【翻译】StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
摘要

最近的研究表明了两个领域内图像到图像转换取得了显著的成功。然而,现有的方法处理两个以上的领域时在可伸缩性和鲁棒性上有局限,因为每对图像域都要构建不同的模型。为了解决这个局限,我们推出starGAN,一种新颖的、可扩展的方法,它可以仅使用一个模型对多个域执行图像到图像的转换。StarGAN的这种统一模型架构可以仅在一个网络中国训练多个数据集的多个领域。这使starGAN与现有模型相比,转换图片的质量更高,拥有灵活地将输入图像转换到任何目标域的新能力。我们的实验证明了我们的方法在面部特征转移和面部表情合成上的有效性。
1.介绍 Introduction
图像到图像转换的任务是改变图像上特定的部分,使给定的图像变成另一张图像,比如改变一个人的面部表情使他从微笑到皱眉(Fig.1),在引入生成性对抗网络(GANs)之后,这项任务经历了显著的改进,其结果包括改变头发颜色、从边缘地图重建照片和改变风景图片的季节。
给定来自两个不同域的训练数据,这些模型学习将图像从一个域转换到另一个域。我们定义attribute表示图片特征,例如头发颜色、性别或年龄,定义attribute value表示为属性的特定值,例如,黑色/金色/棕色表示头发颜色,或男性/女性表示性别。定义domain为一系列共享了某个属性的图片,如女性图片和男性图片分属不同的domain。
一些图像数据集包含许多标记属性。例如,CelebA数据集包含40个与面部属性相关的标签,如头发颜色、性别和年龄,RaFD数据集有8个面部表情标签,如“高兴”、“生气”和“悲伤”。这些设置使我们能够执行更有趣的任务,即多域图像到图像的转换,根据来自多个域的属性更改图像。图1的前五列展示了CelebA图像如何通过‘棕发’、‘性别’、‘年龄’‘白色皮肤’任意四个域之一进行转化的。我们可以更进一步地从多个数据集训练多个领域,例如,联合训练CelebA和RaFD图像,使用在RaFD上训练获得的特征来改变CelebA图像的面部表情,如图1的最右边的几栏。

然而,现有的各种模型在多领域图像转化问题上效率很低,现有的GAN模型效率低是因为为了实现在k个不同的风格域上进行迁移,需要构建k*(k-1)个生成器,图2说明了如何训练12个不同的生成器网络在4个不同的域之间转换图像。同时,尽管存在如人脸形状这样可以可以从所有领域的图像中学习到的全局特征,每个生成器也不能充分利用训练数据,只能从k中选2个学习,这是生成网络的效率很低。未能充分利用训练数据可能会限制生成图像的质量。此外,他们不能训练来自数据集的域,因为每个数据集都有部分标记,将在3.2节进一步讨论。
为了解决这一问题,我们提出starGAN,一种可以在多个域之间映射的生成对抗网络。如图2(b)所示,我们的模型仅用一个生成器训练多个领域,学习所有获得领域间的映射。这个思想很简单,我们的模型没有学习固定的转换(例如,从黑色到金色的头发),而是同时输入图像和域信息,并学习将输入的图像灵活地转换到相应的域中。我们使用一个标签(例如二进制或one-hot向量)来表示域信息, 在训练期间,随机生成一个目标域标签,并训练模型将输入图像灵活地转换到目标域。这样,我们可以控制域标签,并在测试阶段将图像转换到任何所需的域。
我们还介绍一种简单有效的方法,通过在域标签中添加mask vector来实现不同数据集的域之间的联合训练。我们提出的方法确保模型可以忽略位置标签关注特殊数据集提供的标签。用这种方法,我们的模型可以很好地执行任务,例如使用从RaFD学习的特征合成CelebA图像的面部表情,如图1最右边的列所示。直到目前我们所知的中,我们的工作是第一个成功实现跨不同数据集执行多域图像转换的。
总的来说,我们的贡献如下:
- 我们提出StarGAN,一种新颖的生成对抗网络,能够只用一个生成器和判别器学习多领域图像之间的映射。
- 我们证明了利用mask vector的方法我们成功的在不同的数据集上学习多领域图像的转换,这也使得我们提出的StarGAN能够控制各领域的标签。
- 我们使用StarGAN在人脸属性转换和人脸表情分析任务中提供了定量和定性的结果,展示了本模型相对于其他模型的优越性。
2.相关工作Related Work
Generative Adversarial Networks.生成对抗网络(GANs)在各种计算机视觉领域都显示出显著的效果,如图像生成、图像转换、超分辨率成像、面部图像合成。一个传统的GAN模型包含两个模块:一个判别器和一个生成器。判别器学习判别真假样本,生成器学习产生与真样本难以分辨的假样本。我们的方法还利用adversarial 损失,使生成的图像尽可能真实。
Conditional GANs.基于GAN的条件图像生成也展开了积极的研究。先前的研究已经为判别器和生成器提供了类信息,以便生成基于类的样本。其他最近的方法集中于生成与给定文本描述高度相关的特定图像。条件图像生成也成功应用到了域转换,超分辨率成像和图片编辑。本文提出了一种可扩展的GAN框架,通过提供条件域信息,可以灵活地将图像转换到不同的目标域。
Image-to-Image Translation.最近在图像到图像转换的工作得到了令人印象深刻的结果。如pix2pix用cGANs以有监督的方式进行图像转换。它结合了adversarial 损失和L1损失,因此需要成对的数据样本。为了解决获取数据对的问题,提出一种不成对的图像到图像转换的框架。UNIT将VAEs与CoGAN结合起来,CoGAN是由两个生成器共享权重以学习图像在跨域中的联合分布的一个GAN框架。CycleGAN和DiscoGAN利用cycle consistency损失来保存输入图像和转换图像间的关键属性。然而,所有这些框架一次只能学习两个域之间的联系。他们的方法在处理多个域的时候有限制,需要对每对域训练不同的模型。与之前提到的方法不同,我们的框架可以仅用一个生成器学习多个域之间的关系。

