SolrCloud介绍
写在前面的话:当你看到这篇文章时,可能是出于好奇,也可能是公司正要使用solr云架构,作者本人热爱文字,更热爱技术,所以写了这篇文章,希望给正在读这篇文章的你一些帮助,本人能力有限,如果有错误的地方,希望大家能够指正 @所有人
注:solrCloudde的主要适用对象还是偏大的公司(Big data 大数据),与用户交互频繁的(例如电商行业),毕竟分布式与集群比较消耗服务器。
首先,我们先了解SolrCloud是什么,有什么用!
我们先举个栗子吧:作者平时爱开玩笑,段子也不少,个人认为计算机是比较抽象的知识,比喻可以快速的在脑海中构造出这个技术的大概形象!
假如说你小时候出去过年,大年初一穿着崭新的衣服出去给大舅,二舅,三舅,大爷的拜年,通过不要脸的卖萌装傻,忍者亲戚各种抱抱捏捏的,终于你得到了一笔不菲的压岁钱!你开心的下着拿着钱过几天去买个变形金刚或者充气的娃娃,嗯哼!是芭比娃娃!于是你把钱放在了床头一个大的盒子里(单点服务器),你晚上做梦都梦到礼物在向你招手。然而一个阳光明媚充满幸福味道的早上到了,迎着一缕阳光你睁开了眼睛,看着床头的盒子里,空荡荡的,钱不翼而飞了,心里一万个草泥马奔腾而去!(单点故障),这时候妈妈推开房门,笑眯眯着说:钱我先替你保管啦,你就安安心心的学习吧!
多么悲催的一件事情,一夜回到解放前。传统的单点系统就是存在这种问题,一旦服务器故障,带来就有可能是破产之灾。eBay于 1999年6月停机22小时的事故,中断了约230万的拍卖,使eBay的股票下降了9.2个百分点。
栗子举完了,这就是为什么现在集群成了标配的原因,这与两地三活有异曲同工之妙.这个时候我们再看SolrCloud,SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
这是我找到的一算比较专业的回答,要知道,为什么会发展出集群和分布式这种技术出来,肯定是对现有的状态不满足,这里不得不说到计算机的机制,现在的计算机的还是采用计算机之父冯诺依曼当初的设计思想,就是计算机采用存储程序的方式,编制好的程序和数据存放在同一存储器中,计算机可以在无人干预的情况下自动完成逐条取出指令和执行指令的任务;
而当下的电脑cpu单个性能基本固定,能处理的任务就那么多,无论频率再怎么高,都只能处理固定的任务,导致cpu台服务器计算能力低,无法完成复杂的海量数据计算。提高CPU主频和总线带宽是最初提供计算机性能的主要手段。但是这一手段对系统性能的提供是有限的。接着人们通过增加CPU个数和内存容量来提高性能,于是出现了向量机,对称多处理机(SMP)等。但是当CPU的个数超过某一阈值,这些多处理机系统的可扩展性就变的极差。主要瓶颈在于CPU访问内存的带宽并不能随着CPU个数的增加而有效增长。与SMP相反,集群系统的性能随着CPU个数的增加几乎是线性变化的!
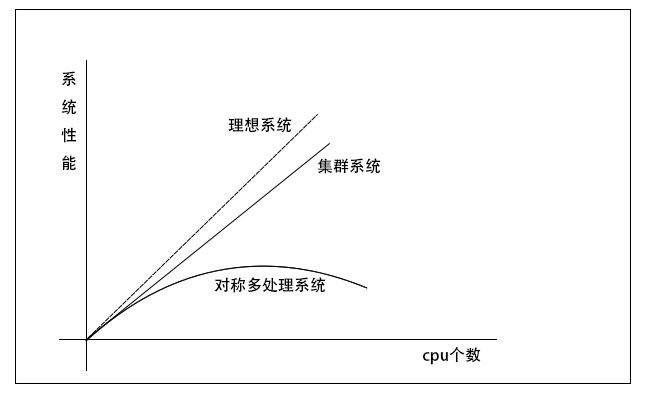
集群的特点:
集群是是指将多台服务器集中在一起,每台服务器都实现相同的业务,做相同的事情。但是每台服务器并不是缺一不可,存在的作用主要是缓解并发压力和单点故障转移问题。可以利用一些廉价的符合工业标准的硬件构造高性能的系统。
实现:高扩展、高性能、低成本、高可用!

