MegDet 与 Synchronized BatchNorm
旷视科技(Face++)的 MegDet 网络取得了 COCO 2017 Challenge 竞赛的检测项目冠军,论文 MegDet: A Large Mini-Batch Object Detector 对该检测器进行了介绍。
摘要
深度学习时代的目标检测发展——从 R-CNN、Fast/Faster R-CNN 到最近的 MaskR-CNN 和 RetinaNet,主要来自新网络、新结构或损失设计。然而,作为深度神经网络训练的一个关键因素,mini-batch 的大小在目标检测方面还没有很好地进行研究。本文提出了一种大 mini-batch 目标检测器(MegDet),可以实现最大 mini-batch 为256的训练,从而可以有效利用最多128个 GPU 以显着缩短训练时间。从技术上讲,我们建议采用预热学习速率策略和跨 GPU 批量标准化,以上方法使我们能够在更短的时间内(例如从33小时到4小时)训练出一个大 mini-batch 检测器,并实现更高的精度。COCO 2017 Challenge 竞赛中,我们提交的方法(mmAP 52.5%)赢得了检测任务的冠军,而 MegDet 是其中的支柱。
简介
在基于CNN的图像分类任务中,近期趋势为使用非常大的 min-batch 来显着加快训练速度。例如,使用8192或16000 的 mini-batch,ResNet-50 的训练可以在一小时内完成,甚至31分钟,而准确率方面的损失很小或没有。相反,在目标检测文献中,mini-batch 保持非常小(例如 2~16)。因此,本文研究了目标检测中 mini-batch 大小的问题,并提出了一种训练大 mini-batch 目标检测器的方案。
小 mini-batch 有什么问题? 在 Faster R-CNN 和 R-FCN 等流行检测器中广泛采用仅涉及 2 2 2个图像的 mini-batch,而这发源于 R-CNN 系列目标检测器。尽管在像 RetinaNet 和 Mask R-CNN 这样最先进的检测器中,mini-batch 的尺寸增加到了 16 16 16,但与当前图像分类中使用的小批量尺寸(例如256)相比,仍然非常小。小 mini-batch 有几个潜在的缺点:
- 首先,训练时间非常长。例如,在 COCO 上训练 ResNet-152 需要3天(在配备8个 Titian XP GPU 的机器上设置 mini-batch 为16)。
- 其次,使用小 mini-batch 训练无法为 batch normalization(BN)提供准确的统计信息。为了获得良好的批量归一化统计,ImageNet 分类网络的最小批量大小通常设置为256,这比当前目标检测器设置中使用的 mini-batch 要大得多。
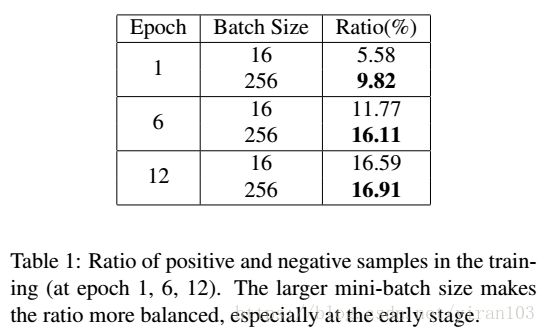
- 最后,小 mini-batch 中的正负训练样本的数量更可能不平衡,这可能会伤害最终的准确性。下图给出了一些不平衡正负提议的例子。Table 1比较了在 COCO 数据集上两个不同 mini-batch 的检测器不同训练时期的统计数据。


简单地增加最小批量大小有什么挑战? 正如图像分类问题一样,我们面临的主要困境是:根据“等效学习率规则”[13][21],大 min-batch 通常需要大的学习率来保持准确性。但是,目标检测中大学习率很可能导致收敛失败;而如果我们使用较小的学习速率来确保收敛,通常会得到较差的结果。
为了摆脱上述困境,我们提出如下解决方案:
- 首先,我们提出了线性缩放规则的一个新解释,并借用“warmup”学习率策略在最初阶段逐步提高学习速率,从而确保训练的收敛性;
- 其次,为了解决准确性和收敛性问题,我们引入了跨 GPU 批量归一化(CGBN)以获得更好的 BN 统计数据。CGBN 不仅提高了准确性,而且使训练更加稳定。这非常重要,因为我们能够安全地享受行业快速增长的计算能力。
我们的 MegDet(ResNet-50作为主干)可以在128个 GPU 上于4个小时内完成 COCO 训练,并达到更高的准确度。相比之下,对应的小 mini-batch 机器需要33小时且准确率较低。这意味着我们可以将创新周期加快几个数量级,且甚至具有更好的性能,如下图所示。MegDet 确保了我们 COCO 2017 Challenge 的冠军位置。

本文的技术贡献可以概括为:
- 本文根据维持等效损失方差的假设,在目标检测语境下给出线性缩放规则的新解释。
- 本文首次在目标检测框架中训练 BN。我们证明,跨 GPU 批量归一化不仅有利于精度,而且还使得训练易于收敛,特别是对于大 mini-batch。
- 我们首次在4小时内完成 COCO 训练(基于ResNet-50),其中使用了128个 GPU,并实现更高的精度。
- MegDet 造就了 COCO 2017 Challenge 的胜利。
相关工作
R-CNN 于2014年首次推出。它采用 Selective Search 来生成一组区域提议,然后通过 CNN 识别模型对拉伸后的图像块进行分类。由于拉伸过程的计算量很大,因此 SPPNet 的改进是通过对经空间金字塔池化的特征图而不是调整大小后的原始图像进行分类。Fast-RCNN 将空间金字塔池化(SPP)简化为 ROIPooling。尽管 Fast-RCNN 已经提供相当不错的性能,但它仍然依赖传统方法,如 Selective Search 来生成提议。
Faster R-CNN 用区域建议网络(Region Proposal Network,RPN)取代传统的候选区域生成方法,并提出了一种端到端的检测框架。如果 proposal 数量很大,Faster R-CNN 的计算成本将显着增加。R-FCN 引入位置敏感池化(Position Sensitive ROI Pooling,PSROI Pooling)以获得速度与精确度的折衷。最近的工作更侧重于提高检测性能。Deformable ConvNets 使用学习的偏移来对特征地图的不同位置进行卷积,并迫使网络专注于目标。 FPN 引入了特征金字塔技术,并在小物体检测方面取得重大进展。由于 FPN 平衡了准确性和实现,我们将其用作默认检测框架。为了解决对齐问题,Mask R-CNN 引入了 ROIAlign 并达到了目标检测和实例分割的领先结果。
方法
本节将介绍我们的大 mini-batch 检测器(MegDet),以在更短的时间内实现更高的准确度。
小 Mini-Batch 的问题
使用小 mini-batch 训练时,存在一些问题。
- 首先,如果使用小 mini-batch 训练,我们必须花费更长的训练时间。如图Figure 2所示,最小批量为16时,训练 ResNet-50 检测器需要30多个小时。设置最小批量为 2 2 2,则训练时间可能超过一周。
- 其次,在检测器的训练中,我们通常固定批量归一化的统计量并使用在ImageNet数据集上预先计算的值。因为小 mini-batch 不适于重新训练 BN 层。这是一个次优的选择,因为两个数据集 COCO 和 ImageNet 差别很大。
- 最后,正负样本的比例可能非常不平衡。在Table 1中,我们提供了正负训练样本比率的统计数据。我们可以看到,小 mini-batch 导致更多不平衡的训练实例,特别是在初始阶段。这种不平衡可能会影响整体检测性能。
正如我们在简介中所讨论的,简单地增加 mini-batch 必须在收敛性和准确度之间做出抉择。为了解决这个问题,我们首先讨论大 mini-batch 的学习率策略。
大 mini-batch 学习率
学习率策略与 SGD 算法密切相关。因此,我们首先回顾目标检测网络的损失结构:
L ( x , w ) = 1 N ∑ i = 1 N l ( x i , w ) + λ 2 ∣ ∣ w ∣ ∣ 2 2 = l ( x , w ) + l ( w ) , \begin{array}{lcl}L(x, w) & = & \frac{1}{N} \sum_{i=1}^N l(x_i, w) + \frac{\lambda}{2}||w||_2^2 \\ & = & l(x, w) + l(w),\end{array} L(x,w)==N1∑i=1Nl(xi,w)+2λ∣∣w∣∣22l(x,w)+l(w),
其中 N N N 是最小批量大小, l ( x , w ) l(x, w) l(x,w) 是任务特定损失, l ( w ) l(w) l(w) 是正则化损失。 对于 Faster R-CNN 框架及其变体(R-FCN、FPN、Mask R-CNN), l ( x i , w ) l(x_i,w) l(xi,w) 由 RPN 预测损失、RPN 边界框回归损失、预测损失和边框回归损失组成。
