python学习笔记(一)数据类型
无论学什么编程语言,学会看官方文档总是很有帮助的,当然看官方文档的话,需要具备一定的英文水平。Python是有官方网站的,和其他编程语言一样,在学习之前,需要进行一定的准备,构建环境,设置环境变量,选择编辑器。
构建环境、设置环境变量的相关教程很多了,过程也不难,就不赘述记录了。
编译环境的话,在刚开始入门Python时,IDLE还是比较高好用的。如果代码比较多的话,可以选择其他的编译器,这里我比较常用Spyder。当然,如果调式一个比较大的项目,最好使用PyCharm,但是一般对于初学者来说,Spyder就已经够用了。
万丈高楼平地起,先从最基本的一些语法开始。我的Python学习有两条主线:
一条是分析并且调试现有的代码;
我以编写一个个小游戏入手,理解一些简单的Python编程语言。目前我已经调试了一些Python游戏编程的代码,接触了pygame模块,当然pygame还能写出更好玩的游戏,这里只是简单实现了一些常用的功能。针对这几天调试的一个个小游戏,整理这里面用到的python语法。
一条是总结项目中涉及到的编程语言语法和一些常用的编程思想。
当然其实在调试这些小程序的时候,就已经写就这些了,只是不全面,近期想较为全面的整理一下python的基本语法,作为前面学习的复习。
话不烦絮,从基本的语法开始,这里先简单了解Python常用的数据结构。
目录
(一)数字类型
(二)字符串类型
1)将字符串理解为字符序列
2)特殊字符和转义序列
3)数字格式(八进制、十六进制)和Unicode编码的转义序列
4)字符串方法
5)格式化字符串
1.用%格式化字符串
2.format方法
6)总结:
(三)列表类型
1)列表类似于数组
2)列表的索引机制
3)修改列表
4)对列表排序
5)其他常用列表操作
(四)元组类型
(五)集合类型
(六)字典类型
1)何为字典
2)字典的其他操作
3)字典视图对象
Python的数据类型大致可以分为以下六类:
- Number(数字): int(整型), bool(布尔), float(浮点数), complex(复数)
- String(字符串)
- List(列表)
- Tuple(元组)
- Sets(集合)
- Dictionary(字典)
- None(空值)
(一)数字类型
通过一张思维导图了解一下数字类型:

关于数据类型的转换:

(二)字符串类型
主要内容
- 将字符串理解为字符序列
- 使用基本的字符串操作
- 插入特殊字符和转义序列
- 将对象转换为字符串
- 对字符串进行格式化
- 使用字节类型
1)将字符串理解为字符序列
如果要提取字符或字符串,可以将字符串看作是一系列字符,也就是说可以使用索引和切片语法进行操作
但是字符串并不是字符列表。字符串和列表之间最明显的区别就是,字符串不可以修改。
>>> x = ["Hello"]
>>> x[0]
'Hello'
>>> x = "Hello"
>>> x[0]
'H'
>>> x[-1]
'o'
>>> x[1 : ]
'ello'
#len()函数确定字符串中的字符数类似于获取列表中的元素一样
>>> len("Hello")
5
#字符串的基本操作
>>> x = 'Hello ' + 'World'
>>> x
'Hello World'
>>> 8 * "x"
'xxxxxxxx'
2)特殊字符和转义序列
以反斜杠开头,用于表示其他字符的字符序列,被称为转义序列(escape sequence)。转义序列通常用来表示特殊字符,也就是这种字符没有标准的用单字符表示的可打印格式。
常见转义序列:
| Escape Sequence | Meaning | Notes |
|---|---|---|
\newline |
Backslash and newline ignored | |
\\ |
Backslash (\) |
|
\' |
Single quote (') |
|
\" |
Double quote (") |
|
\a |
ASCII Bell (BEL) | |
\b |
ASCII Backspace (BS) | |
\f |
ASCII Formfeed (FF) | |
\n |
ASCII Linefeed (LF) | |
\r |
ASCII Carriage Return (CR) | |
\t |
ASCII Horizontal Tab (TAB) | |