3. Star Generative Adversarial Networks
首先定义提出的StarGAN,StarGAN是一个在单个数据集中处理多域图像到图像转换的框架。然后,我们讨论了StarGAN如何将包含不同标签集的多个数据集合并在一起,以便使用这些标签灵活地执行图像转换。
3.1 多域图像转换 Multi-Domain Image-to-Image Translation
我们的目标是训练一个单独的生成器G使他可以学习多域间的映射。为了达到目标我们训练了一个生成器G,它能将带有域标签c的输入图像x转换为输出图像y,G(x, c)—>y。随机生成目标域标签c,使G能灵活地转换输入图像。我们还引入了一个辅助判别器,允许单个的判别器控制多域。也就是说,判别器产生图像和标签的可能性分布为,D:x->{Dsrc(x),Dcls(x)}, 图3说明了我们提出方法的训练过程。
Adversarial Loss.为了让产生的图像与真实图像难以区分,我们采用对抗性损失

G生成图像G(x,c),由输入图像x和目标领域标签c得到,同时判别器D试图区分开真实图像和生成图像。在本文中,我们将Dsrc(x)作为输入图像x经过判别器D之后得到的可能性分布,生成器G使这个式子尽可能的小,而判别器D则尽可能使其最大化。
Domain Classification Loss.给定输入图像x和域标签c,我们的目标是将x转换成输出图像y,该图像被正确地分类到目标域c。为了是实现这个目标,我们在D的顶部增加一个辅助分类器,并加入分类损失函数,使其对生成器和判别器都起到优化的作用。也就是说,我们将目标分解为两项:用于优化D的真实图像的域分类损失和用于优化G的伪图像的域分类损失。前者具体公式为:
![]()
其中Dcls(c’|x)表示由D计算的域标签上的概率分布。最小化这个式子,判别器D学习将真实图像x正确分类到其相关分布c’。我们假设输入图像和域标签对(x,c’)由训练数据得来。另一方面,伪图像的域分类的损失函数定义为:
![]()
换句话说,G最小化这个式子,使得生成的图像能够被判别器判别为目标领域c。
Reconstruction Loss.通过最小化对抗损失和分类损失,生成器G能够生成尽可能真实的图像,并且能够被分类为正确的目标领域。然而,最小化损失(式子(1)、(3))并不能保证转换后的图像在只改变输入中与域相关的部分的同时保留输入图像的内容。为了缓解这一问题,我们对生成器使用了循环一致性损失函数,定义如下:
![]()
其中,生成器G以生成图像G(x,c)以及原始输入图像领域标签c’为输入,努力重构出原始图像x。我们选择L1范数作为重构损失函数。注意我们两次使用了同一个生成器,第一次是将原始图像转化为目标域图像,然后由转换后的图像重构成原始图像。
Full Objective.最终,优化G和D的目标函数分别为:

其中λcls, λrec是和对抗损失相对权重类似分别控制分类误差和重构误差的超参数。在所有实验中,我们设置λcls=1,λrec=10。
3.2 多数据集训练 Training with Multiple Datasets
StarGAN的一个重要优势是同时合并包含不同类型标签的多个数据集,使得其在测试阶段能够控制所有的标签。然而有一个问题是当从多个数据集学习时标签信息对每个数据集而言只是部分已知。在CelebA和RaFD的例子中,前一个数据集包含诸如发色,性别等信息,但它不包含任何后一个数据集中包含的诸如开心生气等表情标签。这是有问题的,因为当从翻译的图像G(x,c)重建输入图像x时,需要关于标签向量c′的完整信息(参见式(4)
Mask Vector.为了缓解这一问题,引入mask vecrot m,允许StarGAN忽略不明确的标签,专注于特定数据集提供的明确的已知标签。在StarGAN中,用n维one-hot向量来表示m,n表示数据集的数量。此外,为标签定义统一的版本:
[·]表示串联,其中ci表示第i个数据集的标签。已知的标签ci的向量可以表示为二进制属性的二进制向量,也可以表示为分类属性的一个one-hot向量。对于剩下的n-1个未知标签我们简单设为0。在我们的实验中,我们使用CelebA和RaFD数据集,n为2。

Training Strategy. 利用多数据集训练StarGAN时,我们使用式子(7)定义的c~作为生成器的输入.这样做使生成器学习忽略不明确的标签,设为0向量,来关注明确的给定标签。生成器的结构与训练单个数据集时是一致的,除了输入c~。另一方面,我们扩展了判别器的辅助分类器来生成所有数据集在标签上的概率分布。然后,将模型按照多任务学习的方式进行训练,其中,判别器只将已知标签相关的分类误差最小化即可。比如,训练CelebA的图像,判别器只是把CelebA中涉及到的属性标签的分类误差最小化,而不是RaFD数据集相关的面部表情的标签。通过这样的设置,判别器学习到了所有数据集的分类特征,生成器也学会控制所有数据集的所有标签。
4.实施Implementation
Improved GAN Training.为了稳定训练过程获得高质量的图片,我们使用带梯度惩罚的WGAN策略作为对抗损失函数,如下:
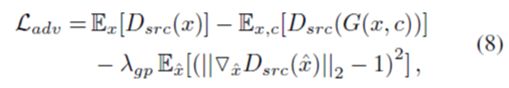
其中x^沿真实图像对和生成图像对之间的直线均匀采样,整个实验过程使用λgp = 10。
Network Architecture. StarGAN具有由两个卷积层组成的生成器网络,其中两个卷积层的步长为2(用于下采样)、六个剩余块和两个转置卷积层的步长为2(用于上采样)。我们对生成器使用实例规范化,但对鉴别器不使用规范化。我们利用PatchGANs作为鉴别网络,它对局部图像补丁的真假进行分类。
5实验 Experiments
在这一部分,首先通过进行用户研究来比较StarGAN和最近的面部属性转移方法。接下来,对人脸表情生成进行分类实验。最后,证明了StarGAN可以学习多个数据集之前图像到图像的翻译。我们所有的实验都是在训练阶段用看不见的图像输出的模型进行的。
5.1 Baseline Models
我们采用DIAT和CycleGAN作为对照组模型,这两种方法都在两个不同的域之间执行图像到图像的转换。为了进行比较,我们为每对不同的域多次训练这些模型。我们还采用IcGAN作为对照组,它可以使用cGAN执行属性转移。
DITA 使用对抗损失来学习从x到y的映射,其中x和y分别是X和Y两个不同域中的人脸图像。该方法在映射上的正则化项为||x-F(G(x))||1,以保持源图像的身份特征,其中F是在人脸识别任务中预先训练的特征提取器。
CycleGAN 同样是用对抗损失学习X,Y两个不同域间的映射。该方法通过循环一致性损失对映射进行正则化||x-GYX(GXY(x))||1和||y-GXY(GYX(y))||1。这种方法需要两个生成器和鉴别器为每对不同的域。
IcGAN将编码器和cGAN结合起来。cGAN学习映射G:{z,c}->x,图像x同时受到潜向量z和条件向量c的作用。此外IcGAN引入一个编码器学习cGAN的逆映射,Ez:x->z 和Ec:x->c。这使得IcGAN可以仅通过改变条件向量和保留潜向量来合成图像。
5.2 Datasets
CelebA.CelbA数据集包含202,599 个名人的面部图像,每个图像都带有40个二进制属性。我们将初始大小为178×218的图像裁剪为178×178,然后将其大小调整为128×128。我们随机选取2000幅图像作为测试集,利用所有剩余图像作为训练数据。我们使用以下属性构建七个域:头发颜色(黑色、金色、棕色)、性别(男性/女性)和年龄(年轻/年老)。
RaFD.RaFD包含从67名参与者收集的4,824张图像。每个参与者在三个不同的注视方向做八个面部表情,从三个不同的角度捕捉。我们将图像裁剪为256×256,其中面居中,然后将其大小调整为128×128。
5.3 Training
用Adam算法训练所有模型,参数β1=0.5,β2=0.999。以0.5的概率水平翻转图像来增强数据。五次鉴别器更新后执行一次生成器更新,一次训练的样本量设为16。在CelebA上的实验中,我们在前10个阶段训练所有学习率为0.0001的模型,并在后10个阶段将学习率线性衰减为0。为了弥补数据的不足,在使用RaFD进行训练时,我们对所有模型进行100个阶段的训练,学习率为0.0001,并在接下来的100个阶段应用相同的衰减策略。在一台NVIDIA Tesla M40 GPU上训练大约需要一天。