根据小批量 SGD 的定义,训练系统需要计算权重 w w w 的梯度,并在每次迭代后对其进行更新。当 mini-batch 的大小发生变化时,例如 N ^ ← k ⋅ N \hat N \leftarrow k \cdot N N^←k⋅N,我们预计应该调整学习率 r r r 以保持训练的效率。之前的工作[19][13][37]使用 线性缩放规则,将新的学习速率改为 r ^ ← k ⋅ r \hat r \leftarrow k\cdot r r^←k⋅r。因为大 mini-batch N ^ \hat N N^ 中的一步应该与小 mini-batch N N N 中的 k k k 次累计步骤的效用相匹配,所以学习率 r r r 也应该乘以相同比例 k k k 以抵消损失中的比例因子。这基于 SGD 更新中的梯度等价假设。这一经验法则在图像分类中得到了很好的验证,我们发现它仍然适用于目标检测。但是,本文基于一个更弱更好的假设,给出了不同的解释。
在图像分类中,每个图像只有一个标注, l ( x , w ) l(x, w) l(x,w) 是一个简单的交叉熵形式。对于目标检测,每个图像具有不同数量的包围盒注释,导致图像之间不同的 ground-truth 分布。考虑到两个任务之间的差异,不同 mini-batch 大小之间梯度等价的假设不太可能在目标检测中成立。所以,我们根据以下方差分析介绍另一种解释。
方差等价。 与梯度等价假设不同,我们假设梯度方差在 k k k 阶段内保持不变。给定最小批量大小 N N N,如果每个样本 ∇ l ( x i , w ) \nabla l(x_i, w) ∇l(xi,w) 的梯度服从 i.i.d.(independent identically distributed,独立同分布), l ( x , w ) l(x, w) l(x,w) 上的梯度方差为:
Var ( ∇ l ( x , w t ) ) = 1 N 2 ∑ i = 1 N Var ( ∂ l ( x i , w t ) ∂ w t ) = 1 N 2 × ( N ⋅ σ l 2 ) = = 1 N σ l 2 . \begin{array}{lcl}\text{Var}(\nabla l(x, w_t)) & = & \frac{1}{N^2}\sum_{i=1}^N \text{Var}(\frac{\partial l(x_i, w_t)}{\partial w_t}) \\ \\ & = & \frac{1}{N^2} \times \left(N \cdot \sigma^2_l \right )\\ \\ & = & = \frac{1}{N} \sigma^2_l.\end{array} Var(∇l(x,wt))===N21∑i=1NVar(∂wt∂l(xi,wt))N21×(N⋅σl2)=N1σl2.
同样,对于大 mini-batch N ^ = k ⋅ N \hat N = k \cdot N N^=k⋅N,我们可以得到下面的表达式:
Var ( ∇ l N ^ ( x , w t ) ) = 1 k N σ l 2 . \text{Var}(\nabla l_{\hat N}(x, w_t)) = \frac{1}{kN} \sigma^2_l. Var(∇lN^(x,wt))=kN1σl2.
我们希望维持大 mini-batch N ^ \hat N N^ 中一个更新的方差等于小 mini-batch N N N 中 k k k 个累计步骤的方差,而不是期望权重更新等价。为了实现这一点,我们有:
Var ( r ⋅ ∑ t = 1 k ( ∇ l N t ( x , w ) ) ) = r 2 ⋅ k ⋅ Var ( ∇ l N ( x , w ) ) ≈ r ^ 2 Var ( ∇ l N ^ ( x , w ) ) \begin{array}{lcl}\text{Var}(r \cdot \sum_{t=1}^k(\nabla l_{N}^t(x, w)) ) & = & r^2\cdot k\cdot \text{Var}(\nabla l_N(x, w)) \\ &\approx & \hat r^2 \text{Var}(\nabla l_{\hat N}(x, w))\end{array} Var(r⋅∑t=1k(∇lNt(x,w)))=≈r2⋅k⋅Var(∇lN(x,w))r^2Var(∇lN^(x,w))
在等式(2)和等式(3)中,当且仅当 r ^ = k ⋅ r \hat r = k\cdot r r^=k⋅r 时上述等式成立,它给出 r ^ \hat r r^ 的相同线性缩放规则。
虽然最终的缩放规则是相同的,公式(4)上的方差等价假设较弱。因为我们只是预期大 mini-batch 训练能够保持等效的梯度统计量。我们希望这里的方差分析能够让我们深入了解更广泛的应用中的学习率。
热身策略。线性缩放规则可能不适用于训练的初始阶段,因为权重的改变是显著的。为了解决这个实际问题,我们借用线性梯度热身。也就是说,我们在开始时设置足够小的学习率,例如 r r r;然后,我们在每次迭代后以恒定速度增大学习率,直到 r ^ \hat r r^。
热身策略有助于收敛。但是,正如我们在后面的实验中所展示的那样,这对于较大的 mini-batch(例如128或256)来说是不够的。接下来,我们介绍 Cross-GPU Batch Normalization,这是大 mini-batch 训练的主力。
Cross-GPU Batch Normalization
Batch Normalization 对于训练非常深的卷积神经网络来说非常重要。如果没有批量归一化,训练如此深的网络会消耗更多的时间,甚至无法收敛。但是,以前的目标检测框架(如FPN)会使用 ImageNet 上预训练的模型对模型进行初始化,然后在整个微调过程中锁定批量归一化层。 在这项工作中,我们试图为目标检测执行批量归一化。
值得注意的是,分类网络的输入图像通常为 224 × 224 224\times{}224 224×224 或 299 × 299 299\times{}299 299×299,而具有12GB 内存的单个 NVIDIA TITAN Xp GPU 足以容纳32张或更多图像。这意味着,可以在每个设备上单独计算批量归一化。但对于目标检测,检测器需要处理各种尺度的物体,因此需要更高分辨率的输入图像。FPN 中,使用大小为 800 × 800 800\times{}800 800×800 的输入,这极大限制了单个设备上的样本数量。因此,我们必须跨越多个 GPU 执行批量归一化,以便从更多样本中收集足够的统计信息。
要实现跨 GPU 的批量归一化,我们需要计算所有设备上汇总的均值/方差统计。大多数现有的深度学习框架使用 cuDNN 中的 BN 实现,它只提供高级 API 而不允许修改内部统计信息。因此,我们需要预先根据数学表达式来实现 BN,然后使用 AllReduce 操作来聚合这些统计信息。这些细粒度的表达式通常会导致大量的运行时间开销,并且大多数框架中都没有 AllReduce 操作。
跨 GPU 批量归一化的实现草图如图下所示。假设总共 n n n 个 GPU 设备,则首先计算设备 k k k 上的训练示例总和 s k s_k sk。通过平均来自所有设备的和值,我们获得当前 mini-batch 的平均值 μ B \mu_{\mathcal{B}} μB。这一步需要一个 AllReduce 操作。然后我们计算每个设备的方差并得到 σ B 2 \sigma^2_{\mathcal{B}} σB2。在向所有设备广播 σ B 2 \sigma^2_{\mathcal{B}} σB2 之后,我们可以通过 y = γ x − μ B σ B 2 + ϵ + β y= \gamma \frac{x-\mu_{\mathcal{B}}}{\sqrt{\sigma^2_{\mathcal{B}}+\epsilon}}+ \beta y=γσB2+ϵx−μB+β 实现归一化。算法 Algorithm 1给出了详细的流程。在我们的实现中,我们使用 NVIDIA 聚合通信库(NCCL)来有效地执行 AllReduce 操作的接收和广播。


请注意,我们只在同一台机器的 GPU 上执行 BN。所以,如果每个 GPU 可以容纳2张图像,我们可以计算16张图像的 BN 统计量。为实现在32或64张图像上执行 BN,我们应用 sub-linear memory,以训练速度的稍许降低来节省 GPU 内存消耗。
在下一节中,我们的实验结果将证明 CGBN 对准确性和收敛性的巨大影响。
实验
我们在 COCO Detection Dataset 上进行了实验,将该数据集划分为训练、验证和测试三个子集,其中共包含80个类别和超过 250 , 000 250,000 250,000 张图像。我们使用在 ImageNet 上预先训练的 ResNet-50 作为骨干网络并以 Feature Pyramid Network (FPN) 作为检测框架。检测器训练使用超过118,000张训练图像并在5000张验证图像上进行评估。我们使用动量为0.9的 SGD 优化器,并采用0.0001的权重衰减。mini-batch 为16的基本学习率是 0.02 0.02 0.02。对于其他设置,应用上节中描述的线性缩放规则。对于大 mini-batch,我们使用 sub-linear memory 和分布式训练来弥补 GPU 的内存限制。