\v |
ASCII Vertical Tab (VT) | |
\ooo |
Character with octal value ooo | (1,3) |
\xhh |
Character with hex value hh | (2,3) |
3)数字格式(八进制、十六进制)和Unicode编码的转义序列
在字符串中,可以用与ASCII字符对应的八进制或十六进制转义序列来包含任何ASCII字符。八进制转义序列是反斜杠后跟3位八进制数,这个八进制数对应的ASCII字符将会被八进制转义序列替代。十六进制转义序列不是用“ \ ”作为前缀,而是用“\x”,后跟任意位数的十六进制数。如果遇到不是十六进制数字的字符,就会视作转义序列结束。
例如,在ASCII字符表中,字符“m”转换为十进制值为109,转换成八进制值就是1551,转换成十六进制值则为6D。
>>> 'm'
'm'
>>> '\155'
'm'
>>> '\x6D'
'm'
#对于换行符“\n”,八进制为012,十六进制为0A
>>> '\n'
'\n'
>>> '\012'
'\n'
>>> '\x0A'
'\n'
Python3的字符串都是Unicode字符串,因此几乎能够包含所有语言的全部字符。
#特殊字符在字符串和print函数中不同的编译方式
>>> 'a\n\tb'
'a\n\tb'
>>> print('a\n\tb')
a
b
#print函数通常还会在字符串末尾添加换行符
>>> print("abc\n")
abc
#将print函数的end参数设置为“ ”,就可以让print函数不再添加换行符
>>> print("abc\n", end="")
abc
4)字符串方法
Python字符串方法大都内置于标准Python字符串类中,因此所有的字符串对象都会自动拥有这些方法。
利用函数int和float,可以将字符串分别转换为整数或浮点数。如果字符串无法转换为指定类型的数值,那么这个函数将会引发ValueError异常。
#split()方法返回字符串中的子字符串列表
>>> x = '1, 2, 3, 4, 5, 6'.split()
>>> x
['1,', '2,', '3,', '4,', '5,', '6']
#join()方法以字符串列表为参数,将字符串连在一起形成一个新字符串
>>> " ".join(x)
'1, 2, 3, 4, 5, 6'
>>> x = '1, 2, 3, 4'.split()
>>> "::".join(x)
'1,::2,::3,::4'
>>> float('123.456')
123.456
>>> float('xxzz')
Traceback (most recent call last):
File "", line 1, in
float('xxzz')
ValueError: could not convert string to float: 'xxzz'
>>> int('3333')
3333
#将10000是为八进制数
>>> int('10000', 8 )
4096
#将101是为二进制数
>>> int('101', 2 )
5
>>> int('ff',16)
255
#以上三个方法可以附带一个参数,这个参数包含了需要移除的字符。
>>> x = "www.python.org"
>>> x.strip("w")
'.python.org'
#字符串搜索
#find()方法返回字符串第一个实例的首字符在调用字符串对象中的
#位置,如果未找到子串则返回-1
>>> x = "Mississippi"
>>> x.find("ss")
2
>>> x.find("zz")
-1
#忽略字符串中位置3之前的所有字符。
>>> x.find("ss", 3)
5
忽略位置3之后的所有字符
>>> x.find("ss", 0, 3)
-1
rfind方法同样也有一个或两个可选参数,用法与find方法相同。
index和rindex方法分别与find和rfind功能完全相同,但是有一点不同:当index或rindex方法在字符串中找不到子字符串时,不会返回-1,而是会引发ValueError。
startswith和endswith方法可以一次搜索多个子字符串。如果参数是个字符串元组,那么这两个方法就会对元组中的所有字符串进行检测,只要有一个字符串匹配就会返回True
