阅读笔记之解决正负样本不均衡---《Focal loss for Dense Obiect Detection》
目录
一、论文信息
二、阅读笔记
三、个人理解
四、相似文章推荐
五、代码实现
一、论文信息
论文:《Focal loss for Dense Obiect Detection》
论文信息:RBG和Kaiming大神在ICCV2017年的大作
原版论文的地址:Focal loss for Dense Obiect Detection(英文版免费下载,网页右上角的download)
论文翻译:用于密集目标检测的焦点损失
论文代码地址:github代码
二、阅读笔记
state-of-the-art 物体探测器存在两种方案:two-stage和one-stage
two-stage方案:第一阶段生成一组稀疏的候选对象位置(1-2k个),第二阶段使用卷积神经网络将每个候选位置分类。通过一系列进展,这个两阶段框架在具有挑战性的COCO基准上达到最高精度,但是速度较慢。eg. R-CNN 、Fast R-CNN 、Faster R-CNN
one-stage方案:在一个阶段生成候选位置并分类,这些候选位置从位置、尺度、长宽比采样来生成密集的位置(100k个),精度较差但速度快。eg. YOLO、SSD
于是作者就有了这样一个问题:could a simple one-stage detector achieve similar accuracy?
对此,作者提出了一个 one-stage 物体探测器,这是第一次与更复杂的 two-stage 最先进的COCO AP相匹配,例如特征金字塔网络(FPN)或 Mask R-CNN 、Faster R-CNN 。为了实现这一结果,我们将训练期间的类不平衡识别视为阻碍 one-stage 探测器实现最先进精度的主要障碍,并提出消除这种障碍的新的损失函数Focal Loss。
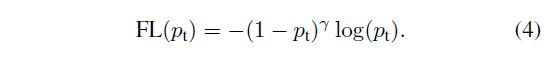
Focal Loss损失函数是动态缩放的交叉熵损失,其中缩放因子随着正确类中的置信度增加而衰减为零,参见下图。直观地说,这个缩放因子可以在训练期间自动降低简单示例的贡献,并快速将模型集中在硬性示例上。

图1. 我们提出一种新的损失函数Focal loss,在标准的交叉熵上添加一个(1-pt)^γ,设置γ>0来减小好分类样本(pt>0.5)的相对loss,更多的着眼于难例。
焦点损失函数有两个特点:1、当一个例子被错误分类并且pt很小时,调制因子接近1并且损失不受影响。当pt →1时,调制因子→0,并且对于好分类的例子会减少loss;2、参数γ平滑地调整容易样本下降的速率。当γ= 0时,FL相当于CE,并且随着γ增加,调制因子的影响同样增加(我们发现γ= 2在我们的实验中效果最好)。
为了阐明focal loss的有效性,作者设计了简单的单阶段检测器RetinaNet,取名源于它对输入图像的目标位置的密集采样。它的设计特点在于有效的网络内特征金字塔和anchor框的使用。RetinaNet是高效并且准确的,在COCO test-dev 上达到了 39.1的AP,速度为5fps,超过了之前最好的单一模型的结果不论是one-stage还是two-stage。

在实际中我们使用α-balanced的focal loss:
FL(pt)=−αt(1−pt)^γ * log(pt)
在实验中,我们发现这种形式会比不带α\alphaα的形式有微弱的提升。
最后,我们注意到loss层的实施结合了计算p的sigmoid方程和loss计算,结果具有很好的数值稳定性。
三、个人理解
Focal Loss两大重要作用:
1、控制正负样本的权重
2、控制样本分类难易程度的权重
以二分类为例:
1、控制正负样本的权重
标准交叉熵函数为
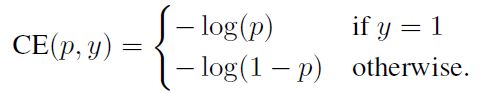
简化公式,令
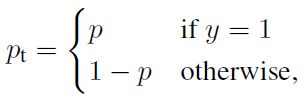
(小声bb:pt代表的是样本期望输出的概率,不是label,小编懵逼了好久,重新查询看了一下多类别交叉熵函数原理才发现的)
则标准交叉熵函数变为

想要降低负样本的影响,可在标准交叉熵函数前加上系数αt,即变为
![]()
其中:

2、控制样本分类难易程度的权重
eg. 样本a属于正样本的概率pt=0.9,样本b属于正样本的概率pt=0.6,则样本a属于易分类样本,样本b属于难分类样本,即样本属于某类的概率越大,其越容易分类。从而,可以利用(1-pt)来计算分类难易程度
令m=(1−pt)**γ (称为调制因子),则公式变为

