混合列压缩(HCC)在OLAP及OLTP场景中的测试
作者:李敏,云和恩墨交付工程师。
2019年度 ACOUG活动启动啦!为了感恩和回馈一直支持社区工作的技术爱好者、会员、嘉宾和合作伙伴,2019年度,我们汇集了行业大咖最新的精彩主题跟大家分享,更有惊喜好礼等你拿,点击“我要报名”,立即参与!2019年,我们将探索更多可能。
本次活动我们邀请到了来自Oracle、云和恩墨、Mellanox的专家,议题涵盖故障解析、新架构、新功能。
有理论上的干货知识,更有动手实验室,手把手教你使用Oracle APEX——快速开发应用。
详情:2019 ACOUG China Tour 上海站
Oracle Corp最先在11G R2中引入了EHCC(Exadata Hybrid Columnar Compression),早先限制较多,体现的方式是这里的E,指的是exadata一体机上才可以启用这个特性。作为exadata上众多优秀特性里一个重要部分,和smart scan或者说cell offloading对比,虽然EHCC能带来极大的空间压缩,但是EHCC还是需要DBA额外做一些操作,甚至多个场景的评估来决定是否要采用。
EHCC(或者说后来因使用平台更多,在除了exadata之外,在Oracle corp的zfssa、Pillar Axiom、SuperCluster、ODA上都支持了之后改成了叫做HCC)本质上解决的问题是IO问题,也可以说,是为了在CPU及IO间平衡,拿算力换空间,目前看来在大部分场景下,这个交换是非常超值的,几倍、十几倍甚至几十倍的压缩率都很常见,如果这部分数据是冷数据,这个特性看起来是完美的。
但是有些时候不是这样的。本文从HCC的多个方面选出一两个点来简述这个特性给DBA带来的第一个直观感受。
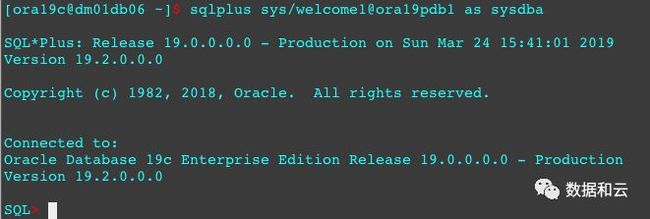
测试环境的DB版本
 存储为模拟的ZFSSA VM,这个是合法的。
存储为模拟的ZFSSA VM,这个是合法的。
首先,准备环境
创建表空间,这里选择多个小文件的方式。
CREATE SMALLFILE TABLESPACE EHCCTBS
DATAFILE
'/ehccfs/ORA19C/ora19pdb1/EHCCTBS_001.DBF' SIZE 10485760 AUTOEXTEND ON NEXT 1048576 MAXSIZE 10737418240 ,
'/ehccfs/ORA19C/ora19pdb1/EHCCTBS_002.DBF' SIZE 10485760 AUTOEXTEND ON NEXT 1048576 MAXSIZE 10737418240 ,
'/ehccfs/ORA19C/ora19pdb1/EHCCTBS_003.DBF' SIZE 10485760 AUTOEXTEND ON NEXT 1048576 MAXSIZE 10737418240 ,
'/ehccfs/ORA19C/ora19pdb1/EHCCTBS_004.DBF' SIZE 10485760 AUTOEXTEND ON NEXT 1048576 MAXSIZE 10737418240
BLOCKSIZE 8192
FORCE LOGGING
DEFAULT COLUMN STORE NO COMPRESS NO INMEMORY
ONLINE
SEGMENT SPACE MANAGEMENT AUTO
EXTENT MANAGEMENT LOCAL AUTOALLOCATE;(左右滑动,查看完整代码,下同)这里选择NO Compress方式创建表空间,不把压缩作为表空间的属性,而用CREATE TABLE的方式来指定压缩属性。
第一部分,这个部分看压缩率。看OLAP的表现。(偏重SELECT)
继续准备,测试用户及源表。
[ora19c@dm01db06 ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sun Mar 24 10:07:02 2019
Version 19.2.0.0.0
Copyright (c) 1982, 2018, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.2.0.0.0
SQL> create user hr identified by welcome1 default tablespace ehcctbs;
User created.
SQL> grant dba to hr;
Grant succeeded.
SQL> create table hr.big_table_no_ehcc as select * from dba_objects;
Table created.
为了体现压缩率的差距,我创建了一个360M的未压缩表,来对比8种压缩方式下的压缩率。
[ora19c@dm01db06 ~]$ sqlplus hr/welcome1@ora19pdb1
SQL*Plus: Release 19.0.0.0.0 - Production on Sun Mar 24 10:07:28 2019
Version 19.2.0.0.0
Copyright (c) 1982, 2018, Oracle. All rights reserved.
Last Successful login time: Sun Mar 24 2019 09:36:33 +08:00
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.2.0.0.0
SQL>
SQL> insert into BIG_TABLE_NO_EHCC select * from BIG_TABLE_NO_EHCC;
72360 rows created.
SQL> /
144720 rows created.
SQL> /
289440 rows created.
SQL> /
578880 rows created.
SQL> insert into BIG_TABLE_NO_EHCC select * from BIG_TABLE_NO_EHCC;
1157760 rows created.
