mysql数据库存储类型及存储引擎分析
于是根据自己的了解以及网上查阅的一些相关资料,做了如下总结:
3.MySQL单表大约在2千万条记录(4G)下能够良好运行,经过数据库的优化后5千万条记录(10G)下运行良好.
首先,我们来分析一下mysql的数据类型,因为MySQL中定义数据字段的类型对你数据库的优化是非常重要的。而MySQL支持多种类型,但大致我们可以分为三类:
①数值
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| tinyint | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| smallint | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| mediumint | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| int或integer | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| bigint | 8 字节 | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| float | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| double | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| decimal | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
| 类型 | 大小 (字节) |
范围 | 格式 | 用途 |
|---|---|---|---|---|
| date | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| year | 1 | 1901/2155 | YYYY | 年份值 |
| datetime | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| timestamp | 4 | 1970-01-01 00:00:00/2037 年某时 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
| 类型 | 大小 | 用途 |
|---|---|---|
| char | 0-255字节 | 定长字符串 |
| varchar | 0-65535 字节 | 变长字符串 |
| tinyblob | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| tinytext | 0-255字节 | 短文本字符串 |
| blob | 0-65 535字节 | 二进制形式的长文本数据 |
| text | 0-65 535字节 | 长文本数据 |
| mediumblob | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| mediumtext | 0-16 777 215字节 | 中等长度文本数据 |
| longblob | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| longtext | 0-4 294 967 295字节 | 极大文本数据 |
对于blob类型字段(如视频,图片)我们用来保存二进制文件
但是在实际存储中,图片视频等文件在我们一般只将文件的路径保存在数据表中,真实的文件还是存储到硬盘里.
对于mysql的存储引擎我们通过命令行输入:show engines;可以查阅到

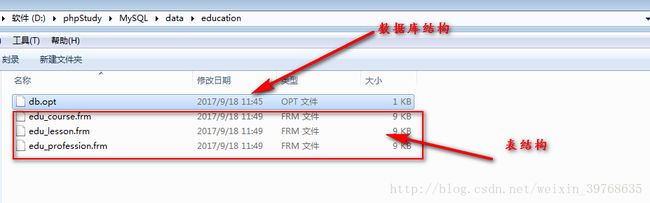
同时我们也可以在mysql中查阅到我们在数据库中存储的mysql数据表存放路径(innodb及myisam存储引擎存储)

在innodb存储引擎中数据表数据是集中存储的,但是,在每个数据库文件夹下都有一个opt文件,它保存的是对应的数据库的选项。

这里我就几个常用的存储引擎进行分析
innoDB存储引擎
(1) innodb存储引擎的mysql表提供了事务,回滚以及系统崩溃修复能力和多版本迸发控制的事务的安全。
(2)innodb支持自增长列(auto_increment),自增长列的值不能为空,如果在使用的时候为空的话怎会进行自动存现有的值开始增值,如果有但是比现在的还大,则就保存这个值。
(3)innodb存储引擎支持外键(foreign key) ,外键所在的表称为子表而所依赖的表称为父表。
(4)innodb存储引擎最重要的是支持事务,以及事务相关联功能。
(5)innodb存储引擎支持mvcc的行级锁。
(6)innodb存储引擎索引使用的是B+Tree
innodb存储引擎 每个数据表有单独的“结构文件” .frm
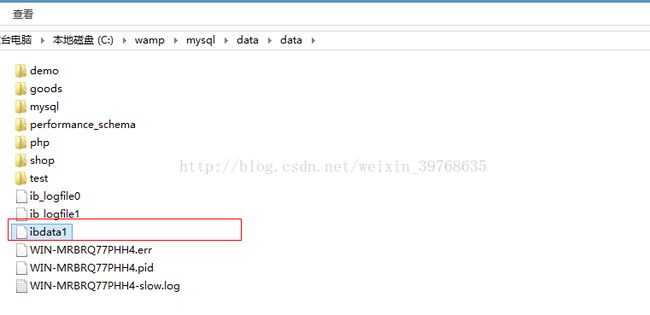
数据,索引集中存储,存储于同一个表空间文件中ibdata1。
创建innodb表后,存在文件如下:

数据库中表t1的结构文件"t1.frm";