#count()返回给定子字符串在给定字符串中不重叠出现的次数
>>> x = "Mississippi"
>>> x.count("s")
4
>>> x.startswith("Miss")
True
>>> x.startswith("Misp")
False
>>> x.endswith("pi")
True
>>> x.endswith("p")
False
字符串是不可变的,但字符串对象有几个方法可以对字符串操作并返回新字符串,新字符串是原字符串修改后的版本。
>>> x.replace("ss", "+++")
'Mi+++i+++ippi'
利用列表修改字符串:
>>> text = "Hello, World"
>>> wordList = list(text)
>>> wordList[6: ] = [ ]
>>> wordList
['H', 'e', 'l', 'l', 'o', ',']
>>> text = "".join(wordList)
>>> print(text)
Hello,
常用的字符串操作:
| 字符串操作 | 说明 |
|---|---|
| + | 把两个字符串拼接在一起 |
| * | 复制字符串 |
| upper | 将字符串转换为大写 |
| lower | 将字符串转换为小写 |
| title | 将字符串中每个单词的首字母变为大写 |
| find、index | 在字符串中搜索子字符串 |
| rfind、rindex | 从字符串尾开始搜索子字符串 |
| startswith、endswith | 检查字符串的首部或尾部是否与给定子字符串匹配 |
| replace | 将字符串中的目标子字符串替换为新的子字符串 |
| strip、rstrip、lstrip | 从字符串两端移除空白符或其他字符 |
| encode | 将Unicode字符串转换为bytes对象 |
注意:上述方法均不会修改原字符串,而是返回在字符串中的位置或新的字符串。
5)格式化字符串
1.用%格式化字符串
>>> print("我是 %s 今年 %d 岁" % ('生活', 10))
我是 生活 今年 10 岁
%c 格式化字符及其ASCII码
%s 格式化字符串
%d 格式化整数
%o 格式化无符号八进制数2.format方法
format方法是一种强大的字符串格式化脚本,称得上是一种微型语言。
x = "1 2 3 4 5".split()
y = "a b c d e".split()
for i in range(0,5):
print("{1} = {0}".format(x[i], y[i]))6)总结:
- Python字符串拥有强大的文本处理功能,包括搜索与替换、清除空格、改变大小写等。
- 字符串是不可变对象,无法原地修改。
- 那些看似修改字符串的操作其实都是返回了修改后的副本。
- re(正则表达式)模块拥有更为强大的字符串处理能力。
最后引用一张思维导图作为拓展:
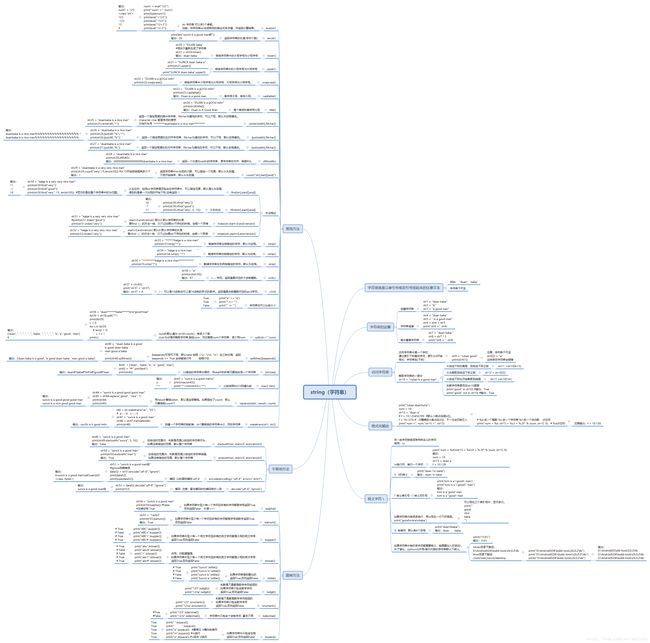
(三)列表类型
主要内容
- 操纵列表及其索引机制
- 修改列表
- 对列表排序
- 使用常用的列表操作
- 处理嵌套列表和深复制
1)列表类似于数组
#将包含3个元素的列表赋给x
x = [1, 2, 3]
注意,列表不必提前声明,也不用提前就将大小固定下来,以上一行代码就完成了列表的创建和赋值,列表的大小会根据需要自动增减。
Python提供了强类型的array模块,支持C语言数据类型的数组。有关数组的用法,可以从官方文档中找到。如果考虑数值计算,则应该考虑NumPy。
Python的列表可以包含不同类型的元素,列表元素可以是任意类型的Python对象。
#第一个元素是数字,第二个元素是字符串,第三个元素是另一个列表
x = [2, "two", [1, 2, 3]]
最基本的列表内置函数或许就是len()函数了,它返回列表元素的数量。注意,列表不会对内部嵌套的列表中的数据项进行计数。
>>> x = [2, "two", [1, 2, 3]]
>>> len(x)
3
2)列表的索引机制
Python从0开始计数,索引为0将返回列表的第一个元素,索引为2将返回第二个元素,依此类推。如果索引为负数,表示从列表末尾开始计数的位置,其中-1是列表的最后位置,-2是倒数第二位,依此类推。
