MySQL的select语法
介绍
SQL中最常用的当属select命令了,它被用于从一张或者多张表中获取数据,简单的使用例子例如是select * from tab_name,可以将一张表中的所有数据取出来;但又由于支持条件过滤、分组、排序、合并、嵌套查询等等特性,有些应用场景中的SQL可以说是非常复杂,下面我们就来整理一下SQL支持的语法都有哪些。
select完整的语法结构如下所示,可以说是非常庞大的。
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[
FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]
]如下是我总结的select语法流程图:
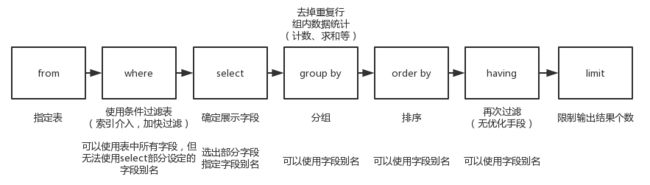
知识点
SELECT select_expr [, select_expr ...]
其中的中括号表示可选的意思,所以只需要SELECT select_expr这两部分,select就可以正常工作啦,这两部分也是必选的。举个例子:
- 查询数字
select 1结果:1 - 查询字符串
select 'a'结果:a - 查询计算结果
select 1+1结果:2 - 查询当前时间
select now()结果:2017-11-11 15:23:11
当然我们也可以查询多个select_expr,这时的语法结构是SELECT select_expr [, select_expr ...]。
FROM table_references
大部分情况下,我们需要指定数据源,即表名,FROM table_references,注意这里是table_references,而不是table_name,因为table_references可以代指多张表的组合。组合的方法查考本文后边提到的JOIN语法。我们暂时只考虑一张表。
假设我们有一张表,表名为student,字段有id, name, age, create_time,
- 查询
id, name两列,select id, name from student - 查询所有的列,
select id, name, age, create from student,更简单的,select * from student,其中*指代student表中的所有列 - 给每个学生的数字id加上20110000,代表学号,
select id+20110000 as student_number, name from student
上述例子中用到了as关键词,代表别称,可以给select_expr指定别名,且此时as是可以省略的(但是非常不建议省略,select c1 c2 from t1等价于select c1 as c2 from t1,而不是select c1, c2 from t1,查询时带上as是好习惯)。
注意:用as指定的别名,不能用在where中,因为where先于select_expr执行。
缺省数据库和缺省表名
如果使用use database_name;指定了缺省的数据库,那么就可以缺省使用表名了;否则,需要显示指定数据的数据库select * from database_name.table_name;。
如果一条查询语句只涉及到一张表,select id,name from student;是可以正常执行的;但如果有两张表,其中有相同的字段名,例如有两个学生表t1和t2,那么查询时需要显式指定查询的字段属于哪张表,select t1.id, t1.name, t2.id, t2.name from t1, t2,以避免冲突。
[GROUP BY {col_name | expr | position} [ASC | DESC], … [WITH ROLLUP]]
group by用来对select xxx from yyy where zzz;的结果做聚类,select age from student where id<100 group by age;,是对id小于100的学生做年龄聚类,返回的结果是没有重复的,这和使用distinct关键词是没有区别的,select distinct age from student where id<100;。
上述使用group by的方法意义不大,一般我们会对每个group做统计,例如统计每个类别中学生的数量,select age,count(*) as count from student where id<100 group by age;。
输出的结果,缺省情况下age升序排列,即group by age asc,也可以使用desc是得输出结果按照age降序排列,group by age desc。(group by缺省升序排列这个特性已经废弃了,建议显式说明排序方式)
此外,也可以按照count降序排列,select age,count(*) as count from student where id<100 group by age order by count desc;
group by position的使用方式已经废弃了,不建议使用,已被SQL标准移除。
[ORDER BY {col_name | expr | position} [ASC | DESC], …]
order by可以对查询结果进行排序,排序指标可以有一个或者多个,例如:
- 按照id降序排列
select * from student order by id desc; - 按照age降序排列,如果age相同,按照id升序排列
select * from student order by age desc, id asc;
使用group by和order by做排序时,如果被排序的值较长,只会根据值的前若干部分进行排序,这个长度由系统变量max_sort_length确定,例如这个值是1024(bytes)。
order by position的使用方式已经废弃了,不建议使用,已被SQL标准移除。
[HAVING where_condition]
having用于对查询结果的过滤,和where类似。
select * from student where id<=10;select * from student having id<=10;
以上两个sql语句都是可以正常执行的,但是不建议使用having替代where。
having几乎是在MySQL服务端将结果发送给客户端之前执行的,非常靠后(limit在having之后),且不会使用优化手段,执行速度比where要慢很多。就用上边这里例子来说,having id<=10会先全表遍历,然后再返回前10行,而where id<=10,通过使用主键等索引,只需要扫描10行就能取到最终的结果。
SQL标准要求having只能使用group by中的字段。但是MySQL支持使用select的字段列表。
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
limit用于限制返回结果的数量。offset的起始值是0。
- 查询前5个学生的数据
select * from student limit 5; - 查询第6到10个学生的数据
select * from student limit 5,10; - 查询第11个之后的所有的学生的数据,用了一个比较大的整数
select * from student limit 10,18446744073709551615;
为了兼容PostgreSQL,MySQL也支持limit row_count offset offset_count这样的语法。
PROCEDURE
PROCEDURE在MySQL 5.7.18被设置为废弃状态,并会在MySQL 8.0中移除。
指定了一个procedure,用于处理结果集中的数据,参考https://dev.mysql.com/doc/refman/5.7/en/procedure-analyse.html。
嵌套查询
举个例子,select * from (select 1,2,3) as t1
其中子查询select 1,2,3生成的结果表,又称为导出表。该结果表必须设定一个别称,用作表名,即as t1。
JOIN
在MySQL中JOIN、CROSS JOIN和INNER JOIN是等价的;但在标准SQL中,是不等价的,INNER JOIN会和ON搭配使用,而CROSS JOIN不是。
INNER JOIN和,是等价的,都会生成两张表的笛卡尔积,即第一张表中的每一行会和第二张表中的每一行组合生成新行。
,的优先级低于INNER JOIN,所以这样的语句是错误的select * from t1, t1 as t2 join t1 as t3 on t1.c1=t3.c1;,需要都使用select * from t1 join t1 as t2 join t1 as t3 on t1.c1=t3.c1;
USING(column_list)中column_list指代的字段必须同时存在于两张表中,例如a LEFT JOIN b USING (c1, c2, c3)
NATURAL [LEFT] JOIN等价于t1 INNER JOIN t2 USING(all_same_column_list),其中all_same_column_list代表t1和t2表中所有名称相同的字段
RIGHT JOIN和LEFT JOIN,建议使用LEFT JOIN
UNION
UNION的语法
SELECT ...