数据/索引集中储存在"ibdata1"中;
我们cmd在命令行输入如下命令:
show variables like ‘innodb_file_per_table%';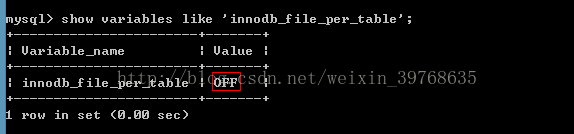
可以看到该配置是关闭的,即默认所有的 innodb表的数据和索引在同一个表空间文件中,通过配置可以达到每个innodb的表对应一个表空间文件。
开启该配置:
set global innodb_file_per_table=1;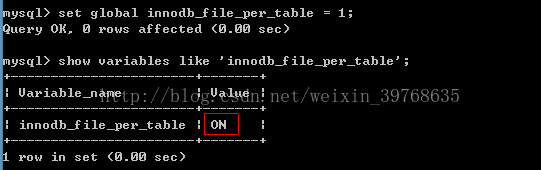
创建一个innodbd的表进行测试使用。

查看表对应的文件自己独立的“数据/索引”文件:t2.ibd
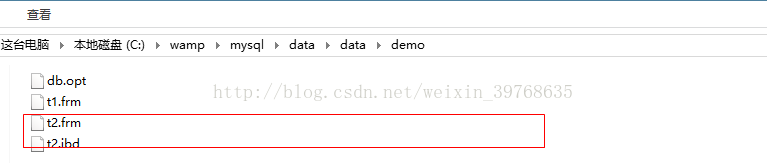
系统配置参数innodb_file_per_table后期无论发生任何变化,t2都有自己独立的“数据/索引”文件。
注意:innodb数据表不能直接进行文件的复制/粘贴进行备份还原,可以使用如下指令:
> mysqldump -uroot -p密码 数据库名字 > f:/文件名称.sql [备份]
> mysql -uroot -p密码数据库 < f:/文件名称.sql [还原]
innodb存储引擎中数据是按照主键顺序存储。如插入一下代码
create table t3(
id int primary key auto_increment,
name varchar(32) not null
)engine innodb charset utf8;
insert into t3 values(223,'刘备'),(12,'张飞'),(162,'张聊'),(1892,'网飞');
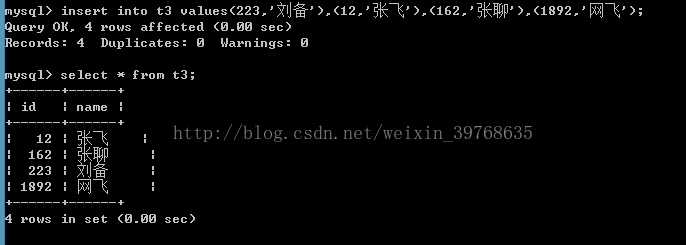
我们发现,当数据的写入顺序 与 存储的顺序不一致,需要按照主键的顺序把记录摆放到对应的位置上去,因此在这一点上innodb由于插入时做排序工作,效率比Myisam的要稍慢。
但是在并发处理上innodb提供了行级锁定(row-level locking),在一定情况下,可以选择行级锁来提升并发性,当然innodb存储引擎也支持表级锁定,innodb根据操作选择行锁与表锁。
同时innodb存储引擎还支持多版本并发控制,MVCC,效果达到无阻塞读操作。

锁机制:
当客户端操作表(记录)时,为了保证操作的隔离性(多个客户端操作不能相互影响),通过加锁来处理。
操作方面:
读锁:读操作时增加的锁,也叫共享锁,S-lock。特征是所有人都只可以读,只有释放锁之后才可以写。
写锁:写操作时增加的锁,也叫独占锁或排他锁,X-lock。特征,只有锁表的客户可以操作(读写)这个表,其他客户读都不能读。
锁定粒度(范围)
表级锁:开销小,加锁快,发生锁冲突的概率最高,并发度最低。myisam和innodb都支持。
行级锁:开销大,加锁慢,发生锁冲突的概率最低,并发度也最高。innodb支持
Tips:默认情况,表锁和行锁都是自动获得的,不需要额外的命令。
MyISAM存储引擎
1、MyISAM 这种存储引擎不支持事务,不支持行级锁,只支持并发插入的表锁,主要用于高负载的select。
2、MyISAM 类型的表支持三种不同的存储结构:静态型、动态型、压缩型。
(1)静态型:就是定义的表列的大小是固定(即不含有:xblob、xtext、varchar等长度可变的数据类型),这样mysql就会自动使用静态myisam格式。
使用静态格式的表的性能比较高,因为在维护和访问的时候以预定格式存储数据时需要的开销很低。但是这高性能是有空间换来的,因为在定义的时候是固定的,所以不管列中的值有多大,都会以最大值为准,占据了整个空间。
(2)动态型:如果列(即使只有一列)定义为动态的(xblob, xtext, varchar等数据类型),这时myisam就自动使用动态型,虽然动态型的表占用了比静态型表较少的空间,但带来了性能的降低,因为如果某个字段的内容发生改变则其位置很可能需要移动,这样就会导致碎片的产生。随着数据变化的怎多,碎片就会增加,数据访问性能就会相应的降低。
对于因为碎片的原因而降低数据访问性,有两种解决办法:
@1、尽可能使用静态数据类型
@2、经常使用optimize table语句,他会整理表的碎片,恢复由于表的更新和删除导致的空间丢失。
(如果存储引擎不支持 optimize table 则可以转储并重新加载数据,这样也可以减少碎片)
(3)压缩型:如果在这个数据库中创建的是在整个生命周期内只读的表,则这种情况就是用myisam的压缩型表来减少空间的占用。
3、MyISAM也是使用B+tree索引但是和Innodb的在具体实现上有些不同。
首先我们来看一下myisam存储引擎的存储方式:

找到对用的数据库文件发现数据,索引,结构分别存储于不同的文件中。
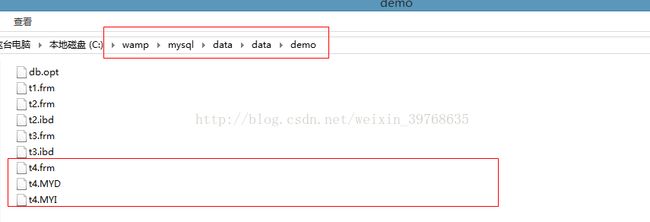
mysiam存储引擎数据表,每个数据表都有三个文件*.frm *.MYD *.MYI 并且这三个文件(表结构,表数据,表索引)支持物理复制、粘贴操作(直接备份还原)。
我们插入数据进行测试:
create table t5(
id int primary key auto_increment,
name varchar(32) not null
)engine myisam charset utf8;
insert into t5 values(2223,'刘备'),(12,'张飞'),(162,'张聊'),(1892,'网飞');

测试结果可以发现:
数据查询的顺序,与写入的顺序一致。
数据写入时候,没有按照主键id值给予排序存储,该特点导致数据写入的速度非常快。
在并发性这一块:因为myisam存储引擎是“表锁”,所以并发性较比innodb要稍逊色.
但是myisam具备压缩性:
如果一个myisam数据表存储的数据非常多,就会占据很大的硬盘空间,为了节省空间,可以把这个myisam数据表给进行压缩处理。
具体压缩步骤:
第一:压缩技术:myisampack.exe 表名(路径)
完成自我复制,增加表的容量 insert into t5(name) select name from t5;

执行压缩之前查找数据文件的大小。
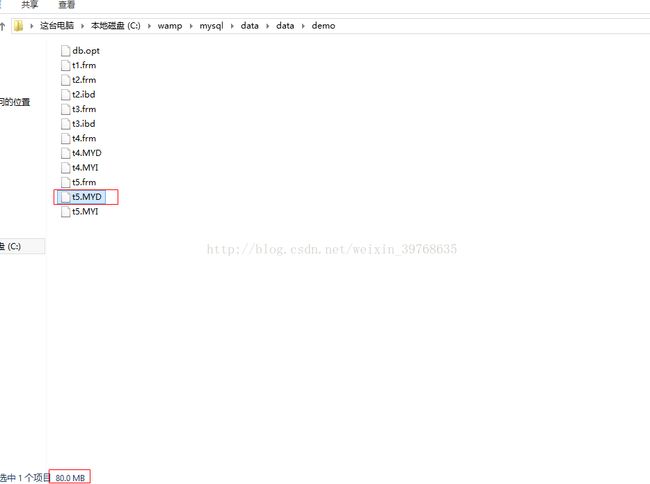
(开始执行压缩,phpstudy中没有myisampack.exe)