SQL> commit;
SQL> select count(*) from BIG_TABLE_NO_EHCC;
COUNT(*)
----------
2315520
SQL> col OWNER for a15
SQL> col SEGMENT_NAME for a40
SQL> select OWNER,SEGMENT_NAME,BYTES/1048576 SIZE_MB from dba_segments where SEGMENT_NAME like ('%EHCC%');
OWNER SEGMENT_NAME SIZE_MB
--------------- ---------------------------------------- ----------
HR BIG_TABLE_NO_EHCC 360
之后基于这个基础表,创建8个不同HCC压缩方式的表。这里我timing on了,但是只做参考,因为redo是200M的,导致CTAS的时候有一次归档行为,IO受影响,可能有一次的时间受影响。
SQL> create table EHCC_QUERY_HIGH compress for query high tablespace ehcctbs as select * from big_table_no_ehcc ;
Table created.
Elapsed: 00:00:10.61
SQL> create table EHCC_QUERY_LOW compress for query low tablespace ehcctbs as select * from big_table_no_ehcc ;
Table created.
Elapsed: 00:00:21.33
SQL> create table EHCC_ARCHIVE_HIGH compress for archive high tablespace ehcctbs as select * from big_table_no_ehcc ;
Table created.
Elapsed: 00:00:38.75
SQL> create table EHCC_ARCHIVE_LOW compress for archive low tablespace ehcctbs as select * from big_table_no_ehcc ;
Table created.
Elapsed: 00:00:11.07
SQL> create table EHCC_QUERY_HIGH_LOCKING compress for query high row level locking tablespace ehcctbs as select * from big_table_no_ehcc ;
Table created.
Elapsed: 00:00:09.46
SQL> create table EHCC_QUERY_LOW_LOCKING compress for query low row level locking tablespace ehcctbs as select * from big_table_no_ehcc ;
Table created.
Elapsed: 00:00:12.35
SQL> create table EHCC_ARCHIVE_HIGH_LOCKING compress for archive high row level locking tablespace ehcctbs as select * from big_table_no_ehcc ;
Table created.
Elapsed: 00:00:33.90
SQL> create table EHCC_ARCHIVE_LOW_LOCKING compress for archive low row level locking tablespace ehcctbs as select * from big_table_no_ehcc ;
Table created.
Elapsed: 00:00:17.50
然后查看这些不同压缩方式下的对象大小。注意这里的LOCKING,指的是row level locking。
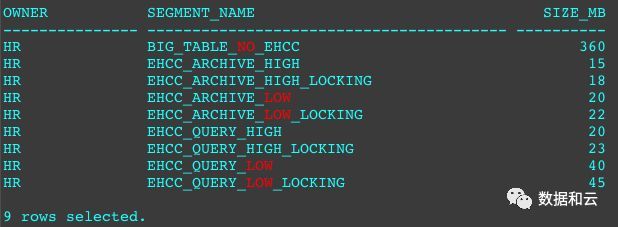
除了第一个基础表之外,每两个相邻对象的压缩区别是row level locking方式的区别。
hr.BIG_TABLE_NO_EHCC这个表是基于PDB的dba_objects来创建的一个28列的表,实话说,这个表做HCC跑分测试并不适合,但是依然能在archive high模式下,达到惊人的360/15=24倍的压缩率。
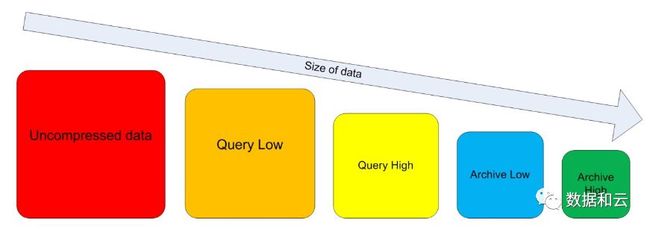
基本符合这个趋势吧?
那么,对未压缩的基础表强制全扫,再对最高压缩的archive high的表做强制全扫的话,哪个快呢?
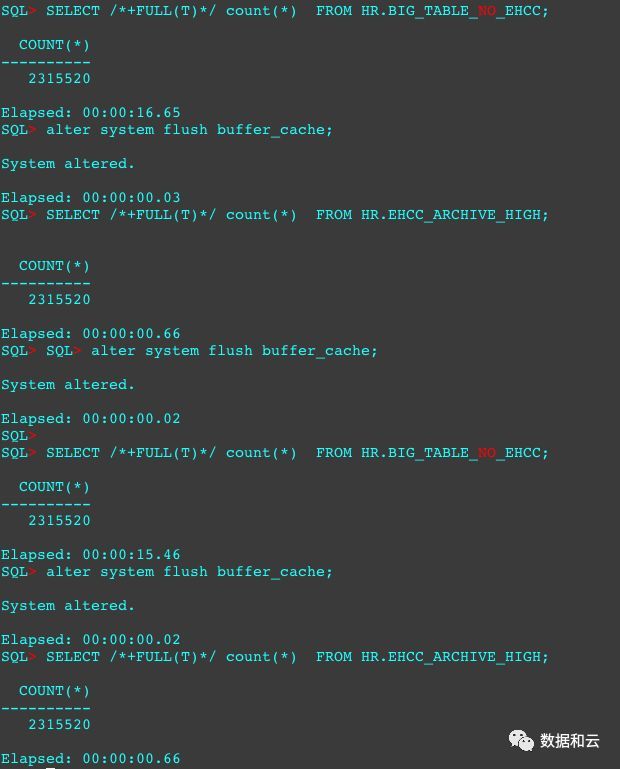
多次测试,结果出乎意料。16秒跟1秒下的差距,这是没在exadata上的结果,如果集合exadata的cell offloading,可以详见OLAP下,HCC的表现了。
Oracle对自家产品间的协同和优化令人目瞪狗呆。
第二部分,这个部分看DML。看OLTP的表现。(偏重DML测试)
既能压缩几十倍的空间,还能高速query,甚至还能高速DML,还想着让锁的范围尽量小,如何实现呢?
