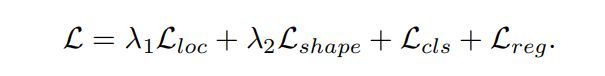
anchor location target
-
要训练 anchor location target
-
对于每个图像,我们需要一个二进制标签映射,其中1 表示 a valid location to place anchor ,否则为0
-
employ ground-truth bounding boxes for guiding the binary label map generation
-
map the ground-truth bounding box ( x g , y g , w g , h g ) (x_g, y_g, w_g, h_g) (xg,yg,wg,hg) to the corresponding feature map scale
and obtain ( x g ′ , y g ′ , w g ′ , h g ′ ) (x'_g, y'_g, w'_g, h'_g) (xg′,yg′,wg′,hg′)


- Center region
中心区域内的 pixels 为正样本 - ignore region
这部分 pixels 既不是正样本也不是负样本,不参与训练 - outside region
这部分 pixels 均为负样本
每一层 feature map 都只针对特定尺度范围内的目标对象
-
assign CR on a feature map only if the center region (positive) ignore region outside region ground truth bounding box feature map matches the scale range of the targeted object
-
大的GT仅在深层特征图作为正例、小的GT仅在浅的特征图上作为正例
-
比如 P2仅训练0到64的GT
如果一个GT的大小在0-64之间,就把P2上的 这个GT对应范围内的 0.2的大小的区域作为CR,然后如果两个框和GT有相交的部分,分配的原则是CR优先于IR 优先于OR -
Focal Loss 来训练location branch。
anchor shape targets
Two steps to determine the best shape target for each anchor
- match the anchor to a ground-truth bounding box
- predict the anchor’s width and height which can best cover the matched ground-truth

-
直接预测anchor 所以没办法分配gt
注意 他是预测anchor而不是预测proposal -
预测anchor所以中心点固定
所以优化的目标就变成了,以这个中心点为中心的任意形状的anchor,然后与这其中iou最大的那个gt,作为这一点的gt就是这个中心点上可能预测出来的无穷种形状的anchor,然后一排gt框,这些anchor和这一排gt框来算iou,iou最大的就是这一点的gt
-
给定 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)
-
我们对 w、h 的一些公共值进行抽样,模拟所有 w、h 的枚举
实验中,抽取9对 ( w , h ) (w,h) (w,h) 样本来估计训练中的vIoU
具体来说,我们采用了9对不同的比例和纵横比用于 RetinaNet
抽样越多,近似就越准确,计算代价就大 -
然后使用 gt 计算这些抽样 anchor 的 IoU
-
并将其最大值 作为 v I o U ( a w h , g t ) vIoU(a_{wh}, g_t) vIoU(awh,gt) 的近似值
-
采用 a variant of bounded iou loss 来优化 shape prediction ,without computing target
-


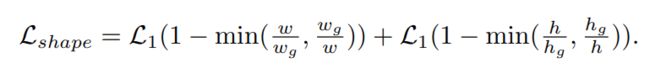
我们发现GA-RPN 能够通过一个微调计划来增强一个经过训练的两阶段检测器
- 给定一个训练过的模型,我们抛弃了 RPN,并使用预先计算的 GA-RPN Proposal 对其进行细化,细化几个epoch(默认为3个epoch)。GA-RPN 建议也用于 Inference 。这种简单的调优方案可以进一步大幅度提高性能,而时间成本只有几个epoch。
Experiment
数据集:MS COCO 2017
backbone:ResNet-50+FPN
image scale:1333×800
σ1 = 0.2,σ2 = 0.5
λ1 = 1, λ2 = 0.1 ( L = λ 1 L l o c + λ 2 L s h a p e + L c l s + L r e g L= λ_1L_{loc}+ λ_2L_{shape}+L_{cls}+L_{reg} L=λ1Lloc+λ2Lshape+Lcls+Lreg to balance the location and shape prediction branches)
batchsize:16
Synchronized SGD over 8 GPUs with 2 images per GPU
12 epoch
lr initial 0.02 / decrease by 0.1 at epoch 8,11