注意:该图中最大的特点就是,每个Tomcat都完成相同的业务,但是分担着不同用户的访问,它们并不是缺一不可,如果一个Tomcat出现故障,网站依旧可以运行。
伸缩性(Scalability)
在一些大的系统中,预测最终用户的数量和行为是非常困难的,伸缩性是指系统适应不断增长的用户数的能力。提高这种并发会话能力的一种最直观的方式就增加资源(CPU,内存,硬盘等),集群是解决这个问题的另一种方式,它允许一组服务器组在一起,像单个服务器一样分担处理一个繁重的任务,我们只需要将新的服务器加入集群中即可,对于客户来看,服务无论从连续性还是性能上都几乎没有变化,好像系统在不知不觉中完成了升级
高可用性(High availability)
单一服务器的解决方案并不是一个健壮方式,因为容易出现单点失效。像银行、账单处理这样一些关键的应用程序是不能容忍哪怕是几分钟的死机。它们需要这样一些服务在任何时间都可以访问并在可预期的合理的时间周期内有响应。高可用性集群的出现是为了使集群的整体服务尽可能可用,以便考虑计算硬件和软件的易错性。如果高可用性集群中的主节点发生了故障,那么这段时间内将由次节点代替它。次节点通常是主节点的镜像,所以当它代替主节点时,它可以完全接管其身份,并且因此使系统环境对于用户是一致的。
负载均衡(Load balancing)
负载均衡集群为企业需求提供了更实用的系统。如名称所暗示的,该系统使负载可以在计算机集群中尽可能平均地分摊处理。该负载可能是需要均衡的应用程序处理负载或网络流量负载。这样的系统非常适合于运行同一组应用程序的大量用户。每个节点都可以处理一部分负载,并且可以在节点之间动态分配负载,以实现平衡。
高性能 (High Performance )
通常,第一种涉及为集群开发并行编程应用程序,以解决复杂的科学问题。这是并行计算的基础,尽管它不使用专门的并行超级计算机,这种超级计算机内部由十至上万个独立处理器组成。但它却使用商业系统,如通过高速连接来链接的一组单处理器或双处理器 PC,并且在公共消息传递层上进行通信以运行并行应用程序。因此,您会常常听说又有一种便宜的 Linux 超级计算机问世了。但它实际是一个计算机集群,其处理能力与真的超级计算机相等。
传统架构的弊端
A:系统过于庞大,开发维护困难
B:功能间耦合度太高
C:无法针对单个模块进行优化
D:无法进行水平扩展
分布式架构
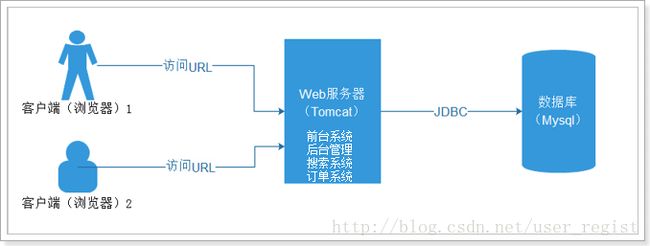
分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。并且每台服务器都缺一不可,如果某台服务器故障,则网站部分功能缺失,或导致整体无法运行。存在的主要作用是大幅度的提高效率,缓解服务器的访问和存储压力。

注意:该图中最大特点是:每个Web服务器(Tomcat)程序都负责一个网站中不同的功能,缺一不可。如果某台服务器故障,则对应的网站功能缺失,也可以导致其依赖功能甚至全部功能都不能够使用。
因此,分布式系统需要运行在集群服务器中,甚至分布式系统的每个不同子任务都可以部署集群
什么是Zookeeper
Zookeeper是集群分布式中大管家
分布式集群系统比较复杂,子模块很多,但是子模块往往不是孤立存在的,它们彼此之间需要协作和交互,各个子系统就好比动物园里的动物,为了使各个子系统能正常为用户提供统一的服务,必须需要一种机制来进行协调——这就是ZooKeeper
Zookeeper 是为分布式应用程序提供高性能协调服务的工具集合,也是Google的Chubby一个开源的实现,是Hadoop 的分布式协调服务。
Zookeeper的集群结构

在ZooKeeper集群当中,集群中的服务器角色有两种:1个Leader和多个Follower,具体功能如下:
1)领导者(leader),负责进行投票的发起和决议,监控集群中的节点是否存活(心跳机制),进行分配资源
2)follower用于接受客户端请求并向客户端返回结果,在选主过程中参与投票
特点:
A:Zookeeper:一个leader,多个follower组成的集群
B:全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的
C:数据更新原子性,一次数据更新要么成功,要么失败
D:实时性,在一定时间范围内,client能读到最新数据
E:半数机制:整个集群中只要有一半以上存活,就可以提供服务。因此通常Zookeeper由2n+1台servers组成,每个server都知道彼此的存在。每个server都维护的内存状态镜像以及持久化存储的事务日志和快照。为了保证Leader选举能过得到多数的支持,所以ZooKeeper集群的数量一般为奇数。对于2n+1台server,只要有n+1台(大多数)server可用,整个系统保持可用
Zookeeper的leader选主机制
全新集群
以一个简单的例子来说明整个选举的过程.