我们有以下两种训练策略:
- normal,在第8和第10个 epoch 减少学习率(乘以比例0.1),在第11次结束;
- long,在第11和第14个 epoch 学习率降为原来的十分之一,第17个 epoch 学习速率减半,并在第18次结束。
除非另有说明,否则我们使用 normal 策略。
大 mini-batch,无 BN
我们通过不使用批量归一化并设置不同的 mini-batch 大小来开始我们的研究。我们以最小批量16、32、64和128进行实验。对于最小批量32,我们观察到训练有一些失败的几率,即使我们使用热身策略。对于最小批量64,我们即便加入热身策略也无法使训练收敛,必须将学习率降低一半。对于最小批量128,预热和半学习率亦不能避免训练失败。COCO 验证集的结果显示在 Table 2中。
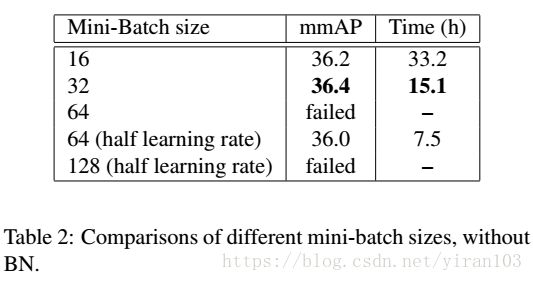
我们可以观察到:
- 与使用16的基线相比,最小批量32的加速几乎是线性的,没有精度损失;
- 较低的学习率(最小批量64)导致明显的准确度损失;
- 当小批次和学习率较大时,即使采用热身策略,训练也会变得更难甚至不可能。
大 mini-batch,带 CGBN
这部分实验通过批量归一化进行训练。我们的第一个关键观察是当将热身策略与 CGBN 结合使用时,无论最小批量是多少,所有训练很容易收敛。这是极好的,因为我们不必担心小学习率可能导致的精度损失。
主要结果汇总在 Table 3中。
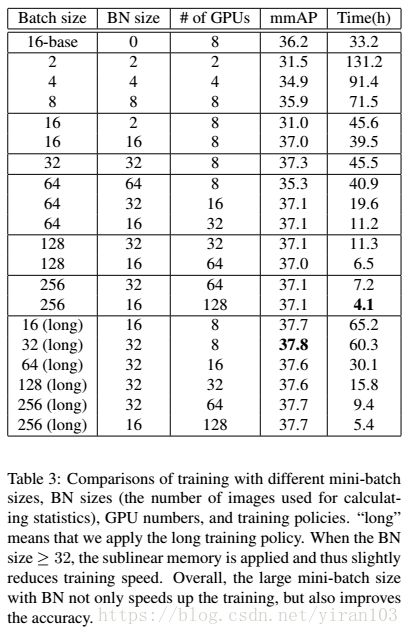
我们观察到:
-
首先,在最小批量增加的情况下,精度几乎保持不变,并且一直比基线(以16为基准)好。与此同时,更大的 mini-batch 通常会缩短训练周期。例如,拥有128个 GPU 最小批量为128的实验仅在4.1小时内就完成了 COCO 训练,这意味着相比 33.2 33.2 33.2 小时基线获得了 8 × 8\times 8× 的加速。
-
其次,最好的 BN 大小(用于 BN 统计的图像数量)是32。图像太少(2、4、8)时,BN 的统计数据非常不准确,从而导致较差的性能。但是,当我们将大小增加到64时,精度会下降。这证明了图像分类与目标检测任务之间的不匹配。
-
第三,在 Table 3的最后部分,我们研究了长期训练策略。训练时间越长,精确度越高。例如,“32 (long)”与其对照相比更好(37.8比37.3)。当最小批量大于16时,最终结果非常一致,这表明真正的收敛。
-
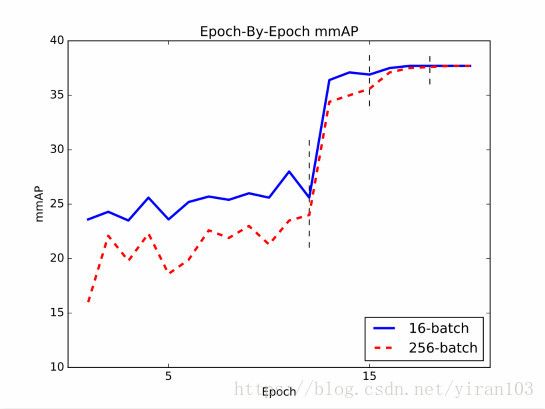
最后,我们在下图中绘制了“16 (long)” 和“256 (long)”每个时期的mmAP曲线。 “256 (long)”在早期较差,但在最后阶段(第二次学习速率衰减后)追平了“16 (long)”。这一观察结果与图像分类[13,39]中不同,后者的准确率曲线和收敛得分在不同的最小批量设置之间非常接近。我们将这种现象的理解留给后续工作。
Appendix
基于 MegDet,我们整合了包括 OHEM、atrous convolution[40,2]、更强基础模型[38,18]、大内核 、分割监督[27,34]、多样化的网络结构[12,32,36]、contextual modules[22,19]、ROIlign 以及针对 COCO 2017目标检测挑战赛进行多尺度训练和测试。我们在验证集上获得了50.5 mmAP,并在test-dev上获得了50.6 mmAP。集成4个检测器后达到了52.5。Table 4汇总了 COCO 2017 Challenge 排行榜上的成绩。

SyncBNLayer
MegDet 可以说是第一个现代化的检测器。它在达到领先性能的同时显著提升了训练的效率。然而跨 GPU 批量归一化其实在图像分割和动作识别中已有应用,因为二者受显存的限制程度甚于目标检测。但不知是疏忽还是阐述角度的问题,上文并未提到。
yjxiong/caffe 基于 OpenMPI 实现了跨 GPU 的 BN。SyncBNLayer 首先计算局部均值 E [ x ] E[x] E[x] 和局部平方均值 E [ x 2 ] E[x^2] E[x2],然后通过调用MPI 规约函数得到全局统计数据。
Caffe2 中将 NCCL 函数封装成了op,相当于提供了官方范例。所以实现 SyncBN 应该也比较容易。
SyncBNLayer 定义在common_layers.hpp,不知道是哪个版本。接口与 BatchNormLayer 一致,成员反而更少。
#ifdef USE_MPI
template <typename Dtype>
class SyncBNLayer : public Layer<Dtype> {
public:
explicit SyncBNLayer(const LayerParameter& param)
: Layer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "SyncBN"; }
virtual inline int ExactNumBottomBlobs() const { return 1; }
virtual inline int ExactNumTopBlobs() const { return 1; }
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
Dtype bn_momentum_;
Dtype bn_eps_;
int num_;
int channels_;
int height_;
int width_;
Blob<Dtype> mean_buffer_;
Blob<Dtype> var_buffer_;
};
#endif
SyncBNLayer::LayerSetUp
读取层参数。SyncBNLayer 与 BNLayer 共享参数。
bn_momentum_ = this->layer_param_.bn_param().momentum();
bn_eps_ = this->layer_param_.bn_param().eps();
GetFiller 函数根据 FillerParameter 参数获取特定的填充符。
设置参数的形状,其中 N=1。共4个参数。
// Initialize parameters
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
this->blobs_.resize(4);
vector<int> shape;
shape.push_back(1);
shape.push_back(bottom[0]->channels());
// slope
this->blobs_[0].reset(new Blob<Dtype>(shape));
shared_ptr<Filler<Dtype> > slope_filler(GetFiller<Dtype>(
this->layer_param_.bn_param().slope_filler()));
slope_filler->Fill(this->blobs_[0].get());
// bias
this->blobs_[1].reset(new Blob<Dtype>(shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.bn_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
// moving average mean
this->blobs_[2].reset(new Blob<Dtype>(shape));
caffe_set(this->blobs_[2]->count(), Dtype(0),
this->blobs_[2]->mutable_cpu_data());
// moving average variance
this->blobs_[3].reset(new Blob<Dtype>(shape));
caffe_set(this->blobs_[3]->count(), Dtype(0),
this->blobs_[3]->mutable_cpu_data());
}
this->param_propagate_down_.resize(this->blobs_.size(), true);
运行平均统计不使用权重衰减和学习率。