这个测试起来要考虑的东西有点多,要考虑CU大小,CU内有多少行,CU内锁的范围,insert的位置,update的影响范围,delete影响的范围,以及delete之后的空间的重用和压缩。
CU是HCC里引入的新概念,叫做Compression Unit,压缩单元。

上文构造的环境有点大,不适合接下来的OLTP的测试,以下dump出来几个块。
拿压缩率最高的EHCC_ARCHIVE_HIGH来吧。
这里插句话,看到有些文档说,HCC下的ROWID不是指的block的ID号,而是指向CU的号,这个部分其实很好理解,不好理解的是,怎么证明哪些block被压在了同一个CU上?
我们查看EHCC_ARCHIVE_HIGH表的extents分布。
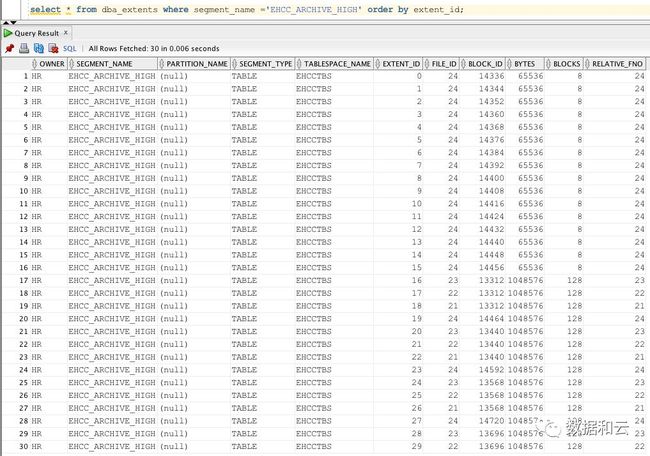
按照Oracle DB的分配原则,0区的前面块为一级,二级位图块,eygle曾展示过三级位图块,但是我的环境里没有做这个构造,这里把一级和二级位图块展示出来。就是0区,24号文件的14336和14337块。然后接着往后dump,14338 ,14339,14340,14341,14342,14343,14344(1区第一个块)。
来看一下这些块是什么。
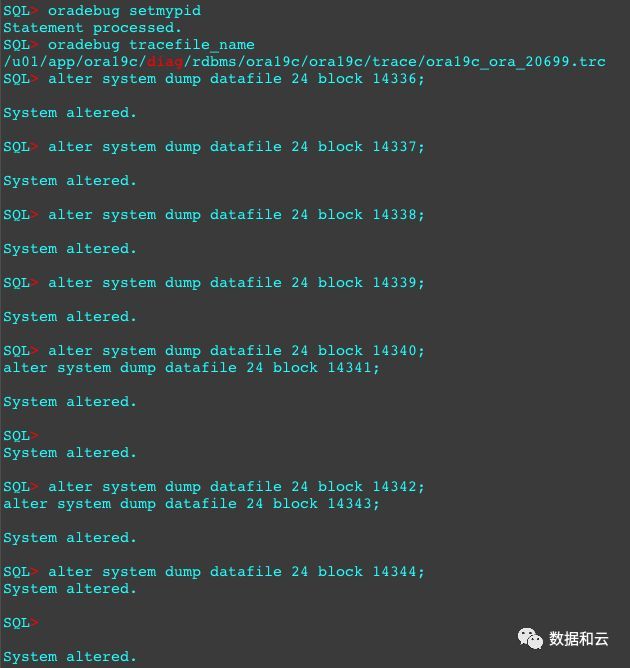 9个块dump到了一个trace里
9个块dump到了一个trace里14336,一级位图块
*** 2019-03-24T17:14:51.182266+08:00 (ORA19PDB1(3))
Start dump data blocks tsn: 6 file#:24 minblk 14336 maxblk 14336
............................
............................
............................
