C++进阶:多线程
C++ 多线程
个人在学习C++的基本STL用法后,虽然对于C++各项功能都有了一些了解,但是却无法形成具体系统影响,导致容易遗忘。这里进行西嘎嘎进阶内容整理,本章主要说明多线程。(本文非原创,东拉西扯各位大佬的东西)
多线程与并发:概念介绍,了解是什么。
hitwengqi的多线程编程:简单粗暴的告诉你怎么实现,但是最后没调好。
Nine-days的多线程编程:内容深化,实例开头,深入了解主要函数。
简介
多线程,也叫并发,即同时发生多件事情,但对于单核计算单元,则是任务切换,由于计算速度较快,可以叫做并发;只有多核计算单元才能实现真正的并发操作。随着技术发展,计算单元的核数和单体计算性能不断提高,为了更充分发挥硬件性能,出现了并发技术,软件并发种类主要分为多进程并发和多线程并发。
并发代码更难理解,尤其是有额外复杂性的多线程代码可能出现更多bug,除非能带来性能提升或模块化需要,否则不建议使用并发。每个线程都会消耗堆区1M左右内存,如4G缓存的32位系统,最多支持4096个线程,没有多余空间用于静态数据和堆数据,通过线程池可以限制线程的数量(比如服务端程序限制连接数目)
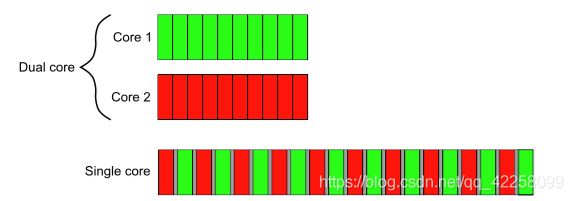
线程和进程的根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位。
**开销差异:**每个进程都有独立的代码和数据空间(程序上下文),程序间的切换有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
**环境差异:**在操作系统中能运行多个进程(程序);而在同一个进程(程序)中可以有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
**内存分配方面:**系统运行时为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
**包含关系:**没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
转自:博主kingdoooom的原文链接
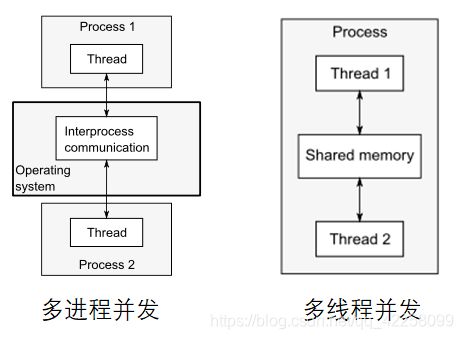
多线程并发
这些进程间可通过正常的进程通信渠道(信号,套接字,文件,管道等)
缺点:1;通信建立较复杂或者慢;2;操作系统需要花时间启动进程和管理进程资源等
优点:1;更容易写安全的并发代码比如Erlang语言 2;可以运行在不同的机器上
多线程并发
线程像轻量级的进程;每个线程互相独立,一个进程的所有线程分享同一个地址空间,多数数据可以共享,比如全局变量,指针和引用可以在线程间传递;
优点:共享地址空间和没有数据保护使得使用多线程程序比多进程程序代价小
实际调用使用
自C++ 11开始通过标准库引入了支持多线程的API,许多命名和结构从boost过来,支持原子操作,实现管理线程、保护共享数据、线程同步等功能。
本篇我们对这部分进行简要的介绍。需要说明的是,C++ 11标准库内部包裹了pthread库,因此,编译程序的时候需要加上-lpthread连接选项。如下所示为简单例子。
1.简单实现
#include 结果显示,多线程直接执行,出现不同步,运行错乱,结果不唯一的问题。
the totol time is hello1...hello...hello...
hello...
hello...
2.在线调用函数传入参数
#include 结果如下所示:调用结果依然乱七八糟
hello in main..