5.4. Experimental Results on CelebA
我们首先将所提出的方法与单属性和多属性传输任务的对照模型进行比较。考虑到所有可能的属性-值对,我们对DIAT和CycleGAN等跨域模型进行了多次训练。在DIAT和CycleGAN的情况下,我们执行多步骤转换以合成多个属性(例如,在更改头发颜色后传输性别属性)。
Qualitative evaluation.图4示出了CelebA上的面部属性转移结果。我们观察到,与跨域模型相比,我们的方法在测试数据上提供了更高质量的转换结果。一个可能的原因是StarGAN通过多任务学习框架的正则化效应。换句话说,相对于训练一个模型来执行固定的转换(例如,棕色-金色头发),这很容易过拟合,更好的是训练我们的模型来根据目标域的标签灵活地转换图像。这使得我们的模型能够学习适用于具有不同面部属性值的图像的多个域的可靠特征。
此外,相对于IcGAN,我们的模型在保留输入的面部特征方面具有优势。我们推测这是因为我们的方法通过使用卷积层的激活图作为潜在的表示来保存空间信息,而不是像IcGAN那样仅仅使用低维的潜向量。
Quantitative evaluation protocol.为了进行定量评估,我们使用AMT对单属性和多属性转换任务进行了两次用户研究。在给定输入图像的情况下,土耳其人被要求根据感知现实、属性转换质量和保持人物的原始特征来选择最佳生成图像。这些选项是从四种不同方法生成的四个随机图像。在一项研究中生成的图像在头发颜色(黑色、金色、棕色)、性别或年龄上都有一个属性转移。在另一项研究中,生成的图像包含属性转换的组合。每个土耳其人被问30到40个问题,包括几个简单合逻辑的问题来验证人类的努力。单次和多次转移任务中,验证的土耳其人的数量分别为146和100。

Quantitative results. 表1和表2分别显示了我们在单属性和多属性转换上的AMT实验结果。在所有实验中,StarGAN在属性转换效果获得了多数选票。在表1中性别变化的情况下,我们的模型和其他模型之间的投票差异很小,例如,StarGAN的39.1%和DIAT的31.4%。然而,在多属性变化中,例如表2中的“G+A”情况,性能差异明显,例如StarGAN的49.8%与IcGAN的20.3%,清楚地显示了StarGAN在更复杂的多属性转移任务中的优势。这是因为与其他方法不同,StarGAN可以通过在训练阶段随机生成目标域标签来处理关于多个属性变化的图像转换。

