Hadoop 2.6.0的安装与配置
系统:Ubuntu 14.10,其部署在VMware workstation 11.0.0上
JDK:jdk-7u25-linux-i586.tar.gz
Hadoop:hadoop-2.6.0.tar.gz(下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/)
Step1:上传安装包
在windows系统预先下载安装包,这里要用到jdk-7u25-linux-i586.tar.gz和Hadoop:hadoop-2.6.0.tar.gz两个包,在/home/caiyong/下面新建setup文件夹,使用Xshell上传jdk-7u25-linux-i586.tar.gz和Hadoop:hadoop-2.6.0.tar.gz到/home/caiyong/setup/目录下面。上传结果如下图所示:

Step2:安装SSH
在命令行执行如下命令:
sudo apt-get install ssh
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys命令行输入:
ssh -V出现的内容如下图,则说明安装成功

命令行输入:
ssh localhost
显示内容如下图,则说明使用ssh免密钥成功登录到了localhost。
Step3:安装JDK
(1)解压JDK安装包
将JDK安装包解压到/usr/java目录下,命令行输入:
tar -zxvf jdk-7u25-linux-i586.tar.gz -C /usr/java 在/etc/profile文件中添加下面的内容:
export JAVA_HOME=/usr/java/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile (3)设置新安装的JDK为默认的JDK
命令行输入如下命令:
sudo update-alternatives --install /usr/bin/java java /usr/java/jdk/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/java/jdk/bin/javac 300
sudo update-alternatives --config java
(4)验证JDK
命令行输入如下命令:
java -version
(1)解压Hadoop安装包
进入/home/caiyong/目录下面,将Hadoop安装包解压到/opt/目录下,命令行输入:
tar -zxvf hadoop-2.6.0.tar.gz -C /opt/进入/opt/hadoop目录下面,用vi编辑器打开etc/hadoop/hadoop-env.sh,在hadoop-env.sh末尾添加如下内容:
# set to the root of my java installation
export JAVA_HOME=/usr/java/jdk
#my hadoop installation directory is
export HADOOP_PREFIX=/opt/hadoop(3)配置core-site.xml
进入/opt/hadoop目录下面,用vi编辑器打开etc/hadoop/core-site.xml,在core-site.xml的
fs.defaultFS
hdfs://localhost:9000
(4)配置hdfs-site.xml
进入/opt/hadoop目录下面,用vi编辑器打开etc/hadoop/hdfs-site.xml,在hdfs-site.xml的
dfs.replication
1
dfs.namenode.name.dir
/home/caiyong/hdfs/namenode
dfs.blocksize
268435456