向 layer_param_ 添加4个成员(ParamSpec),设置第3( moving average mean)和第4个(moving average variance)学习率为0。
lr_mult 和 decay_mult 均属于 ParamSpec。ParamSpec 指定训练参数(全局学习常数的乘数,以及用于权重共享的名称和其他设置)。
// runing average stats does not use weight decay and learning rate
while (this->layer_param_.param_size() < 4){
this->layer_param_.mutable_param()->Add();
}
this->layer_param_.mutable_param(2)->set_lr_mult(Dtype(0));
this->layer_param_.mutable_param(2)->set_decay_mult(Dtype(0));
this->layer_param_.mutable_param(3)->set_lr_mult(Dtype(0));
this->layer_param_.mutable_param(3)->set_decay_mult(Dtype(0));
SyncBNLayer::Reshape
设置mean_buffer_和var_buffer_的形状。
num_ = bottom[0]->num();
channels_ = bottom[0]->channels();
height_ = bottom[0]->height();
width_ = bottom[0]->width();
top[0]->ReshapeLike(*(bottom[0]));
mean_buffer_.Reshape(1, channels_, 1, 1);
var_buffer_.Reshape(1, channels_, 1, 1);
SyncBNLayer::Forward_cpu和SyncBNLayer::Backward_cpu未实现。
SyncBNLayer::Forward_gpu
如果是测试,调用kernel_test_forward 。
if (this->phase_ == TEST) {
kernel_test_forward<<<CAFFE_GET_BLOCKS(bottom[0]->count()),
CAFFE_CUDA_NUM_THREADS>>>(
num_, channels_, height_ * width_,
this->blobs_[0]->gpu_data(),
this->blobs_[1]->gpu_data(),
this->blobs_[2]->gpu_data(),
this->blobs_[3]->gpu_data(),
bn_eps_,
bottom[0]->gpu_data(),
top[0]->mutable_gpu_data()
);
CUDA_POST_KERNEL_CHECK;
否则调用kernel_local_stats计算局部均值 E [ x ] E[x] E[x]和平方均值 E [ x 2 ] E[x^2] E[x2]。
Caffe::MPI_all_rank() 返回mpi_all_rank_。MPI_build_rank() 调用 MPI_Comm_size,确定与通信器关联的组的大小。
m为相同通道的元素数量。
} else {
const int m = num_ * height_ * width_ * Caffe::MPI_all_rank();
// compute local E[x] and E[x^2]
kernel_local_stats<<<channels_, CAFFE_CUDA_NUM_THREADS>>>(
num_, channels_, height_ * width_,
static_cast<Dtype>(m),
bottom[0]->gpu_data(),
mean_buffer_.mutable_gpu_data(),
var_buffer_.mutable_gpu_data()
);
CUDA_POST_KERNEL_CHECK;
对 E [ x ] E[x] E[x]和 E [ x 2 ] E[x^2] E[x2]进行规约。mpi_force_synchronize()调用MPIComm::Syncrhonize()。
// sync E[x] and E[x^2]
mpi_force_synchronize();
caffe_iallreduce(mean_buffer_.mutable_cpu_data(), channels_);
caffe_iallreduce(var_buffer_.mutable_cpu_data(), channels_);
mpi_force_synchronize();
计算方差 V a r Var Var,复用top[0]存储全局 E [ x ] 2 E[x]^2 E[x]2。
s 2 = n n − 1 σ 2 s^2 = \frac{n}{n-1}\sigma^2 s2=n−1nσ2
// var = (E[x^2] - E[x]^2) * bias_correction_factor
caffe_gpu_mul(channels_, mean_buffer_.gpu_data(), mean_buffer_.gpu_data(),
top[0]->mutable_gpu_data()); // reuse the top buffer
caffe_gpu_sub(channels_, var_buffer_.gpu_data(), top[0]->gpu_data(),
var_buffer_.mutable_gpu_data());
if (m > 1) {
caffe_gpu_scal(channels_, Dtype(m) / (m-1),
var_buffer_.mutable_gpu_data());
}
更新运行均值和方差。
μ B = ( 1 − η ) μ ^ B + η μ B σ B 2 = ( 1 − η ) σ ^ B 2 + η σ B 2 \mu_B = (1-\eta)\hat{\mu}_B + \eta\mu_B\\ \sigma_B^2 = (1-\eta)\hat{\sigma}_B^2 + \eta\sigma_B^2 μB=(1−η)μ^B+ημBσB2=(1−η)σ^B2+ησB2
// update running mean and var
caffe_gpu_axpby(mean_buffer_.count(),
Dtype(1) - bn_momentum_, mean_buffer_.gpu_data(),
bn_momentum_, this->blobs_[2]->mutable_gpu_data());
caffe_gpu_axpby(var_buffer_.count(),
Dtype(1) - bn_momentum_, var_buffer_.gpu_data(),
bn_momentum_, this->blobs_[3]->mutable_gpu_data());
计算输出。
x ^ i ← x i − μ B σ B 2 + ϵ y i ← γ x ^ i + β ≡ BN γ , β ( x i ) \begin{array}{lcl}\hat{x}_i& \leftarrow & \frac{x_i-\mu_B}{\sqrt{\sigma_B^2+\epsilon}} \\ y_i &\leftarrow & \gamma\hat{x}_i + \beta \equiv \text{BN}_{\gamma,\beta}(x_i)\end{array} x^iyi←←σB2+ϵxi−μBγx^i+β≡BNγ,β(xi)
// compute output
kernel_test_forward<<<CAFFE_GET_BLOCKS(bottom[0]->count()),
CAFFE_CUDA_NUM_THREADS>>>(
num_, channels_, height_ * width_,
this->blobs_[0]->gpu_data(),
this->blobs_[1]->gpu_data(),
mean_buffer_.gpu_data(),
var_buffer_.gpu_data(),
bn_eps_,
bottom[0]->gpu_data(),
top[0]->mutable_gpu_data()
);
CUDA_POST_KERNEL_CHECK;
}
kernel_test_forward
y i = ( x i − μ c ) σ c 2 + ϵ ∗ γ c + β c y_i = \frac{(x_i-\mu_c)}{\sqrt{\sigma_c^2+\epsilon}}*\gamma_c + \beta_c yi=σc2+ϵ(xi−μc)∗γc+βc