压缩完毕后,把数据表给flush刷新一次,使得硬盘数据与内存数据同步。
flush table 表名称
压缩后的结果
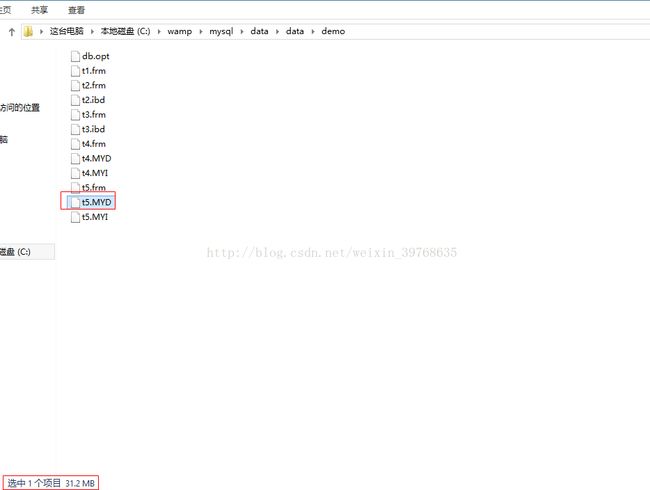
第二:重建索引
压缩后的数据表需要根据最新的数据位置把索引重新建立一次。
根据压缩后的数据把索引重建建立起来。
重建索引的工具:myisamchk.exe -rq 表名(路径)

重建索引成功

第三:只读特性
压缩的数据表不能再写入数据了,必须解压后才可以。
具体解压:myisamchk.exe --unpack 表名
(解压缩的同时,索引会自动重建)
压缩的数据表,禁止写操作。

给数据表进行解压操作,
具体解压:myisamchk.exe --unpack 表名

刷新数据表,清除缓冲文件。

解压缩后,文件大小

解压后,又可以插入新的数据。
注意:什么类型的信息适合压缩:
数据不频繁发生变化,例如全国的邮编信息、地区信息。
myisam和innodb的取舍
myisam: 写入数据非常快,适合使用场合dedecms/phpcms/discuz/微博系统等写入、读取操作多的系统。
innodb: 适合业务逻辑比较强的系统,修改操作较多的,例如ecshop、crm、办公系统、商城系统
(1)memory存储引擎相比前面的一些存储引擎,有点不一样,其使用存储在内存中的数据来创建表,而且所有的数据也都存储在内存中!!!。
(2)每个基于memory存储引擎的表实际对应一个磁盘文件,该文件的文件名和表名是相同的,类型为.frm。该文件只存储表的结构,而其数据文件,都是存储在内存中,这样有利于对数据的快速处理,提高整个表的处理能力。
(3)memory存储引擎默认使用哈希(HASH)索引,其速度比使用B-+Tree型要快,如果读者希望使用B树型,则在创建的时候可以引用。
(4)memory存储引擎文件数据都存储在内存中,如果mysqld进程发生异常,重启或关闭机器这些数据都会消失。所以memory存储引擎中的表的生命周期很短,一般只使用一次。
memory存储引擎:
特点:内部数据运行速度非常快,临时存储一些信息
缺点:服务器如果断电,就会清空该存储引擎的全部数据
BlackHole存储引擎(黑洞引擎)
(1)支持事务,而且支持mvcc的行级锁,主要用于日志记录或同步归档,这个存储引擎除非有特别目的,否则不适合使用!
各存储引擎相互转化
1、alter table tablename engine = INnodb /MyISAM/Memory // 修改了这个表的存储引擎
优点:简单,而且适合所有的引擎。
缺点:
(1)、这种转化方式需要大量的时间 和I/O,mysql要执行从旧表 到新表的一行一行的复制所以效率比较低
(2)、在转化这期间源表加了读锁
(3)、从一种引擎到另一种引擎做表转化,所有属于原始引擎的专用特性都会丢失,比如从innodb到 myisam 则 innodb的索引会丢失!
2、使用dump(转储) import(导入)
优点:使用mysqldump这个工具将修改的数据导出后会以 .sql 的文件保存,你可以对这个文件进行操作,所以你有更多更好的控制, 如修改表名,修改存储引擎等!
3、第一种方式简便,第二种方式安全,这第三种方式就算是前两种方式的折中吧, create select:
(1)、 create table newtable like oldtable;
(2)、alter table newtable engine= innodb/ myisam / memory
(3)、insert into newtable select * from oldtable;
如果数据量不大的话这种方式还是挺好的!
还有更高效的办法就是 增量填充,在填充完每个增量数据块之后提交一次事务,这样就不会导致撤销日志文件过大;
(1)start transaction
(2)insert into newtable select * from oldtable where id(主键) between x and y;
(3) commit
这样等数据填充之后有了需要的新表,旧表也存在,不需要的haunt可以删除,很方便!