论文学习笔记 - CenterTrack
『写在前面』
CenterNet ( Objects as points ) 作者将CenterNet检测器推广到目标跟踪领域的成果,效果极佳,思路清奇。
文章标题:《Tracking Objects as Points》
作者机构:Xingyi Zhou等, UT Austin.
原文链接:https://arxiv.org/abs/2004.01177
相关repo:https://github.com/xingyizhou/CenterTrack
目录
摘要
1 介绍
2 相关工作
3 预备知识
4 CenterTrack
问题描述
4.1 Tracking-conditioned detection
4.2 Association through offsets
4.3 在视频数据上进行训练
4.4 在静态图片上训练
5 分解研究
5.1 两个主要的技术改进点的提升效果研究
5.2 使用noisy heatmap进行训练及使用静态图像进行训练
摘要
现有的主流目标跟踪方法大多遵循 tracking-by-detection的思路。在本文中,作者提出了一种新的跟踪模型结构CenterTrack,它通过在一个图像对上执行检测,并结合先前帧的目标检测结果来估计当前帧的目标运动情况。CenterTrack简单、在线(不需要引入未来信息),同时能达到实时性(在MOT17上可达到22FPS)。
1 介绍
CenterTrack输入是一对图像,以及根据首帧图像的检测结果渲染出的heatmap。模型会输出一个从当前对象中心到前一帧对象中心的偏移向量,并且这个偏移向量将作为中心点的一个附加属性来学习,从而只增加了很少的额外计算量。在有了中心点及偏移量以后,仅靠贪婪匹配策略即可将当前帧的对象与前一帧的相应对象建立起联系。
Tracking as points简化了传统跟踪方案的两个关键步骤:一是跟踪条件检测,因为过去帧中的每个对象都用单个点来表示,它的历史信息包含在它对应的heatmap中,模型可以从中直接提取相关信息;二是时间上的对象关联,通过预测出的位移向量可以很方便地将前后帧中相同的对象建立起联系。
CenterTrack的输入端将首帧的检测结果对应的heatmap也作为了输入,因为相邻帧间相关性往往较高,这样的做法会促使模型简单地复制先前的预测结果而拒绝做更多对跟踪有利的预测,因此作者在训练过程中加入了很多看起来极为激进的增强策略,试验结果表明,这些数据增强方法效果极佳。
在模型训练上,CenterTrack有一个很大的优点是,其既可以在有标注的视频序列上训练,也可以通过对静态图像做数据增强来进行训练。
2 相关工作
传统跟踪方法(Tracking-by-detection)两个缺点:
(1)在建立跟踪联系过程中仅联合高层数(比如框位置等),会丢失图像外观信息,或者还需要有一个计算量比较大的特征提取器;
(2)检测和跟踪是分开进行的
CenterTrack的好处:一是目标的联合与检测一同进行学习,同时还将前帧的跟踪结果作为输入,从而帮助模型恢复被遮挡和中断的目标;二是CenterTrack将跟踪的预测作为点的附加特征,这样网络可以推理并匹配处在画面里的所有目标,即使它们没有存在重叠部分。
3 预备知识
关于CenterNet相关的理论知识,请参考:https://blog.csdn.net/sinat_37532065/article/details/104856366
4 CenterTrack
CenterTrack中将跟踪看做一个从局部角度观察的问题,比如当一个目标离开画面或被遮挡又重新出现时,跟踪模型不会记住它,而是会重新给它分配一个新的ID. 因此,CenterTrack将跟踪建模成了一个在连续帧之间传递检测结果ID的问题,而没有考虑如何给时间上有较大间隔的对象重新建立联系的问题。
问题描述
在时间 ,给定当前帧
,给定当前帧![]() 及上一帧
及上一帧![]() ,以及前一帧的跟踪到的所有目标
,以及前一帧的跟踪到的所有目标![]() ,其中每个目标包含的信息有其位置、大小、置信度得分、编号ID。我们的目标是检测和跟踪当前帧中的目标,得到
,其中每个目标包含的信息有其位置、大小、置信度得分、编号ID。我们的目标是检测和跟踪当前帧中的目标,得到![]() ,并为每个对象分配ID(如果该对象从上一帧就开始出现,那分配的ID要求是一致的)。
,并为每个对象分配ID(如果该对象从上一帧就开始出现,那分配的ID要求是一致的)。
有两个挑战:一是如何在每一帧中找出所以的对象,甚至包含被遮挡的对象;二是如何在时间上为这些对象建立联系。解决办法是:
Tracking-conditioned detection:利用先前帧的检测结果改善当前帧的检测;
Association through offsets:在时间轴上建立检测结果之间的联系

4.1 Tracking-conditioned detection
作为一个检测器,CenterNet已经能够给出跟踪所需的很多信息,如位置、大小和得分。但是它不具备预测未直接出现在当前帧的目标的功能,所以在CenterTrack中,将当前帧及其上一帧图像共同输入模型当中,旨在帮助网络估计场景中对象的变化并根据上一帧图像提供的线索恢复当前帧中可能未观察到的对象。
此外,CenterTrack还将上一帧图像的检测结果添加到输入中,具体做法是根据上一帧的检测结果绘制一张单通道heatmap,其中peak位置对应目标中心点,并使用与训练CenterNet过程中相同的高斯核渲染办法(根据目标大小调整高斯参数)进行模糊处理,为了降低误报概率,作者只对检测结果中得分高于一定阈值的目标进行渲染(即得分低的目标不会体现在新生成的heatmap上)。
综上,CenterTrack与CenterNet模型结构几乎相同,但是输入通道多了4个:上一帧图像(3 channels)、渲染出的heatmap(1 channel)。
4.2 Association through offsets
为了能够在时间上建立检测结果直接的联系,CenterTrack添加了2个额外的输出通道,用于预测一个2维的偏移向量,即描述的是各对象在当前帧中的位置相对于其在前一帧图像当中的位置的X/Y方向的偏移量。此处的训练监督方式与CenterNet中对目标对象长宽或中心偏移情况的部分训练方式相同。
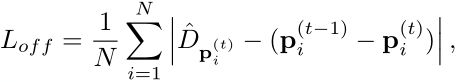
在有了各对象的位置,及其对应的偏移情况后,使用简单的贪婪匹配策略即可建立起对应目标在帧间的联系。
4.3 在视频数据上进行训练
概况来说,CenterTrack = CenterNet + 4 * Input-channels + 2 * output-channels.