Current pthread id = hello in 20
Current pthread id = hello in 13
Current pthread id = hello in 42
Current pthread id = hello in 53
Current pthread id = hello in 64
the totol time is 2
3.加入pthread_join
#include hello in thread hello in thread hello in thread 10
hello in thread 2hello in thread
43
the totol time is 2
4.线程属性pthread_attr_t参数的设置及join功能的使用
#include hello in threadhello in threadhello in threadhello in thread21
04
hello in thread
3pthread_join get status:0xa
pthread_join get status:0xb
pthread_join get status:0xc
pthread_join get status:0xd
pthread_join get status:0xe
the totol time is 3
5.添加互斥锁
互斥锁是实现线程同步的一种机制,只要在临界区前后对资源加锁就能阻塞其他进程的访问。
#include hello in thread 1
before sum is 0 in thread 1
after sum is 1 in thread 1
hello in thread 0
before sum is 1 in thread 0
after sum is 1 in thread 0
hello in thread 4
before sum is 1 in thread 4
after sum is 5 in thread 4
hello in thread 2
before sum is 5 in thread 2
after sum is 7 in thread 2
hello in thread 3
before sum is 7 in thread 3
after sum is 10 in thread 3
finally sum is 10
the totol time is 6
可以看到,通过锁定段的代码能够逐一执行,实现sum的访问和修改,到这里对于不要求顺序执行的线程已经满足功能需求,通过互斥锁的使用确保关键代码段的顺序执行,保证了结果的正确和稳定,但这是付出时间代价实现的,且线程运行顺序依然混乱。这里使用的是<pthread.h>,在C++11后主要使用的是<thread>。
相关内容说明
通过上述分析,已经实现了关于多线程管理的最基本功能需求,当然还留下一个运行顺序混乱的问题。通过实践我们明确主要函数库包括<thread>、<condition_variable>以及<mutex>这三个,下面让我们带着问题先对其中关键内容进行深入了解。
<thread>
C++11中使用std::thread类创建线程,thread类定义于
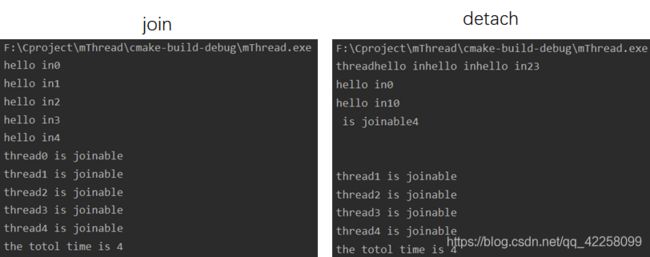
joinable()表示本实例是否还拥有线程管理权,判断是否已关联对象,如果返回true,表明已关联;false表示可关联;
可关联的对象必须进行控制管理,两种措施:
1.detach()解除线程关联,正在执行的线程detach后会自主执行直至结束;
2.join()实现线程关联,一时间只有单线程可工作,其他线程阻塞等待,按顺序执行任务。
以下几种情况,std::thread对象不关联任何线程,默认构造的thread对象、被移动后的thread对象、detach或join后的thread对象。
/* 基于实践的例子进行修改,关于join和detach进行试验,join是成功的*/
void* say_hello(int* args) {
cout << "hello in " << *(args) << endl;
int status = 10 + *(args); //线程退出时的退出信息,status供主程序提取该线程的结束信息
}
int main() {
long t1=clock();
thread tids[NUM_THREADS];
int indexes[NUM_THREADS];
/*设置线程属性参数,这里设定允许join连接,join连接可实现了主程序和线程同步功能*/
for (int i = 0; i < NUM_THREADS; ++i) {
indexes[i] = i;
tids[i]=thread(say_hello,&(indexes[i]));
tids[i].join();//实现关联,只能存在一个