Dump of Second Level Bitmap Block
number: 9 nfree: 1 ffree: 8 pdba: 0x06003802
Inc #: 0 Objd: 72974 Flag: 3
opcode:0
这里提示到:
Second Level Bitmap block DBAs
--------------------------------------------------------
DBA 1: 0x06003801二级位图块,正好是一级14336的下一个块:
下面是这个二级位图块的信息:
Dump of Second Level Bitmap Block
number: 9 nfree: 1 ffree: 8 pdba: 0x06003802
Inc #: 0 Objd: 72974 Flag: 3
opcode:0
xid:
L1 Ranges :
--------------------------------------------------------
0x06003800 Free: 1 Inst: 1
0x06003840 Free: 1 Inst: 1
0x05803400 Free: 1 Inst: 1
0x06003880 Free: 1 Inst: 1
0x05803480 Free: 1 Inst: 1
0x06003900 Free: 1 Inst: 1
0x05803500 Free: 1 Inst: 1
0x06003980 Free: 1 Inst: 1
0x05803580 Free: 7 Inst: 1
--------------------------------------------------------
End dump data blocks tsn: 6 file#: 24 minblk 14337 maxblk 14337
看样子是没什么东西。似乎是表太小没用到。
14338块信息不多。这里看14339块。
block_row_dump:
tab 0, row 0, @0x30
tl: 8016 fb: --H-F--N lb: 0x0 cc: 1
nrid: 0x06003804.0
col 0: [8004]
Compression level: 04 (Archive High)
Length of CU row: 8004
kdzhrh: ------PC- CBLK: 0 Start Slot: 00
NUMP: 22
PNUM: 00 POFF: 7774 PRID: 0x06003804.0
PNUM: 01 POFF: 15790 PRID: 0x06003805.0
PNUM: 02 POFF: 23806 PRID: 0x06003806.0
PNUM: 03 POFF: 31822 PRID: 0x06003807.0
PNUM: 04 POFF: 39838 PRID: 0x06003808.0
PNUM: 05 POFF: 47854 PRID: 0x06003809.0
PNUM: 06 POFF: 55870 PRID: 0x0600380a.0
PNUM: 07 POFF: 63886 PRID: 0x0600380b.0
PNUM: 08 POFF: 71902 PRID: 0x0600380c.0
PNUM: 09 POFF: 79918 PRID: 0x0600380d.0
PNUM: 10 POFF: 87934 PRID: 0x0600380e.0
PNUM: 11 POFF: 95950 PRID: 0x0600380f.0
PNUM: 12 POFF: 103966 PRID: 0x06003810.0
PNUM: 13 POFF: 111982 PRID: 0x06003811.0
PNUM: 14 POFF: 119998 PRID: 0x06003812.0
PNUM: 15 POFF: 128014 PRID: 0x06003813.0
PNUM: 16 POFF: 136030 PRID: 0x06003814.0
PNUM: 17 POFF: 144046 PRID: 0x06003815.0
PNUM: 18 POFF: 152062 PRID: 0x06003816.0
PNUM: 19 POFF: 160078 PRID: 0x06003817.0
PNUM: 20 POFF: 168094 PRID: 0x06003818.0
PNUM: 21 POFF: 176110 PRID: 0x06003819.0
*---------
CU header:
CU version: 0 CU magic number: 0x4b445a30
CU checksum: 0xbdbe82d3
CU total length: 180160
CU flags: NC-U-CRD-OP
ncols: 26
nrows: 32759
algo: 0
CU decomp length: 175939 len/value length: 4332401
row pieces per row: 1
num deleted rows: 0
START_CU:
这部分信息较多,我按照个人的理解来说说。
tl: 8016 fb: –H-F–N这里的H是CUhead的意思。fb是flag byte,F是first的意思,P是previous,N是next。此外我没有dump最后一个row piece,按道理来说,最后一个0x06003819块上的fb会显示L的,代表last。(事实上我事后dump了,显示的LP)
nrid: 0x06003804.0这里nrid是next row piece id的意思,这里的数据是nrid: 0x06003804.0,换成10进制是rdba: 0x6003804(100677636) file: 24 ,block : 14340,24号文件14340块。
按照道理来说,14340块上显示的是类似PN,没有H的tag。
Compression level: 04 (Archive High)是HCC压缩格式。
NUMP: 22是代表这个CU里有多少个row piece,这里显示的是22个row piece,而根据这个地址看,一个row piece就是一个block,我理解是代表,这个CU里有22个block。
CU checksum: 0xbdbe82d3是这个CU的校验值。
nrows: 32759,代表这个CU里存了32759行,这是一个非常大的数值。
接下来,我们dump那个第二个CU块,14340块。
Start dump data blocks tsn: 6 file#:24 minblk 14340 maxblk 14340
..........................
..........................
..........................
block_row_dump:
tab 0, row 0, @0x1f
tl: 8033 fb: ------PN lb: 0x0 cc: 1
nrid: 0x06003805.0
col 0: [8021]
Compression level: 04 (Archive High)
Length of CU row: 8021
kdzhrh: ---------START_CU:
如上文标识的一样,这是PN。
这里将分别按照insert,update,delete这三个DML来测试在HCC情况下相关的可能的压缩转换情况,ROWID变化情况,锁范围情况来阐述。
在DML场景中,对比两张表,非压缩表和压缩表。压缩表的所有行,都在一个CU的一个块里。
如下是创建的表,有一张普通表,一张archive high的表,以及一张row level locking的archive high表。他们分配的大小是一样的,这不代表在extents内占的空间是一样大,而是因为表初始分配的extents是8个block,每个block是8192 bytes。这个是ASSM的分配规律。
SQL> create table dml_test_no_ehcc as select * from dba_objects where rownum < 100;
Table created.
SQL> update dml_test_no_ehcc set OBJECT_ID=rownum;
99 rows updated.
SQL> commit;
Commit complete.
SQL> create table DML_TEST_ARCHIVE_HIGH compress for archive high tablespace ehcctbs as select * from dml_test_no_ehcc ;
Table created.
