Keras model.fit()参数详解
Keras官方文档
fit(x=None, y=None, batch_size=None, epochs=1, verbose=1,
callbacks=None, validation_split=0.0, validation_data=None, shuffle=True,
class_weight=None, sample_weight=None, initial_epoch=0,
steps_per_epoch=None, validation_steps=None, validation_freq=1,
max_queue_size=10, workers=1, use_multiprocessing=False)
-
x
-
y
-
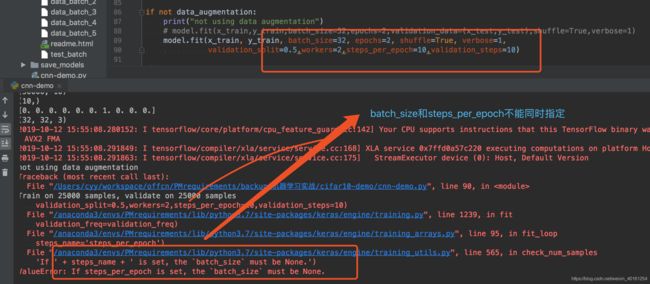
batch_size
整数
每次梯度更新的样本数。
未指定,默认为32 -
epochs
整数
训练模型迭代次数 -
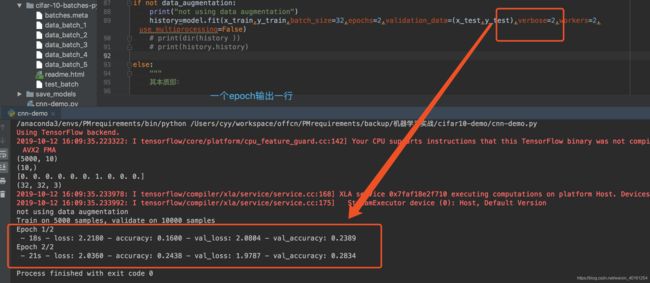
verbose
日志展示,整数
0:为不在标准输出流输出日志信息
1:显示进度条
2:每个epoch输出一行记录 -
callbacks
其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数 -
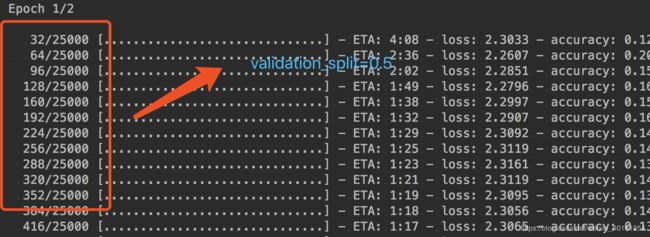
validation_split
浮点数0-1之间
用作验证集的训练数据的比例。
模型将分出一部分不会被训练的验证数据,并将在每一轮结束时评估这些验证数据的误差和任何其他模型指标。
验 证 数 据 是 混 洗 之 前 x 和 y 数 据 的 最 后 一 部 分 样 本 中 。 \color{red}{ 验证数据是混洗之前 x 和y 数据的最后一部分样本中。} 验证数据是混洗之前x和y数据的最后一部分样本中。 -
validation_data
元组 (x_val,y_val) 或元组 (x_val,y_val,val_sample_weights), 用来评估损失,以及在每轮结束时的任何模型度量指标。
模型将不会在这个数据上进行训练。
这个参数会覆盖 validation_split。 -
shuffle
布尔值
是否在每轮迭代之前混洗数据 -
class_weight
-
sample_weight
-
initial_epoch
-
steps_per_Epoch
一个epoch包含的步数(每一步是一个batch的数据送入),当使用如TensorFlow数据Tensor之类的输入张量进行训练时,默认的None代表自动分割,即数据集样本数/batch样本数。 -
validation_steps
仅当steps_per_epoch被指定时有用,在验证集上的step总数。 -
validation_freq
-
max_queue_size
-
workers
整数
最大线程数
Used for generator or keras.utils.Sequence input only -
use_multiprocessing
布尔值
Used for generator or keras.utils.Sequence input only
知否用多线程
demo
print(y_train.shape) # (50000, 10)
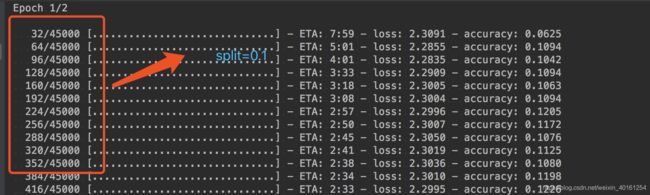
50000个数据集
model.fit(x_train, y_train, batch_size=32, epochs=2, shuffle=True, verbose=1,
validation_split=0.1)

返回
一个 History 对象。其 History.history 属性是连续 epoch 训练损失和评估值,以及验证集损失和评估值的记录(如果适用)
print(dir(history ))
print(history.history)
[‘class’, ‘delattr’, ‘dict’, ‘dir’, ‘doc’, ‘eq’, ‘format’, ‘ge’, ‘getattribute’, ‘gt’, ‘hash’, ‘init’, ‘init_subclass’, ‘le’, ‘lt’, ‘module’, ‘ne’, ‘new’, ‘reduce’, ‘reduce_ex’, ‘repr’, ‘setattr’, ‘sizeof’, ‘str’, ‘subclasshook’, ‘weakref’, ‘epoch’, ‘history’, ‘model’, ‘on_batch_begin’, ‘on_batch_end’, ‘on_epoch_begin’, ‘on_epoch_end’, ‘on_predict_batch_begin’, ‘on_predict_batch_end’, ‘on_predict_begin’, ‘on_predict_end’, ‘on_test_batch_begin’, ‘on_test_batch_end’, ‘on_test_begin’, ‘on_test_end’, ‘on_train_batch_begin’, ‘on_train_batch_end’, ‘on_train_begin’, ‘on_train_end’, ‘params’, ‘set_model’, ‘set_params’, ‘validation_data’]
{‘val_loss’: [2.095771548461914, 1.9237295974731445], ‘val_accuracy’: [0.21889999508857727, 0.29760000109672546], ‘loss’: [2.2294568004608153, 1.9951313903808594], ‘accuracy’: [0.1602, 0.2692]}

解释
- loss
训练集的loss - val_loss
测试集的loss