理解目标检测中的老大难:小目标检测
文章一:
Stitcher: Feedback-driven Data Provider for Object Detection ,该文发明了一种简单方法改进业界老大难:小目标检测问题。

该文作者来自中科院自动化所、旷视科技、香港中文大学,孙剑老师和贾佳亚老师都为论文的共同作者。
大多数目标检测算法在小目标检测上都有显著的性能下降,作者通过统计分析发现,这与训练阶段小目标对损失函数的贡献小有关系,Feedback-driven Data Provider 顾名思义,作者提出了一种基于训练时反馈然后提供数据的方式改进训练,而制作新数据的方式也很简单,就是把图像拼接起来 Stitcher。
请看下图,这是Faster RCNN算法在COCO 数据集上训练时小目标对Loss贡献比例,baseline方法来自小目标的Loss贡献比例小于10%,而该文发明的方法 Stitcher 则让其更加均衡。

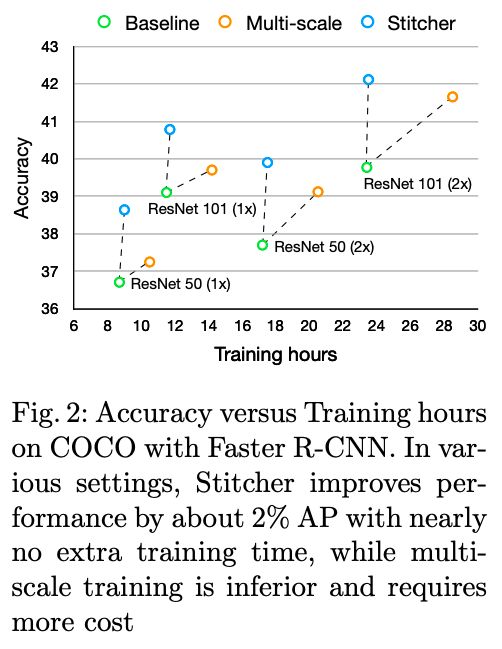
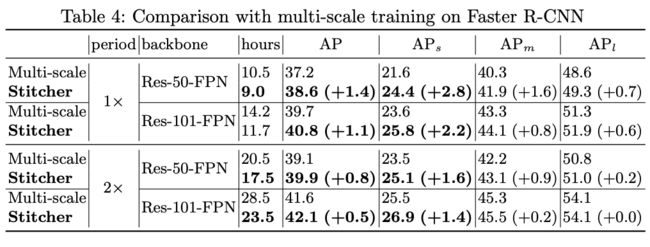
相比于业界已有的多尺度训练的方法,Stitcher几乎不增加训练时间,但取得的精度提升却更加可观,如下图:
下表为在COCO数据集上大中小三种目标的统计,小目标占整个标注框的41.4%,但仅出现在52.3%的图像中,可见小目标数量很多,且在图像中出现较集中。

因为小目标在图像中出现的比例低,那么在训练时缺少小目标时如何制作小目标数据作为补充呢?将正常图像中的目标resize小一点,其纹理依然清晰类别仍然可辨,作者通过将多幅正常图像resize并拼接的方式制作数据集,这就是Stitcher的由来。

算法流程
在训练时,根据小目标对loss的贡献比率确定是否要在下一次迭代提供给网络拼接的图像训练,如下图:


图中是将4幅正常图像拼接resize后拼接为一幅新的训练图像。
当小目标对Loss的贡献比例小于一定阈值,即将拼接的图像加入下一次迭代的训练集。
实验结果
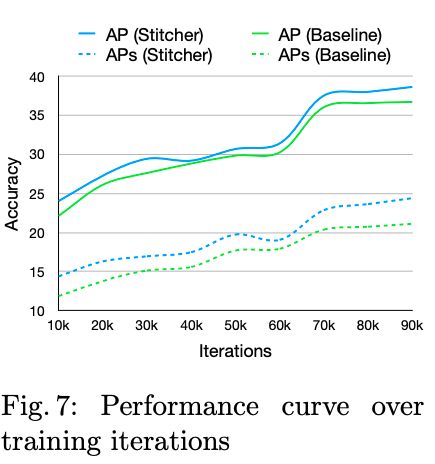
使用上述看似简单的方法,却能带来非常稳固的性能提升,下图为训练Faster R-CNN 随着迭代次数增加AP的变化,
为了验证方法的有效性,作者使用不同的目标检测算法(Faster R-CNN、RetineNet)、骨干网(Res-50-FPN、Res-101-FPN)做了实验,只要加上Stitcher 就能提高模型精度,而且不仅对小目标有效,对大、中目标也有效!当然从结果看,小目标获得的精度增益更大。
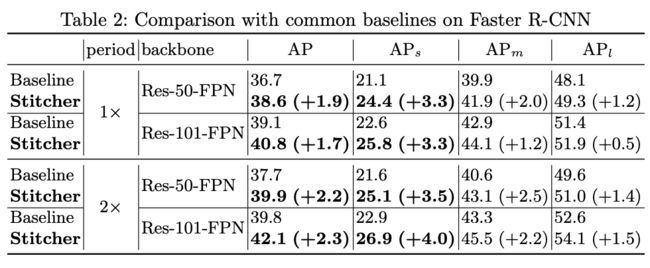
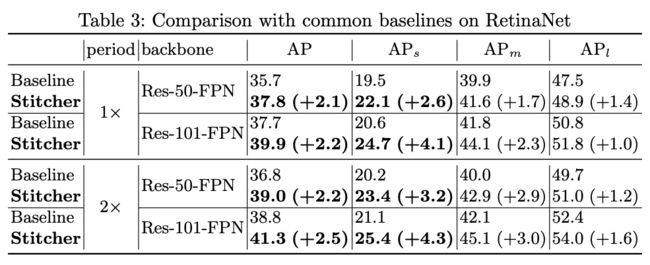
作者又将其与其他处理小目标检测的常见方法比如多尺度训练、SNIP、SNIPER进行了比较,Stitcher 在提高精度更多的情况下,几乎不增加时间代价,当然是更好的选择。

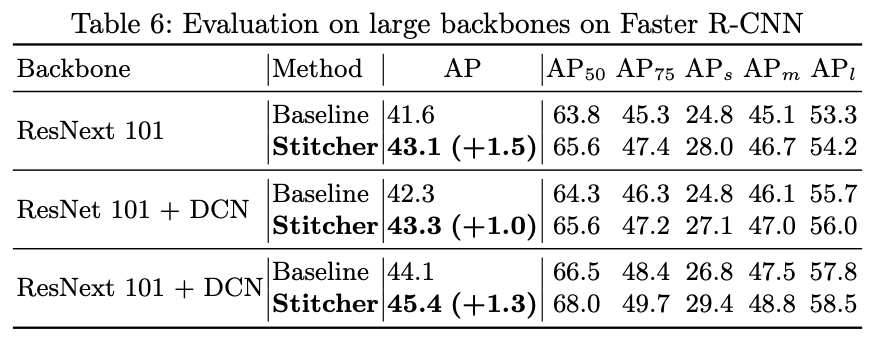
在大的骨干网上也获得了精度增益:
更长的训练周期,Stitcher持续获得精度增益,而baseline在训练周期达到6时精度开始下降,如下表:

换到 PASCAL VOC数据集,依然能涨点:

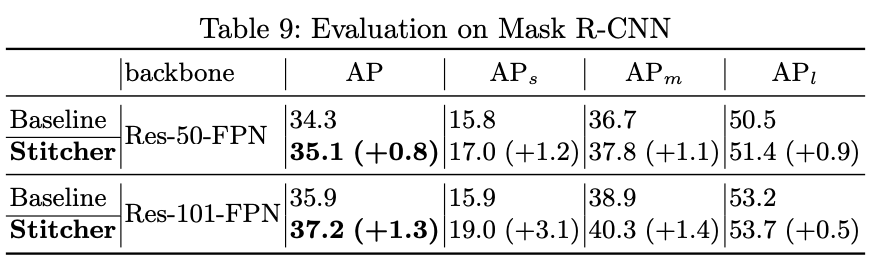
值得一提的是,Stitcher不仅适用于目标检测,在实例分割的对比实验中,同样获得了不晓得精度提升。如下表:
总之,作者从训练样本对Loss贡献不平衡的角度思考小目标检测问题,通过设计Loss反馈驱动的机制和图像拼接的方法显著改进了小目标检测,其稳固的精度增益表明,该机制可以成为目标检测算法训练的通用组件。
论文地址:
https://arxiv.org/abs/2004.12432
作者称代码将开源。
文章二:
方法来自于:《Augmentation for small object detection》
https://arxiv.org/pdf/1902.07296.pdfarxiv.org
什么是小物体?