①当pt→0时,m→1,总的loss贡献值FL越大;当pt→1时,m→0,总的loss贡献值FL越小
②γ =0时,FL=CE,即可通过调成γ 来实现m的改变
四、相似文章推荐
Gradient Harmonized Single-stage Detector
中文翻译:Gradient Harmonized Single-stage Detector
五、代码实现
完整代码详见blog(正在编辑中)
from keras import backend
import tensorflow as tf
def binary_focal_loss(gamma=2, alpha=0.25):
"""
Binary form of focal loss.
适用于二分类问题的focal loss
focal_loss(p_t) = -alpha_t * (1 - p_t)**gamma * log(p_t)
where p = sigmoid(x), p_t = p or 1 - p depending on if the label is 1 or 0, respectively.
References:
https://arxiv.org/pdf/1708.02002.pdf
Usage:
model.compile(loss=[binary_focal_loss(alpha=.25, gamma=2)], metrics=["accuracy"], optimizer=adam)
"""
#tf.constant(value,dtype,shape,name,verify_shape):创建常量 #详见https://blog.csdn.net/csdn_jiayu/article/details/82155224
## value:数值或列表 dtype:数据类型 shape:张量形状,即维数 name:可以是任何内容 verify_shape默认为False,如果修改为True的话表示检查value的形状与shape是否相符,如果不符会报错
alpha = tf.constant(alpha, dtype=tf.float32)
gamma = tf.constant(gamma, dtype=tf.float32)
def binary_focal_loss_fixed(y_true, y_pred):
"""
y_true shape need be (None,1)
y_pred need be compute after sigmoid
"""
#te.cast(x, dtype, name):类型转换函数 ##x:输入 dtype:转换目标类型 name:名称
y_true = tf.cast(y_true, tf.float32)
alpha_t = y_true * alpha + (backend.ones_like(y_true) - y_true) * (1 - alpha)
p_t = y_true * y_pred + (backend.ones_like(y_true) - y_true) * (backend.ones_like(y_true) - y_pred) + backend.epsilon()
focal_loss = - alpha_t * backend.pow((backend.ones_like(y_true) - p_t), gamma) * backend.log(p_t)
return backend.mean(focal_loss)
return binary_focal_loss_fixed
def multi_category_focal_loss1(alpha, gamma=2.0):
"""
focal loss for multi category of multi label problem
适用于多分类或多标签问题的focal loss
alpha用于指定不同类别/标签的权重,数组大小需要与类别个数一致
当你的数据集不同类别/标签之间存在偏斜,可以尝试适用本函数作为loss
Usage:
model.compile(loss=[multi_category_focal_loss1(alpha=[1,2,3,2], gamma=2)], metrics=["accuracy"], optimizer=adam)
"""
epsilon = 1.e-7
alpha = tf.constant(alpha, dtype=tf.float32)
# alpha = tf.constant([[1],[1],[1],[1],[1]], dtype=tf.float32)
# alpha = tf.constant_initializer(alpha)
gamma = float(gamma)
def multi_category_focal_loss1_fixed(y_true, y_pred):
y_true = tf.cast(y_true, tf.float32)
y_pred = tf.clip_by_value(y_pred, epsilon, 1. - epsilon)
y_t = tf.multiply(y_true, y_pred) + tf.multiply(1 - y_true, 1 - y_pred)
ce = -tf.log(y_t)
weight = tf.pow(tf.subtract(1., y_t), gamma)
fl = tf.matmul(tf.multiply(weight, ce), alpha)
loss = tf.reduce_mean(fl)
return loss
return multi_category_focal_loss1_fixed
def multi_category_focal_loss2(gamma=2., alpha=.25):
"""
focal loss for multi category of multi label problem
适用于多分类或多标签问题的focal loss
alpha控制真值y_true为1/0时的权重
1的权重为alpha, 0的权重为1-alpha
当你的模型欠拟合,学习存在困难时,可以尝试适用本函数作为loss
当模型过于激进(无论何时总是倾向于预测出1),尝试将alpha调小
当模型过于惰性(无论何时总是倾向于预测出0,或是某一个固定的常数,说明没有学到有效特征)
尝试将alpha调大,鼓励模型进行预测出1。
Usage:
model.compile(loss=[multi_category_focal_loss2(alpha=0.25, gamma=2)], metrics=["accuracy"], optimizer=adam)
"""
epsilon = 1.e-7
gamma = float(gamma)
alpha = tf.constant(alpha, dtype=tf.float32)
def multi_category_focal_loss2_fixed(y_true, y_pred):
y_true = tf.cast(y_true, tf.float32)
y_pred = tf.clip_by_value(y_pred, epsilon, 1. - epsilon)
alpha_t = y_true * alpha + (tf.ones_like(y_true) - y_true) * (1 - alpha)
y_t = tf.multiply(y_true, y_pred) + tf.multiply(1 - y_true, 1 - y_pred)
ce = -tf.log(y_t)
weight = tf.pow(tf.subtract(1., y_t), gamma)
fl = tf.multiply(tf.multiply(weight, ce), alpha_t)
loss = tf.reduce_mean(fl)
return loss
return multi_category_focal_loss2_fixed