CenterTrack本质上也是一个检测器,所以其训练方法也和训练CenterNet类似,也就意味着我们可以从一个预训练好的CenterNet上finetune出一个CenterTrack。具体做法是,首先根据常规做法,在当前视频数据上训练一个CenterNet模型,然后从它当中拷贝所有权重,并为新添加的部分结构进行随机初始化参数,而后遵循CenterNet的训练方法进行训练,并且额外加上对偏移量分支的监督。
在训练CenterTrack过程中一个最主要的挑战是如何生成一张接近真实情况的tracklets heatmap的问题:在模型推理期间,tracklets heatmap是根据模型预测结果渲染而来的,可能会存在数量不定的missing tracklets、错误定位的目标以及还可能有误检的目标存在。而这些情况在Ground Truth中是不存在的,也就是说如果我们直接利用基于Ground Truth渲染出的heatmap,是无法模拟这种实际情况的,也就会导致模型效果不佳。
上述问题解决办法是在训练过程中通过一些trick来模仿这些test-time error,具体而言:
1. 在前一帧的预测结果上,对各个检测目标点进行高斯扰动(模拟“目标错误定位”的情况,超参数![]() );
);
2. 在Ground Truth目标中心附近以一定概率随机渲染出一些虚假的峰值(模拟“误检”的情况,超参数![]() );
);
3. 以一定概率,随机去除掉一些检测结果(模拟“漏检”的情况,超参数![]() )。
)。
此外,在实际训练过程中,先前帧![]() 不是必须是前一帧,它可以是相同视频序列中的其他帧。通过这种增强的方式,可以规避掉模型对视频帧率的敏感性。在CenterTrack中,从与当前帧间隔小于一定范围(比如前后3帧)的帧中来随机选择
不是必须是前一帧,它可以是相同视频序列中的其他帧。通过这种增强的方式,可以规避掉模型对视频帧率的敏感性。在CenterTrack中,从与当前帧间隔小于一定范围(比如前后3帧)的帧中来随机选择![]() .
.
4.4 在静态图片上训练
如果没有带标注的视频数据,我们还可以使用静态图像来训练CenterTrack:通过随机缩放和变换当前图像,来生成先前帧,从而达到模拟目标运动的目的。实验证明这一trick很有效,几乎不会影响跟踪模型的效果。
5 分解研究
5.1 两个主要的技术改进点的提升效果研究
CenterTrack为了解决跟踪问题,设计了两个关键的思路:跟踪条件的检测(Sec. 4.1)和目标偏移量的预测(Sec. 4.2).
为了分析效果,作者做了3个baseline模型:
Detection only:顾名思义,只使用原版CenterNet进行检测,跟踪通过目标2D距离来匹配对象;
Without offset:使用CenterTrack中对输入端的改进,但不使用预测出的offset,目标的匹配还是通过距离来计算;
Without heatmap:在CenterTrack的基础上,去掉tracklets heatmap的输入,但是输出还是会预测offset,目标的匹配基于预测得到的偏移量结合贪婪匹配的策略进行。
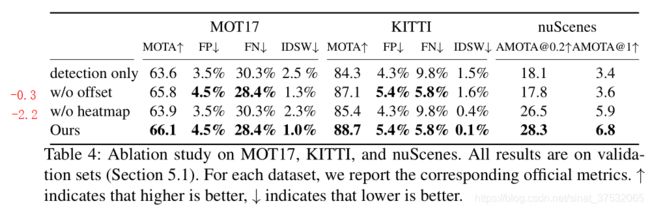
最终实验效果如上图,可以看出,如果不添加tracklets heatmap作为附加输入,效果会大打折扣。虽然看起来不使用offset效果下降不明显,但是这是因为做实验用的这些数据集帧率相对较高,换句话说就是目标的运动不会过于剧烈,这会弱化offset的表现,可能换一个帧率低些的数据集,或者目标运动速度快的,可能offset的作用会更加明显。
5.2 使用noisy heatmap进行训练及使用静态图像进行训练
主要是想分析一下对tracklets heatmap做增强的必要性,个人认为这是CenterTrack能取得不错效果的最关键的一环。
同时还对仅使用静态图像训练的情况作了对比,可以看出与用视频序列进行训练相比,几乎没有差别。