目标检测相关笔记(三)——CenterNet
目标检测相关笔记(三)——CenterNet
目标检测领域2019年的经典算法:CenterNet。结合“扔掉anchor!真正的CenterNet——Objects as Points论文解读”进行一下简单的整理总结。
论文地址:https://arxiv.org/pdf/1904.07850.pdf
代码:https://github.com/xingyizhou/CenterNet
概述
anchor free的目标检测算法,基于CornerNet进行了改进。相较于之前经典的 one stage 和 two stage 目标检测方法,在速度和精度上都有一定的提高。同时,该方法还可以通过改变网络head,应用于关键点检测等任务。
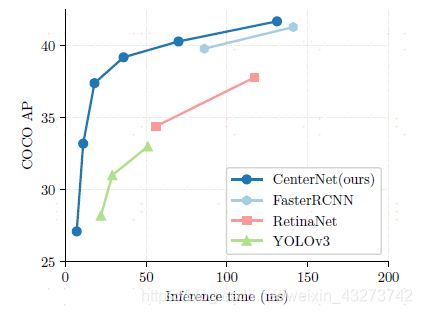
算法思路
将目标检测问题转换为关键点估计问题。将图像传入全卷积网络,得到heatmap,heatmap中的峰值点为目标中心,然后回归得到目标的其他属性:宽、高、偏移等。在网络推理过程中,不存在NMS这类的后处理操作。
对于人体关键点检测任务,将关键点位置作为中心点的偏移量,得到中心点位置后,回归出这些偏移量的值就可以计算得到关键点位置。
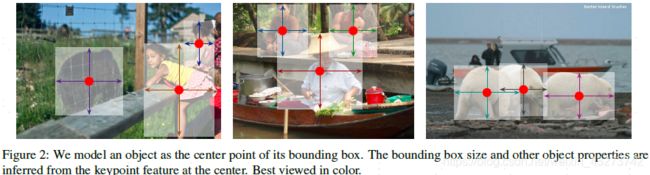
CenterNet特点
- CenterNet中,中心点可以看作是形状未知的“anchor”,但是不同于基于anchor的one stage方法,CenterNet中的anchor仅仅是出现在当前目标位置上,同时没有尺寸信息。所以不需要设置anchor与GT的IOU阈值做前景与背景的分类。(像Faster RCNN会将与GT IOU >0.7的作为前景,<0.3的作为背景,其他不管)
- 每个目标仅有一个中心点(heatmap上的局部峰值点),因此不需要NMS。
- CenterNet使用更大分辨率的输出特征图,下采样4倍。传统目标检测下采样16倍。因此不需要许多的特征图锚点。
网络结构
在CenterNet中,使用了4种编码解码(encoder-decoder)结构的网络:Resnet-18、Resnet-101、DLA-34、Hourglass-104。其中,使用可形变卷积(DCN v2)来优化了Resnet和DLA-34。

对于所有的网络结构,在检测模型最后都是加了3个输出的heads来输出预测值。每一类的heatmap(COCO数据集默认80类)、每个点对应目标框的w和h、中心点的偏移。也就是每个坐标点输出C+4个值。
(hm): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1))
)
(wh): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
(reg): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
在源码opts.py的update_dataset_info_and_set_heads函数中定义如下(ctdet为目标检测、multi_pose为关键点检测)

GT生成
在GT的生成过程中,与CornerNet一样,对于某一类的目标,我们需要将GT的中心点p计算出来用于训练。中心点的计算方法为((x1+x2)/2,(y1+y2)/2)。对于下采样后的坐标p^,计算方法为cliip(p/R),即p除以下采样倍数后向下取整。计算得到中心点位置后,通过高斯核函数对GT的每个点进行赋值。

例如:

损失函数
网络输出包括上述3部分,因此,损失函数也分别对应了3个输出heads。其中,Lk对应80类的heatmap、Lsize对应目标框的w和h、Loff对应中心点的偏移。在论文中,给Lsize和Loff分别赋权重:0.1和1![]()
其中,对于中心点预测部分,采用了修改后的focal loss(与CornerNet一样)。其中,α和β为损失函数中的超参数,分别设置为2和4。N是图像中关键点个数,用于将focal loss归一化。
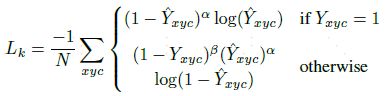
很有趣直观的损失函数解释 :
和Focal Loss类似,对于easy example的中心点,适当减少其训练比重也就是loss值。 当Y=1的时候,(1-Y^)**α
就充当了矫正的作用,假如Y接近1的话,说明这个是一个比较容易检测出来的点,那么(1-Y)**α
就相应比较低了。而当Y接近0的时候,说明这个中心点还没有学习到,所以要加大其训练的比重,因此(1-Y)**α 就会很大.
当Y=0的时候,这里对实际中心点的其他近邻点的训练比重(loss)也进行了调整,首先可以看到(Y)**α,因为当Y=0的时候,(Y)**α
的预测值理应是0,如果不为0的且越来越接近1的话,(Y^)**α 的值就会变大从而使这个损失的训练比重也加大;而(1-Y)**β
则对中心点周围的,和中心点靠得越近的点也做出了调整(因为与实际中心点靠的越近的点可能会影响干扰到实际中心点,造成误检测),因为Y是一个高斯核生成的中心点,在中心点Y=1,但是在中心点周围扩散Y会由1慢慢变小但是并不是直接为0。因此,与中心点距离越近,Y越接近1,(1-Y)**β
越小,相反则越大。
对于距离实际中心点近的点,Y值接近1,但是预测出来这个点的值比较接近1,这个显然是不对的,它应该检测到为0。因此用(Y^)**α
惩罚一下,使其loss比重加大些;但是因为这个检测到的点距离实际的中心点很近了,检测到的Y接近1也情有可原,那么我们就同情一下,用(1-Y)**β
来安慰下,使其loss比重减少些。 对于距离实际中心点远的点,Y值接近0,如果预测出来这个点的值比较接近1,肯定不对,需要用(Y^)**α
惩罚(原理同上),如果预测出来的接近0,那么差不多了,拿(Y^)**α 来安慰下,使其损失比重小一点;至于(1-Y)**β
的话,因为此时预测距离中心点较远的点,所以这一项使距离中心点越远的点的损失比重占的越大,而越近的点损失比重则越小,这相当于弱化了实际中心点周围的其他负样本的损失比重,相当于处理正负样本的不平衡了。
如果结合上面两种情况,那就是:(1-Y^)**α 和(Y^)**α 来限制easy example导致的gradient被easy
example dominant的问题,而(1-Y)**β
则用来处理正负样本的不平衡问题(因为每一个物体只有一个实际中心点,其余的都是负样本,但是负样本相较于一个中心点显得有很多)。
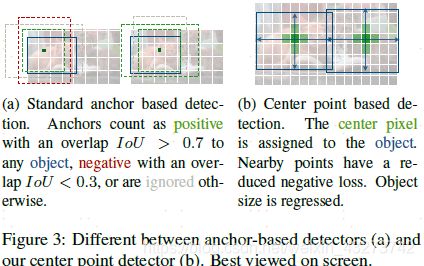
传统的基于anchor的检测方法,通常选择与标记框IoU大于0.7的作为positive,相反,IoU小于0.3的则标记为negative,如下图a。这样设定好box之后,在训练过程中使positive和negative的box比例为1:3来减少negative
box的比例。 而在CenterNet中,每个中心点对应一个目标的位置,不需要进行overlap的判断。那么怎么去减少negative
center pointer的比例呢?CenterNet是采用Focal Loss的思想,在实际训练中,中心点的周围其他点(negative
center pointer)的损失则是经过衰减后的损失(上文提到的),而目标的长和宽是经过对应当前中心点的w和h回归得到的:
 由于网络对图像进行了4倍的下采样,所以特征图在重新映射到原始图像时会带来精度误差。因此,对于每个中心点,采用一个local offset偏移来进行补偿。所有类别共享同一个offset。这个损失采用L1 loss。
由于网络对图像进行了4倍的下采样,所以特征图在重新映射到原始图像时会带来精度误差。因此,对于每个中心点,采用一个local offset偏移来进行补偿。所有类别共享同一个offset。这个损失采用L1 loss。
解释:因为我们原始的annotation是浮点数的形式(COCO数据集),使用转化后的box计算出来的中心点也是浮点型的,假设计算出来的中心点是[98.97667,2.3566666]。但是在推断过程中,我们首先读入图像[512,512],然后下采样4倍成[128,128]。最终预测使用的图像大小是[128,128],而每个预测出来的热点中心(headmap
center),假设我们预测出与实际标记的中心点[98.97667,2.3566666]对应的点是[98,2],等同于这个点上有物体存在,但是我们标记出的点是[98,2],直接映射为[512,512]的形式肯定会有精度损失,为了解决这个就引入了Loff偏置损失。
 其中O是预测得到的偏移,(p/R-p^)是提前计算的数值。
其中O是预测得到的偏移,(p/R-p^)是提前计算的数值。
ct 即 center point reg是偏置回归数组,存放每个中心店的偏置值 k是当前图中第k个目标
reg[k] = ct - ct_int
# 实际例子为
# [98.97667 2.3566666] - [98 2] = [0.97667, 0.3566666]
预测到中心点坐标后,还需要预测对应bbox的宽和高从而计算得到最终的(x1,y1,x2,y2)。损失函数同样采用L1 loss。在计算过程中,没有对scale进行归一化,直接使用原始像素坐标进行计算。

推理方式
在推理阶段,首先将图像输入网络获取heatmap,然后采用3x3的MaxPool检测当前热点的值是否比周围的八个近邻点(八方位)都大(或者等于),取100个这样的点(类似于anchor-based检测中nms的效果)。使用回归得到的偏移和尺寸值进行计算得到bbox:
![]()
最终,通过预测得到的Y的值进行选择,选择大于阈值0.3的中心点作为最终结果。