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生什么.
1) 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态
2) 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
3) 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader.
4) 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了.
5) 服务器5启动,同4一样,当小弟.
非全新集群
那么,初始化的时候,是按照上述的说明进行选举的,但是当zookeeper运行了一段时间之后,有机器down掉,重新选举时,选举过程就相对复杂了。
需要加入数据id、leader id和逻辑时钟。
数据id:数据新的id就大,数据每次更新都会更新id。
Leader id:就是我们配置的myid中的值,每个机器一个。
逻辑时钟:这个值从0开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么这个值应该是一致的 ; 逻辑时钟值越大,说明这一次选举leader的进程最新.
选举的标准就变成:
1、逻辑时钟小的选举结果被忽略,重新投票
2、统一逻辑时钟后,数据id大的胜出
3、数据id相同的情况下,leader id大的胜出
根据这个规则选出leader。
Zookeeper的作用
Zookeeper包含一个简单的原语集,分布式应用程序可以基于它实现命名服务、配置维护、集群选主等:
命名服务:注册节点信息,形成有层次的目录结构(类似Java的包名)。
配置维护:配置信息的统一管理和动态切换
集群选主:确保整个集群中只有一个主,其它为从。并且当主挂了后,可以自动选主
SolrCloud结构简介
为了实现海量数据的存储,我们会把索引进行分片(Shard),把分片后的数据存储到不同Solr节点。
为了保证节点数据的高可用,避免单点故障,我们又会对每一个Shard进行复制,产生很多副本(Replicas),每一个副本对于一个Solr节点中的一个core
用户访问的时候,可以访问任何一个会被自动分配到任何一个可用副本进行查询,这样就实现了负载均衡

Collection:在SolrCloud集群中逻辑意义上的完整的索引。一般会包含多个Shard(分片),如果大于1个分片,那么就是分布式存储。
Shard: Collection的逻辑分片。每个Shard被化成一个或者多个replicas(副本),通过选举确定哪个是Leader(主),其它为从
Replica: Shard的一个副本,存储在Solr集群的某一台机器中(就是一个节点),对应这台Solr的一个Core。
Leader: 赢得选举的Shard replicas。每个Shard有多个Replicas,这几个Replicas需要选举来确定一个Leader。选举可以发生在任何时间,但是通常他们仅在某个Solr实例发生故障时才会触发。当索引documents时,SolrCloud会传递它们到此Shard对应的leader,leader再分发它们到全部Shard的replicas
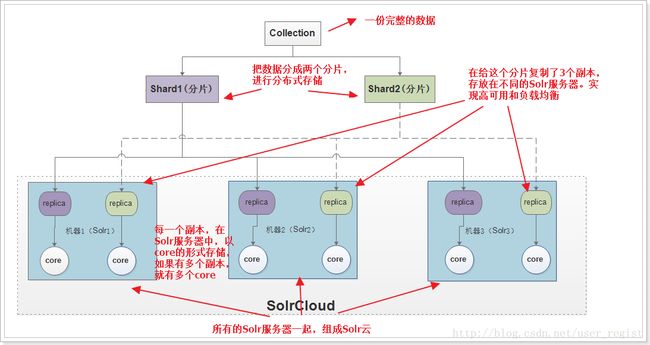
分片数量越多,每一片的数据就越少,每一个副本的数据就越少。但是一般不要多于机器数量
分片数量越少,每一片的数据就越多,每一个副本的数据就越多。
副本数量越少,总数据量越少, 这样可以减少每一台机器上的数据量,会降低高可用性,提高数据存储上限。
副本数量越多,总数据量越多,会增加每一台机器上的数据量,但是会提高整个集群的高可用性。