UNION [ALL | DISTINCT] SELECT ...
[UNION [ALL | DISTINCT] SELECT ...]UNION用于合并多个select查询结果。
第一个select结果中的列名称会作为总结果的列名称。
多个select结果中对应列的类型应该相同;否则总结果会统筹考虑所有select结果的值。
默认情况下,如果两个select的结果有相同的行,只会保留相同行中的一个。如果不希望这样的事发生,需要使用关键词ALL,即select ... union all select ...;。
如果单个select中使用了order by或者limit,需要用括号括起来:
(SELECT a FROM t1 WHERE a=10 AND B=1 ORDER BY a LIMIT 10)
UNION
(SELECT a FROM t2 WHERE a=11 AND B=2 ORDER BY a LIMIT 10);可以对合并后的结果做order by和limit操作,例如:
(SELECT a FROM t1 WHERE a=10 AND B=1)
UNION
(SELECT a FROM t2 WHERE a=11 AND B=2)
ORDER BY a LIMIT 10;可以使用一个固定值来连接两个表,标识数据是属于哪张表的
(SELECT 1 AS sort_col, col1a, col1b, ... FROM t1)
UNION
(SELECT 2, col2a, col2b, ... FROM t2) ORDER BY sort_col;附录
INNER JOIN LEFT JOIN RIGHT JOIN比较
表t1,表t2如下所示
mysql> select * from t1;
+------+------+
| c1 | c2 |
+------+------+
| 1 | 1 |
| 2 | 3 |
| 3 | 5 |
+------+------+
mysql> select * from t2;
+------+------+
| c1 | c2 |
+------+------+
| 1 | 2 |
| 2 | 4 |
| 4 | 6 |
+------+------+mysql> select * from t1 inner join t2;
+------+------+------+------+
| c1 | c2 | c1 | c2 |
+------+------+------+------+
| 1 | 1 | 1 | 2 |
| 2 | 3 | 1 | 2 |
| 3 | 5 | 1 | 2 |
| 1 | 1 | 2 | 4 |
| 2 | 3 | 2 | 4 |
| 3 | 5 | 2 | 4 |
| 1 | 1 | 4 | 6 |
| 2 | 3 | 4 | 6 |
| 3 | 5 | 4 | 6 |
+------+------+------+------+mysql> select * from t1 inner join t2 on t1.c1=t2.c1;
+------+------+------+------+
| c1 | c2 | c1 | c2 |
+------+------+------+------+
| 1 | 1 | 1 | 2 |
| 2 | 3 | 2 | 4 |
+------+------+------+------+
mysql> select * from t1 left join t2 on t1.c1=t2.c1;
+------+------+------+------+
| c1 | c2 | c1 | c2 |
+------+------+------+------+
| 1 | 1 | 1 | 2 |
| 2 | 3 | 2 | 4 |
| 3 | 5 | NULL | NULL |
+------+------+------+------+
mysql> select * from t1 right join t2 on t1.c1=t2.c1;
+------+------+------+------+
| c1 | c2 | c1 | c2 |
+------+------+------+------+
| 1 | 1 | 1 | 2 |
| 2 | 3 | 2 | 4 |
| NULL | NULL | 4 | 6 |
+------+------+------+------+c1是t1和t2的共有字段
mysql> select * from t1 inner join t2 using (c1);
+------+------+------+
| c1 | c2 | c2 |
+------+------+------+
| 1 | 1 | 2 |
| 2 | 3 | 4 |
+------+------+------+
mysql> select * from t1 left join t2 using (c1);
+------+------+------+
| c1 | c2 | c2 |
+------+------+------+
| 1 | 1 | 2 |
| 2 | 3 | 4 |
| 3 | 5 | NULL |
+------+------+------+
mysql> select * from t1 right join t2 using (c1);
+------+------+------+
| c1 | c2 | c2 |
+------+------+------+
| 1 | 2 | 1 |
| 2 | 4 | 3 |
| 4 | 6 | NULL |
+------+------+------+参考
- https://dev.mysql.com/doc/refman/5.7/en/select.html
- https://dev.mysql.com/doc/refman/5.7/en/join.html
- https://dev.mysql.com/doc/refman/5.7/en/union.html