CUDA_KERNEL_LOOP实现grid步长内的循环,每个线程每次处理一个元素,首先获取对应通道的均值、方差、斜率和偏置。
CUDA_KERNEL_LOOP(index, num * channels * spatial_dim) {
int c = (index / spatial_dim) % channels;
top_data[index] = (bottom_data[index] - mean[c]) / sqrt(var[c] + eps)
* scale[c] + bias[c];
}
kernel_local_stats
kernel_local_stats 统计每通道的局部均值和平方均值。
kernel 最后除以norm_factor的效率并不高,而放在外面会增加 kernel 启动次数。
创建共享内存变量buffer1和buffer2。
// store local E[x] to mean, E[x^2] to var temporarily
__shared__ Dtype buffer1[CAFFE_CUDA_NUM_THREADS];
__shared__ Dtype buffer2[CAFFE_CUDA_NUM_THREADS];
const int tid = threadIdx.x;
const int c = blockIdx.x;
每个线程加载并累加数据。
// load and accumulate data on each thread
buffer1[tid] = buffer2[tid] = 0;
for (int i = tid; i < num * spatial_dim; i += blockDim.x) {
const int index = i / spatial_dim * channels * spatial_dim
+ c * spatial_dim + i % spatial_dim;
buffer1[tid] += bottom_data[index];
buffer2[tid] += bottom_data[index] * bottom_data[index];
}
__syncthreads();
对于每个线程得到的数据进行树规约。
// do tree reduction
for (int s = blockDim.x / 2; s > 0; s >>= 1) {
if (tid < s) {
buffer1[tid] += buffer1[tid + s];
buffer2[tid] += buffer2[tid + s];
}
__syncthreads();
}
保存结果。
// save the result back
if (tid == 0) {
mean[c] = buffer1[0] / norm_factor;
var[c] = buffer2[0] / norm_factor;
}
SyncBNLayer::Backward_gpu
如果进行反向传播,检查是否更新参数。
if (propagate_down[0]) {
CHECK(this->param_propagate_down_[0] && this->param_propagate_down_[1])
<< "SyncBN layer params should backprop when the layer backprops";
计算局部scale和bias的梯度。
// compute local scale and bias diff
kernel_backward_scale_bias<<<channels_, CAFFE_CUDA_NUM_THREADS>>>(
num_, channels_, height_ * width_,
mean_buffer_.gpu_data(),
var_buffer_.gpu_data(),
bn_eps_,
top[0]->gpu_diff(),
bottom[0]->gpu_data(),
mean_buffer_.mutable_gpu_diff(), // temp use for local scale diff
var_buffer_.mutable_gpu_diff() // temp use for local bias diff
);
CUDA_POST_KERNEL_CHECK;
对局部梯度进行规约。
// sync scale and bias diff
mpi_force_synchronize();
caffe_iallreduce(mean_buffer_.mutable_cpu_diff(), channels_);
caffe_iallreduce(var_buffer_.mutable_cpu_diff(), channels_);
mpi_force_synchronize();
除以 GPU 数量使得在计算 ∂ J ∂ X \frac{\partial J}{\partial X} ∂X∂J 时与单卡公式相同。
// add to param blobs diff
caffe_gpu_axpy(channels_, Dtype(1) / Caffe::MPI_all_rank(),
mean_buffer_.gpu_diff(),
this->blobs_[0]->mutable_gpu_diff());
caffe_gpu_axpy(channels_, Dtype(1) / Caffe::MPI_all_rank(),
var_buffer_.gpu_diff(),
this->blobs_[1]->mutable_gpu_diff());
计算梯度 ∂ J ∂ X \frac{\partial J}{\partial X} ∂X∂J。
// compute bottom diff
kernel_backward_bottom<<<CAFFE_GET_BLOCKS(bottom[0]->count()),
CAFFE_CUDA_NUM_THREADS>>>(
num_, channels_, height_ * width_,
this->blobs_[0]->gpu_data(),
this->blobs_[1]->gpu_data(),
mean_buffer_.gpu_data(),
var_buffer_.gpu_data(),
bn_eps_,
static_cast<Dtype>(num_ * height_ * width_ * Caffe::MPI_all_rank()),
top[0]->gpu_diff(),
mean_buffer_.gpu_diff(),
var_buffer_.gpu_diff(),
bottom[0]->gpu_data(),
bottom[0]->mutable_gpu_diff()
);
}
kernel_backward_scale_bias
计算损失 J J J 对参数 γ \gamma γ 和 β \beta β 的梯度。
∂ J ∂ γ = ∑ i ∂ J ∂ y i ⊙ x ^ i ∂ J ∂ β = ∑ i ∂ J ∂ y i \begin{array}{lcl}\frac{\partial J}{\partial \gamma} & = & \sum_i \frac{\partial J}{\partial y_i} \odot \hat{x}_i \\ \\ \frac{\partial J}{\partial \beta} & = & \sum_i \frac{\partial J}{\partial y_i}\end{array} ∂γ∂J∂β∂J==∑i∂yi∂J⊙x^i∑i∂yi∂J
为每个线程创建两个共享内存。
__shared__ Dtype buffer1[CAFFE_CUDA_NUM_THREADS];
__shared__ Dtype buffer2[CAFFE_CUDA_NUM_THREADS];
const int tid = threadIdx.x;
const int c = blockIdx.x;
buffer1[tid] = ∑ i + = blockDim ∂ J ∂ y i + tid ⊙ x ^ i + tid buffer2[tid] = ∑ i + = blockDim ∂ J ∂ y i + tid \begin{array}{lcl}\text{buffer1[tid]} & = & \sum_{i+=\text{blockDim}} \frac{\partial J}{\partial y_{i+\text{tid}}} \odot \hat{x}_{i+\text{tid}} \\ \\ \text{buffer2[tid]} & = & \sum_{i+=\text{blockDim}} \frac{\partial J}{\partial y_{i+\text{tid}}}\end{array} buffer1[tid]buffer2[tid]==∑i+=blockDim∂yi+tid∂J⊙x^i+tid∑i+=blockDim∂yi+tid∂J