切片(slice):左闭右开,包含左边的元素,不包含右边的元素。
复制列表:如果两个索引都省略了将会由原列表从头到尾创建一个新列表,即列表的复制。如果需要修改列表,但又不想影响原列表,就需要创建列表的副本,这时就能用到列表复制技术了。
在Python里面,列表的引用都是建立在原列表之上的:
>>> x
['first', 'secend', 'third', 'four']
#右边数字在左边数字的前面,则返回空列表
>>> x[2 : 0]
[]
#从0到第三个
>>> x[ : 3]
['first', 'secend', 'third']
#从第三个元素到最后一个。
>>> x[2 : ]
['third', 'four']
#从第一个到最后一个
>>> x[:]
['first', 'secend', 'third', 'four']
#复制列表,在需要对列表进行操作,但是又不想影响原列表时。
>>> y = x[:]
>>> y
['first', 'secend', 'third', 'four']
3)修改列表
除了提取列表元素,使用列表索引语法还可以修改列表。只要将索引放在赋值操作符左侧即可:
>>> x = [1, 2, 3, 4]
>>> x[1] = 'two'
>>> x
[1, 'two', 3, 4]
切片语法也可以这样使用:
>>> x = [1, 2, 3, 4]
>>> x[len(x) : ] = [5, 6, 7]
>>> x
[1, 2, 3, 4, 5, 6, 7]
>>> x[ : 0] = [-1, 0]
>>> x
[-1, 0, 1, 2, 3, 4, 5, 6, 7]
>>> x[1 : -1] = []
>>> x
[-1, 7]
向列表添加单个元素是常见操作,所以专门为此提供了append()方法:
>>> x = [1, 2, 3]
>>> x.append('four')
>>> x
[1, 2, 3, 'four']
如果用append方法把列表添加到另一个列表中去,添加进去的列表会成为主列表中的单个元素:
>>> x = [1, 2, 3, 4]
>>> y = [5, 6, 7]
>>> x.append(y)
>>> x
[1, 2, 3, 4, [5, 6, 7]]
可以用extend()方法将列表追加到另一个列表之后:
>>> x = [1, 2, 3, 4]
>>> y = [5, 6, 7]
>>> x.extend(y)
>>> x
[1, 2, 3, 4, 5, 6, 7]
insert()方法,可以在两个现有的元素之间或列表之前插入新的元素。insert是列表的方法,带有两个参数。第一个参数是新元素被插入列表的索引位置,第二个参数是新元素本身。可以理解为在列表的第n个元素之前插入新元素:
>>> x = [1, 2, 3]
>>> x.insert(2, "Hello")
>>> print(x)
[1, 2, 'Hello', 3]
>>> x.insert(0, "start")
>>> x
['start', 1, 2, 'Hello', 3]
insert()甚至可以处理负数索引:
>>> x = [1, 2, 3]
>>> x.insert(-1, "Hello")
>>> x
[1, 2, 'Hello', 3]
删除列表数据项或切片可以使用del语句:
>>> x = 'Hello Python I love you'.split()
>>> del x[4]
>>> x
['Hello', 'Python', 'I', 'love']
remove()方法会先在列表中查找给定值的第一个实例,然后将该值从列表中删除。如果remove找不到要删除的值,就会引发错误:
>>> x = [1, 2, 3, 4, 5, 6, 7, 8]
>>> x.remove(3)
>>> x
[1, 2, 4, 5, 6, 7, 8]
4)对列表排序
列表sort()方法可以对列表进行排序。sort()方法时原地排序的,也就是说会修改原来的列表。
可以新建列表副本,对副本进行排序。
sort()用到默认键方法要求,列表中的所有类型都是可以进行比较的类型,也就是说,如果列表同时包含数字和字符串,那么使用sort()方法将会引发异常:
>>> x
[7, 6, 5, 4, 2, 1]
>>> x.sort()
>>> x
[1, 2, 4, 5, 6, 7]