// tids[i].detach();//实现分离,不能同时存在
}
void *status;
for (int i = 0; i < NUM_THREADS; ++i) {
if (tids[i].joinable() == false) {
cout << "thread"<<i<< " is joinable" << endl;
} else {
cout << "thread" << i << "is not joinable" << endl;
}
}
cout << "the totol time is " << clock()-t1 << endl;
}
扩展
线程暂停:实际线程运行需要停顿,但直接停顿会引发很多并发问题,可以使用std::this_thread::sleep_for或std::this_thread::sleep_until。
线程异常:若没有进行join或者detach,会导致线程异常终止而产生析构,如果线程还在运行,则会被强行终止,造成资源泄漏。
获取序号:每个线程都有线程id,可通过get_id获取,如下为源码,贼漂亮。。。
template<class _CharT, class _Traits>
inline basic_ostream<_CharT, _Traits>&
operator<<(basic_ostream<_CharT, _Traits>& __out, thread::id __id) {
if (__id == thread::id())
return __out << "thread::id of a non-executing thread";
else
return __out << __id._M_thread;
}
<mutex>
通过实践我们知道互斥锁的作用了,与join()不同,mutex提供了lock,try_lock,unlock等几个接口,通过mutex可以方便的对临界区域加锁,可以人为细致的控制线程,尽可能提高线程的运行速度。其功能如下:
1.线程在调用lock或try_lock时mutex必须未占用,如果成功,则线程占有mutex对象直到unlock();
2.线程占有mutex时,其他线程若试图要求mutex的所有权,将阻塞(对于 lock 的调用)或收到false返回值(对于 try_lock );
3.mutex和thread一样,不可复制(拷贝构造函数和拷贝赋值操作符都被删除),而且,mutex也不可移动(move)。
lock(),互斥量加锁,如果互斥量已被加锁,线程阻塞,若本线程已占用互斥量则死锁。
try_lock(),尝试加锁,如果互斥量未被加锁,则执行加锁操作,返回true;如果互斥量已被加锁,返回false,线程不阻塞。
unlock(),解锁互斥量。
/*
现在基于mutex进行修改,然而结果同detach,进而可以明白,其作用只针对该段代码域实现各线程的不干扰运行,相当于独木桥过河,除了这个地方其他地方都各线程自行其是,包括计算、cout等,自己尝试可以更有印象。
*/
#include C++11根据mutext的属性提供四种的互斥量,分别是
1.std::mutex,最常用,普遍的互斥量(默认属性);
2.std::recursive_mutex,允许同一线程使用recursive_mutex多次加锁-解锁,如果加锁解锁不配套会死锁。
3.std::timed_mutex,在mutex上增加了时间的属性,增加了成员函数try_lock_for(),try_lock_until(),分别接收一个时间范围,在给定的时间内如果被加锁,超过时间阈值,返回false。
4.std::recursive_timed_mutex,增加递归和时间属性
mutex的lock和unlock必须成对调用,lock之后忘记调用unlock将是非常严重的错误,再次lock时会造成死锁。RAII式的栈对象能保证在异常情形下mutex可以在lock_guard对象析构被解锁。
std::lock_guard(有作用域的mutex,让程序更稳定,防止死锁)
std::lock_guard是mutex封装器,通过便利的RAII机制在其作用域内占有mutex,对象构建时传入mutex,会自动对mutex加锁,直到离开类的作用域,析构时完成解锁,不需要程序员手动调用lock和unlock对mutex进行上锁和解锁操作。lock_guard对象并不负责管理mutex对象的生命周期,只是简化了上锁-解锁操作,即在某个lock_guard对象的生命周期内,所管理的锁对象会一直保持上锁;而lock_guard的生命周期结束之后,它所管理的锁对象会被解锁。