SQL> create table DML_TEST_ARCHIVE_HIGH_LOCKING compress for archive high row level locking tablespace ehcctbs as select * from dml_test_no_ehcc ;
Table created.
col OWNER for a15
col SEGMENT_NAME for a40
SQL> select s.OWNER,s.SEGMENT_NAME,s.BYTES/1024 SIZE_MB,t.COMPRESS_FOR from dba_segments s,dba_tables t where s.SEGMENT_NAME like ('DML_TEST_%') and s.owner=t.owner and s.segment_name = t.table_name order by 2;
OWNER SEGMENT_NAME SIZE_MB COMPRESS_FOR
--------------- ---------------------------------------- ---------- ----------------------------------
SYS DML_TEST_ARCHIVE_HIGH 64 ARCHIVE HIGH
SYS DML_TEST_ARCHIVE_HIGH_LOCKING 64 ARCHIVE HIGH ROW LEVEL LOCKING
SYS DML_TEST_NO_EHCC
接下来,需要证明这两个HCC的表的所有行都在同一个CU里。


这个时候,除去一级和二级位图块,dump每个表的第四个块,就是说DML_TEST_ARCHIVE_HIGH在24号文件的19203块,和DML_TEST_ARCHIVE_HIGH_LOCKING在24号文件的19211块,从dump信息中查看是否所有行在一个CU内。
19203块,信息如下,可以看到fb标识为Head,有F,有L,代表这个CU既是first也是last的CU,并且这个CU里的nrows 是99行。这都跟构造的环境一致。
data_block_dump,data header at 0x9b95a07c
===============
tsiz: 0x1f80
hsiz: 0x1c
pbl: 0x9b95a07c
76543210
flag=-0------
ntab=1
nrow=1
frre=-1
fsbo=0x1c
fseo=0x1830
avsp=0x1814
tosp=0x1814
r0_9ir2=0x0
mec_kdbh9ir2=0x0
76543210
shcf_kdbh9ir2=----------
76543210
flag_9ir2=--R----- Archive compression: Y
fcls_9ir2[0]={ }
0x16:pti[0] nrow=1 offs=0
0x1a:pri[0] offs=0x1830
block_row_dump:
tab 0, row 0, @0x1830
tl: 1872 fb: --H-FL-- lb: 0x0 cc: 1
col 0: [1866]
Compression level: 04 (Archive High)
Length of CU row: 1866
kdzhrh: --------- Start Slot: 00
*---------
CU header:
CU version: 0 CU magic number: 0x4b445a30
CU checksum: 0x24a713c2
CU total length: 1854
CU flags: NC-U-CRD-OP
ncols: 26
nrows: 99
algo: 0
CU decomp length: 1715 len/value length: 10614
row pieces per row: 1
num deleted rows: 0
START_CU:
同样,另外一个表的19211块也是得到一样的构造信息。
data_block_dump,data header at 0x7fda7a65e07c
===============
tsiz: 0x1f80
hsiz: 0x1c
pbl: 0x7fda7a65e07c
76543210
flag=-0------
ntab=1
nrow=1
frre=-1
fsbo=0x1c
fseo=0x17c9
avsp=0x17ad
tosp=0x17ad
r0_9ir2=0x0
mec_kdbh9ir2=0x0
76543210
shcf_kdbh9ir2=----------
76543210
flag_9ir2=--R----- Archive compression: Y
fcls_9ir2[0]={ }
0x16:pti[0] nrow=1 offs=0
0x1a:pri[0] offs=0x17c9
block_row_dump:
tab 0, row 0, @0x17c9
tl: 1975 fb: --H-FL-- lb: 0x0 cc: 1
col 0: [1969]
Compression level: 04 (Archive High)
Length of CU row: 1969
kdzhrh: --------L Start Slot: 00
num lock bits: 8
locked rows:
*---------
CU header:
CU version: 0 CU magic number: 0x4b445a30
CU checksum: 0x24a713c2
CU total length: 1854
CU flags: NC-U-CRD-OP
ncols: 26
nrows: 99
algo: 0
CU decomp length: 1715 len/value length: 10614
row pieces per row: 1
num deleted rows: 0
START_CU:
OLTP下的第一个场景测试,我们暂定为insert测试,这里只针对HCC的表做测试,分别测试append方式和常规插入方式在HCC表及row level locking的HCC表下的表现。
根据文档显示,对已经HCC压缩的表的插入,如果是常规插入,新插入的数据将不会被压缩,只有以append等直接路径的方式插入,才会继续压缩。这里除了需要验证这个事情之外,还需要验证下其他会话的并发插入会不会受影响,如果被阻塞,需要测试row level locking方式的HCC表是否受影响。
SQL> select distinct(sid) from v$mystat;
SID
----------
147
SQL> insert into DML_TEST_ARCHIVE_HIGH select * from DML_TEST_NO_EHCC;
99 rows created.
SQL>
SQL> select distinct(sid) from v$mystat;
SID
----------
269
SQL> insert into DML_TEST_ARCHIVE_HIGH select * from DML_TEST_NO_EHCC;
99 rows created.