对列表的列表是可以排序的,排序方式为,先升序比较的一个元素,再升序比较第二个元素:
>>> x = [[1,4] , [2 ,3] , [2 , 9],[4 , 8],[4 , 4]]
>>> x.sort ()
>>> x
[[1, 4], [2, 3], [2, 9], [4, 4], [4, 8]]
自定义排序:
word_list = ["Python", "is", "better", "than", "C"]
word_list.sort()
print(word_list)
>>>['C', 'Python', 'better', 'is', 'than']
自定义函数排序。按照字符数量升序排序:
def comper_num_of_chars(strings):
return len(strings)
word_list = ["Python", "is", "better", "than", "C"]
word_list.sort(key = comper_num_of_chars)
print(word_list)
函数也是Python对象,可以像其他任何Python对象一样来传递。
内置sorted()函数,能够从任何可迭代对象返回有序列表:
>>> x = [4,3,1,2]
>>> y = sorted(x)
>>> y
[1, 2, 3, 4]
当reverse=True时,可以实现逆向排序:
>>> z = sorted(x, reverse=True)
>>> z
[4, 3, 2, 1]
5)其他常用列表操作
用in操作符判断列表成员:
>>> z
[4, 3, 2, 1]
>>> 3 in z
True
>>> 5 in z
False
>>> 7 not in z
True
使用+操作符拼接列表:
>>> m = z + [7, 8, 9]
>>> m
[4, 3, 2, 1, 7, 8, 9]
用*操作符初始化列表:
>>> z = [None] * 4
>>> z
[None, None, None, None]
>>> z = [3, 2] *4
>>> z
[3, 2, 3, 2, 3, 2, 3, 2]
用min和max方法求列表的最小值和最大值:
>>> min z
SyntaxError: invalid syntax
>>> min(z)
2
>>> max(x)
4
用index()方法搜索列表查找元素在列表的位置。
用count()方法对匹配项计数:
>>> x
[4, 3, 1, 2]
>>> x.index(3)
1
>>> x
[1, 2, 4, 5, 6, 7, 8]
>>> x.count(2)
1
常见列表操作汇总:
| 列表操作 | 说明 |
| [] | 创建空列表 |
| len | 返回列表长度 |
| append | 在列表末尾添加一个元素 |
| extend | 在列表末尾添加一个新的列表 |
| insert | 在列表的指定位置插入一个新的元素 |
| del | 删除一个列表元素或切片 |
| remove | 检索列表并且移除给定的值 |
| reverse | 原地将列表逆序 |
| sort | 原地对列表进行排序 |
| + | 将两个列表拼接在一起 |
| * | 将列表复制多份 |
| min | 返回列表中的最小元素 |
| max | 返回列表中的最大元素 |
| index | 返回某值在列表中的位置 |
| count | 对某值在列表中出现的次数记数 |
| sum | 对列表数据项计算合计值 |
| in | 返回某数据项是否为列表的元素 |
引用思维导图:
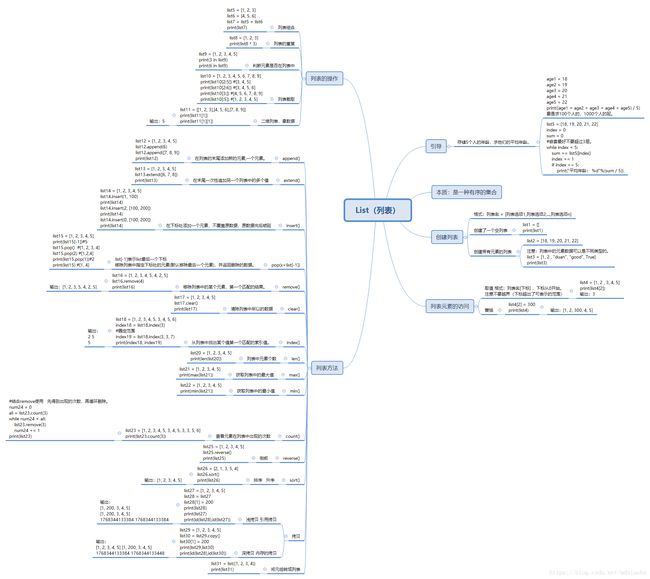
(四)元组类型
元组就像是不可修改的列表,可被视为受限的列表类型或记录类型。后续会讨论这种受限的数据类型的必要性。对于集合类型,当一个对象在集合中的成员身份(而不是位置)很重要时,那么集合就很有用。
元组与列表类似,元组只能创建,不能修改。元组可以用作字典的键:
#新建元组
>>> x = ("a", "b", "c")
>>> x
('a', 'b', 'c')
#查找元组指定元素。
>>> x[2]
'c'
#元组中的最大值和最小值
>>> max(x)
'c'
>>> min(x)
'a'
#判断元素是否在元组内,返回布尔值。
>>> 5 in x