unique_lock与lock_guard功能近似,通过对lock和unlock进行一次薄的封装,实现自动unlock的功能。但是std::unique_lock要更灵活,比如std::unique_lock维护了互斥量的状态,可通过owns_lock()访问,当locked时返回true,否则返回false。其代价是占用空间相对更大一点且相对更慢一点。std::unique_lock的构造函数的数目相对来说比std::lock_guard多,其中一方面也是因为 std::unique_lock 更加灵活,从而在构造 std::unique_lock 对象时可以接受额外的参数。
/*
一般需要加锁的代码段,我们用{}括起来形成一个作用域,括号的开端创建lock_guard对象,把mutex对象作为参数传入lock_guard的构造函数即可,比如上面的例子加锁的部分,我们可以改写如下,结果同mutex小节结果,
*/
void* say_hello(int* args, mutex* mtx) {
{
lock_guard<mutex> guard(*mtx);
cout << "hello in " << *(args) << endl;
}
/*进入作用域,临时对象guard创建,获取mutex控制权(构造函数里调用了mutex的lock接口),离开作用域,临时对象guard销毁,释放了mutex(析构函数里调用了unlock接口),这是对mutex的更为安全的操作方式(对异常导致的执行路径改变也有效),大家在实践中应该多多使用*/
}
int main() {
long t1=clock();
mutex mtx;
thread tids[NUM_THREADS];
int indexes[NUM_THREADS];
/*设置线程属性参数,这里设定允许join连接,join连接可实现了主程序和线程同步功能*/
for (int i = 0; i < NUM_THREADS; ++i) {
indexes[i] = i;
tids[i]=thread(say_hello,&(indexes[i]),&mtx);
// tids[i].join();//实现关联,只能存在一个
tids[i].detach();//实现分离,不能同时存在
}
void *status;
for (int i = 0; i < NUM_THREADS; ++i) {
// if (tids[i].joinable() == false) {
// cout << "thread"<
// } else {
// cout << "thread" << i << "is not joinable" << endl;
// }
}
cout << "the totol time is " << clock()-t1 << endl;
}
条件变量<condition_variable> 别问,问就是不会,等我会了再写例子。
condition_variable,当互斥操作不够用时引入,预防死锁,比如,线程可能需要等待某个条件为真才能继续执行,而一个忙等待循环中可能会导致所有其他线程都无法进入临界区,使得条件为真时发生死锁,使用condition_variable对象可以唤醒等待线程从而避免死锁。
notify_one()用于唤醒一个线程,notify_all() 则是通知所有线程。
conditon_variable也可以实现线程同步,设定延时使同步。
线程等待在多线程编程中使用非常频繁,经常需要等待一些异步执行的条件的返回结果。C++11中的std::condition_variable就像Linux下使用pthread_cond_wait和pthread_cond_signal一样,可以让线程休眠,直到被唤醒。
想要看例子的请翻大佬Nine-days的多线程编程的小节-thread使用。没看懂。。
小结
通过以上操作我们简单知道如何控制线程的运行,现在对其内容进行概括总结:
1.线程管理是普遍无序的。虽然在声明时,各线程有明确的先后次序,但是在执行过程中,收工况影响,会出现运行次序的随机调动,如同赛跑一样,虽然可能彼此之间存在一定前后顺序关系,但是依然无法确认最终名次。可以通过join进行阻塞管理,通过付出时间代价提高线程有序性,相当于强行开辟多合一汇流赛道,之前各线程自由发挥,进了汇流赛道,名次固定。
2.mutex和condition_variable只能干预控制,无序自由的线程是最快的,干预越多时间代价越大,mutex合condition_variable实现精细线程管理,不同方法效果不同。同样还有原子操作但是目前未感觉其与互斥量的优势和区别,就不做多说,等以后了解后再专题分析。
扩展:原子操作
在新标准C++11,引入了原子操作的概念,原子操作更接近内核,并通过这个新的头文件提供了多种原子操作数据类型,例如,atomic_bool,atomic_int等等,如果我们在多个线程中对这些类型的共享资源进行操作,编译器将保证这些操作都是原子性的,也就是说,确保任意时刻只有一个线程对这个资源进行访问,编译器将保证,多个线程访问这个共享资源的正确性。从而避免了锁的使用,提高了效率。
#include 通过前期简单了解,原子操作更多涉及硬件,包括CPU算力以及内存等,目前这块本人并不熟悉,就不做分析了。