分箱统计,数据频率统计,数据分类
分箱统计
方法一:
分箱统计,利用plt直接
| import matplotlib.pyplot as plt import numpy as np import matplotlib
# 设置matplotlib正常显示中文和负号 matplotlib.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文 matplotlib.rcParams['axes.unicode_minus']=False # 正常显示负号 |
方法二:
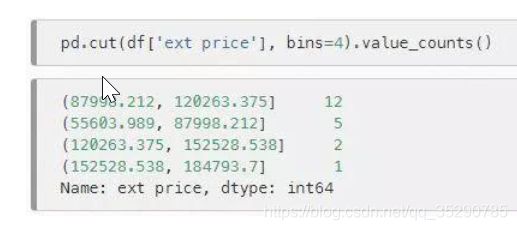
利用函数:
| df.Q1.groupby(pd.qcut(df.Q1,q=2)).count() '''Q1(0.999, 51.5] 50(51.5, 98.0] 50Name: Q1, dtype: int64'''
|
| import pandas as pd
score_list = [63, 67, 73, 84, 88, 97, 70, 85, 68, 96, 95, 60, 83, 70, 77, 86, 83, 94, 100, 82] print(score_list)
bins = [50,70,90,100]
res = pd.cut(score_list, bins) res1 = pd.cut(score_list, bins, labels=["及格","中等","优秀"]) print(res) print("---"*35) print(res1) ################################################# """ [63, 67, 73, 84, 88, 97, 70, 85, 68, 96, 95, 60, 83, 70, 77, 86, 83, 94, 100, 82] [(50, 70], (50, 70], (70, 90], (70, 90], (70, 90], ..., (70, 90], (70, 90], (90, 100], (90, 100], (70, 90]] Length: 20 Categories (3, interval[int64]): [(50, 70] < (70, 90] < (90, 100]] --------------------------------------------------------------------------------------------------------- [及格, 及格, 中等, 中等, 中等, ..., 中等, 中等, 优秀, 优秀, 中等] Length: 20 Categories (3, object): [及格 < 中等 < 优秀] """
|