// load and accumulate data on each thread
buffer1[tid] = buffer2[tid] = 0;
for (int i = tid; i < num * spatial_dim; i += blockDim.x) {
const int index = i / spatial_dim * channels * spatial_dim
+ c * spatial_dim + i % spatial_dim;
buffer1[tid] += top_diff[index] * (bottom_data[index] - mean[c])
/ sqrt(var[c] + eps);
buffer2[tid] += top_diff[index];
}
__syncthreads();
对于 block 内的结果进行树型规约。
// do tree reduction
for (int s = blockDim.x / 2; s > 0; s >>= 1) {
if (tid < s) {
buffer1[tid] += buffer1[tid + s];
buffer2[tid] += buffer2[tid + s];
}
__syncthreads();
}
存储结果。
// save the result back
if (tid == 0) {
scale_diff[c] = buffer1[0];
bias_diff[c] = buffer2[0];
}
kernel_backward_bottom
基于 ∂ J ∂ γ \frac{\partial J}{\partial \gamma} ∂γ∂J 和 ∂ J ∂ β \frac{\partial J}{\partial \beta} ∂β∂J 计算 ∂ J ∂ X \frac{\partial J}{\partial X} ∂X∂J:
∂ J ∂ X = 1 N γ ⊙ 1 σ 2 + ϵ [ − ∂ J ∂ γ ⊙ X ^ + N ∂ J ∂ Y − 1 N ⋅ ∂ J ∂ β ] = γ ⊙ 1 σ 2 + ϵ [ ∂ J ∂ Y − ∂ J ∂ γ ⊙ X ^ + 1 N ⋅ ∂ J ∂ β N ] \begin{array}{lcl}\frac{\partial J}{\partial X} & = & \frac{1}{N} \gamma \odot \frac{1}{\sqrt{\sigma^2 + \epsilon}} \bigg[-\frac{\partial J}{\partial \gamma} \odot \hat{X} + N \frac{\partial J}{\partial Y} - \mathbf{1}_N \cdot \frac{\partial J}{\partial \beta} \bigg] \\ \\ & = & \gamma \odot \frac{1}{\sqrt{\sigma^2 + \epsilon}} \bigg[ \frac{\partial J}{\partial Y} - \frac{ \frac{\partial J}{\partial \gamma} \odot \hat{X} + \mathbf{1}_N \cdot \frac{\partial J}{\partial \beta} }{N} \bigg]\end{array} ∂X∂J==N1γ⊙σ2+ϵ1[−∂γ∂J⊙X^+N∂Y∂J−1N⋅∂β∂J]γ⊙σ2+ϵ1[∂Y∂J−N∂γ∂J⊙X^+1N⋅∂β∂J]
CUDA_KERNEL_LOOP(index, num * channels * spatial_dim) {
int c = (index / spatial_dim) % channels;
const Dtype inv_std = Dtype(1) / sqrt(var[c] + eps);
const Dtype x_norm = (bottom_data[index] - mean[c]) * inv_std;
bottom_diff[index] = scale[c] * inv_std *
(top_diff[index] - (x_norm * scale_diff[c] + bias_diff[c]) / norm_factor);
}
caffe_iallreduce
caffe_iallreduce 调用 MPIComm::AddJob
template <typename Dtype>
void caffe_iallreduce(Dtype* src_data, Dtype* dst_data, int count){
MPIJob job = {src_data, dst_data, count, sizeof(Dtype), OP_SUM_ALL};
MPIComm::AddMPIJob(job);
}
mpi_force_synchronize()

void mpi_force_synchronize(){
MPIComm::Syncrhonize();
}
MPIComm
MPIComm拥有两个条件变量cond_work_和cond_finish_。
MPIComm::AddJob和MPIComm::EndProcessing()通过cond_work_通知MPIComm::ThreadFunc();
MPIComm::ThreadFunc()通过cond_finish_通知MPIComm::WaitAll()。

MPIComm 是一个单例类,并且使用了boost::mutex、boost::condition_variable和boost::atomic。
Get() 在创建 MPIComm 对象后会调用 MPIComm::StartProcessing()。
class MPIComm{
public:
~MPIComm();
inline static MPIComm& Get() {
if (!singleton_.get()) {
singleton_.reset(new MPIComm());
singleton_->StartProcessing();
}
return *singleton_;
}
inline static void AddMPIJob(MPIJob job){ Get().AddJob(job);};
inline static void Syncrhonize(){Get().WaitAll();}
private:
MPIComm();
void ThreadFunc();
void DispatchJob(MPIJob& job);
bool IsRunning();
bool IsIdle();
void StartProcessing();
void EndProcessing();
void AddJob(MPIJob new_job);
void WaitAll();
queue<MPIJob> task_queue_;
mutable mutex queue_mutex_;
atomic<bool> running_, started_;
shared_ptr<boost::thread> thread_;
condition_variable cond_work_;
condition_variable cond_finish_;
static shared_ptr<MPIComm> singleton_;
};
};
MPIComm::StartProcessing()
启动传输线程。
void MPIComm::StartProcessing() {
running_.store(true);
// start the transmission thread
try {
thread_.reset(
new boost::thread(&MPIComm::ThreadFunc, this));
} catch (...) {
LOG(FATAL)<<"Cannot start MPI comminication thread";
}
}
MPIComm::ThreadFunc()
MPIComm::ThreadFunc() 有两个while循环。
第1个循环首先检查task_queue_,如果为空则等待条件cond_work_。正常情况下当task_queue_有任务时,从task_queue_中获取第一个任务,调用MPIComm::DispatchJob并将任务出队。同时通知一个等待线程。
MPIComm::~MPIComm()会调用MPIComm::EndProcessing(),此时第2个循环执行队列剩余任务?