5.5 Experimental Results on RaFD
接下来训练我们的模型在RaFD数据集上生成面部表情。为了比较StarGAN和对照组的模型,我们将输入域固定为“中性”表达式,但目标域在其余七个表达式中有所不同。
Qualitative evaluation.如图5所示,StarGAN在正确保持输入的人物特征和面部特征的同时,清晰地生成最自然的表情。尽管DIAT和CycleGAN大多保留了输入的身份,但它们的许多结果显示模糊,无法保持输入中看到的锐度。IcGAN甚至无法在生成男性图像时保留图像中的个人身份。
我们认为,StarGAN在图像质量方面的优势是由于其来自多任务学习环境的隐式数据增强效应。RaFD图像包含较小的样本,如每个域500个图像。当在两个域上训练时,DIAT和CycleGAN一次只能使用1000个训练图像,但是StarGAN总共可以使用所有可用域中的4000个图像进行训练。这使得StarGAN能够正确地学习如何保持生成输出的质量和清晰度。

Quantitative evaluation.为了进行定量评估,我们计算了人脸表情生成图像的分类误差。我们使用ResNet-18体系结构在RaFD数据集上训练了一个面部表情分类器(训练集和测试集的分割率为90%/10%),得到了接近完美的99.55%的准确率。然后,我们使用相同的训练集训练每个图像转换模型,并在相同的、不可见的测试集上执行图像转换。最后,我们使用上面提到分类器对转化后的图像表情进行分类。如表3所示,我们的模型达到了最低的分类误差,这表明我们的模型在所有比较方法中产生了最真实的面部表情。
模型的另一个重要优点是可以根据所需参数的数量进行伸缩。表3的最后一列显示,StarGAN学习所有转换所需的参数数量比DIAT小7倍,比CycleGAN小14倍。这是因为StarGAN只需要一个生成器和判别器对,而不考虑域的数量,但是在跨域模型的情况下,如CycleGAN,需要为每个源-目标域对训练完全不同的模型。

5.6 Experimental Results on CelebA+RaFD
最后,证明我们的模型不仅可以从单个数据集中的多个域学习,而且可以从多个数据集中学习。使用mask vector在CelebA和RaFD数据集上联合训练模型。为了区分只在RaFD上训练的模型和同时在CelebA和RaFD上训练的模型,我们将前者表示为StarGAN-SNG(single),后者表示为StarGAN-JNT(joint)。

Effects of joint training.图6在合成CelebA图像的面部表情对StarGAN-SNG和StarGAN-JNT之间进行定性比较。StarGAN-JNT展现了高质量的情感图像,而StarGAN-SNG产生合理但模糊的灰色背景图像。这种差异是因为StarGAN-JNT在训练中学习转换CelebA图像,而StarGAN-SNG没有。换句话说,StarGAN-JNT可以利用这两个数据集来改进共享的低级任务,比如面部关键点检测和分割。通过同时使用CelebA和RaFD,StarGAN-JNT可以改善这些低级任务,这有利于学习面部表情合成。
Learned role of mask vector.在这个实验,给出一个one-hot向量c,对给定维度的人脸表情设置为1。这样,由于显式地给出了与第二个数据集相关联的标签,因此正确的mask vector是[0,1]。图7显示了给出正确mask vector的情况和相反mask vector即[1,0]的情况。使用的错误的mask vector时StarGAN-JNT 生成人脸表情失败,它会操纵输入图像的年龄。这是因为模型忽略了未知的面部表情标签,并通过mask vector将面部属性标签视为有效。注意,由于其中一个面部属性是“young”,因此当模型接受零向量作为输入时,它会将图像从young转换为old。通过这种行为,我们可以确认,当涉及到来自多个数据集的所有标签时,StarGAN正确地学习了mask vector在图像到图像转换中的预期作用。
6. 结论 Conclusion
本文提出StarGAN,一种可扩展的只用一个生成器和判别器进行多领域图像到图像转换的模型。除了在可扩展性方面的优势,由于多任务学习策略在生成能力上的提升,StarGAN相对于其他现有方法也能生成质量更高的图像。除此之外,本文提出的mask vector也使得StarGAN能够利用包含不同分布标签的不同数据集,进而可以处理从这些数据集中学习到的所有的属性标签。希望我们的工作能够让用户开发跨多个领域的图像转换应用。