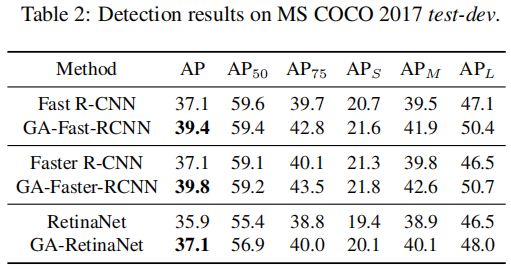

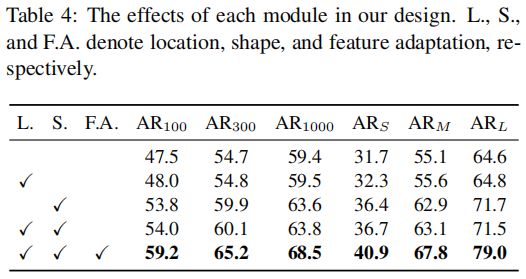
各个模块的对照实验(其中AR 表示每幅图像 proposal的平均召回率,ARS、ARM、ARL是在100 proposal计算的):
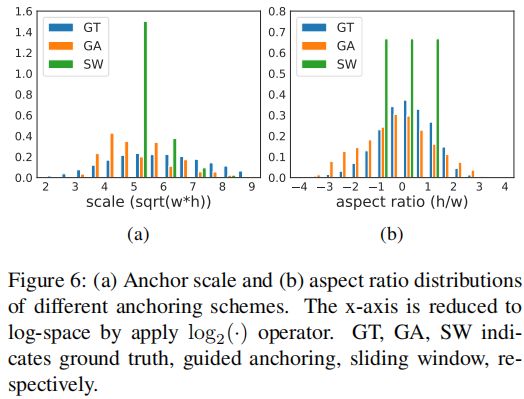
显示了滑窗法、GA以及gt产生的anchor的尺度和宽高比分布情况:

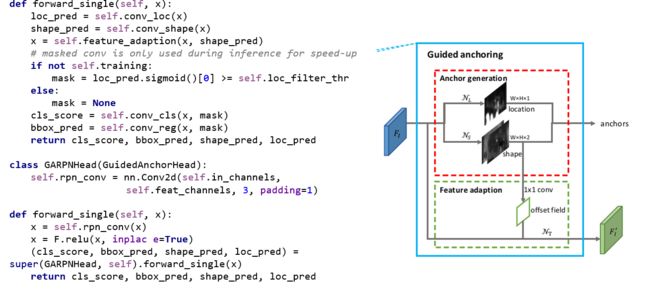
ε L ε_L εL
- 是loc_thr
就是大于多少被判定为有anchor
是 loc分支的阈值
Pytorch

class FeatureAdaption(nn.Module):
offset_channels = kernel_size * kernel_size * 2
self.conv_offset = nn.Conv2d(2, deformable_groups * offset_channels, 1, bias=False)
self.conv_adaption = DeformConv(in_channels,out_channels,kernel_size=kernel_size,
padding=(kernel_size - 1) // 2,deformable_groups=deformable_groups)
self.relu = nn.ReLU(inplace=True)
def init_weights(self):
normal_init(self.conv_offset, std=0.1)
normal_init(self.conv_adaption, std=0.01)
def forward(self, x, shape):
offset = self.conv_offset(shape.detach())
x = self.relu(self.conv_adaption(x, offset))
return x
class GuidedAnchorHead(AnchorHead):
def _init_layers(self):
self.relu = nn.ReLU(inplace=True)
self.conv_loc = nn.Conv2d(self.in_channels, 1, 1)
self.conv_shape = nn.Conv2d(self.in_channels, self.num_anchors * 2, 1)
self.feature_adaption = FeatureAdaption(self.in_channels,self.feat_channels,kernel_size=3,
deformable_groups=self.deformable_groups)
self.conv_cls = MaskedConv2d(self.feat_channels,self.num_anchors * self.cls_out_channels,1)
self.conv_reg = MaskedConv2d(self.feat_channels, self.num_anchors * 4,1)
def forward_single(self, x):
loc_pred = self.conv_loc(x)
shape_pred = self.conv_shape(x)
x = self.feature_adaption(x, shape_pred)
# masked conv is only used during inference for speed-up
if not self.training:
mask = loc_pred.sigmoid()[0] >= self.loc_filter_thr
else:
mask = None
cls_score = self.conv_cls(x, mask)
bbox_pred = self.conv_reg(x, mask)
return cls_score, bbox_pred, shape_pred, loc_pred
class GARPNHead(GuidedAnchorHead):
def _init_layers(self):
self.rpn_conv = nn.Conv2d(self.in_channels, self.feat_channels, 3, padding=1)
def forward_single(self, x):
x = self.rpn_conv(x)
x = F.relu(x, inplace=True)
(cls_score, bbox_pred, shape_pred,loc_pred) = super(GARPNHead, self).forward_single(x)
return cls_score, bbox_pred, shape_pred, loc_pred
Reference
https://zhuanlan.zhihu.com/p/55314193
https://www.cnblogs.com/cieusy/p/10477167.html