#ifndef CPU_ONLY
CUDA_CHECK(cudaSetDevice(Caffe::device_id()));
#endif
started_.store(true);
MPIJob job;
while (true){
mutex::scoped_lock lock(queue_mutex_);
while( task_queue_.empty() && IsRunning()){
DLOG(INFO)<<"no job running, waiting on cond";
cond_work_.wait(lock);
}
lock.unlock();
DLOG(INFO)<<"Cond fulfilled, dispatching job";
if (IsRunning()){
job = task_queue_.front();
DLOG(INFO)<<task_queue_.size();
DispatchJob(job);
mutex::scoped_lock pop_lock(queue_mutex_);
task_queue_.pop();
pop_lock.unlock();
cond_finish_.notify_one();
DLOG(INFO)<<"job finished, poped taskqueue";
}else{
break;
}
}
// finish remaining jobs
while (!task_queue_.empty()){
boost::lock_guard<mutex> lock(queue_mutex_);
job = task_queue_.front();
task_queue_.pop();
DispatchJob(job);
}
}
MPIComm::DispatchJob
根据任务类型调用 MPI 的函数。
MPI_Datatype data_type = (job.dtype_size_ == 4) ? MPI_FLOAT : MPI_DOUBLE;
// call MPI APIs for real works
switch (job.op_) {
case OP_SUM_ALL: {
DLOG(INFO)<<"Running all reduce\n";
MPI_CHECK(MPI_Allreduce((job.src_ptr_ == job.dst_ptr_) ? MPI_IN_PLACE : job.src_ptr_,
job.dst_ptr_, job.count_, data_type,
MPI_SUM, MPI_COMM_WORLD
));
break;
}
case OP_GATHER: {
MPI_CHECK(MPI_Allgather(job.src_ptr_, job.count_, data_type,
job.dst_ptr_, job.count_, data_type,
MPI_COMM_WORLD));
break;
}
case OP_SCATTER: {
MPI_CHECK(MPI_Scatter(job.src_ptr_, job.count_, data_type,
job.dst_ptr_, job.count_, data_type,
0, MPI_COMM_WORLD));
break;
}
case OP_BROADCAST: {
CHECK_EQ(job.src_ptr_, job.dst_ptr_);
MPI_CHECK(MPI_Bcast(job.src_ptr_, job.count_, data_type,
0, MPI_COMM_WORLD));
break;
}
default: {
LOG(FATAL)<<"Unknown MPI job type";
}
}
MPIComm::AddJob
等待 MPIComm::ThreadFunc() 创建就绪,添加任务到队列并通知其执行。
void MPIComm::AddJob(MPIJob new_job) {
if (IsRunning()) {
while(!started_.load());
mutex::scoped_lock lock(queue_mutex_);
DLOG(INFO) << "adding job on " << Caffe::MPI_my_rank() << " task queue size " << task_queue_.size() << " \n";
task_queue_.push(new_job);
lock.unlock();
cond_work_.notify_one();
}else{
LOG(FATAL)<<"Cannot push job while MPI Comm is shutting down";
}
}
MPIComm::WaitAll()
阻塞直到所有任务完成。
while (task_queue_.size()){
DLOG(INFO)<<"Waiting for tasks to finish, task size "<<task_queue_.size()<<"\n";
cond_finish_.wait(lock);
}
DLOG(INFO)<<"all task done on "<<Caffe::MPI_my_rank()<<"\n";
MPIComm::EndProcessing()
通知传输线程完成并关闭。
if (IsRunning()) {
try {
cond_work_.notify_one();
running_.store(false); //notify the transmission thread to finish and shutdown
thread_->join();
} catch (...) {
LOG(FATAL)<<"Cannot destroy MPI comminication thread";
}
}
MPI in Caffe
代码将调用 MPI 函数需要用到一些变量追加到 Caffe 类中。
do{...}while(0)帮助定义复杂的宏以避免错误
mpi.h 是 mpi 库的头文件。
#ifdef USE_MPI
#include "mpi.h"
#define MPI_CHECK(cond) \
do { \
int status = cond; \
CHECK_EQ(status, MPI_SUCCESS) << " " \
<< "MPI Error Code: " << status; \
} while (0)
#endif
Caffe 是一个单例类,用于容纳通用的caffe对象,比如caffe将用于cublas,curand等的句柄。
Caffe 构造函数私有并且类内维护一个静态对象指针,用于Get() 函数。
static shared_ptr<Caffe> singleton_;
private:
// The private constructor to avoid duplicate instantiation.
Caffe();
DISABLE_COPY_AND_ASSIGN(Caffe);
MPI涉及到的成员函数
#ifdef USE_MPI
enum PARALLEL_MODE { NO, MPI };
//Returns current parallel mode, No or MPI
inline static PARALLEL_MODE parallel_mode() {return Get().parallel_mode_;}
// Setter of parallel mode
inline static void set_parallel_mode(PARALLEL_MODE mode) {Get().parallel_mode_ = mode;}
//Returns MPI_MY_RANK
inline static int MPI_my_rank(){return Get().mpi_my_rank_;}
inline static int MPI_all_rank(){return Get().mpi_all_rank_;}
inline static void MPI_build_rank(){
MPI_Comm_rank(MPI_COMM_WORLD, &(Get().mpi_my_rank_));
MPI_Comm_size(MPI_COMM_WORLD, &(Get().mpi_all_rank_));
}
inline static int device_id(){return Get().device_id_;}
inline static int remaining_sub_iter(){return Get().remaining_sub_iter_;}
inline static void set_remaining_sub_iter(int n){Get().remaining_sub_iter_ = n;}
// Functions for splitting MPI_Comm to fast distributed training.