False
>>> 5 not in x
True
#元组 + * 操作
>>> x + x
('a', 'b', 'c', 'a', 'b', 'c')
>>> 2 * x
('a', 'b', 'c', 'a', 'b', 'c')
#新建元组副本
>>> y = x[:]
>>> y
('a', 'b', 'c')
#单个元素的元组应加上逗号
>>> x = 3
>>> y = 4
#相当于二者加和
>>> (x + y)
7
#加 , 意味着圆括号是用来标识元组的
>>> (x + y, )
(7,)
#创建一个新元组
>>> ()
()
元组的打包和拆包
Python允许元组出现在赋值操作符的左侧,这是元组中的变量会依次被赋予赋值操作符右侧元组的元素值
>>> (one, two, three, four) = (1, 2, 3, 4)
>>> one
1
>>> two
2
在赋值时,即使没有圆括号,Python也可以识别出元组,这时等号右侧的值会被打包为元组,然后拆包到左侧的变量中去。
>>> five, six, seven, eight = 5, 6, 7, 8
>>> five
5
交换两个变量:
>>> var1 = 1
>>> var2 = 2
>>> var1, var2 = var2, var1
>>> var1
2
>>> var2
1
扩展拆包的特性:允许带*的元素接收任意数量的未匹配元素。
带*的元素会把多余的所有数据项接收为列表。如果没有多余的元素,则带星号的元素会收到空列表。
>>> x = (1, 2, 3, 4)
>>> a, b, *c = x
>>> a, b, c
(1, 2, [3, 4])
>>> a, b, c, d, *e = x
>>> a, b, c, d, e
(1, 2, 3, 4, [])
#列表和元组的相互转换:
>>> x = (1, 2, 3, 4)
>>> list(x)
[1, 2, 3, 4]
>>> tuple(x)
SyntaxError: invalid character in identifier
>>>
>>> tuple(x)
(1, 2, 3, 4)
引用思维导图:

(五)集合类型
集合(set)是无序集。主要用于是否属于集合、是否唯一。集合中的项必须是不可变的、可散列的。
整数、浮点数、字符串、和元组可以作为集合的成员。
列表、字典和集合本身不可以作为集合的成员。
>>> y = [1,2,3,4,5,6,7]
创建集合
>>> x = set(y)
>>> x
{1, 2, 3, 4, 5, 6, 7}
为集合添加元素
>>> x.add(8)
>>> x
{1, 2, 3, 4, 5, 6, 7, 8}
移除集合中的元素
>>> x.remove(7)
>>> x
{1, 2, 3, 4, 5, 6, 8}
判断1 是否属于集合x
>>> 1 in x
True
>>> 0 in x
False
>>> z = {5,7,8,9}
并集
>>> x | z
{1, 2, 3, 4, 5, 6, 7, 8, 9}
交集
>>> x & z
{8, 5}
对称差:属于一个但是不同时属于两个集合的元素。
>>> x ^ z
{1, 2, 3, 4, 6, 7, 9}
不可变集合
因为集合是不可变的、可散列的,所以不能用作其他集合的成员。为了让集合本身也能够成为集合的成员,采用frozenset
与集合类似,但是创建之后就不能更改了。
新建集合
>>> x = set([1,2,3,1,3,5])
frozenset集合类型:
>>> z = frozenset(x)
>>> z
frozenset({1, 2, 3, 5})
>>> z .add(9)
Traceback (most recent call last):
File "", line 1, in
z .add(9)
AttributeError: 'frozenset' object has no attribute 'add'
>>> x . add(9)
>>> x
{1, 2, 3, 5, 9}
>>> x.add(z)
>>> x
{1, 2, 3, 5, 9, frozenset({1, 2, 3, 5})}
引用思维导图:

(六)字典类型
字典,这是Python对关联数组(associative array)或映射(map)的叫法。字典通过使用散列表(hash table)实现。