SQL>
这个测试为了证明没有row level locking属性的HCC表的插入,不会锁定单个CU。
但是,这个测试测下来,有一个问题,就是对于没有使用append方式的插入,如果插入的数据,当前已经压缩的CU可以容下,那么插入的数据是会被压缩的,如果以没有append方式插入的数据,当前CU放置不下,那么在接下来的分配中,超出当前CU的数据是特么的不会被压缩的。
这个又一次出乎意料。
COUNT(*) COMPRESSION_TYPE
---------- ---------------------------------------------------------------
10 COMP_NOCOMPRESS
323126 COMP_FOR_ARCHIVE_HIGH
SQL>
OLTP下的第二个场景,我们测试DELETE,这个我也不知道测试什么,我暂且对HCC的表,做两个会话的删除测试。
我测试了两次,如果这个表没有被压缩,我分别在两个会话中,删除object_id=1及2的数据,不提交,是互相不会阻塞的。
但是,如果这个表是HCC压缩,并且没有开启row level locking的话,如果在会话1删除object_id=1的条目,在会话2中删除object_id=2的条目,会话2的删除,是会被会话1阻塞的。

这也侧面验证了,普通HCC表,锁的最小单元是CU,而不是像普通表那样,受影响的是被其他会话已经影响到的行。不过仔细一想,道理似乎是一样的。
那么,我前面铺垫了那么多row level locking的HCC特性这个时候就发挥作用了。这个特性是在12c的HCC中引入了。Oracle corp可能发现对整个CU加锁影响的范围太大了,为了对OLTP友好,引入了row level locking的HCC的特性,虽然这可能带来一点点的压缩损耗,在前文能看到压缩损耗的情况。
接下来,对那张创建好的row level locking的表做不同会话的object_id=1和object_id=2的记录的删除。
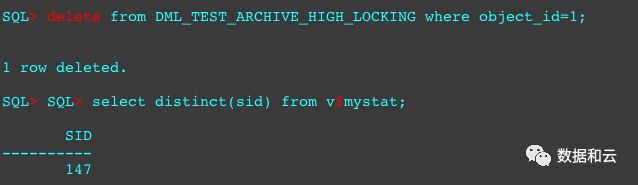
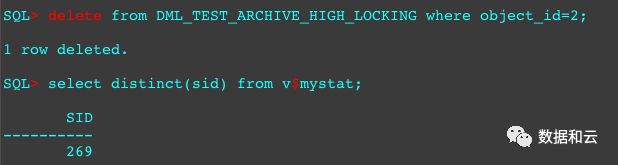
可以看到添加了row level locking属性的HCC表的同个CU内的删除是互不影响的。
OLTP中,第三个场景测试,我们将测试update,据前文DELETE测试,可以显然的知道,HCC中不带row level locking的压缩是会被其他update阻塞的。带了的话,如果针对同一个CU内不同记录操作,是不会影响的。如果是同一个CU内的相同记录操作,那会是怎么样呢:)。
UPDATE部分,这里重点测试的是rowid变化情况。
重新生成环境:
SQL> drop table DML_TEST_ARCHIVE_HIGH purge;
Table dropped.
SQL> drop table DML_TEST_ARCHIVE_HIGH_LOCKING purge;
Table dropped.
SQL> drop table DML_TEST_NO_EHCC purge;
Table dropped.
这次表创建的更小。
SQL> create table dml_test_no_ehcc as select * from dba_objects where rownum < 10;
Table created.
SQL> create table DML_TEST_ARCHIVE_HIGH compress for archive high tablespace ehcctbs as select * from dml_test_no_ehcc ;
Table created.
SQL> create table DML_TEST_ARCHIVE_HIGH_LOCKING compress for archive high row level locking tablespace ehcctbs as select * from dml_test_no_ehcc ;
Table created.
SQL>
SQL> col OWNER for a15
SQL> col SEGMENT_NAME for a40
SQL> select s.OWNER,s.SEGMENT_NAME,s.BYTES/1024 SIZE_MB,t.COMPRESS_FOR from dba_segments s,dba_tables t where s.SEGMENT_NAME like ('DML_TEST_%') and s.owner=t.owner and s.segment_name = t.table_name order by 2;
OWNER SEGMENT_NAME SIZE_MB COMPRESS_FOR
--------------- ---------------------------------------- ---------- ------------------------------------------------------------------------------------------
HR DML_TEST_ARCHIVE_HIGH 64 ARCHIVE HIGH
HR DML_TEST_ARCHIVE_HIGH_LOCKING 64 ARCHIVE HIGH ROW LEVEL LOCKING
HR DML_TEST_NO_EHCC 64
SQL>
查看其中HCC表的rowid及块号分布情况。
SQL> select rowid,object_name,dbms_rowid.rowid_block_number(rowid) from DML_TEST_ARCHIVE_HIGH;
ROWID OBJECT_NAME DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)
------------------ ---------------------------------------- ------------------------------------
AAAR0vAAWAAAEWLAAA I_FILE#_BLOCK# 17803
AAAR0vAAWAAAEWLAAB I_OBJ3 17803
AAAR0vAAWAAAEWLAAC I_TS1 17803
AAAR0vAAWAAAEWLAAD I_CON1 17803
AAAR0vAAWAAAEWLAAE IND$ 17803
AAAR0vAAWAAAEWLAAF CDEF$ 17803
AAAR0vAAWAAAEWLAAG C_TS# 17803
AAAR0vAAWAAAEWLAAH I_CCOL2 17803
AAAR0vAAWAAAEWLAAI I_PROXY_DATA$ 17803
9 rows selected.