inline static void MPI_split_comm(const int color, const int key) {
MPI_Comm intra_comm;
MPI_Comm_split(MPI_COMM_WORLD, color, key, &intra_comm);
}
#endif
MPI涉及到的成员变量。
#ifdef USE_MPI
PARALLEL_MODE parallel_mode_;
int mpi_my_rank_;
int mpi_all_rank_;
int device_id_;
int remaining_sub_iter_;
#endif
GlobalInit
在全局初始化函数 GlobalInit 中启动 MPI 通信系统。

MPI_Init_thread 初始化 MPI 执行环境,MPI_Comm_rank 确定通信器中调用进程的级别,MPI_Comm_size 返回与通信器关联的组的大小。
#ifdef USE_MPI
//try start MPI communication system
int provided_thread_support;
MPI_Init_thread(pargc, pargv, MPI_THREAD_MULTIPLE, &provided_thread_support);
CHECK_GE(provided_thread_support, MPI_THREAD_SERIALIZED)<<" Cannot activate MPI thread support";
Caffe::MPI_build_rank();
if (Caffe::MPI_all_rank() > 1) {
Caffe::set_parallel_mode(Caffe::MPI);
LOG(INFO)<<"Running parallel training with MPI support!";
}else{
Caffe::set_parallel_mode(Caffe::NO);
LOG(INFO)<<"You are running caffe compiled with MPI support. Now it's running in non-parallel model";
}
//disable slave processes from logging to stderr
//also enable logging only events above ERROR level to logfile.
if (Caffe::MPI_my_rank() != 0){
FLAGS_logtostderr = false;
FLAGS_minloglevel = 2;
}
#endif
GlobalFinalize()
MPI_Finalize 终止 MPI 执行环境。
#ifdef USE_MPI
MPI_Finalize();
#endif
Caffe::Caffe()
在使用 MPI 时不在这里创建任何 cuda 对象,因为在独占模式 GPU 上它会导致程序失败。原因:此时未分配设备ID,所有进程都会尝试访问GPU 0。
#ifndef USE_MPI
// Try to create a cublas handler, and report an error if failed (but we will
// keep the program running as one might just want to run CPU code).
if (cublasCreate(&cublas_handle_) != CUBLAS_STATUS_SUCCESS) {
LOG(ERROR) << "Cannot create Cublas handle. Cublas won't be available.";
}
// Try to create a curand handler.
if (curandCreateGenerator(&curand_generator_, CURAND_RNG_PSEUDO_DEFAULT)
!= CURAND_STATUS_SUCCESS ||
curandSetPseudoRandomGeneratorSeed(curand_generator_, cluster_seedgen())
!= CURAND_STATUS_SUCCESS) {
LOG(ERROR) << "Cannot create Curand generator. Curand won't be available.";
}
#else
// we are not trying to create the any cuda stuff here
// because on exclusive mode GPUs it will cause program fail
// Reason: no device id assigned at this time, all processes will try to access gpu 0.
#endif
Caffe::SetDevice
设置设备时记录其id。
#ifdef USE_MPI
Get().device_id_ = device_id;
#endif
MPI train
如果solver_param未指定设备数量,则进行设置。
如果指定了group_id使用split切分通信域。
#ifndef USE_MPI
// Set device id and mode
if (FLAGS_gpu >= 0) {
LOG(INFO) << "Use GPU with device ID " << FLAGS_gpu;
Caffe::SetDevice(FLAGS_gpu);
Caffe::set_mode(Caffe::GPU);
} else {
LOG(INFO) << "Use CPU.";
Caffe::set_mode(Caffe::CPU);
}
// If the gpu flag is not provided, allow the mode and device to be set
// in the solver prototxt.
if (FLAGS_gpu < 0
&& solver_param.solver_mode() == caffe::SolverParameter_SolverMode_GPU) {
LOG(INFO) <<"Swtiching to GPU 0";
Caffe::set_mode(Caffe::GPU);
if (solver_param.device_id_size() == 0){
Caffe::SetDevice(0);
}else{
Caffe::SetDevice(solver_param.device_id(0));
}
}
#else
if (Caffe::parallel_mode() == Caffe::MPI){
if (FLAGS_gpu >= 0 ){
LOG(WARNING)<<"We detect that you are setting device id in command line flags. This will be ignored in parallel mode";
LOG(WARNING)<<"Please set a list of usable devices in the solver file.";
}
if (solver_param.solver_mode() == caffe::SolverParameter_SolverMode_GPU){
Caffe::set_mode(Caffe::GPU);
if (solver_param.device_id_size() == 0){
LOG(INFO)<<"Using the automatic ordinal info for device id. Possible risk of over number";
Caffe::SetDevice(Caffe::MPI_my_rank());
}else {
CHECK_GE(solver_param.device_id_size(), Caffe::MPI_all_rank())
<<"If you would like to specify device id, please specify equal or more number of ids than the number of jobs";
Caffe::SetDevice(solver_param.device_id(Caffe::MPI_my_rank()));
}
// Check if group_id is specified.
if (solver_param.group_id_size() > 0) {
CHECK_GE(solver_param.group_id_size(), Caffe::MPI_all_rank())
<< "If you would like to specifiy group id, please specify equal or more number of ids than the number of jobs";
std::map<int, int> count; // count how many processes in each group
int index; // index of the current process inside its group
for (int i = 0; i < solver_param.group_id_size(); ++i) {
if (i == Caffe::MPI_my_rank()) {
index = count[solver_param.group_id(i)];
}
++count[solver_param.group_id(i)];
}
if (count.size() > 1) {
Caffe::MPI_split_comm(solver_param.group_id(Caffe::MPI_my_rank()), index);
}
}
}else{
Caffe::set_mode(Caffe::CPU);
}
}else{
if (FLAGS_gpu >= 0) {
LOG(INFO) << "Use GPU with device ID " << FLAGS_gpu;
Caffe::SetDevice(FLAGS_gpu);
Caffe::set_mode(Caffe::GPU);
} else {
LOG(INFO) << "Use CPU.";
Caffe::set_mode(Caffe::CPU);
}
// If the gpu flag is not provided, allow the mode and device to be set
// in the solver prototxt.
if (FLAGS_gpu < 0
&& solver_param.solver_mode() == caffe::SolverParameter_SolverMode_GPU) {
LOG(INFO) <<"Swtiching to GPU 0";
Caffe::set_mode(Caffe::GPU);
if (solver_param.device_id_size() == 0){
Caffe::SetDevice(0);
}else{
Caffe::SetDevice(solver_param.device_id(0));
}
}
}
#endif
最后,程序运行采用 MPI 命令的方式:
#!/usr/bin/env sh
GOOGLE_LOG_DIR=models/action_recognition/log \
mpirun -np 4 \
cmake_build/install/bin/caffe train \
--solver=models/action_recognition/vgg_16_flow_solver.prototxt \
--weights=vgg_16_action_flow_pretrain.caffemodel
参考资料
- batch normalization的multi-GPU版本该怎么实现?
- [论文笔记]MegDet: A Large Mini-Batch Object Detector