主要内容:
- 定义字典
- 利用字典操作
- 确定哪些对象可用作字典键
- 创建稀疏矩阵
- 将字典用作缓存
- 相信字典的效率
1)何为字典
不妨将字典与列表进行比较,以便能理解其用法。
- 列表中的值可以通过整数索引进行访问,索引表示了给定值在列表中的位置。
- 字典中的“值”通过“键”进行访问,键可以是整数、字符串或其他Python对象,同样表示了给定值在字典中的位置。换句话说,列表和字典都支持用索引来访问任意值,但是字典“索引”可用的数据类型比列表的索引要多得多。而且字典提供的索引访问机制与列表的完全不同。
- 列表和字典都可以存放任何类型的对象。
- 列表中存储的值隐含了按照在列表中的位置排序,因为这些值的索引是连续的整数。这种顺序可能会被忽略,但需要时就可以用到。存储在字典中的值相互之间没有隐含的顺序关系,因为字典的键不只是数字。注意,如果用字典的时候同时还需要考虑条目的顺序(指加入字典的顺序),那么可以使用有序字典。有序字典是字典类的子类,可从collections模块中导入。还可以用其他数据结构(通常是列表)来定义字典条目的顺序,显式的将顺序保存起来,但这不会改变普通字典没有隐式(内置)排序的事实。
尽管存在差异,但字典和列表的用法往往比较类似。空字典的创建就很像空列表,但是用花括号代替了方括号:
>>> x = []
>>> y = {}
列表创建完毕后,就可以像使用列表一样在里面存储数据值:
>>> y[0] = 'Hello'
>>> y[1] = 'Goodbye'
如果对列表做同样的操作,就会引发错误。因为在Python中,对列表中不存在的位置赋值时非法的。列表的索引必须是整数,而字典的键则没有什么限制,可以是数字、字符串或其他很多种Python对象。
2)字典的其他操作
与keys方法类似,items方法通常与for循环结合使用,用于遍历字典中的内容:
# 创建字典
>>> english_to_french = {'red' : 'rouge', 'blue' : 'bleu', 'green' : 'vert'}
# 返回字典的条目数量
>>> len(english_to_french)
3
#返回字典中的所有键
>>> list(english_to_french.keys())
['red', 'blue', 'green']
#返回储存在字典中的所有值
>>> list(english_to_french.values())
['rouge', 'bleu', 'vert']
# 将所有键及其关联值以元组序列的形式返回
>>> list(english_to_french.items())
[('red', 'rouge'), ('blue', 'bleu'), ('green', 'vert')]
#删除
>>> del english_to_french['green']
>>> list(english_to_french.items())
[('red', 'rouge'), ('blue', 'bleu')]
#检测字典中是否存在该键
>>> 'red' in english_to_french
True
#检测是否存在该键,存在则返回键值,不存在则返回第二个参数
>>> english_to_french.get('blue' , 'No founded')
'bleu'
>>> english_to_french.get('play' , 'No founded')
'No founded'
3)字典视图对象
keys、values、和items方法返回结果都不是列表,而是视图(view)。视图的表现与序列类似,但在字典内容变化时会动态更新。这就是上例中要用list函数将结果转换为列表。除此之外,它们的表现与序列相似,允许用for循环迭代,可用in来检查成员的资格,等等。由keys方法(有时候是items方法)返回的视图还与集合有点类似,可以进行并集、差集和交集操作。
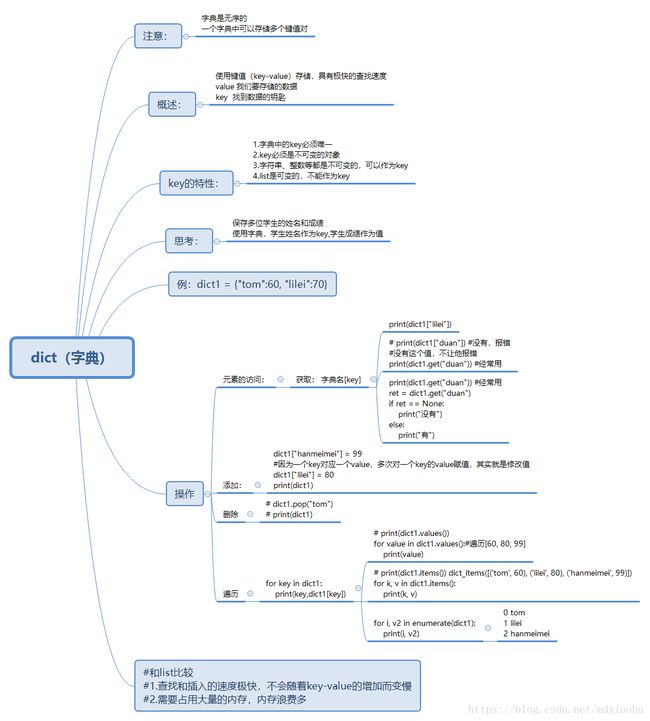
参考:
- 思维导图来源:https://blog.csdn.net/mdxiaohu/article/details/81811459
- 《THE Quick Python Book》(THIRD EDITIION) Naomi Ceder
- 菜鸟教程
- B站:小甲鱼课程