dfs.datanode.data.dir
/home/caiyong/hdfs/datanode
至此,基本配置完成。可以在本机上运行MapReduce任务。
#1:格式化文件系统
进入/opt/hadoop目录下面,命令行输入:
bin/hdfs namenode -format#2:启动 NameNode 和 DataNode 的守护进程
在/opt/hadoop目录下面,命令行输入:
sbin/start-dfs.shHadoop的守护进程的日志被写入到 $HADOOP_LOG_GIR目录下面,默认是在$HADOOP_LOG_DIR/logs里面。
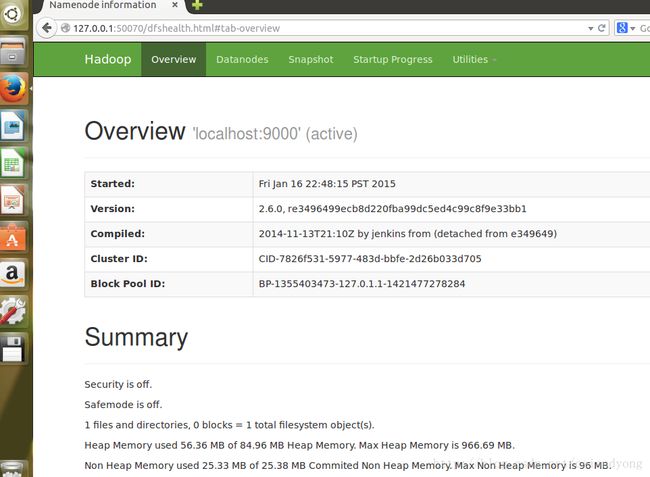
#3:通过web浏览器接口查看NameNode的情况
默认情况下,是在浏览器输入http://localhost:50070/
我的NameNode的情况如下图所示:
#4:建立 HDFS 文件目录
在/opt/hadoop目录下面,命令行依次输入:
bin/hdfs dfs -mkdir /user bin/hdfs dfs -mkdir /user/caiyong //此处,caiyong为我的用户名
#5:把输入的文件拷贝到文件系统
在/opt/hadoop目录下面,命令行依次输入:
cp etc/hadoop/*.xml input //将etc/hadoop/目录下面所有的xml文件拷贝到input文件夹里面
bin/hdfs dfs -put etc/hadoop input
#6:运行实例
在/opt/hadoop目录下面,命令行输入:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'
#7:查看实例运行结果
在/opt/hadoop目录下面,命令行依次输入:
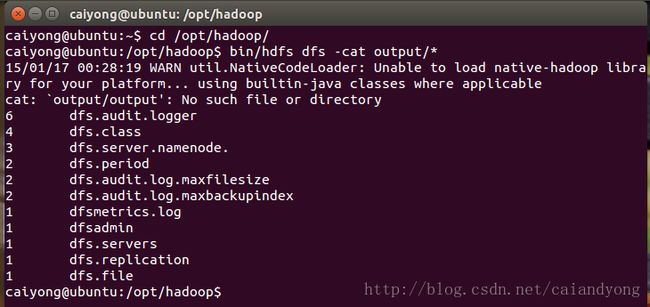
bin/hdfs dfs -get output output cat output/*或者输入:
bin/hdfs dfs -cat output/*在本机上,实例运行结果后,output里面的内容如下图所示:
#8:运行结束,关闭守护进程
在/opt/hadoop目录下面,命令行输入:
sbin/stop-dfs.sh(5)在 YARN上运行MapReduce的配置
#1:配置mapred-site.xml
进入/opt/hadoop目录下面,用vi编辑器打开etc/hadoop/mapred-site.xml,在mapred-site.xml的
mapreduce.framework.name yarn
#2:配置yarn-site.xml
进入/opt/hadoop目录下面,用vi编辑器打开etc/hadoop/yarn-site.xml:,在yarn-site.xml的
#3:启动ResourceManager和NodeManager的守护进程yarn.nodemanager.aux-services mapreduce_shuffle
在/opt/hadoop目录下面,命令行输入:
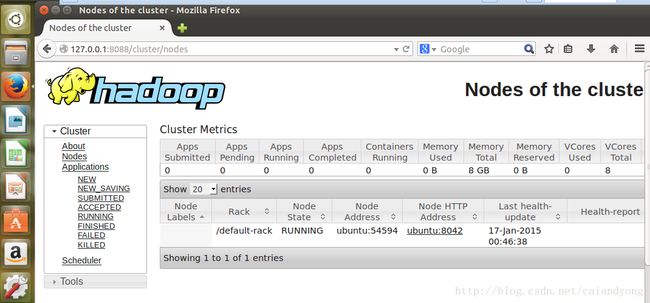
sbin/start-yarn.sh#4:通过web浏览器接口查看ResourceManager的信息
默认情况下,是在浏览器输入http://localhost:8088/
我的ResourceManage的信息如下图所示:
#5:关闭守护进程
在/opt/hadoop目录下面,命令行输入:
sbin/stop-yarn.sh
参考资料:
[1]http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Execution
[2]http://wiki.apache.org/hadoop/Hadoop2OnWindows