这里可以通过DBMS_COMPRESSION.GET_COMPRESSION_TYPE来确认某行数据的压缩方式:
SQL> select DBMS_COMPRESSION.GET_COMPRESSION_TYPE('HR','DML_TEST_ARCHIVE_HIGH','AAAR0vAAWAAAEWLAAA') from dual;
DBMS_COMPRESSION.GET_COMPRESSION_TYPE('HR','DML_TEST_ARCHIVE_HIGH','AAAR0VAAWAAAEWLAAA')
----------------------------------------------------------------------------------------
16
参考如下:
COMP_NOCOMPRESS CONSTANT NUMBER := 1;
COMP_FOR_OLTP CONSTANT NUMBER := 2;
COMP_FOR_QUERY_HIGH CONSTANT NUMBER := 4;
COMP_FOR_QUERY_LOW CONSTANT NUMBER := 8;
COMP_FOR_ARCHIVE_HIGH CONSTANT NUMBER := 16;
COMP_FOR_ARCHIVE_LOW CONSTANT NUMBER := 32;
COMP_RATIO_MINROWS CONSTANT NUMBER := 1000000;
COMP_RATIO_ALLROWS CONSTANT NUMBER := -1;
可以得知,16就是创建时候的ARCHIVE_HIGH压缩方式。
之后,对这个表,进行更新操作。
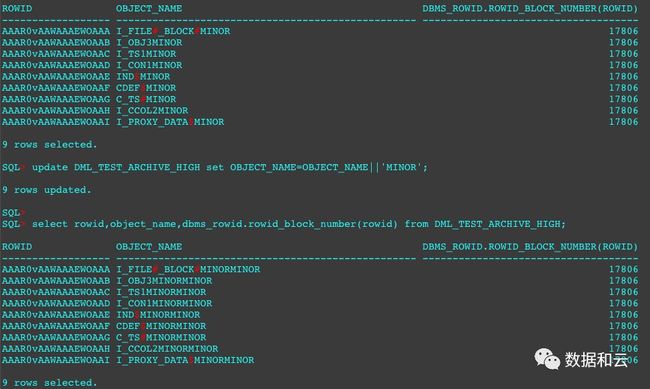
SQL> update DML_TEST_ARCHIVE_HIGH set OBJECT_NAME=OBJECT_NAME||'MINOR';
9 rows updated.
再次查看这个表的rowid及块号:
SQL> select rowid,object_name,dbms_rowid.rowid_block_number(rowid) from DML_TEST_ARCHIVE_HIGH;
ROWID OBJECT_NAME DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)
------------------ ---------------------------------------- ------------------------------------
AAAR0vAAWAAAEWOAAA I_FILE#_BLOCK#MINOR 17806
AAAR0vAAWAAAEWOAAB I_OBJ3MINOR 17806
AAAR0vAAWAAAEWOAAC I_TS1MINOR 17806
AAAR0vAAWAAAEWOAAD I_CON1MINOR 17806
AAAR0vAAWAAAEWOAAE IND$MINOR 17806
AAAR0vAAWAAAEWOAAF CDEF$MINOR 17806
AAAR0vAAWAAAEWOAAG C_TS#MINOR 17806
AAAR0vAAWAAAEWOAAH I_CCOL2MINOR 17806
AAAR0vAAWAAAEWOAAI I_PROXY_DATA$MINOR 17806
9 rows selected.
可以看到,rowid,block id,都发生了变化,所以证明对CU内的数据更新,这里有解压,移动到别的block更新的操作。
那么更新后的数据还是压缩的吗?显然,不是了。
SQL> select DBMS_COMPRESSION.GET_COMPRESSION_TYPE('HR','DML_TEST_ARCHIVE_HIGH',rowid) from DML_TEST_ARCHIVE_HIGH;
DBMS_COMPRESSION.GET_COMPRESSION_TYPE('HR','DML_TEST_ARCHIVE_HIGH',ROWID)
-------------------------------------------------------------------------
1
1
1
1
1
1
1
1
1
9 rows selected.
压缩为1,1代表的是COMP_NOCOMPRESS CONSTANT NUMBER := 1,不压缩。所以,除了insert,update也会带来解压不压缩的情况。在执行update操作时,db会将列压缩的数据,转换为行来操作,并且在操作完成之后,并不会再次压缩。
如果需要重新让这些复苏的数据重新压缩,需要显式的move这些表。
刚才注意到,更新会导致压缩数据的rowid发生变化,那么,能不能不变化?答案是可以的。
隐含参数:
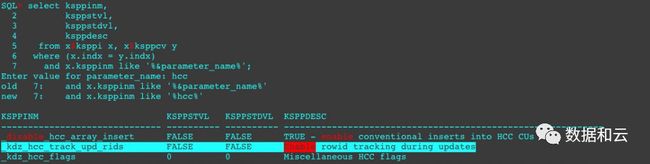

然后我们复现上面的更新操作:
第三部分,上面OLAP及OLTP的这么多测试均是单个场景的测试,那么HCC在实际场景下使用起来跟不带HCC的环境对比起来怎么样?这里想起了swingbench。
swingbench不多介绍。但是有个问题,swingbench的对象是自己程序生成的,不能人工干预创建对象用的参数,除非你逐个去改那些脚本。
其实有个简单的办法,就是创建测试表空间的时候,给表空间加上HCC参数。这里只做query high场景下不带row level locking及带row level locking跟非HCC场景下的压力测试。考虑到客户环境不是会串行的,所以我使用4个会话来测试。测试基准数据量为0.5GB,要测三场。
首先生成三个承载表空间,一个是带了HCC属性,一个是带了HCC的row level locking属性,一个是不带HCC属性。
SQL> CREATE SMALLFILE TABLESPACE SOE_EHCC_TBS
2 DATAFILE
3 '/ehccfs/ORA19C/ora19pdb1/SOE_EHCC_TBS_001.DBF' SIZE 10485760 AUTOEXTEND ON NEXT 1048576 MAXSIZE 10737418240
4 BLOCKSIZE 8192
5 FORCE LOGGING
6 DEFAULT COLUMN STORE COMPRESS FOR query HIGH NO INMEMORY
7 ONLINE
8 SEGMENT SPACE MANAGEMENT AUTO
9 EXTENT MANAGEMENT LOCAL AUTOALLOCATE;
Tablespace created.