在COCO数据集,其给出了小目标、中等目标、大目标的区分定义,如上图。主要是看目标框的大小。
小物体的检测效果怎么样?
COCO上state-of-art目标实例分割算法的性能情况:
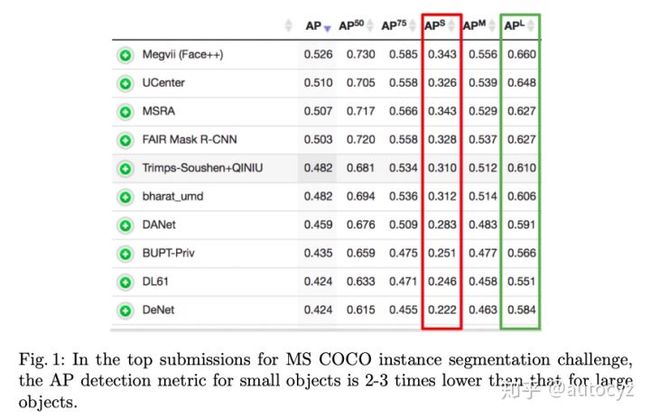
看上图,可以发现小目标的检测性能 几乎只有大目标 的一半。因此,小目标的检测性能成了很多任务、算法的瓶颈所在。
分析:为何小目标的检测性能不好
直观上,当我们看到一幅时,我们首先关注的是图像中比较醒目的图像,一般的,这些醒目的图像往往在图中所占的比例比较大。而小目标目标往往被我们忽略。数据集中也存在这种情况,很多图像中包含的小物体并没有被标出。另外,小目标所在区域较小,在提取特征的过程中,其提取到的特征非常少,这些都不利于我们对小目标的检测。
下面从量化的角度来分析一下为何小目标不好做。

上图是在COCO上的统计图,可以发现COCO中,小目标的个数还是很高的,占到了41.43%,但是含有小目标的图片只有51.82%,大目标(large)所占比例为24.24%,但是含有大目标的图像却有82.28%。这说明有一半的图像是不含小目标的,大部分的小目标都集中在一些少量的图片中。这就导致在训练的过程中,模型有一半的时间是学习不到小目标的特性的。
另外,对于小目标,平均能够匹配的anchor数量为1个,平均最大的IoU为0.29,这说明很多情况下,有些小目标是没有对应的anchor或者对应的anchor非常少的,且即使有对应的anchor,他们的IoU也比较小,平均最大的IoU也才0.29。
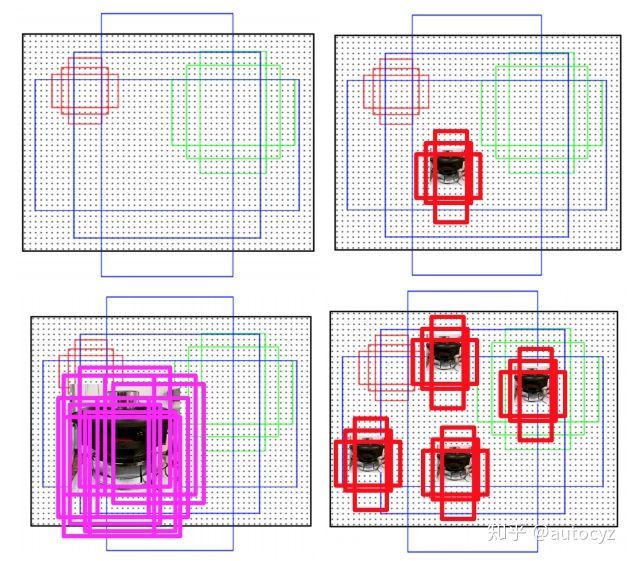
如上图,左上角是一个anchor示意图,右上角是一个小目标所对应的anchor,一共有只有三个anchor能够与小目标配对,且配对的IoU也不高。左下角是一个大目标对应的anchor,可以发现有非常多的anchor能够与其匹配。匹配的anchor数量越多,则此目标被检出的概率也就越大。
基于上述分析,我们可以得到小目标不好检测的两大原因:
1)数据集中包含小目标的图片比较少,导致模型在训练的时候会偏向medium和large的目标。
2)小目标的面积太小了,导致包含目标的anchor比较少,这也意味着小目标被检测出的概率变小。
改进方法:
1)对于数据集中含有小目标图片较少的情况,使用过度采样(oversample)的方式,即多次训练这类样本。
2)对于第二类问题,则是对于那些包含小物体的图像,将小物体在图片中复制多分,在保证不影响其他物体的基础上,人工增加小物体在图片中出现的次数,提升被anchor包含的概率。
如上图右下角,本来只有一个小目标,对应的anchor数量为3个,现在将其复制三份,则在图中就出现了四个小目标,对应的anchor数量也就变成了12个,大大增加了这个小目标被检出的概率。从而让模型在训练的过程中,也能够有机会得到更多的小目标训练样本。
具体的实现方式如下图:图中网球和飞碟都是小物体,本来图中只有一个网球,一个飞碟,通过人工复制的方式,在图像中复制多份。同时要保证复制后的小物体不能够覆盖该原来存在的目标。

具体性能的提升文章做了较多的实验对比,可以参看论文。