【玩转华为云】手把手教你用Modelarts基于FasterRCNN算法实现物体检测

本篇推文共计2000个字,阅读时间约3分钟。
华为云—华为公司倾力打造的云战略品牌,2011年成立,致力于为全球客户提供领先的公有云服务,包含弹性云服务器、云数据库、云安全等云计算服务,软件开发服务,面向企业的大数据和人工智能服务,以及场景化的解决方案。

华为云用在线的方式将华为30多年在ICT基础设施领域的技术积累和产品解决方案开放给客户,致力于提供稳定可靠、安全可信、可持续创新的云服务,做智能世界的“黑土地”,推进实现“用得起、用得好、用得放心”的普惠AI。华为云作为底座,为华为全栈全场景AI战略提供强大的算力平台和更易用的开发平台。

华为云官方网站
ModelArts是华为云产品中面向开发者的一站式AI开发平台,为机器学习与深度学习提供海量数据预处理及半自动化标注、大规模分布式Training、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。

华为云官方网站

基于FasterRCNN算法实现物体检测
本实验我们将聚焦于用FasterRCNN算法实现物体检测,在ModelArts的Notebook开发环境中实现用FasterRCNN算法构建一个物体检测的神经网络模型,并在该环境中实现对物体检测神经网络模型的训练与测试,最终达到实现物体检测的实验目的。

基于FasterRCNN算法实现物体检测
实验流程
1.准备实验环境与创建开发环境
2.下载数据与训练代码
3.准备数据
4.FasterRCNN模型训练
5.FasterRCNN模型测试
1
1.1进入ModelArts
首先需要进入华为云Modelarts主页,输入自己的账号密码:
https://www.huaweicloud.com/product/modelarts.html
点击进入“进入控制台”
在左侧开发环境处,点击Notebook:
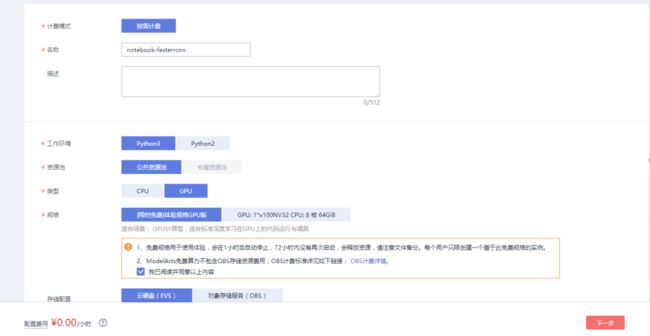
点击“创建”,填写配置信息:
名称:自定义(此处我设置的是notebook-fasterrcnn)
工作环境:Python3
资源池:公共资源池
类型:GPU
规格:体验规格GPU(这样就不要花费)
存储配置:云硬盘
这里我说说我对云硬盘与对象存储服务的理解:
云硬盘对应的是云服务器,就如同电脑的自带硬盘,存储在云硬盘的数据可以随时的在云端查看。
对象存储服务就如同移动硬盘,可以随时做资料备份。
按“下一步”确认信息无误,点击“提交”即可:
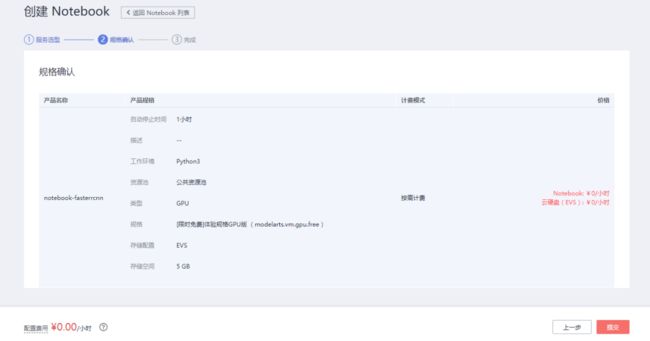
即可完成创建:
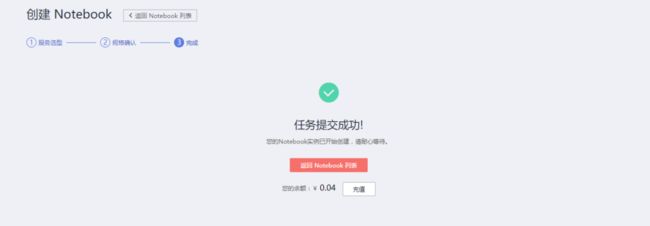
点击“返回Notebook列表”,即看到正在运行的Notebook环境:

点击进入创建的notebook-fasterrcnn中:
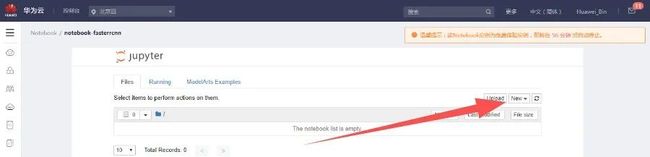
点击选择右侧的“New”
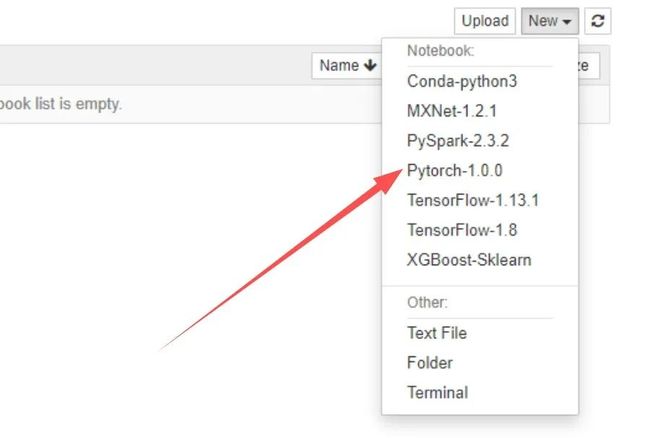
点击选择Pytorch-1.0.0开发环境后,进入页面:

输入下面代码后,点击“Run”进行测试:
print("Hello world!")
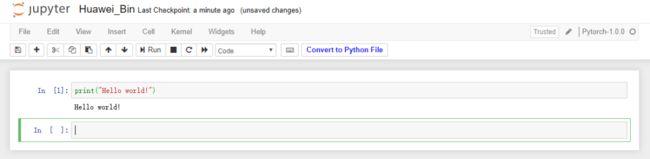
成功输出“Hello world!”,说明环境配置正确
2
2.数据和代码下载
点击“Run”运行下面代码,进行实验代码和实验数据的下载和解压:
from modelarts.session import Session
sess = Session()
if sess.region_name == 'cn-north-1':
bucket_path="modelarts-labs/notebook/DL_object_detection_faster/fasterrcnn.tar.gz"
elif sess.region_name == 'cn-north-4':
bucket_path="modelarts-labs-bj4/notebook/DL_object_detection_faster/fasterrcnn.tar.gz"
else:
print("请更换地区到北京一或北京四")
sess.download_data(bucket_path=bucket_path, path="./fasterrcnn.tar.gz")
# 解压文件
!tar -xf ./fasterrcnn.tar.gz
# 清理压缩包
!rm -r ./fasterrcnn.tar.gz本案例使用PASCAL VOC 2007数据集训练模型,共20个类别的物体:
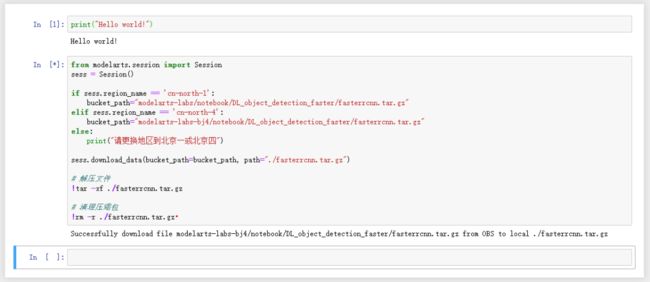
下载后的代码和数据保存在了之前设置的云硬盘(EVS)中
这里是已经下载好的文件目录:
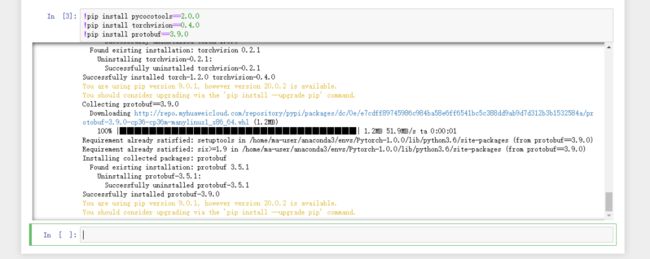
安装依赖:
!pip install pycocotools==2.0.0
!pip install torchvision==0.4.0
!pip install protobuf==3.9.0运行之后的页面如下:
利用下面两段代码引用之前安装的依赖:
代码1:
import tools._init_paths
%matplotlib inline
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorboardX as tb
from datasets.factory import get_imdb
from model.train_val import get_training_roidb, train_net
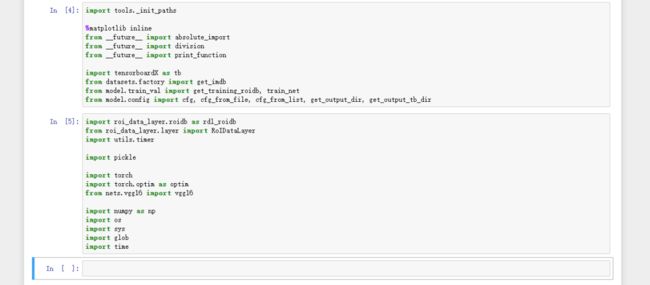
from model.config import cfg, cfg_from_file, cfg_from_list, get_output_dir, get_output_tb_dir代码2:
import roi_data_layer.roidb as rdl_roidb
from roi_data_layer.layer import RoIDataLayer
import utils.timer
import pickle
import torch
import torch.optim as optim
from nets.vgg16 import vgg16
import numpy as np
import os
import sys
import glob
import time运行之后的页面如下:
3
3.神经网络搭建
为了节省时间,运行以下代码,本实验将在预训练模型的基础上进行训练。实验中我们使用VGG16作为FasterRCNN的主干网络:
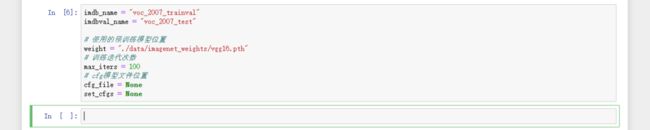
imdb_name = "voc_2007_trainval"
imdbval_name = "voc_2007_test"
# 使用的预训练模型位置
weight = "./data/imagenet_weights/vgg16.pth"
# 训练迭代次数
max_iters = 100
# cfg模型文件位置
cfg_file = None
set_cfgs = None运行结果如下:
运行下面代码,定义读取数据集函数:
数据集的标注格式是PASCAL VOC格式。
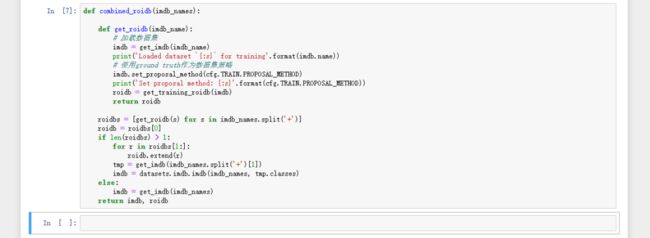
def combined_roidb(imdb_names):
def get_roidb(imdb_name):
# 加载数据集
imdb = get_imdb(imdb_name)
print('Loaded dataset `{:s}` for training'.format(imdb.name))
# 使用ground truth作为数据集策略
imdb.set_proposal_method(cfg.TRAIN.PROPOSAL_METHOD)
print('Set proposal method: {:s}'.format(cfg.TRAIN.PROPOSAL_METHOD))
roidb = get_training_roidb(imdb)
return roidb
roidbs = [get_roidb(s) for s in imdb_names.split('+')]
roidb = roidbs[0]
if len(roidbs) > 1:
for r in roidbs[1:]:
roidb.extend(r)
tmp = get_imdb(imdb_names.split('+')[1])
imdb = datasets.imdb.imdb(imdb_names, tmp.classes)
else:
imdb = get_imdb(imdb_names)
return imdb, roidb运行界面:
运行下面代码,设置模型训练参数:
if cfg_file is not None:
cfg_from_file(cfg_file)
if set_cfgs is not None:
cfg_from_list(set_cfgs)
print('Using config:')
print(cfg)
np.random.seed(cfg.RNG_SEED)
# 加载训练数据集
imdb, roidb = combined_roidb(imdb_name)
print('{:d} roidb entries'.format(len(roidb)))
# 设置输出路径
output_dir = get_output_dir(imdb,None)
print('Output will be saved to `{:s}`'.format(output_dir))
# 设置日志保存路径
tb_dir = get_output_tb_dir(imdb, None)
print('TensorFlow summaries will be saved to `{:s}`'.format(tb_dir))
# 加载验证数据集
orgflip = cfg.TRAIN.USE_FLIPPED
cfg.TRAIN.USE_FLIPPED = False
_, valroidb = combined_roidb(imdbval_name)
print('{:d} validation roidb entries'.format(len(valroidb)))
cfg.TRAIN.USE_FLIPPED = orgflip
# 创建backbone网络
# 在案例中使用的是VGG16模型,可以尝试其他不同的模型结构,例如Resnet等
net = vgg16()运行界面:

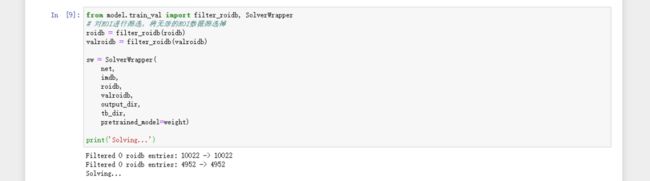
运行下面代码,对ROI进行筛选,将无效的ROI数据筛选掉:
from model.train_val import filter_roidb, SolverWrapper
# 对ROI进行筛选,将无效的ROI数据筛选掉
roidb = filter_roidb(roidb)
valroidb = filter_roidb(valroidb)
sw = SolverWrapper(
net,
imdb,
roidb,
valroidb,
output_dir,
tb_dir,
pretrained_model=weight)
print('Solving...')运行界面:
运行下面代码,显示所有模型属性:
# 显示所有模型属性
sw.__dict__.keys()运行界面如下:

运行下面代码,输出查看主干网络:
# sw.net为主干网络
print(sw.net)运行界面如下:

定义神经网络结构,使用PyTorch搭建神经网络:
# 构建网络结构,模型加入ROI数据层
sw.data_layer = RoIDataLayer(sw.roidb, sw.imdb.num_classes)
sw.data_layer_val = RoIDataLayer(sw.valroidb, sw.imdb.num_classes, random=True)
# 构建网络结构,在VGG16基础上加入ROI和Classifier部分
lr, train_op = sw.construct_graph()
# 加载之前的snapshot
lsf, nfiles, sfiles = sw.find_previous()
# snapshot 为训练提供了断点训练,如果有snapshot将加载进来,继续训练
if lsf == 0:
lr, last_snapshot_iter, stepsizes, np_paths, ss_paths = sw.initialize()
else:
lr, last_snapshot_iter, stepsizes, np_paths, ss_paths = sw.restore(str(sfiles[-1]), str(nfiles[-1]))
iter = last_snapshot_iter + 1
last_summary_time = time.time()
# 在之前的训练基础上继续进行训练
stepsizes.append(max_iters)
stepsizes.reverse()
next_stepsize = stepsizes.pop()
# 将net切换成训练模式
print("网络结构:")
sw.net.train()
sw.net.to(sw.net._device)运行界面如下:

4
4.FasterRCNN模型训练
本实验使用的是Pytorch深度学习框架搭建FasterRCNN神经网络模型。
在实验中可以进入Notebook的管理控制台查看相应的源码实现。
训练神经网络:
while iter < max_iters + 1:
cfg.SNAPSHOT_PREFIX = "VGG_faster_rcnn"
if iter == next_stepsize + 1:
# 加入snapshot节点
sw.snapshot(iter)
lr *= cfg.TRAIN.GAMMA
scale_lr(sw.optimizer, cfg.TRAIN.GAMMA)
next_stepsize = stepsizes.pop()
utils.timer.timer.tic()
# 数据通过ROI数据层,进行前向计算
blobs = sw.data_layer.forward()
now = time.time()
if iter == 1 or now - last_summary_time > cfg.TRAIN.SUMMARY_INTERVAL:
# 计算loss函数
# 根据loss函数对模型进行训练
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, total_loss, summary = \
sw.net.train_step_with_summary(blobs, sw.optimizer)
for _sum in summary:
sw.writer.add_summary(_sum, float(iter))
# 进行数据层验证计算
blobs_val = sw.data_layer_val.forward()
summary_val = sw.net.get_summary(blobs_val)
for _sum in summary_val:
sw.valwriter.add_summary(_sum, float(iter))
last_summary_time = now
else:
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, total_loss = \
sw.net.train_step(blobs, sw.optimizer)
utils.timer.timer.toc()
if iter % (cfg.TRAIN.DISPLAY) == 0:
print('iter: %d / %d, total loss: %.6f\n >>> rpn_loss_cls: %.6f\n '
'>>> rpn_loss_box: %.6f\n >>> loss_cls: %.6f\n >>> loss_box: %.6f\n >>> lr: %f' % \
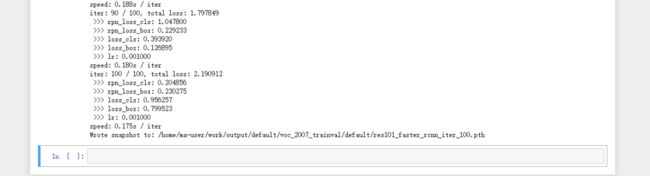
(iter, max_iters, total_loss, rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, lr))
print('speed: {:.3f}s / iter'.format(
utils.timer.timer.average_time()))
# 进行snapshot存储
if iter % cfg.TRAIN.SNAPSHOT_ITERS == 0:
last_snapshot_iter = iter
ss_path, np_path = sw.snapshot(iter)
np_paths.append(np_path)
ss_paths.append(ss_path)
# 删掉多余的snapshot
if len(np_paths) > cfg.TRAIN.SNAPSHOT_KEPT:
sw.remove_snapshot(np_paths, ss_paths)
iter += 1
if last_snapshot_iter != iter - 1:
sw.snapshot(iter - 1)
sw.writer.close()
sw.valwriter.close()点击“Run”,运行界面如下:
5
5.FasterRCNN模型测试
运行以下代码,点击“Run”,利用训练得到的代码进行推理测试:
%matplotlib inline
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
# 将路径转入lib
import tools._init_paths
from model.config import cfg
from model.test import im_detect
from torchvision.ops import nms
from utils.timer import Timer
import matplotlib.pyplot as plt
import numpy as np
import os, cv2
import argparse
from nets.vgg16 import vgg16
from nets.resnet_v1 import resnetv1
from model.bbox_transform import clip_boxes, bbox_transform_inv
import torch运行界面如下:
运行下面代码进行模型参数定义:
# PASCAL VOC类别设置
CLASSES = ('__background__',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
# 网络模型文件名定义
NETS = {'vgg16': ('vgg16_faster_rcnn_iter_%d.pth',),'res101': ('res101_faster_rcnn_iter_%d.pth',)}
# 数据集文件名定义
DATASETS= {'pascal_voc': ('voc_2007_trainval',),'pascal_voc_0712': ('voc_2007_trainval+voc_2012_trainval',)}运行界面如下:

结果绘制,将预测的标签和边界框绘制在原图上:
def vis_detections(im, class_dets, thresh=0.5):
"""Draw detected bounding boxes."""
im = im[:, :, (2, 1, 0)]
fig, ax = plt.subplots(figsize=(12, 12))
ax.imshow(im, aspect='equal')
for class_name in class_dets:
dets = class_dets[class_name]
inds = np.where(dets[:, -1] >= thresh)[0]
if len(inds) == 0:
continue
for i in inds:
bbox = dets[i, :4]
score = dets[i, -1]
ax.add_patch(
plt.Rectangle((bbox[0], bbox[1]),
bbox[2] - bbox[0],
bbox[3] - bbox[1], fill=False,
edgecolor='red', linewidth=3.5)
)
ax.text(bbox[0], bbox[1] - 2,
'{:s} {:.3f}'.format(class_name, score),
bbox=dict(facecolor='blue', alpha=0.5),
fontsize=14, color='white')
plt.axis('off')
plt.tight_layout()
plt.draw()运行结果如下所示:
继续输入代码,选择测试图片的文件夹路径:
test_file = "./test"运行结果如下;