SQL> CREATE SMALLFILE TABLESPACE SOE_NO_EHCC_TBS
2 DATAFILE
3 '/ehccfs/ORA19C/ora19pdb1/SOE_NO_EHCC_TBS_001.DBF' SIZE 10485760 AUTOEXTEND ON NEXT 1048576 MAXSIZE 10737418240
4 BLOCKSIZE 8192
5 FORCE LOGGING
6 DEFAULT COLUMN STORE COMPRESS FOR query HIGH NO INMEMORY
7 ONLINE
8 SEGMENT SPACE MANAGEMENT AUTO
9 EXTENT MANAGEMENT LOCAL AUTOALLOCATE;
Tablespace created.
SQL> CREATE SMALLFILE TABLESPACE SOE_EHCC_ROW_LOCKING_TBS
2 DATAFILE
3 '/ehccfs/ORA19C/ora19pdb1/SOE_EHCC_ROW_LOCKING_TBS_001.DBF' SIZE 10485760 AUTOEXTEND ON NEXT 1048576 MAXSIZE 10737418240
4 BLOCKSIZE 8192
5 FORCE LOGGING
6 DEFAULT COLUMN STORE COMPRESS FOR query HIGH ROW LEVEL LOCKING NO INMEMORY
7 ONLINE
8 SEGMENT SPACE MANAGEMENT AUTO
9 EXTENT MANAGEMENT LOCAL AUTOALLOCATE;
Tablespace created.
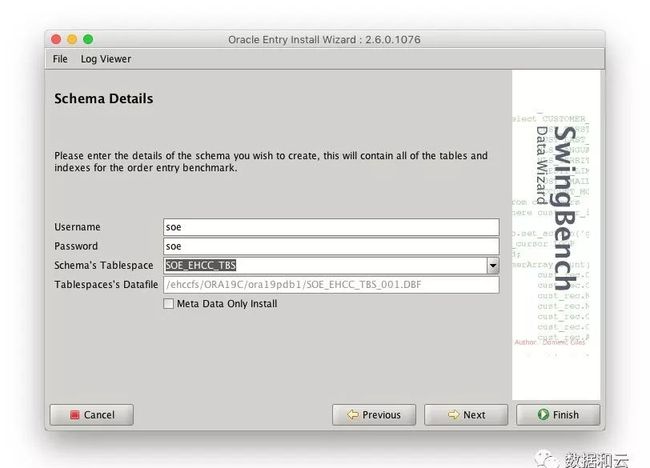
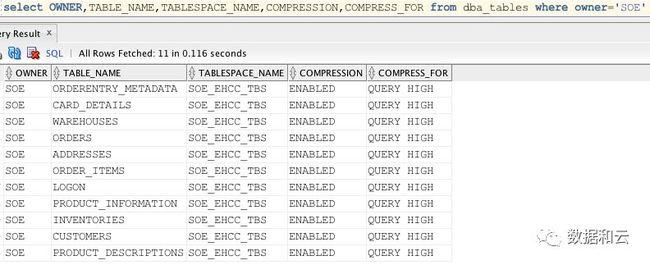
最终能看到生成的数据如下:
待数据生成完成之后,开始swingbench的测试。这里停止了测试。因为在swingbench的默认场景中,有大量的DML操作,而跟我上文测试的结果,随着业务时间的推移,大部分表都会因DML而变成非压缩表。所以DML测试的意义不大。唯一可能有测试意义的就是OLAP了。这个修改swingbench配置此处省略。
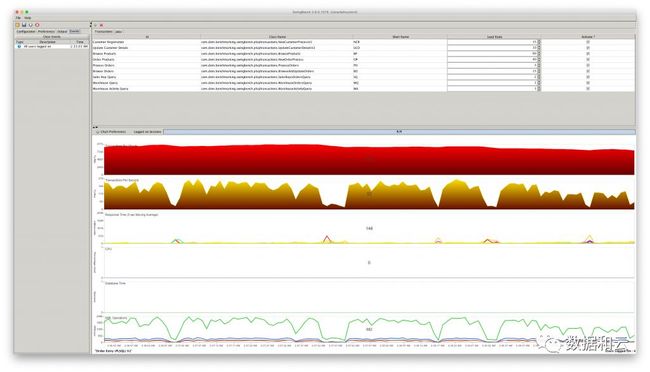 DML测试中,数据趋于跟非HCC一致了。
DML测试中,数据趋于跟非HCC一致了。
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
2018DTCC , 数据库大会PPT
2018DTC,2018 DTC 大会 PPT
ENMOBK,《Oracle性能优化与诊断案例》
DBALIFE ,“DBA 的一天”海报
DBA04 ,DBA 手记4 电子书
122ARCH ,Oracle 12.2体系结构图
2018OOW ,Oracle OpenWorld 资料
产品推荐云和恩墨Bethune Pro企业版,集监控、巡检、安全于一身,你的专属数据库实时监控和智能巡检平台,漂亮的不像实力派,你值得拥有!
云和恩墨zData一体机现已发布超融合版本和精简版,支持各种简化场景部署,零数据丢失备份一体机ZDBM也已发布,欢迎关注。