运行以下代码,进行模型推理:
import cv2
from utils.timer import Timer
from model.test import im_detect
from torchvision.ops import nms
cfg.TEST.HAS_RPN = True # Use RPN for proposals
# 模型存储位置
# 这里我们加载一个已经训练110000迭代之后的模型,可以选择自己的训练模型位置
saved_model = "./models/vgg16-voc0712/vgg16_faster_rcnn_iter_110000.pth"
print('trying to load weights from ', saved_model)
# 加载backbone
net = vgg16()
# 构建网络
net.create_architecture(21, tag='default', anchor_scales=[8, 16, 32])
# 加载权重文件
net.load_state_dict(torch.load(saved_model, map_location=lambda storage, loc: storage))
net.eval()
# 选择推理设备
net.to(net._device)
print('Loaded network {:s}'.format(saved_model))
for file in os.listdir(test_file):
if file.startswith("._") == False:
file_path = os.path.join(test_file, file)
print(file_path)
# 打开测试图片文件
im = cv2.imread(file_path)
# 定义计时器
timer = Timer()
timer.tic()
# 检测得到图片ROI
scores, boxes = im_detect(net, im)
print(scores.shape, boxes.shape)
timer.toc()
print('Detection took {:.3f}s for {:d} object proposals'.format(timer.total_time(), boxes.shape[0]))
# 定义阈值
CONF_THRESH = 0.7
NMS_THRESH = 0.3
cls_dets = {}
# NMS 非极大值抑制操作,过滤边界框
for cls_ind, cls in enumerate(CLASSES[1:]):
cls_ind += 1 # 跳过 background
cls_boxes = boxes[:, 4*cls_ind:4*(cls_ind + 1)]
cls_scores = scores[:, cls_ind]
dets = np.hstack((cls_boxes,
cls_scores[:, np.newaxis])).astype(np.float32)
keep = nms(torch.from_numpy(cls_boxes), torch.from_numpy(cls_scores), NMS_THRESH)
dets = dets[keep.numpy(), :]
if len(dets) > 0:
if cls in cls_dets:
cls_dets[cls] = np.vstack([cls_dets[cls], dets])
else:
cls_dets[cls] = dets
vis_detections(im, cls_dets, thresh=CONF_THRESH)
plt.show()运行界面如下:

测试1
利用步骤进行其它图片测试:

测试2
测试3
 测试4
测试4

测试5
 测试6
测试6
至此实验全部完成。
大家使用的云端资源记得全部删除如ModelArts创建的Notebook开发环境需要删除,并停用访问密钥,以免造成不必要的花费。
通过对实验结果的比对,可以看出利用
[华为云ModelArts]训练出来的物体检测模型是很棒的,六个字总结就是-高效,快捷,省心。
如您对本系列的实验感兴趣,点击底部阅读原文可体验于4月20日开始的
[华为云开发者青年班第二期 AI实战营],现进行到打卡第六天,每天一天实战演练,让你足不出户免费体验[华为云]高级技术专家亲自指导,学、练、赛的全流程内容,让你轻松Get AI技能。
心动不如行动,快来学习吧。

正因我们国家有许多像华为这样强大的民族企业在国家背后默默做支撑,做奉献。我们国家才能屹立于世界民族之林。
华为,中国骄傲!中华有为!

往期回顾
【玩转华为云】Modelarts基于YOLO V3算法实现物体检测
【玩转华为云】Modelarts基于海量数据训练猫狗分类模型
【玩转华为云】Modelarts实现猫狗数据集的智能标注
【玩转华为云】ModelArts基于海量数据训练美食分类模型
【玩转华为云】ModelArts零代码开发美食分类模型
【玩转华为云】ModelArts实现垃圾的智能分类
【玩转华为云】ModelArts实现数据集的图片标注
【玩转华为云】ModelArts实现一键目标物体检测
【玩转华为云】ModelArts实现一键行人车辆检测
【Python3+OpenCV】实现图像处理—灰度变换篇
【Python3+OpenCV】实现图像处理—基本操作篇
武汉加油,中国加油!
欢迎各位读者在下方进行提问留言
☆ END ☆

你与世界
只差一个
公众号
扫描上方二维码,获取千元“编程学习资料”大礼包